What is the difference between synchronous and asynchronous Python?
Pay attention to "Python Cat", a public account worthy of starring

Stills | "Tang Bohu Spots Autumn Fragrance"
Author | Miguel Grinberg
Source | Architecture Headlines
In this article, I will explain in detail what asynchronous is and how it differs from ordinary Python code.
Have you heard people say that asynchronous Python code is faster than "normal (or synchronous) Python code? Is that really the case?"
1 What do "synchronous" and "asynchronous" mean?
Web applications usually process many requests, which come from different clients in a short period of time. To avoid processing delays, you must consider processing multiple requests in parallel, which is often referred to as "concurrency."
In this article, I will continue to use Web applications as examples, but there are other types of applications that also benefit from concurrency. Therefore, this discussion is not just for Web applications.
The terms "synchronous" and "asynchronous" refer to two ways of writing concurrent applications. So-called "synchronized" servers use threads and processes supported by the underlying operating system to achieve this concurrency. The following is a schematic diagram of synchronous deployment:
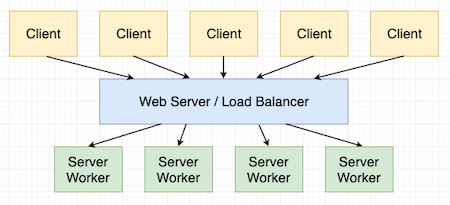
In this case, we have 5 clients, all sending requests to the application. The access entry of this application is a Web server, which acts as a [Load Balancing] (https://cloud.tencent.com/product/clb?from=10680) device by assigning services to a server worker pool. These workers can be implemented as processes, threads, or a combination of both. These workers execute the requests assigned to them by the load balancer. The application logic you write using a web application framework (such as Flask or Django) runs in these workers.
This type of solution is better for servers with multiple CPUs, because you can set the number of workers to the number of CPUs, so you can use your processor cores evenly, while a single Python process is locked due to the global interpreter. (GIL) restrictions cannot achieve this.
On the shortcomings, the above schematic diagram also clearly shows the main limitations of this scheme. We have 5 clients, but only 4 workers. If these 5 clients send requests at the same time, the load balancer will send all requests except a certain client to the worker pool, and the remaining requests have to be kept in a queue, waiting for workers to change Must be available. Therefore, four-fifths of the requests will be responded immediately, and the remaining one-fifth will need to wait a while. A key to server optimization is to select an appropriate number of workers to prevent or minimize request blocking for a given expected load.
The configuration of an asynchronous server is difficult to draw, but I tried my best:
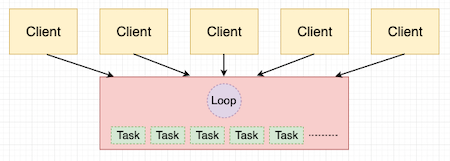
This type of server runs in a single process, controlled by loops. This loop is a very efficient task manager and scheduler, creating tasks to execute requests sent by clients. Unlike long-lived server workers, asynchronous tasks are created by loops to process a specific request. When that request is completed, the task will also be destroyed. At any time, an asynchronous server will have hundreds or thousands of active tasks, and they all perform their work under the management of the loop.
You might be wondering how parallelism between asynchronous tasks is achieved. This is the interesting part, because an asynchronous application achieves this through only cooperative multitasking. what does this mean? When a task needs to wait for an external event (for example, a response from a database server), it will not wait like a synchronized worker, but will tell the loop what it needs to wait for, and then return control to it. The loop can find another ready task when this task is blocked by the database. Eventually, the database will send a response, and then the loop will think that the first task is ready to run again, and will resume it as soon as possible.
The ability of asynchronous tasks to pause and resume execution may be difficult to understand in the abstract. In order to help you apply what you already know, you can consider using the await or yield keyword in Python to achieve this, but you will later find that this is not the only way to implement asynchronous tasks.
An asynchronous application runs completely in a single process or thread, which can be said to be surprising. Of course, this type of concurrency needs to follow some rules, so you can't let a task occupy the CPU for too long, otherwise, the remaining tasks will be blocked. In order to execute asynchronously, all tasks need to be actively paused periodically and return control to the loop. In order to benefit from the asynchronous approach, an application needs to have tasks that are often blocked by I/O and not have much CPU work. Web applications are usually very suitable, especially when they need to handle a large number of client requests.
When using an asynchronous server, in order to maximize the utilization of multiple CPUs, it is usually necessary to create a hybrid solution, add a load balancer and run an asynchronous server on each CPU, as shown in the following figure:

2 2 ways to achieve asynchrony in Python
I'm sure, you know that to write an asynchronous application in Python, you can use the asyncio package, which implements the pause and resume features required by all asynchronous applications on the basis of coroutines. Among them, the yield keyword, as well as the updated async and await are the basis for asyncio to build asynchronous capabilities.
https://docs.python.org/3/library/asyncio.html
There are other asynchronous solutions based on coroutines in the Python ecosystem, such as Trio and Curio. There is also Twisted, which is the oldest of all coroutine frameworks and even appeared earlier than asyncio.
If you are interested in writing asynchronous web applications, there are many asynchronous frameworks based on coroutines to choose from, including aiohttp, sanic, FastAPI and Tornado.
What many people don't know is that coroutines are just one of two ways to write asynchronous code in Python. The second method is based on a library called greenlet, which you can install with pip. Greenlets are similar to coroutines in that they also allow a Python function to suspend execution and resume later, but the way they achieve this is completely different, which means that the asynchronous ecosystem in Python is divided into two categories.
The most interesting difference between coroutines and greenlets for asynchronous development is that the former requires Python language-specific keywords and features to work, while the latter does not. What I mean is that coroutine-based applications need to use a specific syntax to write, and greenlet-based applications look almost like normal Python code. This is very cool, because in some cases, it allows synchronous code to be executed asynchronously, which is not possible with coroutine-based solutions such as asyncio.
So in terms of greenlet, what libraries are equivalent to asyncio? I know of 3 greenlet-based asynchronous packages: Gevent, Eventlet, and Meinheld, although the last one is more like a web server than a general asynchronous library. They all have their own asynchronous loop implementations, and they all provide an interesting "monkey-patching" function that replaces the blocking functions in the Python standard library, such as those that perform network and thread functions, and implement the equivalent based on greenlets The non-blocking version. If you have some synchronous code that you want to run asynchronously, these packages will help you.
As far as I know, the only web framework that explicitly supports greenlet is Flask. This framework will automatically monitor, when you want to run on a greenlet Web server, it will adjust itself accordingly, without any configuration. When doing this, you need to be careful not to call blocking functions, or if you want to call blocking functions, it is best to use monkey patching to "fix" those blocking functions.
However, Flask is not the only framework that benefits from greenlets. Other web frameworks, such as Django and Bottle], although they do not have greenlets, they can also be run asynchronously by combining a greenlet web server and using monkey-patching to fix blocking functions.
3 Is asynchronous faster than synchronous?
There is a widespread misunderstanding about the performance of synchronous and asynchronous applications-asynchronous applications are much faster than synchronous applications.
In this regard, I need to clarify. Whether it is written synchronously or asynchronously, Python code runs at almost the same speed. In addition to code, there are two factors that can affect the performance of a concurrent application: context switching and scalability.
Context switch
Sharing the work required by the CPU fairly among all running tasks, called context switching, can affect the performance of the application. For synchronization applications, this work is done by the operating system, and it is basically a black box without configuration or fine-tuning options. For asynchronous applications, context switching is done by loops.
The default loop implementation is provided by asyncio, which is written in Python and is not very efficient. The uvloop package provides an alternative loop scheme, some of which are written in C to achieve better performance. The event loop used by Gevent and Meinheld is also written in C. Eventlet uses a loop written in Python.
A highly optimized asynchronous loop is more efficient than the operating system in context switching, but in my experience, to see actual efficiency improvements, you must run a very large amount of concurrency. For most applications, I don't think the performance gap between synchronous and asynchronous context switching is so obvious.
Scalability
I think the source of the myth that asynchronous is faster is that asynchronous applications usually use the CPU more efficiently, scale better, and scale more flexibly than synchronous.
If the synchronization server in the above diagram receives 100 requests at the same time, think about what will happen. This server can only process up to 4 requests at the same time, so most requests will stay in a queue and wait until they are assigned a worker.
In contrast, the asynchronous server will immediately create 100 tasks (or in the mixed mode, create 25 tasks on each of the 4 asynchronous workers). With an asynchronous server, all requests will be processed immediately without waiting (although it is fair to say that this solution also has other bottlenecks that will slow down the speed, such as the limit on active database connections).
If these 100 tasks mainly use the CPU, then the synchronous and asynchronous schemes will have similar performance, because each CPU runs at a fixed speed, the speed at which Python executes code is always the same, and the work to be done by the application is also the same . However, if these tasks require a lot of I/O operations, then the synchronous server can only handle 4 concurrent requests and cannot achieve high CPU utilization. On the other hand, an asynchronous server will better keep the CPU busy because it runs all these 100 requests in parallel.
You may wonder why you can't run 100 simultaneous workers, so that the two servers will have the same concurrency capabilities. It should be noted that each worker needs its own Python interpreter and all resources associated with it, plus a separate copy of the application and its resources. The size of your server and application will determine how many worker instances you can run, but usually this number is not very large. On the other hand, asynchronous tasks are very lightweight and run in the context of a single worker process, so they have obvious advantages.
In summary, we can say that asynchronous may be faster than synchronous only in the following scenarios:
- There is high load (without high load, high concurrency of access has no advantage)
- The task is I/O bound (if the task is CPU bound, concurrency exceeding the number of CPUs does not help)
- You look at the average number of requests processed per unit time. If you look at the processing time of a single request, you won't see a big difference, and even asynchronous may be slower, because asynchronous has more concurrent tasks competing for CPU.
4 in conclusion
Hope this article can answer some confusions and misunderstandings about asynchronous code. I hope you can remember the following two key points:
- Asynchronous applications will only do better than synchronous applications under high load
- Thanks to greenlets, even if you write code in the usual way and use traditional frameworks like Flask or Django, you can benefit from asynchrony.
If you want to know more details about how asynchronous systems work, you can check out my talk Asynchronous Python for the Complete Beginner at PyCon on YouTube. https://www.youtube.com/watch?v=iG6fr81xHKA
Original link: https://blog.miguelgrinberg.com/post/sync-vs-async-python-what-is-the-difference


Recommended Posts