Talking about Python coroutine
Coroutine
Coroutine, also known as micro thread, fiber. The English name is Coroutine. One sentence explains what a thread is: a coroutine is a lightweight thread in a user mode.
The coroutine has its own register context and stack. When the coroutine scheduling switch, save the register context and stack to other places, and restore the previously saved register context and stack when switching back. therefore:
The coroutine can retain the state when it was last called (that is, a specific combination of all local states). Each time the process is reentered, it is equivalent to entering the state of the last call. In other words: entering the logic that was in the last time it left. The location of the stream.
Benefits of coroutine:
- No thread context switching overhead
- No atomic operation locking and synchronization overhead
- "Atomic operation (atomic operation) does not need to be synchronized", the so-called atomic operation refers to the operation that will not be interrupted by the thread scheduling mechanism; once this operation starts, it will run to the end without any context switch (switch) To another thread). Atomic operations can be one step or multiple steps, but the sequence cannot be disrupted, or cut off only the execution part. As the whole is the core of atomicity.
- Convenient to switch control flow and simplify programming model
- High concurrency + high scalability + low cost: It is not a problem for a CPU to support tens of thousands of coroutines. So it is very suitable for high concurrency processing.
Disadvantages:
- Unable to use multi-core resources: the nature of the coroutine is a single thread, it cannot use multiple cores of a single CPU at the same time, the coroutine needs to cooperate with the process to run on multiple CPUs. Of course, most of the applications we write every day are This is not necessary, unless it is a cpu-intensive application.
- Blocking operations (such as IO) will block the entire program
Example of using yield to implement coroutine operation
import time
import queue
def consumer(name):print("--- starting eating baozi...")while True:
new_baozi =yieldprint("[%s] is eating baozi %s"%(name, new_baozi))
# time.sleep(1)
def producer(): #Producer
r = con.__next__()
r = con2.__next__()
n =0while n <5:
n +=1
con.send(n)
con2.send(n)print("3[32;1m[producer]3[0m is making baozi %s"% n)if __name__ =='__main__':
con =consumer("c1")
con2 =consumer("c2")
p =producer()
The result of program execution is:
— starting eating baozi…
— starting eating baozi…
[ c1] is eating baozi 1
[ c2] is eating baozi 1
[ producer] is making baozi 1
[ c1] is eating baozi 2
[ c2] is eating baozi 2
[ producer] is making baozi 2
[ c1] is eating baozi 3
[ c2] is eating baozi 3
[ producer] is making baozi 3
[ c1] is eating baozi 4
[ c2] is eating baozi 4
[ producer] is making baozi 4
[ c1] is eating baozi 5
[ c2] is eating baozi 5
[ producer] is making baozi 5
Here comes the problem. The reason why the effect of multiple concurrency can be achieved now is because each producer does not have any time-consuming code, so he is not stuck at all. If the producer sleeps (1) at this time, then the speed is suddenly It becomes slower, look at the following function
def home():
print(“in func 1”)
time.sleep(5)
print(“home exec done”)
def bbs():
print(“in func 2”)
time.sleep(2)
def login():
print(“in func 2”)
If nginx comes to a request every time it is processed by a function, but it is a single-threaded situation, if nginx requests the home page, because nginx is single-threaded in the background processing, in the case of single-threaded colleagues come three requests, then What should I do? It must be serial execution time and time again, but in order to make him feel that it is concurrent, should I switch between various coroutines, but when should I switch? So, I ask you, if a request comes in and prints a print directly, will I switch to this place immediately? Because there is no blockage, it will not be the card owner, so there is no need to switch immediately. If he needs to do something, for example, the whole home takes 5 seconds, and the single thread is serial. Even if the coroutine is used, it is still serial. In order to ensure the effect of concurrency, when is the switch? Should time.sleep(5) switch to bbs request here, what if bbs also sleeps? Then it switches to the next login, then it is just that switch. How can we achieve the concurrency effect of the above program under a single thread? In a word, switch when encountering io operation. The reason why the coroutine can handle large concurrency is actually to squeeze out the io operation, that is, the io operation is switched, that is, this program only has the CPU in operation, so the speed is very fast! Then the question is again. After switching, when do you switch back? In other words, how can the program automatically monitor the completion of the io operation? Then look at the next knowledge point!
Greenlet
Greenlet is a coroutine module implemented in C. Compared with the yield that comes with python, it is a encapsulated coroutine that allows you to switch between any functions at will, without the need to declare this function as generator.
from greenlet import greenlet
def test1():print(12)
gr2.switch() #Switch to gr2
print(34)
gr2.switch() #Switch to gr2
def test2():print(56)
gr1.switch() #Switch to gr1
print(78)
gr1 =greenlet(test1) #Start a coroutine
gr2 =greenlet(test2) #
gr1.switch() #Switch to gr1
The result of the program execution is:
12
56
34
78
Gevent
The greenlet above is the automatic switching of manual gear. Now let's look at the automatic switching of automatic gear Gevent. It switches when it encounters IO.
Gevent is a third-party library that can easily implement concurrent synchronous or asynchronous programming through gevent. The main mode used in gevent is Greenlet, which is a lightweight coroutine that connects to Python in the form of a C extension module. Greenlets all run inside the main program operating system process, but they are scheduled cooperatively.
Let's take a look at the very simple coroutine switching applet
import gevent
def func1():print('3[31;1m Li Chuang is engaging with Haitao...3[0m')
gevent.sleep(2) #Imitate IO
print('3[31;1m Li Chuang went back and continued to engage with Haitao...3[0m')
def func2():print('3[32;1m Li Chuang switched to engaging with Hailong...3[0m')
gevent.sleep(1)print('3[32;1m Li Chuang finished Haitao, come back and continue with Hailong...3[0m')
gevent.joinall([
gevent.spawn(func1), #spawn starts a coroutine
gevent.spawn(func2),])
The result of the program execution is:
Li Chuang is engaging with Haitao...
Li Chuang switched to working with Hailong...
After Li Chuang finished Haitao, he came back and continued to engage with Hailong...
Li Chuang went back and continued to engage with Haitao...
Coroutine crawler
Now use coroutines to implement simple crawlers
from gevent import monkey; monkey.patch_all() #Mark all the io operations of the current program individually for me
import gevent #Coroutine module
from urllib.request import urlopen #Modules needed by crawlers
def f(url):print('GET: %s'% url)
resp =urlopen(url)
data = resp.read()print('%d bytes received from %s.'%(len(data), url))
gevent.joinall([ #Use coroutines to crawl web pages concurrently
gevent.spawn(f,'https://www.python.org/'),
gevent.spawn(f,'https://www.yahoo.com/'),
gevent.spawn(f,'https://github.com/'),])
The result of program execution is:
GET: https://www.python.org/
GET: https://www.yahoo.com/
GET: https://github.com/
59619 bytes received from https://github.com/.
495691 bytes received from https://www.yahoo.com/.
48834 bytes received from https://www.python.org/.
Coroutine Socket
Realize multi-socket concurrency under single thread through gevent
# socket_server #
import sys
import socket
import time
import gevent
from gevent import socket,monkey
monkey.patch_all()
def server(port):
s = socket.socket()
s.bind(('HW-20180425SPSL', port))
s.listen(500)while True:
cli, addr = s.accept()
gevent.spawn(handle_request, cli)
def handle_request(conn):try:while True:
data = conn.recv(1024)print("recv:", data)
conn.send(data)if not data:
conn.shutdown(socket.SHUT_WR)
except Exception as ex:print(ex)finally:
conn.close()if __name__ =='__main__':server(8001)
# socket_client #
import socket
HOST ='HW-20180425SPSL' # The remote host
PORT =8001 # The same port as used by the server
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))while True:
msg =bytes(input(" :"),encoding="utf8")
s.sendall(msg)
data = s.recv(1024)
# print(data)print('Received',repr(data))
s.close()
The result of the program execution is:
socket_client.py
: lala
Received b’lala’
:
socket_server.py
recv: b’heihei’
On event-driven and asynchronous IO
Generally, when we write programs for server processing models, there are the following models:
(1) Each time a request is received, a new process is created to handle the request;
(2) Each time a request is received, a new thread is created to process the request;
(3) Every time a request is received, put in an event list, and let the main process process the request through non-blocking I/O
The above methods have their own merits,
The method in (1), because the cost of creating a new process is relatively large, it will lead to poor server performance, but the implementation is relatively simple.
The (2) method, due to the synchronization of threads, may face deadlock and other problems.
In the third method, when writing application code, the logic is more complicated than the previous two.
Considering various factors, it is generally believed that the method (3) is the method adopted by most network servers
Look at the picture and talk about the event-driven model
In UI programming, it is often necessary to respond to mouse clicks. How to obtain mouse clicks first?
Method 1: Create a thread, the thread has been looping to detect whether there is a mouse click, then this method has the following disadvantages:
-
The CPU resources are wasted. The frequency of mouse clicks may be very small, but the scanning thread will continue to loop detection, which will cause a lot of waste of CPU resources; what if the interface for scanning mouse clicks is blocked?
-
If it is blocked, the following problems will occur. If we not only scan for mouse clicks, but also scan whether the keyboard is pressed, because the mouse is blocked when scanning the mouse, then the keyboard may never be scanned;
-
If there are a lot of devices that need to be scanned in a cycle, this will cause response time problems;
Therefore, this method is very bad.
Method 2: Event-driven model
At present, most UI programming is an event-driven model. For example, many UI platforms provide onClick() events, which represent mouse press events. The general idea of the event-driven model is as follows:
-
There is an event (message) queue;
-
When the mouse is pressed, a click event (message) is added to this queue;
-
There is a loop, which constantly takes out events from the queue, and calls different functions according to different events, such as onClick(), onKeyDown(), etc.;
-
Events (messages) generally save their own processing function pointers, so that each message has an independent processing function;
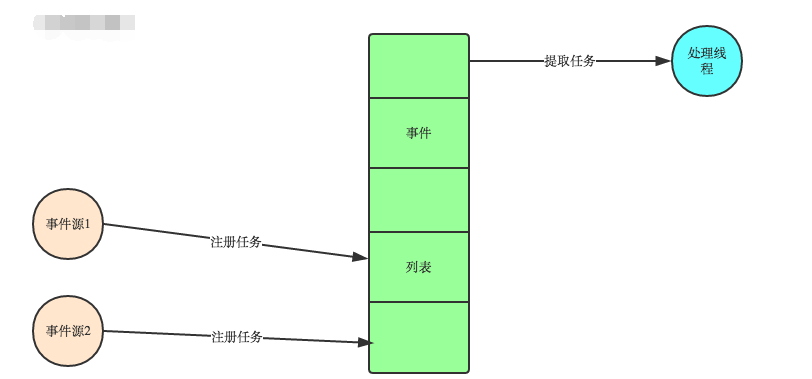
**What is an event-driven model? **
**In fact, it is to respond to events! **
Event-driven programming is a programming paradigm, where the execution flow of the program is determined by external events. It is characterized by including an event loop, when an external event occurs, a callback mechanism is used to trigger the corresponding processing. Two other common programming paradigms are (single-threaded) synchronous and multi-threaded programming.
Let us use examples to compare and contrast single-threaded, multi-threaded, and event-driven programming models. The following figure shows the work done by the program in these three modes over time. This program has 3 tasks to complete, and each task blocks itself while waiting for I/O operations. The time spent blocking I/O operations has been marked with a gray box.
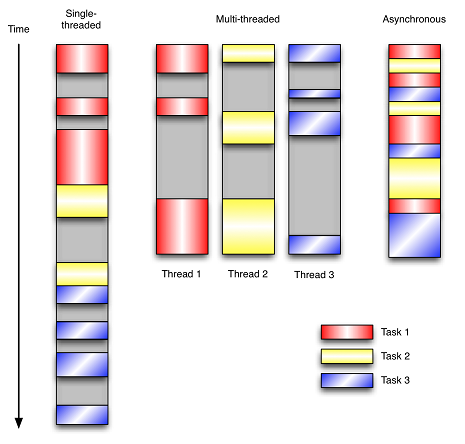
In the single-threaded synchronization model, tasks are executed sequentially. If a task is blocked due to I/O, all other tasks must wait until they are completed before they can be executed in sequence. This clear execution sequence and serialization behavior is easy to infer. If the tasks are not dependent on each other, but still need to wait for each other, this makes the program unnecessary to reduce the running speed.
In the multi-threaded version, these 3 tasks are executed in separate threads. These threads are managed by the operating system and can be processed in parallel on a multi-processor system or interleaved on a single-processor system. This allows other threads to continue execution while a thread is blocked on a certain resource. Compared with a synchronized program that performs similar functions, this method is more efficient, but the programmer must write code to protect shared resources and prevent them from being accessed by multiple threads at the same time. Multithreaded programs are more difficult to infer, because such programs have to deal with thread safety issues through thread synchronization mechanisms such as locks, reentrant functions, thread-local storage, or other mechanisms. Improper implementation will lead to subtle and undesirable bug.
In the event-driven version of the program, the three tasks are interleaved, but they are still controlled by a single thread. When processing I/O or other expensive operations, register a callback to the event loop, and then continue execution when the I/O operation is complete. The callback describes how to handle an event. The event loop polls all events and assigns them to the callback function waiting to process the event when the event arrives. In this way, the program can be executed as much as possible without the need for additional threads. Event-driven programs are easier to infer behavior than multi-threaded programs because programmers do not need to care about thread safety issues.
When we face the following environment, the event-driven model is usually a good choice:
-
There are many tasks in the program, and...
-
The tasks are highly independent (so they do not need to communicate with each other or wait for each other) and...
-
Some tasks will be blocked while waiting for the event to arrive.
This is also a good choice when the application needs to share variable data between tasks, because there is no need for synchronization.
Network applications usually have these characteristics, which makes them fit the event-driven programming model well.
A question to be raised here is that in the event-driven model above, as long as it encounters IO, it registers an event, and then the main program can continue to do other things. Only after the io is processed, it resumes the interruption. Task, how is this essentially achieved? Haha, let's uncover this mystery together. . . .
Please see this article on Python IO port multiplexing in detail
The above is the detailed content of the Python coroutine. For more information about the Python coroutine, please pay attention to other related articles on ZaLou.Cn!
Recommended Posts