Python Automation (20) | Talk about several methods of Python operation PDF (merge, split, watermark, encryption)

I. Introduction
Hello everyone, I have written a case about the operation of PDF in Python before ?PDF Batch Merge. The original intention of this case is to provide you with a convenient script, and there is not much explanation of the principle. It is the very practical module PyPDF2 for PDF processing. This article will analyze this module, and it will mainly involve
Comprehensive application of osmoduleComprehensive application of globmodulePyPDF2module operation
2. Basic operation
The code for PyPDF2 import module is often:
from PyPDF2 import PdfFileReader, PdfFileWriter
Two methods are imported here:
PdfFileReadercan be understood as a readerPdfFileWritercan be understood as a writer
Next, we will further understand the wonders of these two tools through a few cases. The sample file used is the pdf of 5 invoices.
The PDF of each invoice consists of two pages:

Three, merge
The first task is to combine 5 invoice pdfs into 10 pages. How should the reader and writer work together here?
The logic is as follows:
- The reader reads all pdfs once
- The reader passes the read content to the writer
- Writer unified output to a new pdf
There is also an important point of knowledge here: the reader can only deliver the read content to the writer page by page.
Therefore, step 1 and step 2 in the logic are actually not independent steps, but after the reader reads a pdf, it loops all the pages of the pdf and writes them page by page. Device. Finally, wait until all the reading work is finished before outputting.
Looking at the code can make the idea clearer:
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxxxxx'
pdf_writer =PdfFileWriter()for i inrange(1,6):
pdf_reader =PdfFileReader(path +'/INV{}.pdf'.format(i))for page inrange(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))withopen(path + r'\Merge PDF\merge.pdf','wb')as out:
pdf_writer.write(out)
Since all content needs to be delivered to the same writer for final output, the initialization of the writer must be outside the loop body.
If it is inside the loop body, it will become Every time a pdf is accessed and read a new writer is generated, so that the content of each reader handed over to the writer will be repeatedly overwritten , Unable to achieve our merger requirements!
The code at the beginning of the loop body:
for i inrange(1,6):
pdf_reader =PdfFileReader(path +'/INV{}.pdf'.format(i))
The purpose is to read a new pdf file in each cycle and pass it to the reader for subsequent operations. In fact, this writing method is not very recommended, because each pdf name happens to be very regular, so you can directly manually specify the number to cycle. A better way is to use the glob module:
import glob
for file in glob.glob(path +'/*.pdf'):
pdf_reader =PdfFileReader(path)
In the code, pdf_reader.getNumPages(): can get the number of pages of the reader, with range, it can traverse all pages of the reader.
pdf_writer.addPage(pdf_reader.getPage(page)) can pass the current page to the writer.
Finally, create a new pdf with with and output it by the pdf_writer.write(out) method of the writer
Fourth, split
If you understand the cooperation of the reader and writer in the merge operation, then the splitting is easy to understand. Here we take the splitting of INV1.pdf into two separate pdf documents as an example, and we will also start with A stroke of logic:
- Reader to read PDF documents
- Reader handed to writer page by page
- Writer immediately outputs every time it gets a page
Through this code logic, we can also understand that the initialization and output positions of the writer must be in the loop body that reads each page of the PDF loop, not outside the loop.
The code is simple:
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxx'
pdf_reader =PdfFileReader(path +'\INV1.pdf')for page inrange(pdf_reader.getNumPages()):
# Traverse to each page to generate writers one by one
pdf_writer =PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
# The writer immediately outputs a pdf after adding a page
withopen(path +'\INV1-{}.pdf'.format(page +1),'wb')as out:
pdf_writer.write(out)
Five, watermark
This time the work is to add the following picture as a watermark to INV1.pdf
The first is the preparation work. Insert the picture that needs to be used as a watermark into Word, adjust the appropriate position and save it as a PDF file. Then the code can be coded, and the copy module needs to be additionally used. The specific explanation is shown in the figure below:
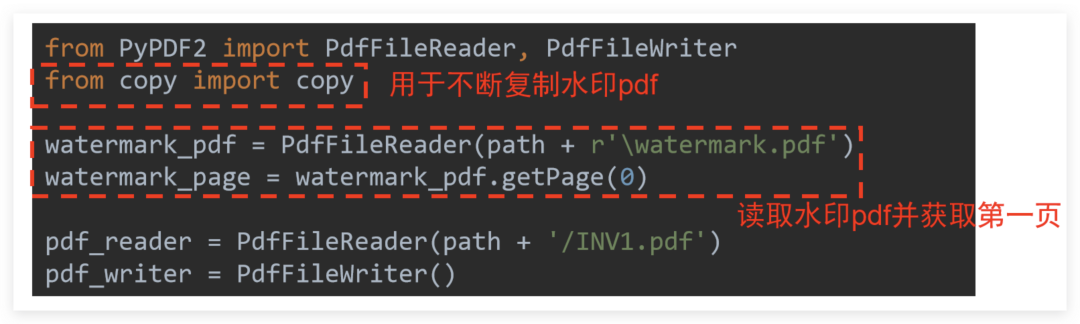
It is to initialize the reader and writer, and read the watermark PDF page first, the core code is a little harder to understand:
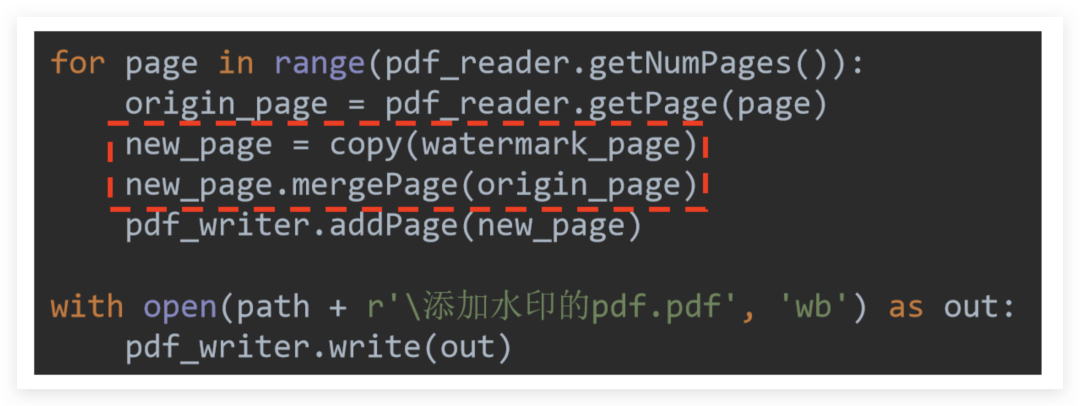
Watermarking is essentially merge the watermarked PDF page and every page that needs to be watermarked
Since the PDF that needs to be watermarked may have many pages, and the watermarked PDF has only one page, if the watermarked PDF is directly merged, it can be abstractly understood as the first page is added, and the watermarked PDF page is gone.**
Therefore cannot be merged directly, but the watermarked PDF page should be continuously copy out into a new page standby new_page, and then use the .mergePage method to complete the merge with each page, and merge the merged PDF page The page is handed over to the writer for final unified output!
Regarding the use of .mergePage: appears on the following page.mergePage (appears on the upper page), the final effect is shown in the figure:

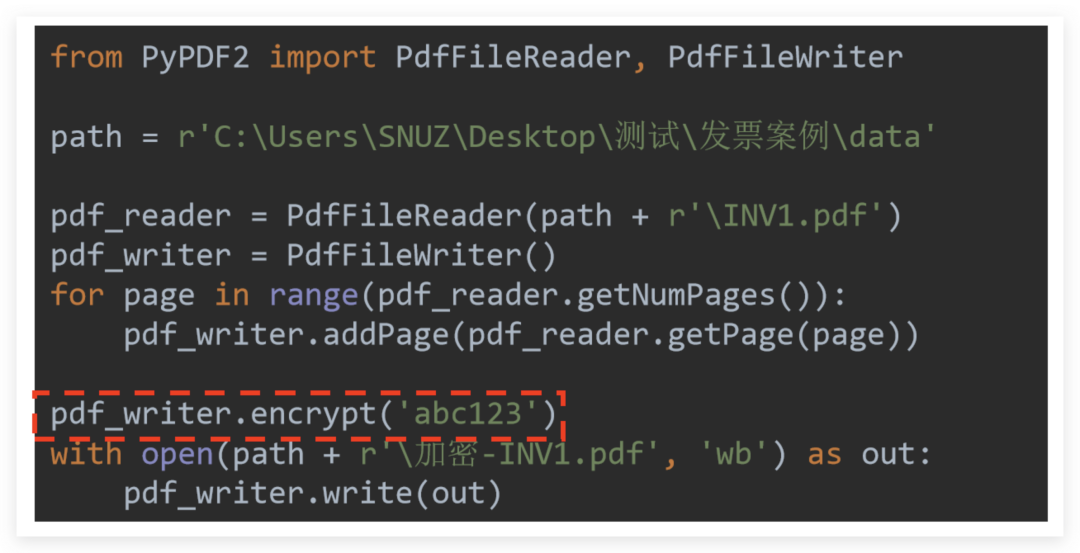
Six, encryption
Encryption is very simple, just remember: "Encryption is for writer encryption"
Therefore, you only need to call pdf_writer.encrypt(password) after the relevant operation is completed
Take the encryption of a single PDF as an example:
Written at the end
Of course, in addition to PDF merging, splitting, encryption, and watermarking, we can also use Python to combine Excel and Word to achieve more automation requirements. These are left to the readers to develop themselves.
Finally, I hope everyone can understand that one of the cores of Python office automation is batch operation-free hands to automate complex tasks!