Python write breakpoint download software
One of the annual python applet programming series-download software for resumable downloading.
1. The principle of HTTP resumable transmission
In fact, the principle of HTTP resumable transmission is relatively simple. In the HTTP data packet, a Range header can be added. This header specifies the requested range in bytes to download the byte stream within the range. Such as:
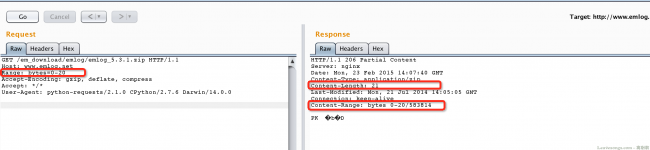
As shown in the above picture, we select the range of the requested content when sending the data packet, and return the packet to get the content of the corresponding length. Therefore, when downloading, we can divide the target file into many "small pieces", and download one small piece at a time (use Range to indicate the range of the small piece) until all the small pieces are downloaded.
When the network is interrupted, or an error causes the download to terminate, we only need to record which "small blocks" have been downloaded and which have not yet been downloaded. When downloading next time, fill in the range of the undownloaded small blocks in Range, so that it can form a resumable upload.
In fact, the same principle applies to multi-threaded downloaders like Thunder. Divide the target file into small pieces, distribute them to different threads to download, and finally integrate and check the integrity.
2. How to download files in Python
We still use the requests library introduced before as the HTTP request library.
Take a look at this document first: http://docs.python-requests.org/en/latest/user/advanced/#body-content-workflow, when steam=True is set at the time of the request, the connection will not be closed immediately, and we read the body in the form of a stream until all the information is read or Response is called. close close the connection.
Therefore, if you want to download a large file, set steam to True and download it slowly instead of waiting for the entire file to be downloaded before returning.
Some students on stackoverflow gave a simple download demo:
def download_file(url):
local_filename = url.split('/')[-1]
# NOTE the stream=True parameter
r = requests.get(url, stream=True)withopen(local_filename,'wb')as f:for chunk in r.iter_content(chunk_size=1024):if chunk: # filter out keep-alive newchunks
f.write(chunk)
f.flush()return local_filename
This is basically our core download code.
3. Resume uploading combined with large file download
Well, let's write a small program combining these two knowledge points: a downloader that supports resumable upload.
We can first consider what points need to be paid attention to, or what functions can be added:
- User customization: cookie, referer, user-agent can be defined. For example, some download sites check the user login before allowing downloads.
- Many servers do not support resumable uploads. How to judge?
- How to express the progress bar?
- How to know the total size of the file? Use HEAD request? What if the server does not support HEAD requests?
- The downloaded file name (there may be a filename in the header, and there is also a filename in the url, and the user can also specify the filename), what should I do? Also consider which characters Windows does not allow for file names.
- How to divide into blocks, whether to join multiple threads.
In fact, thinking about it, there are still many doubts, and some places may not be resolved for a while. First think about the answers to each question:
- headers can be customized by the user
- Before the official download, make a HEAD request to get whether the server status code is 206, and whether there are marks such as Range-content in the header, and judge whether it supports resumable transmission.
- You can not use the progress bar at first, only display the current download size and total size
- Match the total size of the file in the Range-content in the HEAD request, or get the content-length size (the total content-length will be returned when the resumable upload is not supported). If the HEAD request is not supported or there is no content-type, set the total size to 0. (Anyway, it will not hinder the download)
- File name priority: user-defined> content-disposition in header> definition in url. In order to avoid trouble, I am here the same as wget under linux, ignoring the definition of content-disposition. If the user does not specify the saved user name, the content after the last "/" in the url is used as the user name.
- For stability and simplicity, do not do multi-threading. If we don't do multi-threading, we can divide the blocks into smaller ones, such as 1KB, and then download them from the beginning, filling in one K and one K. This avoids a lot of trouble. When the download is interrupted, we only need to simply check how many bytes have been downloaded, and then continue to download from the next byte.
After solving these questions, we started writing. In fact, the questions weren't thought up when I didn't start the pen. They were basically the problems I discovered suddenly when I was halfway through.
def download(self, url, filename, headers ={}):
finished = False
block = self.config['block']
local_filename = self.remove_nonchars(filename)
tmp_filename = local_filename +'.downtmp'if self.support_continue(url): #Support breakpoint resume
try:withopen(tmp_filename,'rb')as fin:
self.size =int(fin.read())+1
except:
self.touch(tmp_filename)finally:
headers['Range']="bytes=%d-"%(self.size,)else:
self.touch(tmp_filename)
self.touch(local_filename)
size = self.size
total = self.total
r = requests.get(url, stream = True, verify = False, headers = headers)if total >0:
print "[+] Size: %dKB"%(total /1024)else:
print "[+] Size: None"
start_t = time.time()withopen(local_filename,'ab')as f:try:for chunk in r.iter_content(chunk_size = block):if chunk:
f.write(chunk)
size +=len(chunk)
f.flush()
sys.stdout.write('\b'*64+'Now: %d, Total: %s'%(size, total))
sys.stdout.flush()
finished = True
os.remove(tmp_filename)
spend =int(time.time()- start_t)
speed =int(size /1024/ spend)
sys.stdout.write('\nDownload Finished!\nTotal Time: %ss, Download Speed: %sk/s\n'%(spend, speed))
sys.stdout.flush()
except:import traceback
print traceback.print_exc()
print "\nDownload pause.\n"finally:if not finished:withopen(tmp_filename,'wb')as ftmp:
ftmp.write(str(size))
This is the download method. First, the if statement calls self.support_continue(url) to determine whether it supports breakpoint resume. If it is supported, read how many bytes have been downloaded from a temporary file. If the file does not exist, an error will be thrown, and the size defaults to 0, indicating that no byte has been downloaded.
Then request the url, get the download connection, and download the for loop. At this time, we have to catch the exception. Once an exception occurs, the program cannot be exited, but the currently downloaded byte size is normally written into the temporary file. Read this file when downloading again next time, set Range to bytes=(size+1)-, which is the range from the next byte of the current byte to the end. Start downloading from this range to achieve a breakpoint resume.
The method of judging whether to support resumable uploading also takes into account a function of obtaining the target file size:
def support_continue(self, url):
headers ={'Range':'bytes=0-4'}try:
r = requests.head(url, headers = headers)
crange = r.headers['content-range']
self.total =int(re.match(ur'^bytes 0-4/(\d+)$', crange).group(1))return True
except:
pass
try:
self.total =int(r.headers['content-length'])
except:
self.total =0return False
Use regular to match the size, get headers['content-length'] directly, and set it to 0.
The core code is basically these, and there are some settings, you can go to github to see directly: https://github.com/phith0n/py-wget/blob/master/py-wget.py
Run to get the latest installation package of emlog:
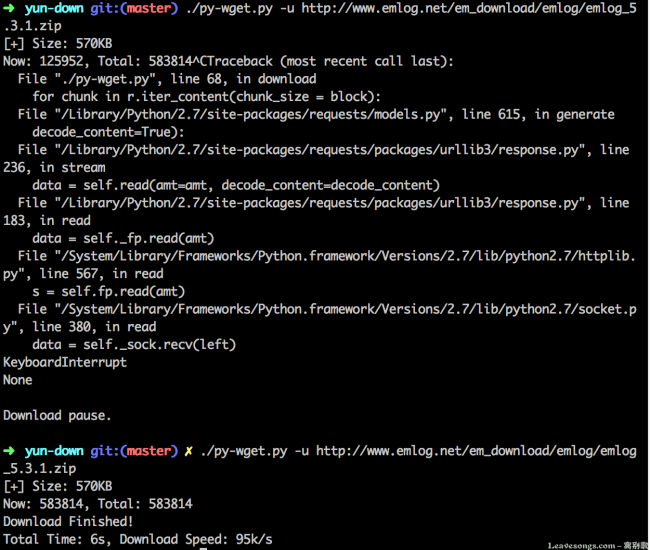
In the middle, I pressed Contrl + C to manually interrupt the download process, but after that I continued to download and realized "breakpoint resumable upload". But in my actual testing process, not so many requests can be resumable, so I deal with the files that do not support resumable transmission: download again.
The downloaded compressed package is decompressed normally, which fully proves the integrity of the download:
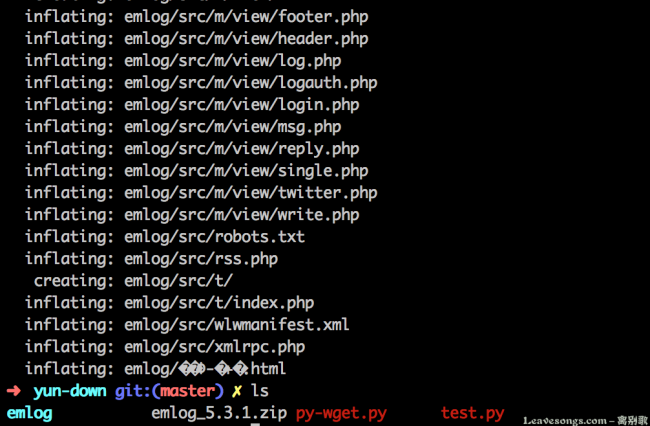
Made a small animation:
If you want to use my little script as a tool, you can check the instructions under github: https://github.com/phith0n/py-wget.
Recommended Posts