Mycat for PXCクラスターを導入し、完全な高可用性クラスターアーキテクチャを構築します
[ MySQL](https://cloud.tencent.com/product/cdb?from=10680)クラスターミドルウェアの比較##
[ CentOS8でのPXCクラスターの構築](https://blog.51cto.com/zero01/2467717)の記事では、3ノードのPXCクラスターを最初から構築する方法を示しています。ただし、実際のエンタープライズアプリケーションでは、複数のPXCクラスターが存在する可能性があり、各クラスターはデータスライスとして存在するため、PXCクラスターを構築するだけでは不十分です。したがって、完全なアーキテクチャでは、データシャーディングや[ロードバランシング](https://cloud.tencent.com/product/clb?from=10680)などの機能を実現するために、クラスタにデータベースミドルウェアを導入する必要もあります。
市場には多くのデータベースミドルウェアがありますが、これらのミドルウェアは主にロードバランシングタイプとデータセグメンテーションタイプの2つのタイプに分けられます(通常、データセグメンテーションタイプにはロードバランシング機能があります)。
-
負荷分散タイプ:
-
Haproxy
-
MySQL - Proxy
-
データセグメンテーションタイプ:
-
MyCat
-
Atlas
-
OneProxy
-
ProxySQL
負荷分散ミドルウェアの役割:
- 負荷分散は要求転送を提供します。これにより、クラスター内の各ノードに要求を均等に転送できるため、単一ノードの負荷が軽減されます。
- クラスタ内の各ノードのリソースを最大限に活用して、クラスタのパフォーマンスを最大限に活用できます
データセグメンテーションミドルウェアの役割:
- さまざまなルーティングアルゴリズムに従ってSQLステートメントを配布し、さまざまなシャードがさまざまなデータを格納できるようにして、データのセグメンテーションを形成します
- 特定のシャードのデータ量がデータベースのストレージ制限を超えないように、データを異なるシャードに均等に保存します。ここでのシャーディングとは、クラスターまたはデータベースノードを指します
以下は、一般的なミドルウェアの比較です。
| 名前 | オープンソースで無料ですか | 負荷容量 | 開発言語 | 機能 | ドキュメント | 人口率 |
|---|---|---|---|---|---|---|
| MyCat | オープンソースおよび無料 | AlibabaのCorbaミドルウェアに基づいて再構築され、トラフィックの多い検査 | Java | 包括的な機能、豊富なシャーディングアルゴリズム、および読み取り/書き込み分離、グローバルプライマリキー、分散トランザクションなどの機能 | ドキュメント豊富な、公式の「Mycat Authoritative Guide」だけでなく、コミュニティから寄稿された多くのドキュメント | 通信やeコマースの分野でのアプリケーションがあり、中国で最も普及率の高いMySQLミドルウェアです |
| Atlas | オープンソースで無料 | MySQLProxyに基づいており、主に360製品に使用されます。毎日数十億のリクエストを処理するアクセス検査があります。 | C言語 | 機能が制限され、読み取りと書き込みの分離を実現し、データセグメンテーションアルゴリズムが少量で、サポートしていませんグローバルプライマリキーと分散トランザクション | ドキュメントが少なく、オープンソースプロジェクトドキュメントのみで、技術コミュニティや出版物はありません | Qihoo 360を除き、一部の中小規模のプロジェクトでのみ使用される普及率が低く、参照するケースは多くありません |
| OneProxy | 無料バージョンとエンタープライズバージョンに分割 | パフォーマンスの高いCベースのカーネル | C言語 | 機能が制限され、読み取りと書き込みの分離が実現され、データセグメンテーションアルゴリズムが少量で、グローバルプライマリキーと分散トランザクションをサポートしていません | ドキュメント公式ウェブサイトにはドキュメントがなく、技術コミュニティや出版物もありません | 浸透率が低く、一部の中小企業の内部システムでのみ使用されています |
| ProxySQL | オープンソースで無料 | Perconaが推奨する優れたパフォーマンス | C ++ | 比較的豊富な機能、読み取り/書き込み分離、データセグメンテーション、フェイルオーバー、クエリキャッシングなどのサポート | 豊富なドキュメント、公式ドキュメント、技術コミュニティ | 普及率をMycatと比較低いですが、多くの企業がそれを使おうとしています |
Mycatデータセグメンテーションを構成します##
前のセクションで紹介して比較した後、MyCatとProxySQLが理想的なデータベースミドルウェアであることがわかります。 ProxySQLと比較して、MyCatはより包括的な機能と高い浸透率を備えているため、MycatはPXCクラスターのミドルウェアとして使用されます。 Mycatの紹介とインストールについては、他の記事[Mycatクイックスタート](https://blog.51cto.com/zero01/2464817)を参照してください。ここでは繰り返されません。
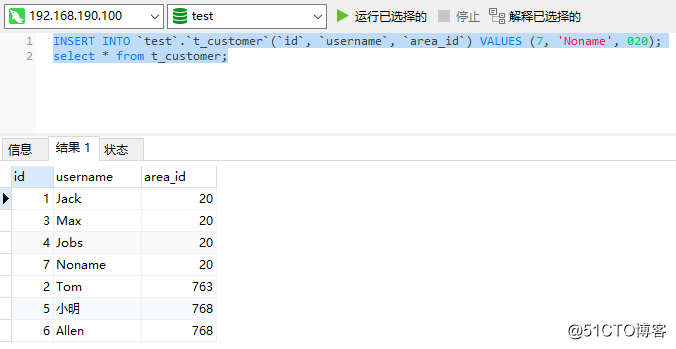
このセクションでは、主にMycatのデータセグメンテーション機能を構成して、Mycatがフロントエンドデータセグメンテーションミドルウェアとして機能し、SQL要求をバックエンドPXCクラスターシャードに転送する方法を紹介します。したがって、ここでは2つのPXCクラスターをセットアップし、各クラスターはシャードであり、後でデュアルシステムホットスタンバイを形成するために2つのMycatノードと2つのHaproxyノードをセットアップします。示されているように:
各ノードの情報は次のとおりです。
| 役割 | ホスト | IP |
|---|---|---|
| Haproxy-Master | Haproxy-Master | 192.168.190.140 |
| Haproxy-Backup | Haproxy-Backup | 192.168.190.141 |
| Mycat:Node1 | mycat-01 | 192.168.190.136 |
| Mycat:Node2 | mycat-02 | 192.168.190.135 |
| PXCフラグメント-1:Node1 | PXC-Node1 | 192.168.190.132 |
| PXCフラグメント-1:Node2 | PXC-Node2 | 192.168.190.133 |
| PXCフラグメント-1:Node3 | PXC-Node3 | 192.168.190.134 |
| PXCフラグメント-2:Node1 | PXC-Node1 | 192.168.190.137 |
| PXCフラグメント-2:Node2 | PXC-Node2 | 192.168.190.138 |
| PXCフラグメント-2:Node3 | PXC-Node3 | 192.168.190.139 |
各シャードに testライブラリを作成し、テスト用にライブラリに t_userテーブルを作成します。具体的なテーブル作成SQLは次のとおりです。
CREATE TABLE `t_user`(`id`int(11) NOT NULL,`username`varchar(20) NOT NULL,`password`char(36) NOT NULL,`tel`char(11) NOT NULL,`locked`char(10) NOT NULL,
PRIMARY KEY(`id`),
UNIQUE KEY `idx_username`(`username`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
上記の準備が完了したら、Mycatの構成を開始します。Mycatの構成ファイルがわからない場合は、他の記事[Mycatコア構成の詳細](https://blog.51cto.com/zero01/2465837)を参照してください。この記事では繰り返しません。
1、 server.xmlファイルを編集し、Mycatのアクセスユーザーを構成します。
< user name="admin" defaultAccount="true"><property name="password">Abc_123456</property><property name="schemas">test</property><property name="defaultSchema">test</property></user>
2、 schema.xmlファイルを編集して、Mycatロジックライブラリ、ロジックテーブル、およびクラスターノードの接続情報を構成します。
<? xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><!--ロジックライブラリを構成する--><schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1"><!--構成ロジックテーブル--><table name="t_user" dataNode="dn1,dn2" rule="mod-long"/></schema><!--データの断片化を構成します。各フラグメントには、0から始まるインデックス値があります。たとえば、dn1のインデックス値は0、dn2のインデックス値は1などです。--><!--フラグメントのインデックスはフラグメントアルゴリズムに関連しており、フラグメントアルゴリズムによって計算された値はフラグメントインデックスです。--><dataNode name="dn1" dataHost="pxc-cluster1" database="test"/><dataNode name="dn2" dataHost="pxc-cluster2" database="test"/><!--クラスターノードの接続情報を構成する--><dataHost name="pxc-cluster1" maxCon="1000" minCon="10" balance="2"
writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="W1" url="192.168.190.132:3306" user="admin"
password="Abc_123456"><readHost host="W1-R1" url="192.168.190.133:3306" user="admin" password="Abc_123456"/><readHost host="W1-R2" url="192.168.190.134:3306" user="admin" password="Abc_123456"/></writeHost><writeHost host="W2" url="192.168.190.133:3306" user="admin"
password="Abc_123456"><readHost host="W2-R1" url="192.168.190.132:3306" user="admin" password="Abc_123456"/><readHost host="W2-R2" url="192.168.190.134:3306" user="admin" password="Abc_123456"/></writeHost></dataHost><dataHost name="pxc-cluster2" maxCon="1000" minCon="10" balance="2"
writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="W1" url="192.168.190.137:3306" user="admin" password="Abc_123456"><readHost host="W1-R1" url="192.168.190.138:3306" user="admin" password="Abc_123456"/><readHost host="W1-R2" url="192.168.190.139:3306" user="admin" password="Abc_123456"/></writeHost><writeHost host="W2" url="192.168.190.138:3306" user="admin" password="Abc_123456"><readHost host="W2-R1" url="192.168.190.137:3306" user="admin" password="Abc_123456"/><readHost host="W2-R2" url="192.168.190.138:3306" user="admin" password="Abc_123456"/></writeHost></dataHost></mycat:schema>
3、 rule.xmlファイルを編集し、 mod-longフラグメンテーションアルゴリズムのモジュラスカーディナリティを変更します。フラグメントとしてのクラスターは2つしかないため、カーディナリティを 2に変更する必要があります。
< tableRule name="mod-long"><rule><columns>id</columns><algorithm>mod-long</algorithm></rule></tableRule><function name="mod-long"class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function>
- **ヒント:**フラグメンテーションアルゴリズムは、テーブルの
id列の値を使用してモジュラスベースを変調し、データフラグメントのインデックスを取得します
上記の3つのファイルの構成が完了したら、Mycatを起動します。
[ root@mycat-01~]# mycat start
Starting Mycat-server...[root@mycat-01~]# more /usr/local/mycat/logs/wrapper.log |grep successfully
# ログ出力は、起動が成功したことを示しています
INFO | jvm 1|2020/01/1915:09:02| MyCAT Server startup successfully. see logs in logs/mycat.log
テスト###
起動が完了したら、Mycatと入力して挿入ステートメントを実行し、SQLを正しいクラスターシャードに転送できるかどうかをテストします。具体的な手順は次のとおりです。
[ root@mycat-01~]# mysql -uadmin -P8066 -h127.0.0.1-p
mysql> use test;
mysql> insert into t_user(id, username, password, tel, locked)->values(1,'Jack',hex(AES_ENCRYPT('123456','Test')),'13333333333','N');
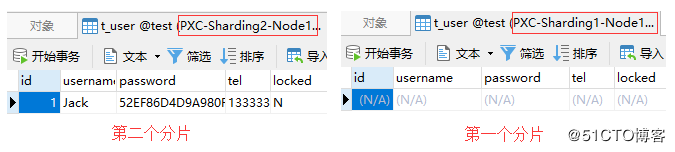
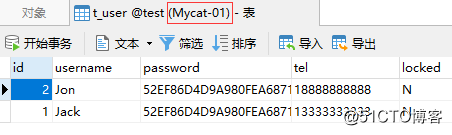
上記の insertステートメントは idを 1としてレコードを挿入し、 id列を変調するフラグメンテーションアルゴリズムを使用します。構成されたモジュラスベースは 2です。したがって、 idの値とモジュロベースに基づくモジュロ計算の結果は次のようになります。1%2 = 1。結果の 1はシャードのインデックスであるため、通常の状況では、Mycatは insertステートメントをシャードインデックスが 1のクラスターに転送します。
schema.xmlファイルの構成によると、インデックスが 1のシャードに対応するクラスターは、2番目のPXCクラスターシャードである pxc-cluster2です。次に、2つのクラスターのデータを比較して、MycatがSQLを期待どおりに正しく転送したかどうかを確認できます。
次の図からわかるように、Mycatは insertステートメントを2番目のシャードに正しく転送しました。現時点では、最初のシャードにはデータがありません。
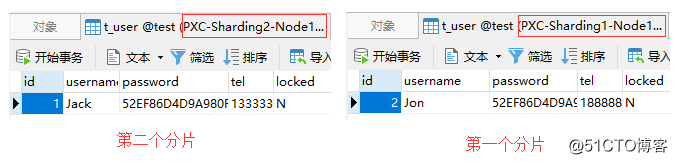
次に、 idが 2のときに、MycatがSQLを最初のシャードに転送できるかどうかをテストします。具体的なSQLは次のとおりです。
insert into t_user(id, username, password, tel, locked)values(2,'Jon',hex(AES_ENCRYPT('123456','Test')),'18888888888','N');
テスト結果を図に示します。
上記のテストを完了した後、この時点ですべてのシャードのデータをMycatで照会できます。
一般的に使用される4つのデータセグメンテーションアルゴリズム##
プライマリキーモジュラスセグメンテーション###
前のセクションの例では、プライマリキーモジュラーセグメンテーションが使用されており、その特性は次のとおりです。
- プライマリキーモジュロセグメンテーションは、初期データが大きいがデータが急速に増加していないシナリオに適しています。たとえば、製品、管理データ、企業データなどをマップします。
- プライマリキーモジュラーセグメンテーションの欠点は、新しいセグメントを拡張することが難しく、移行されるデータが多すぎることです。
- フラグメントの数を拡張する必要がある場合は、拡張されたフラグメントの数を元のフラグメントの2n倍にすることをお勧めします。たとえば、元々は2つのシャードでしたが、拡張後は4つのシャードになります。
プライマリキー範囲のセグメンテーション###
- プライマリキー範囲のセグメンテーションは、データが急速に増加しているシナリオに適しています
- シャーディングを増やすのは簡単で、明確なプライマリキー列が必要です
日付のセグメンテーション###
- 日付のセグメンテーションは、データが急速に増加しているシナリオに適しています
- シャードを追加するのは簡単で、明確な日付列が必要です
列挙値のセグメンテーション###
- 列挙値のセグメンテーションは、データが分類および保存されるシナリオに適しており、ほとんどのビジネスに適しています
- 列挙値のセグメンテーションは、特定のフィールドの値(数値)と
mapFileの構成との間のマッピング関係に従ってデータを分割します - 列挙値セグメンテーションの欠点は、シャードに格納されているデータが十分に均一でないことです。
記事[Mycatコア構成の詳細](https://blog.51cto.com/zero01/2465837)では、列挙値セグメンテーションアルゴリズムも紹介されています。他のアルゴリズムと比較して、このアルゴリズムは追加のマッピングファイル( mapFile)を使用するため、このアルゴリズムの使用法の簡単なデモンストレーションを次に示します。
**要件:**ユーザーテーブルには、ユーザーが配置されているエリアコードを格納する列があります。この列は、異なるエリアコードのユーザーデータを異なるシャードに格納できるように、シャード列として使用する必要があります。
1、 まず、Mycatの rule.xmlファイルに次の設定を追加します。
<!- - シャーディングルールを定義する--><tableRule name="sharding-by-areafile"><rule><!--シャード列として使用する列を定義します--><columns>area_id</columns><algorithm>area-int</algorithm></rule></tableRule><!--シャーディングアルゴリズムを定義する--><function name="area-int"class="io.mycat.route.function.PartitionByFileMap"><!--confディレクトリにあるmapFileのファイル名を定義します--><property name="mapFile">area-hash-int.txt</property></function>
2、 confディレクトリに area-hash-int.txtファイルを作成して、エリアコードとフラグメントインデックス間の対応を定義します。
[ root@mycat-01/usr/local/mycat]# vim conf/area-hash-int.txt
020=00755=00757=00763=10768=10751=1
3、 schema.xmlを構成し、論理テーブルを追加して、そのシャーディングルールを sharding-by-areafileに設定します。
< schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1"><table name="t_user" dataNode="dn1,dn2" rule="mod-long"/><table name="t_customer" dataNode="dn1,dn2" rule="sharding-by-areafile"/></schema>
4、 Mycatと入力して、ホットリロードステートメントを実行します。これにより、Mycatは再起動せずに新しい構成を適用できます。
[ root@mycat-01~]# mysql -uadmin -P9066 -h127.0.0.1-p
mysql> reload @@config_all;
テスト####
上記の構成が完了したら、テーブルを作成してテストし、すべてのクラスターに t_customerテーブルを作成しましょう。特定のテーブルSQLは次のとおりです。
create table t_customer(
id int primary key,
username varchar(20) not null,
area_id int not null);
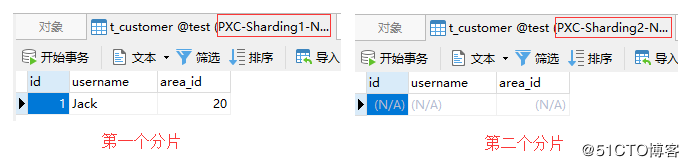
area_idを 020としてMycatにレコードを挿入します。
[ root@mycat-01~]# mysql -uadmin -P8066 -h127.0.0.1-p
mysql> use test;
mysql> insert into t_customer(id, username, area_id)->values(1,'Jack',020);
マッピングファイルの構成に従って、以下に示すように、 area_idが 020のデータが最初のシャードに格納されます。
- **ヒント:**ここでは、
area_idはint型であるため、前の0は削除されます
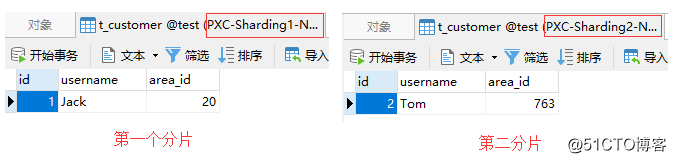
次に、 area_idを 0763としてレコードを挿入します。
insert into t_customer(id, username, area_id)values(2,'Tom',0763);
マッピングファイルの構成に従って、以下に示すように、 area_idが 0763のデータが2番目のシャードに格納されます。
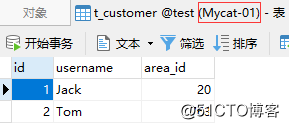
上記のテストを完了した後、この時点ですべてのシャードのデータをMycatで照会する必要があります。
父と息子のテーブル##
関連データが異なるシャードに保存されている場合、テーブル結合の問題が発生します。Mycatでは、シャード間でテーブル結合クエリを実行することは許可されていません。クロスシャーディングテーブル接続の問題を解決するために、Mycatは親子テーブルのソリューションを提案しました。
親子テーブルでは、親テーブルに任意のセグメンテーションアルゴリズムを設定できますが、それに関連付けられた子テーブルにセグメンテーションアルゴリズムを設定することはできません。つまり、子テーブルのデータは常に親テーブルのデータと同じスライスに格納されます。親テーブルに使用されるセグメンテーションアルゴリズムに関係なく、子テーブルは常に親テーブルの後に格納されます。
たとえば、ユーザーテーブルと注文テーブルは関連しています。ユーザーテーブルを親テーブルとして使用し、注文テーブルを子テーブルとして使用できます。ユーザーAがシャード1に格納されている場合、ユーザーAによって生成された注文データもシャード1に格納されるため、ユーザーAの注文データを照会するときにシャードをクロスする必要はありません。以下に示すように:

練習###
親子テーブルの概念を理解した後、Mycatで親子テーブルを構成する方法を見てみましょう。まず、 schema.xmlファイルで親子テーブルの関係を構成します。
< schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1"><table name="t_customer" dataNode="dn1,dn2" rule="sharding-by-areafile"><!--構成サブテーブル--><childTable name="t_orders" joinKey="customer_id" parentKey="id"/></table></schema>
childTableラベルの説明:
joinKey属性:子テーブルの親テーブルを関連付けるために使用される列を定義しますparentKey属性:親テーブルの関連する列を定義します引き続き、childTableタグにchildTableタグを追加できます
上記の構成が完了したら、Mycatに構成ファイルを再ロードさせます。
reload @@config_all;
テスト###
次に、すべてのシャードに t_ordersテーブルを作成します。具体的なテーブル作成SQLは次のとおりです。
create table t_orders(
id int primary key,
customer_id int not null,
create_time datetime default current_timestamp
);
これで、シャードに2人のユーザーが存在し、「id」が「1」のユーザーが最初のシャードに格納され、「id」が「2」のユーザーが2番目のシャードに格納されます。この時点で、Mycatを介して注文レコードを挿入します。
insert into t_orders(id, customer_id)values(1,1);
注文レコードはIDが 1のユーザーに関連付けられているため、親子テーブルの規定に従って最初のシャードに格納されます。以下に示すように:
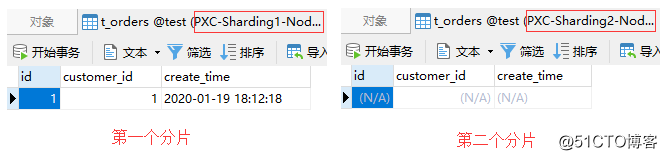
同様に、注文レコードがIDが「2」のユーザーに関連付けられている場合、2番目のシャードに保存されます。
insert into t_orders(id, customer_id)values(2,2);
テスト結果は次のとおりです。
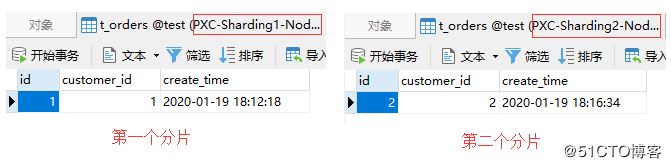
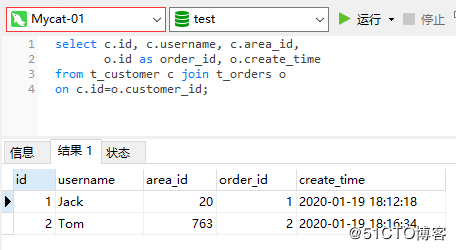
親テーブルと子テーブルのデータは同じシャードに格納されているため、Mycatの関連するクエリに問題はありません。
デュアルシステムのホットバックアップを使用して、可用性の高いMycatクラスターを確立します##
序文###
上記のセクションの例では、バックエンドデータベースクラスターでの読み取りおよび書き込み操作がすべてMycatで実行されていることがわかります。 Mycatは、クライアント要求の受信とバックエンドデータベースクラスターへの要求の転送を担当するミドルウェアとして、必然的に高い可用性を必要とします。そうしないと、Mycatに単一の障害が発生した場合、データベースクラスター全体が使用できなくなり、システム全体に大きな影響を及ぼします。
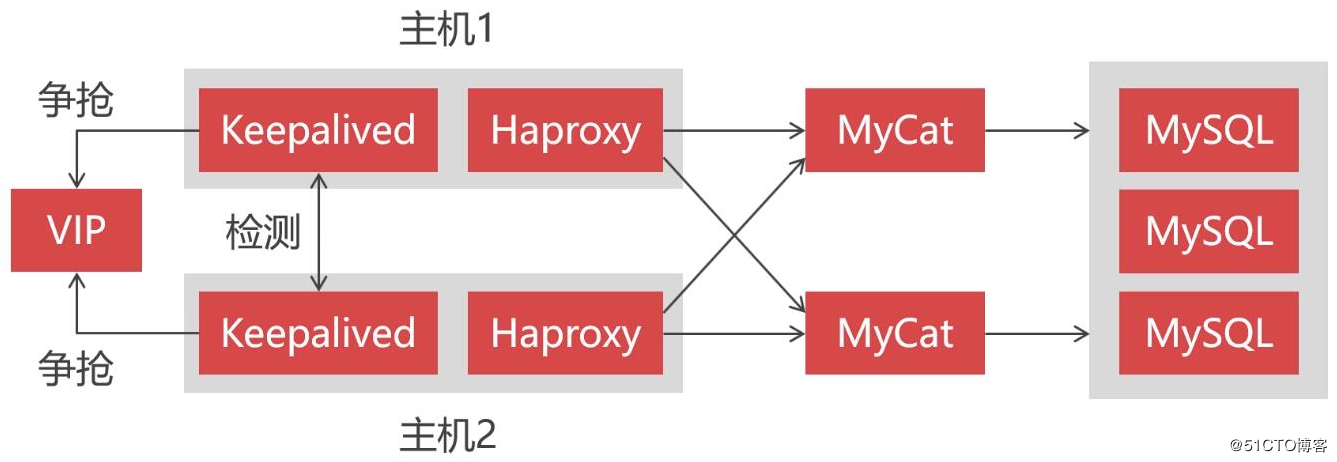
したがって、このセクションでは、可用性の高いMycatクラスターを構築する方法を示します。Mycatの可用性の高いクラスターを構築するには、3つ以上のMycatノードがあることに加えて、HaproxyコンポーネントとKeepalivedコンポーネントを導入する必要があります。
その中で、負荷分散コンポーネントとしてのHaproxyは、クライアントリクエストを受信し、各Mycatノードにリクエストを配信して、Mycatの高可用性を確保するために最前線に配置されています。 Keepalivedは、デュアルシステムのホットバックアップを実装するために使用されます。これは、Haproxyも高い可用性を備えている必要があるためです。1つのHaproxyがダウンすると、別のスタンバイHaproxyがすぐに引き継ぐことができます。つまり、1つのHaproxyのみが同時に実行され、もう1つのHaproxyがバックアップとして待機しています。実行中のHaproxyが予期せずダウンした場合、KeepalivedはスタンバイHaproxyを実行状態にすぐに切り替えることができます。
Keepalivedを使用すると、ホストは同じ仮想IP(VIP)をめぐって競合し、高可用性を実現できます。これらのホストは、マスターとバックアップの2つの役割に分けられ、マスターは1つだけですが、バックアップは複数持つことができます。最初に、マスターはVIPが実行されていることを取得します。マスターがダウンすると、バックアップはマスターを検出できない場合に自動的にVIPを取得します。この時点で、VIPに送信された要求はバックアップによって受信されます。このようにして、バックアップはマスターの作業をシームレスに引き継ぎ、高い可用性を実現できます。
これらのコンポーネントを導入した後、クラスターアーキテクチャは最終的に次のように進化します。
Haproxy ###をインストールします
Haproxyは旧ブランドの負荷分散コンポーネントであるため、このコンポーネントのインストールパッケージはCentOSの yumリポジトリに含まれており、インストールは非常に簡単です。インストールコマンドは次のとおりです。
[ root@Haproxy-Master ~]# yum install -y haproxy
Haproxyの構成:
[ root@Haproxy-Master ~]# vim /etc/haproxy/haproxy.cfg
# ファイルの最後に次の構成項目を追加します
# インターフェイス構成の監視
listen admin_stats
# バインドされたIPとリスニングポート
bind 0.0.0.0:4001
# アクセス契約
mode http
# URI相対アドレス
stats uri /dbs
# 統計レポート形式
stats realm Global\ statistics
# 監視インターフェイスへのログインに使用されるアカウントパスワード
stats auth admin:abc123456
# データベースの負荷分散構成
listen proxy-mysql
# バインドされたIPとリスニングポート
bind 0.0.0.0:3306
# アクセス契約
mode tcp
# 負荷分散アルゴリズム
# ラウンドロビン:ポーリング
# static-rr:重量
# 最小接続:最小接続
# ソース:リクエストソースIP
balance roundrobin
# ログ形式
option tcplog
# 負荷分散が必要なホスト
server mycat_01 192.168.190.136:8066 check port 8066 weight 1 maxconn 2000
server mycat_02 192.168.190.135:8066 check port 8066 weight 1 maxconn 2000
# キープアライブを使用してデッドリンクを検出する
option tcpka
3306ポートは TCP転送用に構成され、 4001はHaproxy監視インターフェイスのアクセスポートとして構成されているため、次の2つのポートをファイアウォールで開く必要があります。
[ root@Haproxy-Master ~]# firewall-cmd --zone=public--add-port=3306/tcp --permanent
[ root@Haproxy-Master ~]# firewall-cmd --zone=public--add-port=4001/tcp --permanent
[ root@Haproxy-Master ~]# firewall-cmd --reload
上記の手順を完了したら、Haproxyサービスを開始します。
[ root@Haproxy-Master ~]# systemctl start haproxy
次に、ブラウザを使用してHaproxyの監視インターフェイスにアクセスします。初めてアクセスするときに、ユーザー名とパスワードを入力するように求められます。ユーザー名とパスワードは、構成ファイルで構成されています。
正常にログインすると、次のページが表示されます。
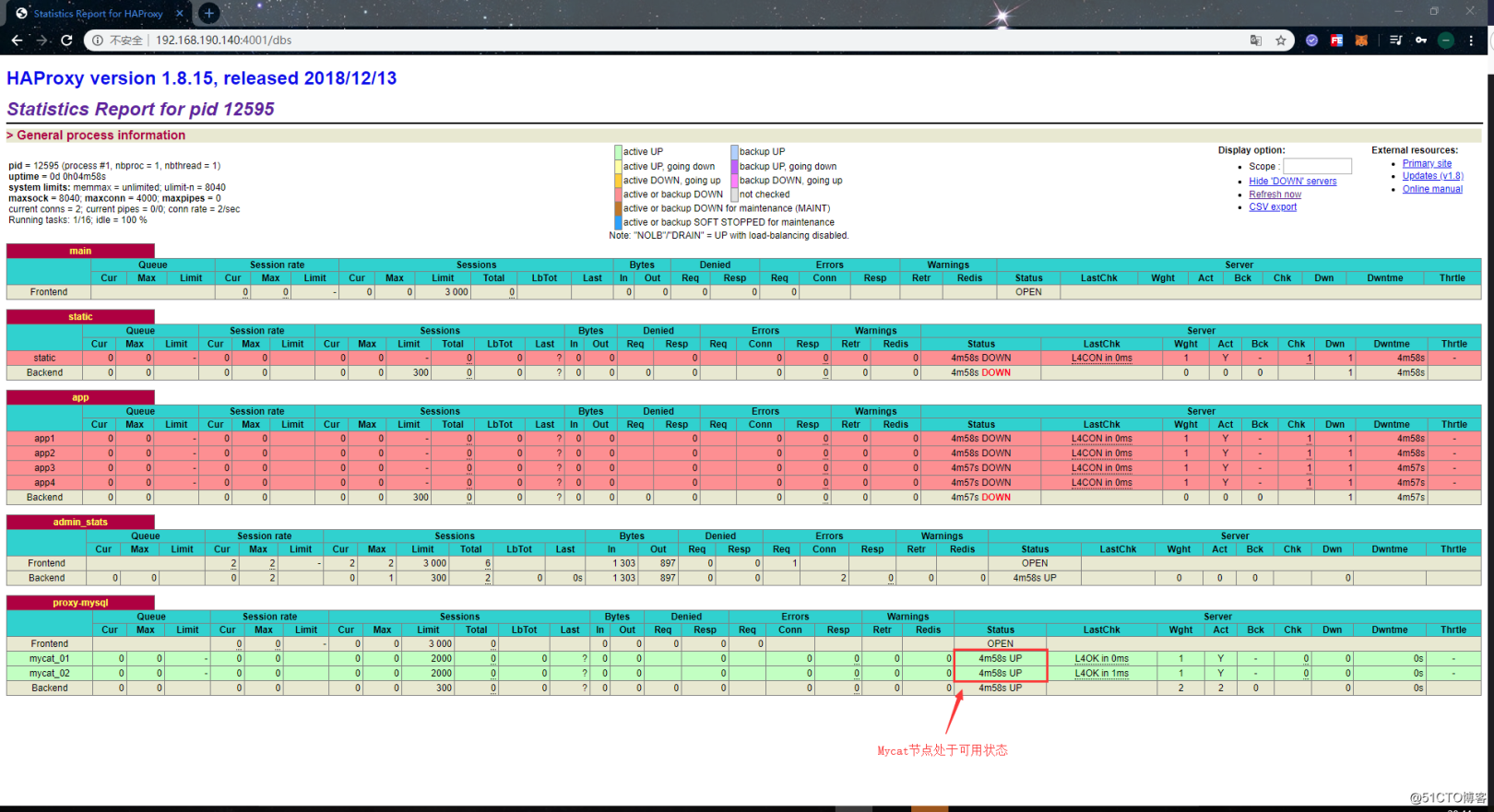
Haproxyの監視インターフェースによって提供される監視情報も比較的包括的です。このインターフェースの下で、各ホストの接続情報とそれ自体のステータスを確認できます。ホストが接続できない場合、「ステータス」の列に「DOWN」と表示され、背景色も赤に変わります。通常状態の値は UPで、背景色は緑です。
別のHaproxyノードもインストールと構成に上記の手順を使用するため、ここでは繰り返しません。
Haproxy ###をテストします
Haproxyサービスを設定したら、リモートツールを使用して、Haproxyを介してMycatに正常に接続できるかどうかをテストしましょう。次のように:
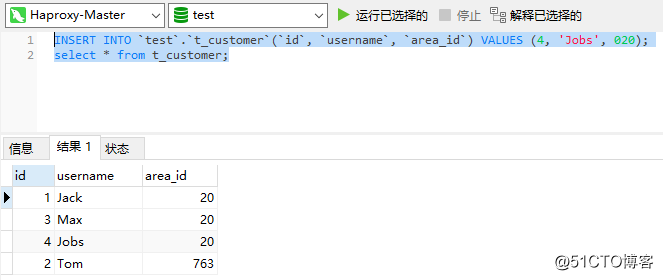
接続が成功したら、HaproxyでいくつかのSQLステートメントを実行して、データを挿入し、データを正常に照会できるかどうかを確認します。
Mycatの可用性を高めるためにHaproxyを構築したので、最後にMycatの可用性が高いかどうかをテストし、最初にMycatノードを停止します。
[ root@mycat-01~]# mycat stop
Stopping Mycat-server...
Stopped Mycat-server.[root@mycat-01~]#
この時点で、Haproxyの監視インターフェイスから、ノード mycat_01がすでにオフラインになっていることがわかります。

これで、クラスターにMycatノードが1つ残った後、HaproxyでいくつかのSQLステートメントを実行して、データを挿入し、データを正常に照会できるかどうかを確認します。
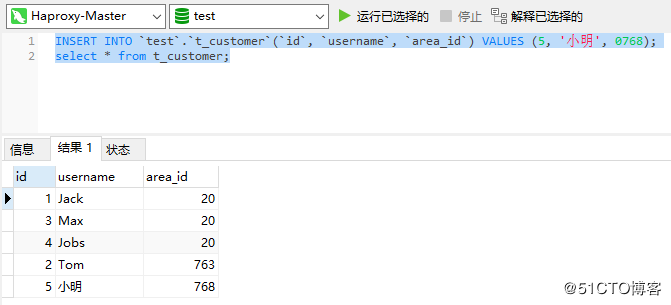
テスト結果からわかるように、挿入ステートメントとクエリステートメントは引き続き正常に実行できます。つまり、この時点で1つのMycatノードがオフになっている場合でも、データベースクラスター全体を正常に使用でき、Mycatクラスターの可用性が高いことを示しています。
Keepalivedを使用して、Haproxy ###の高可用性を実現します
Mycatクラスターの高可用性を達成した後、現在のアーキテクチャが最初のMycatクライアント指向からHaproxyクライアント指向に変更されたため、Haproxyの高可用性を達成する必要があります。
同時に、使用可能なHaproxyは1つだけです。そうしないと、クライアントはどのHaproxyに接続するかがわかりません。これがVIPが使用される理由でもあります。このメカニズムにより、複数のノードが相互に引き継ぐときに同じIPを使用でき、クライアントは最初から最後までこのVIPに接続するだけで済みます。したがって、Haproxyの高可用性を実現するには、Keepalivedが登場する番です。Keepalivedをインストールする前に、ファイアウォールのVRRPプロトコルを有効にする必要があります。
[ root@Haproxy-Master ~]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0--protocol vrrp -j ACCEPT
[ root@Haproxy-Master ~]# firewall-cmd --reload
次に、 yumコマンドを使用してKeepalivedをインストールできます。KeepalivedはHaproxyノードにインストールされていることに注意してください。
[ root@Haproxy-Master ~]# yum install -y keepalived
インストールが完了したら、keepalivedの構成ファイルを編集します。
[ root@Haproxy-Master ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak #組み込みの構成ファイルは使用しないでください
[ root@Haproxy-Master ~]# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER
interfaceens32
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456}
virtual_ipaddress {192.168.190.100}}
構成手順:
-
state MASTER:ノードの役割をマスターとして定義します。役割がマスターの場合、ノードは競合することなくVIPを取得できます。クラスターには複数のマスターが許可されています。複数のマスターが存在する場合、マスターはVIPを競う必要があります。他の役割の場合、VIPはマスターがオフラインのときにのみ取得できます -
interface ens32:外部通信に使用できるネットワークカードの名前を定義します。ネットワークカードの名前は、ipaddrコマンドで表示できます。 -
virtual_router_id 51:仮想ルートのIDを定義します。値は0〜255です。各ノードの値は一意である必要があります。つまり、同じになるように構成することはできません。 -
優先度100:重みを定義します。重みが大きいほど、VIPを取得する優先度が高くなります。 -
advert_int 1:検出間隔を1秒として定義します -
authentication:ハートビートチェックで使用される認証情報を定義します -
auth_type PASS:認証タイプをパスワードとして定義します -
auth_pass 123456:特定のパスワードを定義します -
virtual_ipaddress:仮想IP(VIP)を定義します。これは、同じネットワークセグメントの下のIPである必要があり、各ノードは一貫している必要があります
上記の構成が完了したら、keepalivedサービスを開始します。
[ root@Haproxy-Master ~]# systemctl start keepalived
keepalivedサービスが正常に開始されたら、 ip addrコマンドを使用して、ネットワークカードにバインドされている仮想IPを表示します。
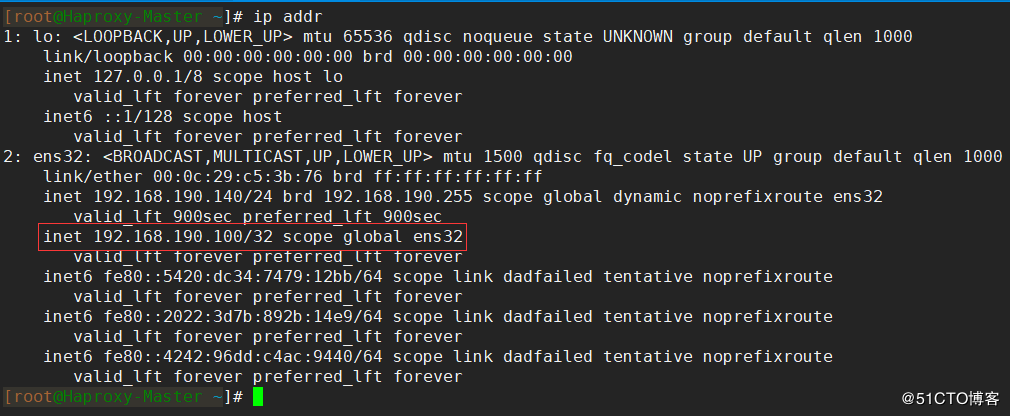
他のノードも上記の手順を使用してインストールおよび構成されているため、ここでは繰り返しません。
Keepalived ###をテストします
上記では、Keepalivedのインストールと構成が完了しました。最後に、Keepalivedサービスが正常に利用可能かどうか、およびHaproxyの可用性が高いかどうかをテストします。
まず、仮想IPが他のノードで正常にpingできるかどうかをテストします。pingできない場合は、構成を確認する必要があります。図に示すように、通常、ここで「ping」を実行できます。
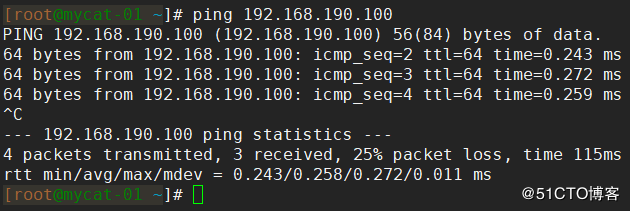
一般的な仮想IPpingの失敗:
- ファイアウォールの構成が正しくなく、VRRPプロトコルが正しく開かれていません
- 構成された仮想IPは、他のノードのIPと同じネットワークセグメントにありません
- Keepalivedが正しく構成されていないか、Keepalivedがまったく正常に起動しませんでした
Keepalived仮想IPが外部の pingから通信できることを確認したら、Navicatを使用して、仮想IPを介してMycatに接続できるかどうかをテストします。
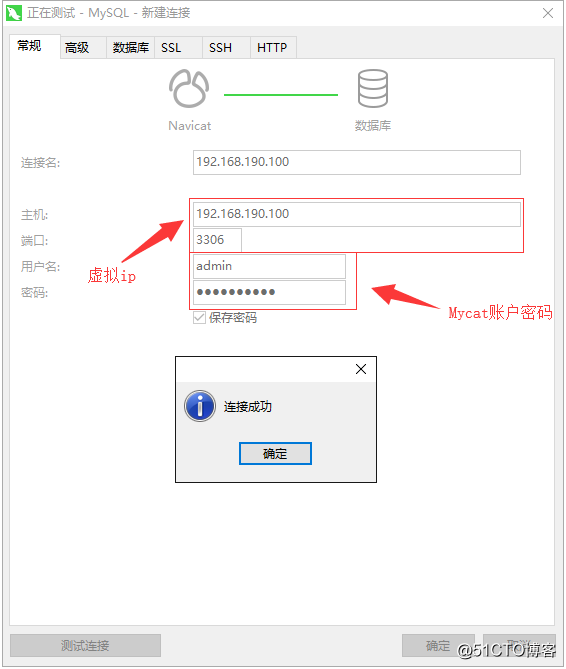
接続が成功したら、いくつかのステートメントを実行して、データを挿入して正常にクエリできるかどうかをテストします。
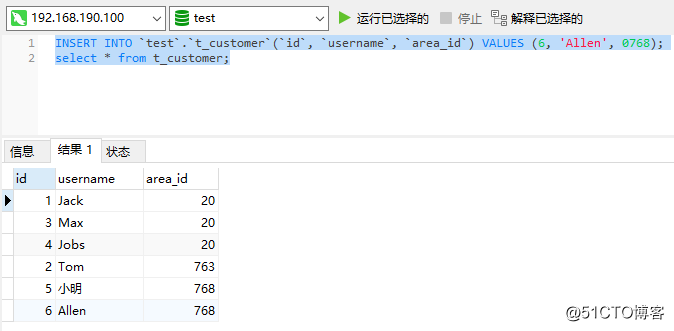
この時点では、基本的に問題はありません。最後に、Haproxyの高可用性をテストし、Haproxyノードの1つでkeepalivedサービスをオフにします。
[ root@Haproxy-Master ~]# systemctl stop keepalived
次に、いくつかのステートメントを再度実行して、データを挿入して正常にクエリできるかどうかをテストします。以下は正常に実行できます。これは、Haproxyノードの可用性が高いことを意味します。