可用性の高いレプリケーションクラスターを構築して、大量のコールドデータをアーカイブします
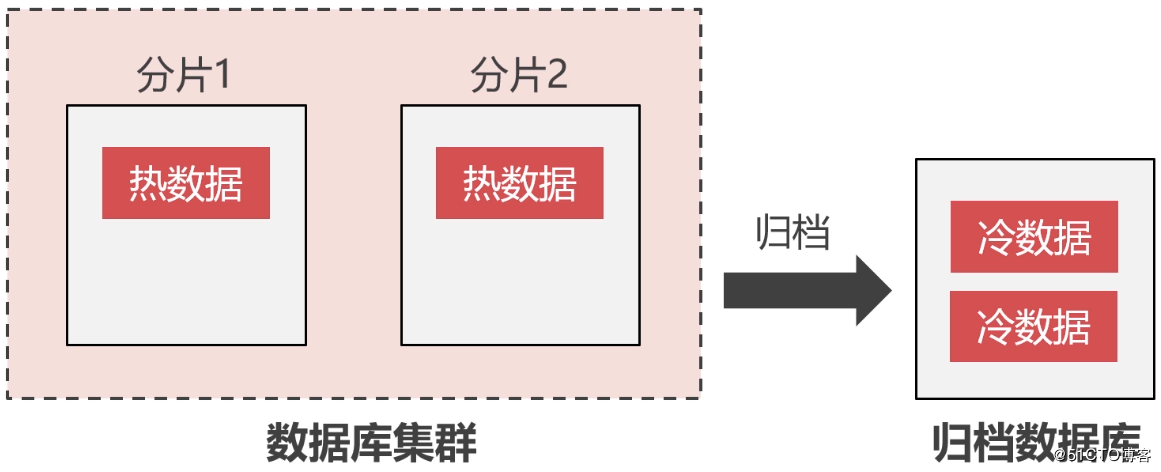
ホットデータとコールドデータの分離##
ビジネスは成長を続けており、クラスターシャード内のデータは時間の経過とともに増加します。注文レコード、トランザクションレコード、製品レビュー、その他の数年前のデータなど、データのかなりの部分がほとんど使用されません。 。データのこの部分はコールドデータと呼ばれ、頻繁に使用されるデータはホットデータと呼ばれます。
[MySQL](https://cloud.tencent.com/product/cdb?from=10680)の単一テーブルのデータ量が2,000万を超えると、読み取りと書き込みのパフォーマンスが大幅に低下することは誰もが知っています。保存されているデータのほとんどが価値の高いホットデータである場合、これらのデータは利点をもたらす可能性があるため、クラスターシャーディングを拡張するためにお金を費やすことができると言ったほうがよいでしょう。しかし、それが価値の低いコールドデータである場合、このお金を使う必要はありません。
したがって、コールドデータをクラスターシャードから分離し、専用のアーカイブデータベースに保存して、ストレージスペースを解放し、クラスターシャードのストレージ圧力を軽減する必要があります。クラスターシャードに可能な限りホットデータのみを保存させて、コールドデータのストレージスペースを無駄にすることなく、読み取りと書き込みのパフォーマンスを向上させます。
InnoDBの瞬間的な書き込みパフォーマンスは高くないため、アーカイブデータベースでInnoDBエンジンを使用することは適していません。 Perconaが作成した[TokuDB](https://www.percona.com/software/mysql-database/percona-tokudb)は、通常、アーカイブデータベースのストレージエンジンとして使用されます。エンジンには次の特性があるためです。
- 高い圧縮率、高い書き込みパフォーマンス
- オンラインでインデックスとフィールドを作成できます
- トランザクション機能のサポート
- マスタースレーブ同期をサポート
レプリケーションクラスターのセットアップ##
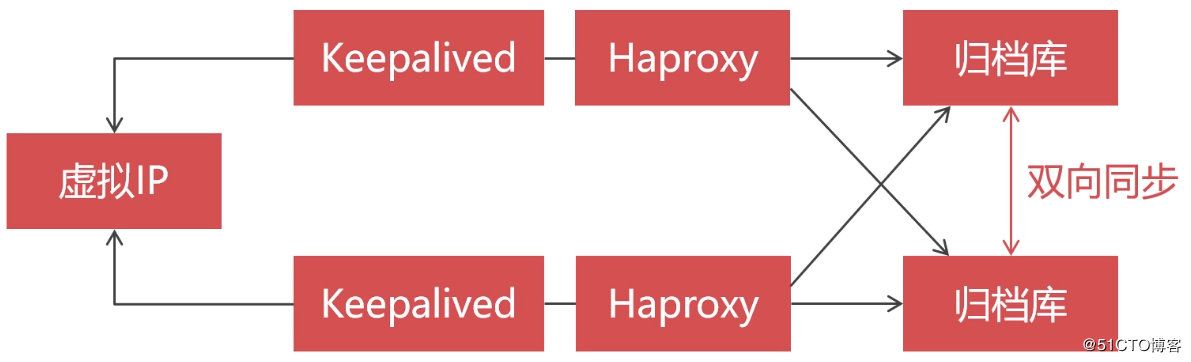
前のセクションでは、ホットデータとコールドデータの分離の概念を紹介しました。このセクションでは、コールドデータをアーカイブするための可用性の高いレプリケーションクラスターを構築します。アーカイブライブラリですが、可用性が高い必要があります。結局のところ、実際の企業では、データベース内の単一の障害点は許可されていません。また、アーカイブライブラリ内のデータは使用されませんが、使用される可能性は高くありません。
この記事のレプリケーションクラスターアーキテクチャの設計は次のとおりです。
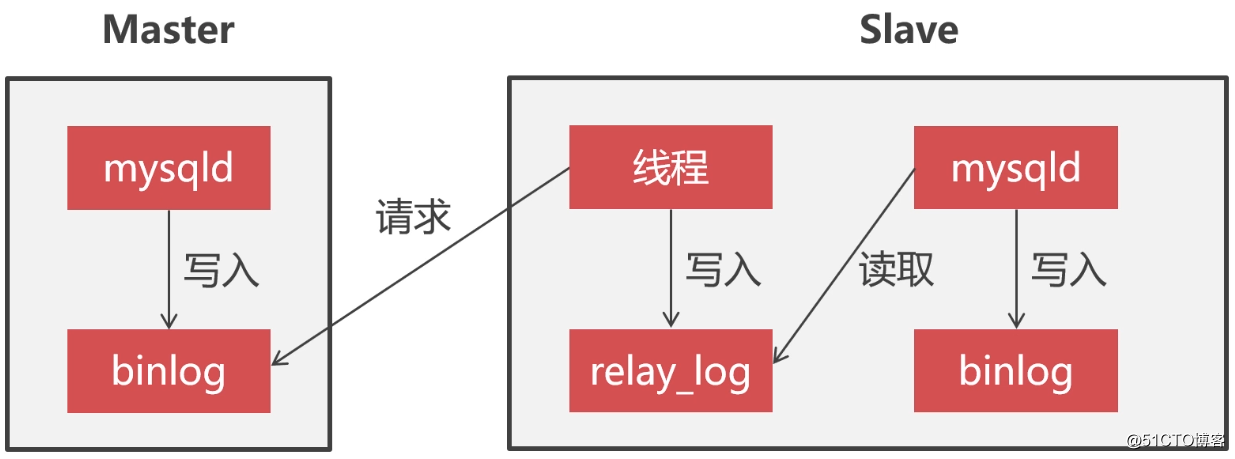
いわゆるレプリケーションクラスターは、私たちがよく言うマスタースレーブアーキテクチャです。レプリケーションクラスターでは、ノードはマスターとスレーブの2つの役割に分けられます。マスターは主に書き込みサービスを提供し、スレーブは読み取りサービスを提供し、通常、スレーブは read_onlyに設定されます。
マスターノードとスレーブノード間のデータ同期は非同期です。スレーブはスレッドを使用してマスターノードの binlogログを監視します。マスターの binlogログが変更されると、スレッドはマスターの binlogログの内容を読み取ります。そしてそれをローカルの relay_logに書き込みます。次に、mysqlプロセスは定期的に relay_logを読み取り、データをローカルの binlogファイルに書き込みます。これにより、マスターとスレーブ間のデータ同期が実現されます。以下に示すように:
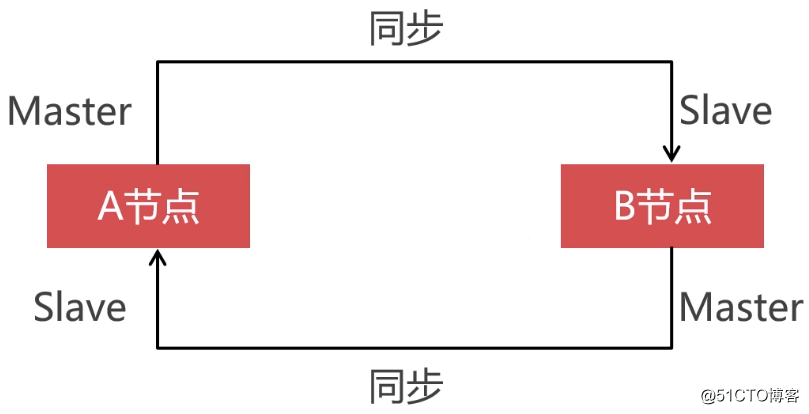
レプリケーションクラスターの高可用性を確保するには、2つのデータベースノードを相互にマスタースレーブ関係にして、双方向のデータ同期を実現する必要があります。このようにして、マスターノードがハングしたときにマスタースレーブ切り替えを実行できます。そうしないと、マスターノードはリカバリ後にスレーブノードとデータを同期せず、ノード間でデータの不整合が発生します。
準備オーケー###
次に、クラスター構築のための事前環境の準備を開始します。最初に、4つの仮想マシンを作成する必要があります。そのうちの2つは、Percona Server for Replicationクラスターとともにインストールされ、2つは、[ロードバランシング](https://cloud.tencent.com/product/clb?from=10680)およびデュアルマシンホットスタンバイ用のHaproxyおよびKeepalivedとともにインストールされます。
| 役割 | ホスト | IP |
|---|---|---|
| Haproxy+Keepalived | HA-01 | 192.168.190.135 |
| Haproxy+Keepalived | HA-02 | 192.168.190.143 |
| Percona Server | node-A | 192.168.190.142 |
| Percona Server | node-B | 192.168.190.131 |
各仮想マシンの構成は次のとおりです。
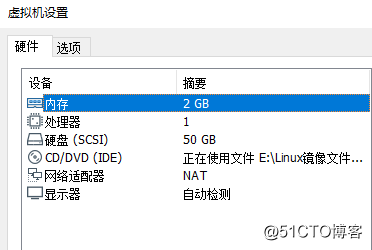
環境バージョンの説明:
- オペレーティングシステム:CentOS 8
- Percona Server:8.0.18
- TokuDB:8.0.18
- Haproxy:1.8.15-5.el8
- Keepalived:2.0.10-4.el8_0.2
TokuDBをインストールします###
InnoDBは、その特性から、アーカイブデータベースのストレージエンジンとして使用する必要があると述べました。 TokuDBは、MySQLの任意の派生物にインストールできます。この記事では、デモとして、MySQLの派生物であるPerconaServerを使用します。
ここでは、2つの仮想マシン 192.168.190.142と 192.168.190.131にすでにPerconaServerをインストールしています。インストール方法がわからない場合は、[Percona Serverデータベースのインストール(CentOS 8)]( https://blog.51cto.com/zero01/2467718)。次に、PerconaServer用のTokuDBをインストールします。
まず、TokuDBをインストールする前に、jemallocライブラリがシステムにすでに存在することを確認してください。存在しない場合は、次のコマンドを使用してインストールできます。
[ root@node-A ~]# yum install -y jemalloc
[ root@node-A ~]# ls /usr/lib64/|grep jemalloc #ライブラリファイルのパス
libjemalloc.so.1[root@node-A ~]#
jemallocライブラリファイルが配置されているパスの構成を構成ファイルに追加します。
[ root@node-A ~]# vim /etc/my.cnf
...[ mysql_safe]
malloc-lib=/usr/lib64/libjemalloc.so.1
構成ファイルの変更が完了したら、データベースサービスを再起動します。
[ root@node-A ~]# systemctl restart mysqld
TokuDBの書き込みパフォーマンスを確保するには、Linuxシステムのラージページメモリ管理設定を調整する必要があります。コマンドは次のとおりです。
# 事前に割り当てられたメモリの代わりに動的に割り当てられたメモリを使用する
[ root@node-A ~]# echo never >/sys/kernel/mm/transparent_hugepage/enabled
# メモリの断片化をオンにします
[ root@node-A ~]# echo never >/sys/kernel/mm/transparent_hugepage/defrag
公式の yumリポジトリからTokuDBエンジンをインストールします。
[ root@node-A ~]# yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
[ root@node-A ~]# percona-release setup ps80
[ root@node-A ~]# yum install -y percona-server-tokudb.x86_64
次に、 ps-adminコマンドを使用して、MySQLにTokuDBエンジンをインストールします。
[ root@node-A ~]# ps-admin --enable-tokudb -uroot -p
データベースサービスを再起動します。
[ root@node-A ~]# systemctl restart mysqld
データベースの再起動が完了したら、 ps-adminコマンドを再度実行して、TokuDBエンジンをアクティブにします。
[ root@node-A ~]# ps-admin --enable-tokudb -uroot -p
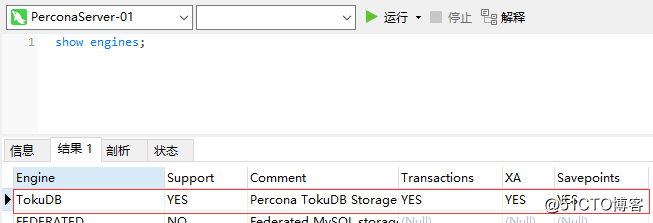
最後に、 showengines;ステートメントを使用してTokuDBエンジンがMySQLに正常にインストールされているかどうかを確認します。
マスターとスレーブの関係を構成します###
まず、2つのノードで同期するためのデータベースアカウントを作成します。
create user 'backup'@'%' identified by 'Abc_123456';
grant super, reload, replication slave on *.* to 'backup'@'%';
flush privileges;
- **ヒント:**アカウントを作成したら、アカウントを使用して2つのノードで相互にログインし、アカウントが使用可能であることを確認する必要があります
次に、MySQL構成ファイルを変更します。
[ root@node-A ~]# vim /etc/my.cnf
[ mysqld]
# ノードのIDを設定します
server_id=101
# binlogを開く
log_bin=mysql_bin
# リレーを有効にする_log
relay_log=relay_bin
他のノードも同じ構成ですが、 server_idを同じにすることはできません。
[ root@node-B ~]# vim /etc/my.cnf
[ mysqld]
server_id=102
log_bin=mysql_bin
relay_log=relay_bin
構成ファイルを変更した後、MySQLサービスを再起動します。
[ root@node-A ~]# systemctl restart mysqld
[ root@node-B ~]# systemctl restart mysqld
node-Bと node-A ###の間のマスターとスレーブの関係を構成します
node-BのMySQLコマンドラインターミナルに入り、次のステートメントを実行します。
mysql> stop slave;--マスターとスレーブの同期を停止します
mysql> change master to master_host='192.168.190.142', master_port=3306, master_user='backup', master_password='Abc_123456';--マスターノードの接続情報を構成します
mysql> start slave;--マスタースレーブ同期を開始します
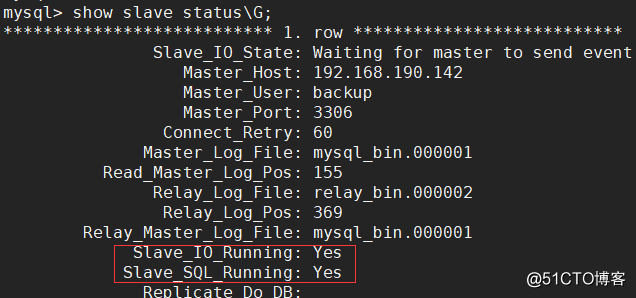
show slave status \ G;ステートメントを使用してマスター-スレーブ同期ステータスを表示します。Slave_IO_Runningと Slave_SQL_Runningの値は両方とも Yesであり、マスター-スレーブ同期ステータスが正常であることを示します。
node-Aと node-B ###の間のマスターとスレーブの関係を構成します
双方向の同期を実現するには、 node-Aと node-Bが互いにマスタースレーブ関係にある必要があるため、 node-Aと node-Bの間のマスタースレーブ関係を構成する必要があります。 node-AのMySQLコマンドラインターミナルに入り、それぞれ次のステートメントを実行します。ここでの master_hostは node-Bのipである必要があることに注意してください。
mysql> stop slave;--マスターとスレーブの同期を停止します
mysql> change master to master_host='192.168.190.131', master_port=3306, master_user='backup', master_password='Abc_123456';--マスターノードの接続情報を構成します
mysql> start slave;--マスタースレーブ同期を開始します
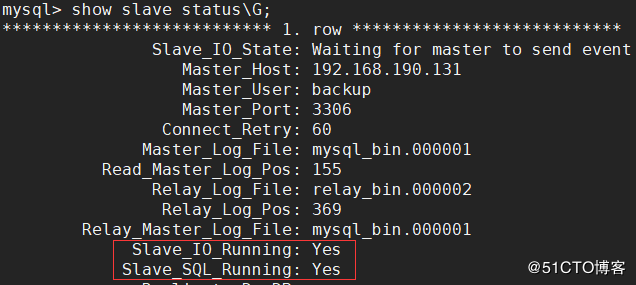
同じ構成が完了したら、 show slave status \ G;ステートメントを使用してマスタースレーブ同期ステータスを表示します。Slave_IO_Runningと Slave_SQL_Runningの値は両方とも Yesであり、マスタースレーブ同期ステータスが正常であることを示します。
マスターとスレーブの同期をテストします###
2つのノードのマスターとスレーブの同期関係を構成した後、レプリケーションクラスターの確立が完了しました。次に、任意のノードにアーカイブテーブルを作成して、2つのノード間でデータを正常に同期できるかどうかを確認します。特定のテーブルSQLは次のとおりです。
create table t_purchase_201909(
id int unsigned primary key,
purchase_price decimal(10,2) not null comment '購入金額',
purchase_num int unsigned not null comment '購入数量',
purchase_sum decimal(10,2) not null comment '合計購入価格',
purchase_buyer int unsigned not null comment '購入者',
purchase_date timestamp not nulldefault current_timestamp comment '購入日',
company_id int unsigned not null comment '購入会社のID',
goods_id int unsigned not null comment '製品番号',
key idx_company_id(company_id),
key idx_goods_id(goods_id)) engine=TokuDB comment '2019年9月のインバウンドデータファイリングテーブル';
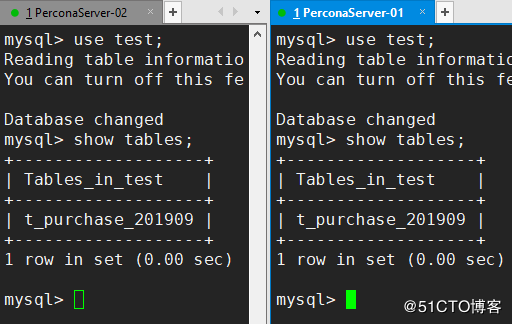
ここで正常に同期できます。図の両方のノードで次の表を確認できます。
Haproxy ###をインストールします
これまでに、レプリケーションクラスターの確立とテストを完了しました。次のステップは、レプリケーションクラスターの可用性を高めることです。これは、[Haproxy](https://www.haproxy.org/)の番です。 Haproxyは、高可用性、負荷分散、およびTCP(レイヤー4)およびHTTP(レイヤー7)アプリケーションを提供するプロキシソフトウェアです。 Haproxyを使用して、MySQLクラスターの負荷を分散し、クラスターに高い可用性を与え、クラスターのパフォーマンスを最大限に活用します。
Haproxyは旧ブランドの負荷分散コンポーネントであるため、このコンポーネントのインストールパッケージはCentOSの yumリポジトリに含まれており、インストールは非常に簡単です。インストールコマンドは次のとおりです。
[ root@HA-01~]# yum install -y haproxy
インストールが完了したら、Haproxyの構成ファイルを編集し、監視インターフェイスとプロキシを必要とするデータベースノードの構成を追加します。
[ root@HA-01~]# vim /etc/haproxy/haproxy.cfg
# ファイルの最後に次の構成項目を追加します
# インターフェイス構成の監視
listen admin_stats
# バインドされたIPとリスニングポート
bind 0.0.0.0:4001
# アクセス契約
mode http
# URI相対アドレス
stats uri /dbs
# 統計レポート形式
stats realm Global\ statistics
# 監視インターフェイスへのログインに使用されるアカウントパスワード
stats auth admin:abc123456
# データベースの負荷分散構成
listen proxy-mysql
# バインドされたIPとリスニングポート
bind 0.0.0.0:3306
# アクセス契約
mode tcp
# 負荷分散アルゴリズム
# ラウンドロビン:ポーリング
# static-rr:重量
# 最小接続:最小接続
# ソース:リクエストソースIP
balance roundrobin
# ログ形式
option tcplog
# 負荷分散が必要なホスト
server node-A 192.168.190.142:3306 check port 3306 weight 1 maxconn 2000
server node-B 192.168.190.131:3306 check port 3306 weight 1 maxconn 2000
# キープアライブを使用してデッドリンクを検出する
option tcpka
3306ポートは TCP転送用に構成され、 4001はHaproxy監視インターフェイスのアクセスポートとして構成されているため、次の2つのポートをファイアウォールで開く必要があります。
[ root@HA-01~]# firewall-cmd --zone=public--add-port=3306/tcp --permanent
[ root@HA-01~]# firewall-cmd --zone=public--add-port=4001/tcp --permanent
[ root@HA-01~]# firewall-cmd --reload
上記の手順を完了したら、Haproxyサービスを開始します。
[ root@HA-01~]# systemctl start haproxy
次に、ブラウザを使用してHaproxyの監視インターフェイスにアクセスします。初めてアクセスするときに、ユーザー名とパスワードを入力するように求められます。ユーザー名とパスワードは、構成ファイルで構成されています。
正常にログインすると、次のページが表示されます。
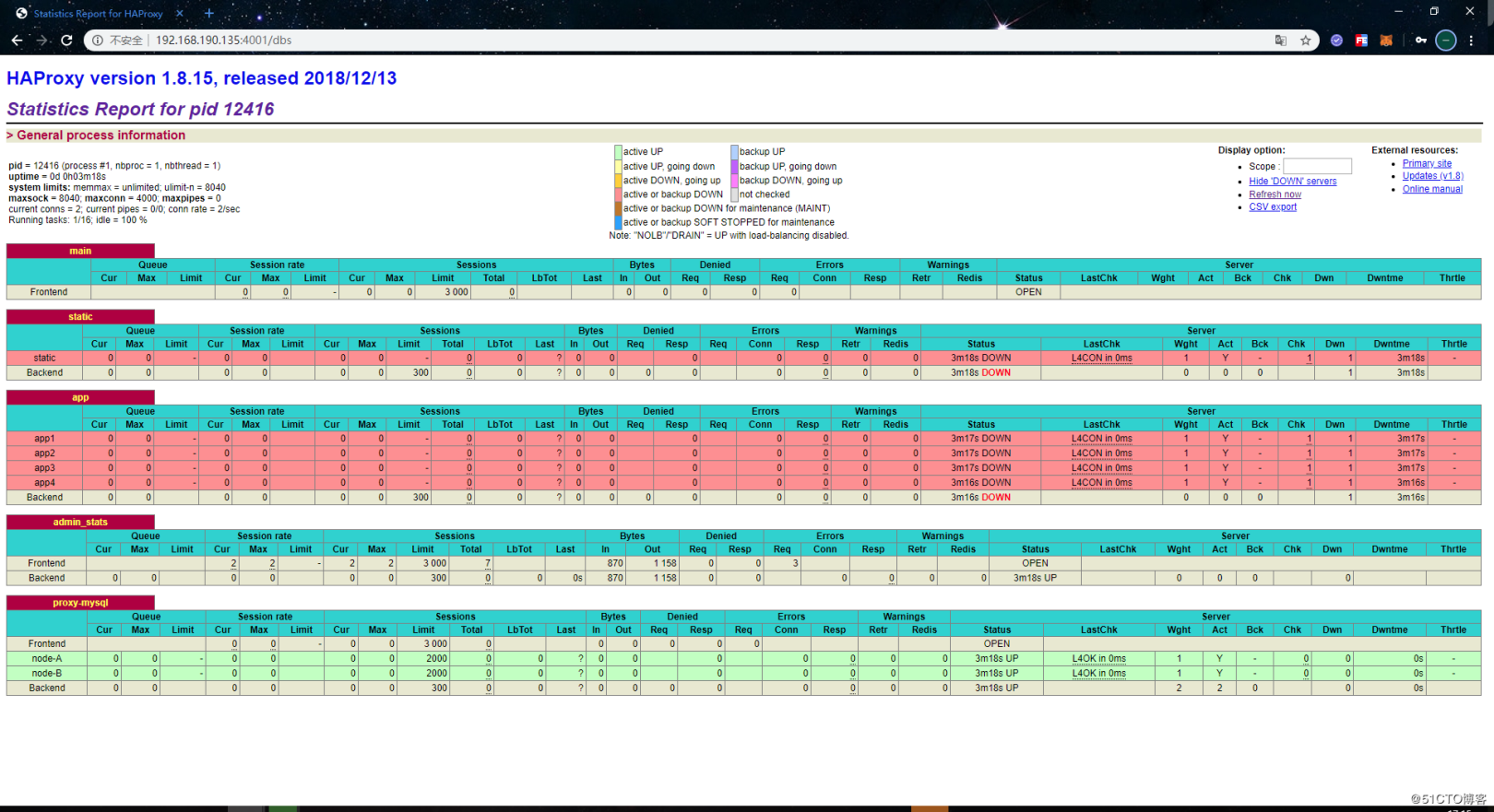
Haproxyの監視インターフェースによって提供される監視情報も比較的包括的です。このインターフェースの下で、各ホストの接続情報とそれ自体のステータスを確認できます。ホストが接続できない場合、「ステータス」の列に「DOWN」と表示され、背景色も赤に変わります。通常状態の値は UPで、背景色は緑です。
別のHaproxyノードもインストールと構成に上記の手順を使用するため、ここでは繰り返しません。
Haproxy ###をテストします
Haproxyサービスを設定したら、リモートツールを使用して、Haproxyを介してデータベースに正常に接続できるかどうかをテストします。次のように:
接続が成功したら、HaproxyでいくつかのSQLステートメントを実行して、データを挿入し、データを正常に照会できるかどうかを確認します。
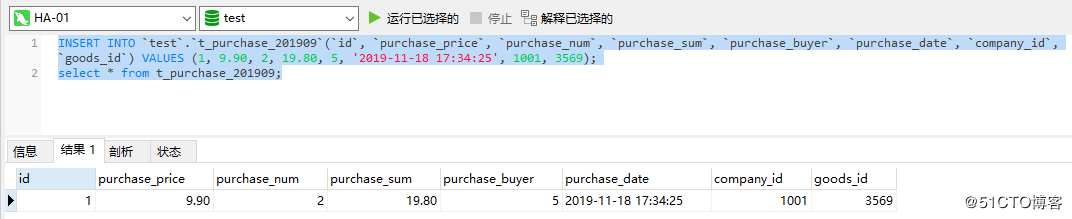
レプリケーションクラスターの可用性を高めるためにHaproxyを構築したので、最後にレプリケーションクラスターの可用性が高いかどうかをテストし、最初にノードの1つを停止します。
[ root@node-B ~]# systemctl stop mysqld
この時点で、Haproxyの監視インターフェイスから、ノード node-Bがすでにオフラインになっていることがわかります。

これで、クラスターに1つのノードが残った後、HaproxyでいくつかのSQLステートメントを実行して、データを正常に挿入および照会できるかどうかを確認します。
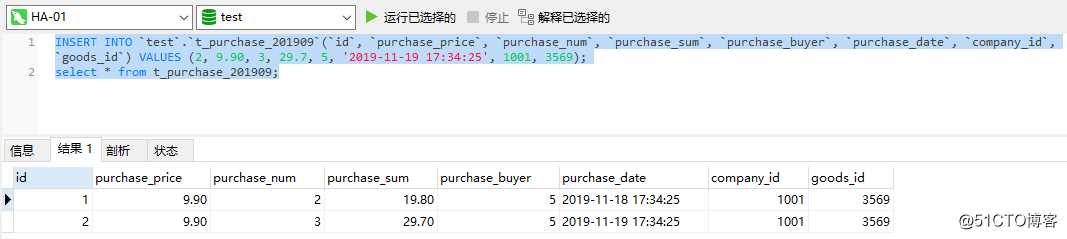
テスト結果からわかるように、挿入ステートメントとクエリステートメントは引き続き正常に実行できます。つまり、この時点で1つのノードがオフになっている場合でも、データベースクラスター全体を正常に使用でき、レプリケーションクラスターの可用性が高いことを示しています。
Keepalivedを使用して、Haproxy ###の高可用性を実現します
レプリケーションクラスターの高可用性を実現した後、Haproxyの高可用性を実現する必要があります。これは、Haproxyがクライアント要求の受信とバックエンドデータベースクラスターへの要求の転送を担当する入り口として、必然的に高可用性を必要とするためです。そうしないと、Haproxyに単一の障害ポイントがある場合、Haproxyによってプロキシされたすべてのデータベースクラスターノードにアクセスできなくなり、システム全体に大きな影響を及ぼします。
同時に使用できるHaproxyは1つだけです。そうしないと、クライアントはどのHaproxyに接続するかがわかりません。これが、Keepalivedの仮想IPが使用される理由でもあります。このメカニズムにより、複数のノードが相互に引き継ぐときに同じIPを使用でき、クライアントは最初から最後までこの仮想IPに接続するだけで済みます。したがって、Haproxyの高可用性を実現するには、Keepalivedが登場する番です。Keepalivedをインストールする前に、ファイアウォールのVRRPプロトコルを有効にする必要があります。
[ root@HA-01~]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0--protocol vrrp -j ACCEPT
[ root@HA-01~]# firewall-cmd --reload
次に、 yumコマンドを使用してKeepalivedをインストールできます。
[ root@HA-01~]# yum install -y keepalived
インストールが完了したら、keepalivedの構成ファイルを編集します。
[ root@HA-01~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak #組み込みの構成ファイルは使用しないでください
[ root@HA-01~]# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER
interfaceens32
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456}
virtual_ipaddress {192.168.190.101}}
構成手順:
-
state MASTER:ノードの役割をマスターとして定義します。役割がマスターの場合、ノードは競合することなくVIPを取得できます。クラスターには複数のマスターが許可されています。複数のマスターが存在する場合、マスターはVIPを競う必要があります。他の役割の場合、VIPはマスターがオフラインのときにのみ取得できます -
interface ens32:外部通信に使用できるネットワークカードの名前を定義します。ネットワークカードの名前は、ipaddrコマンドで表示できます。 -
virtual_router_id 51:仮想ルートのIDを定義します。値は0〜255です。各ノードの値は一意である必要があります。つまり、同じになるように構成することはできません。 -
優先度100:重みを定義します。重みが大きいほど、VIPを取得する優先度が高くなります。 -
advert_int 1:検出間隔を1秒として定義します -
authentication:ハートビートチェックで使用される認証情報を定義します -
auth_type PASS:認証タイプをパスワードとして定義します -
auth_pass 123456:特定のパスワードを定義します -
virtual_ipaddress:仮想IP(VIP)を定義します。これは、同じネットワークセグメントの下のIPである必要があり、各ノードは一貫している必要があります
上記の構成が完了したら、keepalivedサービスを開始します。
[ root@HA-01~]# systemctl start keepalived
keepalivedサービスが正常に開始されたら、 ip addrコマンドを使用して、ネットワークカードにバインドされている仮想IPを表示します。
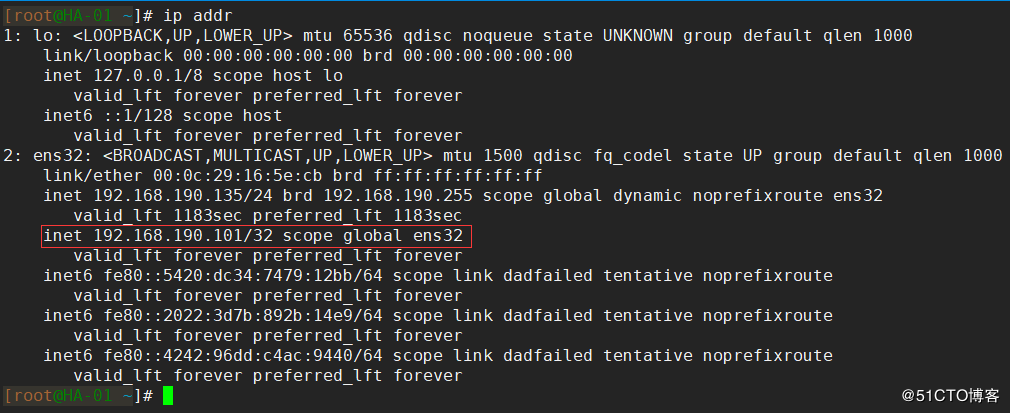
他のノードも上記の手順を使用してインストールおよび構成されているため、ここでは繰り返しません。ただし、 virtual_router_idを同じように構成することはできず、 virtual_ipaddressを同じ仮想IPになるように構成する必要があることに注意してください。
Keepalived ###をテストします
上記では、Keepalivedのインストールと構成が完了しました。最後に、Keepalivedサービスが正常に利用可能かどうか、およびHaproxyの可用性が高いかどうかをテストします。
まず、仮想IPが他のノードで正常にpingできるかどうかをテストします。pingできない場合は、構成を確認する必要があります。図に示すように、通常、ここで「ping」を実行できます。
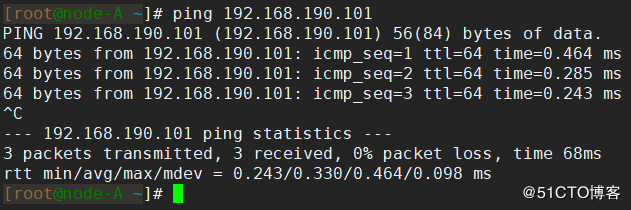
一般的な仮想IPpingの失敗:
- ファイアウォールの構成が正しくなく、VRRPプロトコルが正しく開かれていません
- 構成された仮想IPは、他のノードのIPと同じネットワークセグメントにありません
- Keepalivedが正しく構成されていないか、Keepalivedがまったく正常に起動しませんでした
Keepalived仮想IPが外部からpingできることを確認した後、Navicatを使用して、仮想IPをデータベースに接続できるかどうかをテストします。
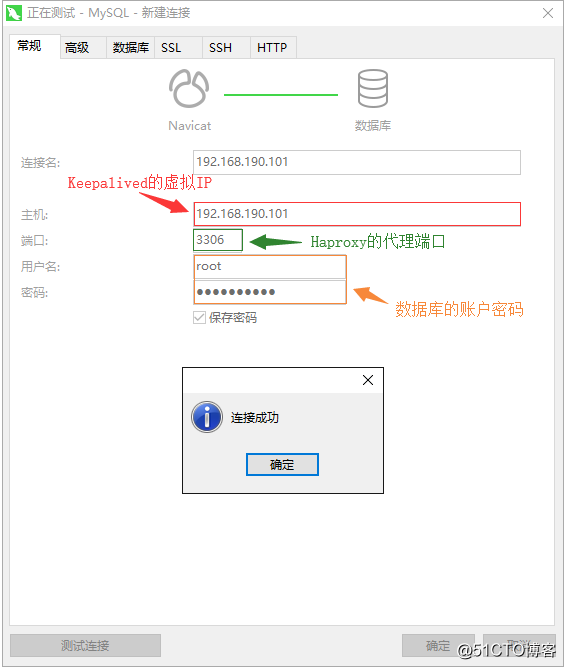
接続が成功したら、いくつかのステートメントを実行して、データを挿入して正常にクエリできるかどうかをテストします。
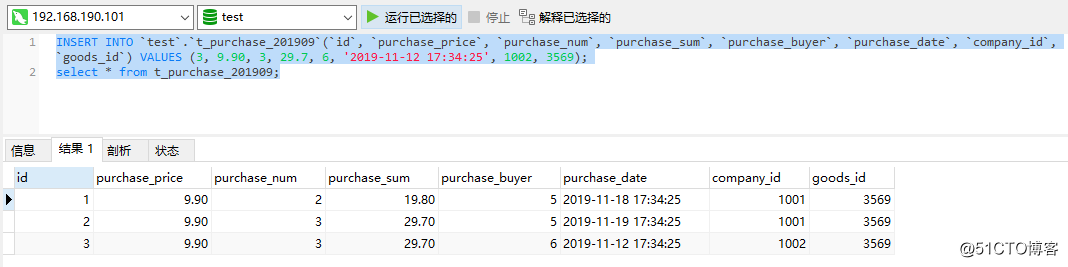
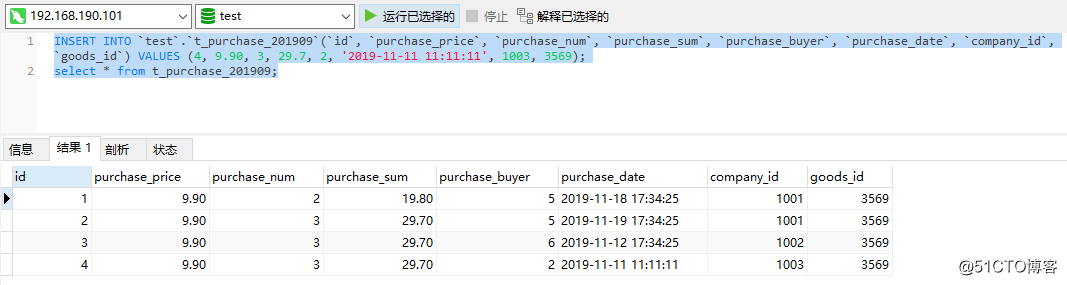
この時点では、基本的に問題はありません。最後に、Haproxyの高可用性をテストし、Haproxyノードの1つでKeepalivedサービスとHaproxyサービスをオフにします。
[ root@HA-01~]# systemctl stop keepalived
[ root@HA-01~]# systemctl stop haproxy
次に、いくつかのステートメントを再度実行して、データを挿入して正常にクエリできるかどうかをテストします。以下は正常に実行できます。これは、Haproxyノードの可用性が高いことを意味します。
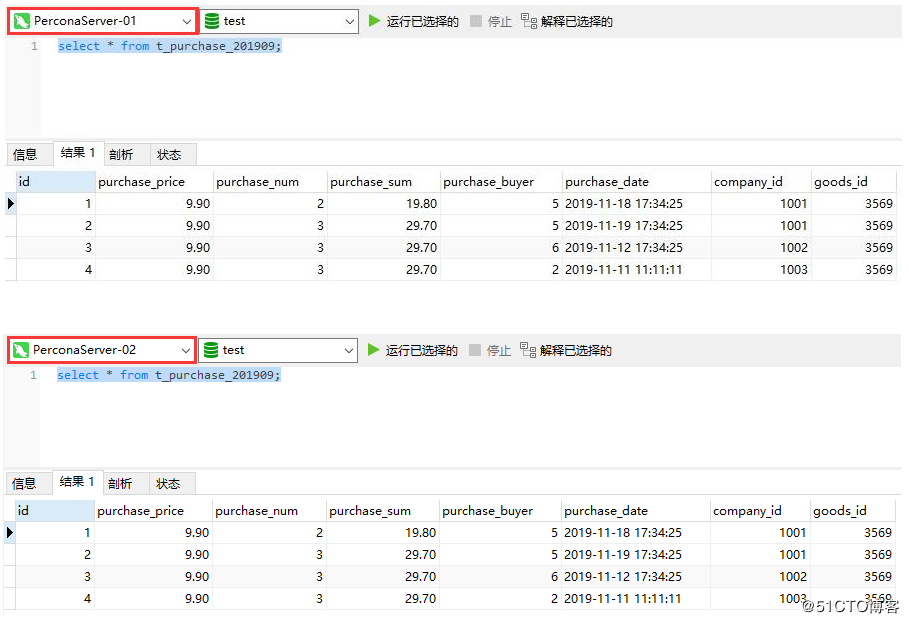
最後に、すべてのサービスを実行状態に復元し、停止したノードが復元された後、データに一貫性があるかどうかを確認します。次のように、ここでの2つのレプリケーションノードのデータは同じです。
練習データアーカイブ##
これまでに、可用性の高いレプリケーションクラスターの確立を完了しました。次のステップは、PXCクラスターシャードから大量のコールドデータを取り除き、それらをレプリケーションクラスターにアーカイブする方法を練習することです。ここに2つのPXCクラスターシャードがあります。
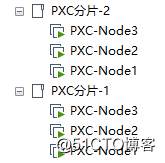
- PXCクラスターの内容については、別の記事を参照してください:[PXCクラスター用のMycatを紹介し、完全な高可用性クラスターアーキテクチャを構築する](https://blog.51cto.com/zero01/2467910)
各シャードには t_purchaseテーブルがあり、そのテーブルSQLは次のとおりです。
create table t_purchase(
id int unsigned primary key,
purchase_price decimal(10,2) not null comment '購入金額',
purchase_num int unsigned not null comment '購入数量',
purchase_sum decimal(10,2) not null comment '合計購入価格',
purchase_buyer int unsigned not null comment '購入者',
purchase_date timestamp not nulldefault current_timestamp comment '購入日',
company_id int unsigned not null comment '購入会社のID',
goods_id int unsigned not null comment '製品番号',
key idx_company_id(company_id),
key idx_goods_id(goods_id)) comment '購入リスト';
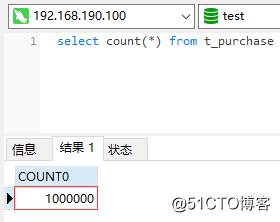
各シャードには、合計100wの購入データが保存されます。
その中で、60wの購入データの購入日は 2019-11-01より前です。
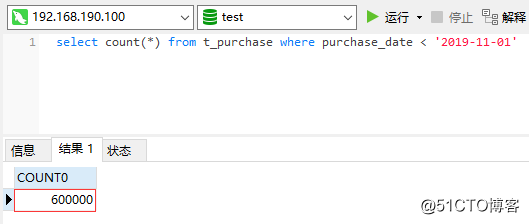
現在の要求は、アーカイブのために「2019-11-01」の前にすべてのデータを取り除くことですが、これをどのように達成できますか?自分でコードを書くのは間違いなく面倒です。幸い、Perconaツールキットにはデータをアーカイブするためのツールが用意されています。 pt-archiverは、このツールを使用してデータアーカイブを簡単に完了できるため、独自のアーカイブプログラムを作成する手間が省けます。 。 pt-archiverには2つの主な目的があります。
- データ処理のためにオンラインデータをオフラインにエクスポートする
- 期限切れのデータをクリーンアップし、データをローカルアーカイブテーブルまたはリモートアーカイブサーバーにアーカイブします
pt-archiverを使用するには、最初にPerconaツールキットをインストールする必要があります。
[ root@node-A ~]# yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
[ root@node-A ~]# percona-release enable ps-80 release
[ root@node-A ~]# yum install -y percona-toolkit
インストールが完了したら、 pt-archiverコマンドが使用可能であることを確認します。
[ root@node-A ~]# pt-archiver --version
pt-archiver 3.1.0[root@node-A ~]#
次に、 pt-archiverコマンドを使用してデータをアーカイブできます。最初に、レプリケーションクラスターにアーカイブテーブルを作成する必要があります。テーブル名の末尾にはアーカイブデータの日付が付けられ、ストレージエンジンはTokuDBを使用します。特定のテーブルSQLは次のとおりです。
create table t_purchase_201910(
id int unsigned primary key,
purchase_price decimal(10,2) not null comment '購入金額',
purchase_num int unsigned not null comment '購入数量',
purchase_sum decimal(10,2) not null comment '合計購入価格',
purchase_buyer int unsigned not null comment '購入者',
purchase_date timestamp not nulldefault current_timestamp comment '購入日',
company_id int unsigned not null comment '購入会社のID',
goods_id int unsigned not null comment '製品番号',
key idx_company_id(company_id),
key idx_goods_id(goods_id)) engine=TokuDB comment '2019年10月の購入データのファイリングテーブル';
次に、次の例に示すように、 pt-archiverコマンドを使用してデータアーカイブを完成させます。
[ root@node-A ~]# pt-archiver --source h=192.168.190.100,P=3306,u=admin,p=Abc_123456,D=test,t=t_purchase --dest h=192.168.190.101,P=3306,u=archive,p=Abc_123456,D=test,t=t_purchase_201910 --no-check-charset --where 'purchase_date < "2019-11-01 0:0:0"'--progress 50000--bulk-delete--bulk-insert --limit=100000--statistics
- ヒント:
pt-archiverコマンドはloaddataステートメントを使用してデータをインポートするため、MySQLでlocal_infileが有効になっていることを確認してください。アーカイブデータが有効になっていないと失敗します。setgloballocal_infile= 'ON';ステートメントを使用してlocal_infileを有効にできます。
コマンドパラメータの説明:
- - source:データを読み取るデータベースを指定します- - dest:データをアーカイブするデータベースを指定します- - no-check-charset:データの文字セットをチェックしません- - ここで、:アーカイブするデータを指定します。この場合、2019-09-11より前のデータをアーカイブします。- - progress:アーカイブするデータの数を1回出力するステータス情報を指定します- - 一括削除:アーカイブデータの一括削除を指定します。データの削除はトランザクションによって保証されており、アーカイブが成功せずにデータを削除することはありません。- - 一括挿入:バッチ書き込みアーカイブデータを指定します- - limit:毎回アーカイブするデータの数を指定します- - statistics:データをアーカイブした後に統計を出力します
データのアーカイブが完了するまで約15分待ちます。出力統計は次のとおりです。
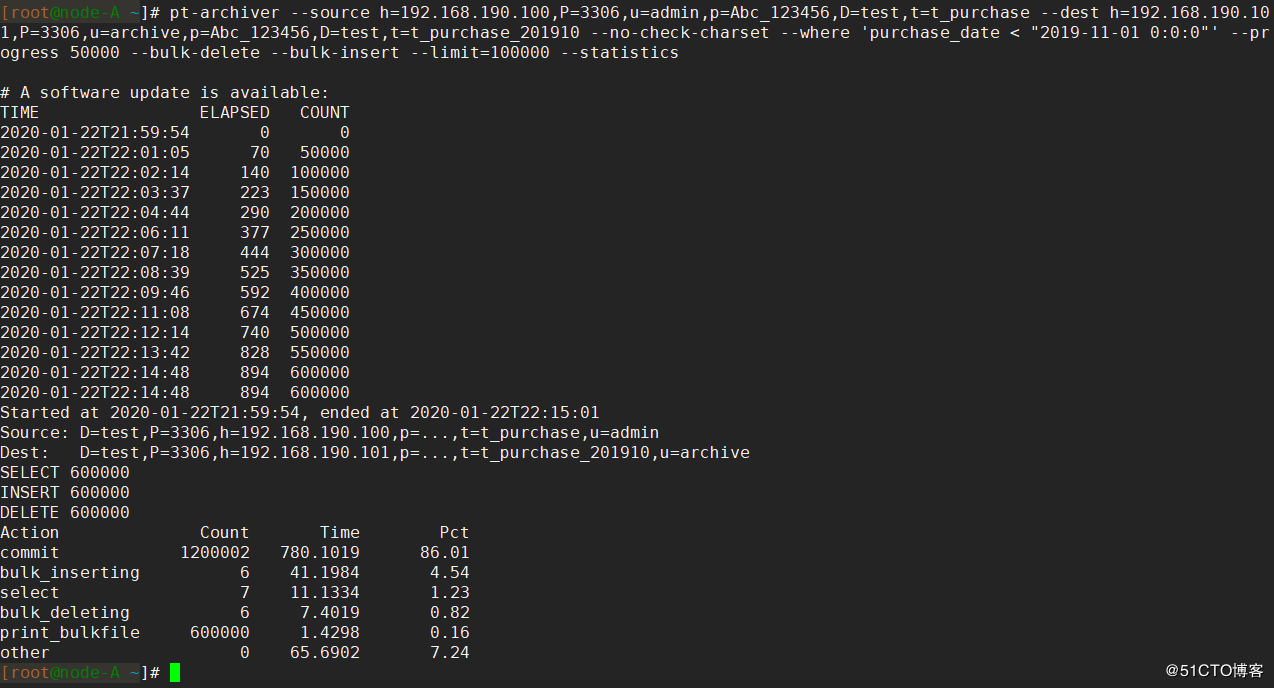
この時点で、60wデータがレプリケーションクラスターのアーカイブテーブルに保存されていることがわかります。
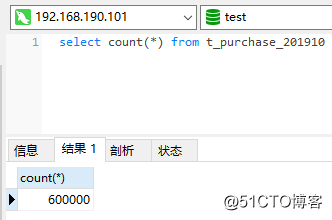
また、元のPXCクラスターには40wのデータしか残っていません。
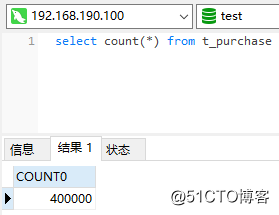
このようにして、コールドデータとホットデータの分離が完了し、指定されたアーカイブデータベースに大量のコールドデータが保存されました。
総括する##
- コールドデータとホットデータを分離し、価値の低いコールドデータをアーカイブライブラリに保存し、ホットデータの読み取りと書き込みの効率を維持します
- TokuDBエンジンを使用して、高速書き込み特性を備えたアーカイブデータを保存します
- デュアルシステムのホットバックアップソリューションを使用して、可用性の高いアーカイブライブラリを構築します
pt-archiverを使用して、大量のデータとアーカイブストレージをエクスポートします。これは、シンプルで簡単です。