オンライン環境Linuxシステムの通話追跡
その過程でシステム呼び出しを動的に追跡する方法について言えば、誰もが最初にstraceを考えることができると思います。その基本的な使用法は非常に単純で、「このソフトウェアがこのマシンで実行できないのはなぜですか?」という問題の解決に非常に適しています。ただし、オンラインサービスの一部のシステム呼び出しの遅延(特に遅延の影響を受けやすい)を分析する必要がある場合、straceは非常に大きなオーバーヘッドをもたらすため、あまり適していません。パフォーマンス分析マスターのBrendan Greggのテスト結果によると、 straceによって追跡されるターゲットプロセスの実行速度は100倍以上低下します。これは、実稼働環境にとって災害になります。
では、実稼働環境で使用するためのより良いツールはありますか?答えは「はい」です。以下では、2つのツールで一般的に使用されるコマンドを紹介し、必要なときに簡単に参照できるようにします。
Perf
ご存知のとおり、perfはLinuxシステムの下で非常に強力なパフォーマンスツールであり、Linuxカーネル開発者によって絶えず進化および最適化されています。 PMU(Performance Monitoring Unit)ハードウェアイベント、カーネルイベント、およびその他の一般的な機能の分析に加えて、perfは、スケジュール分析スケジューラなどの他の「サブモジュール」も提供し、タイムチャートは負荷特性に基づいてシステムの動作を視覚化し、c2cは考えられる誤った共有を分析します(RedHatはこの一連のc2c開発プロトタイプを多数のLinuxアプリケーションでテストし、疑似共有キャッシュラインに関する多くのホットな問題を発見することに成功しました。)など、トレースを使用してシステム呼び出しを分析できます。これは非常に強力で保証されています。許容可能なオーバーヘッドを達成するために-実行速度はわずか1.36倍遅くなります(テスト負荷のdd)。いくつかの一般的なシナリオを見てみましょう。
- syscall呼び出し数のトップランキング
perf top -F 49-e raw_syscalls:sys_enter --sort comm,dso --show-nr-samples
出力から、サンプリング期間中、kubeであることがわかります。-apiserverはほとんどの場合syscallを呼び出します。
- 一定の遅延を超えるシステムコール情報を表示する
perf trace --duration 200
出力から、プロセス名、pid、特定のシステム呼び出しパラメーター、および200ミリ秒を超える戻り値を確認できます。
- 一定期間にわたる特定のプロセスでのシステム呼び出しのコストをカウントします
perf trace -p $PID -s
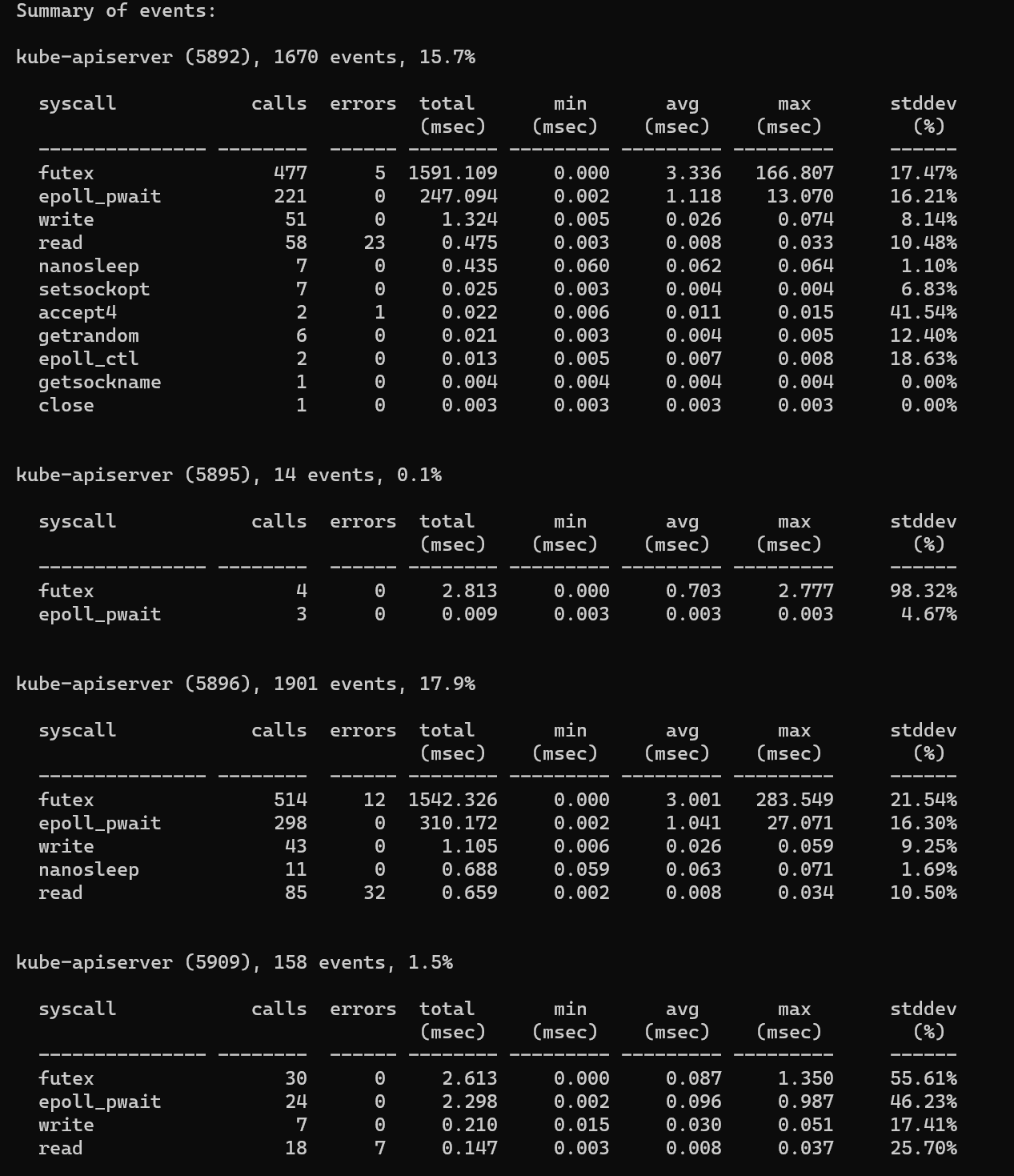
出力から、システムコールの数、返されたエラーの数、合計遅延、および平均遅延を確認できます。
- また、待ち時間の長いコールスタック情報をさらに分析することもできます
perf trace record --call-graph dwarf -p $PID -- sleep 10
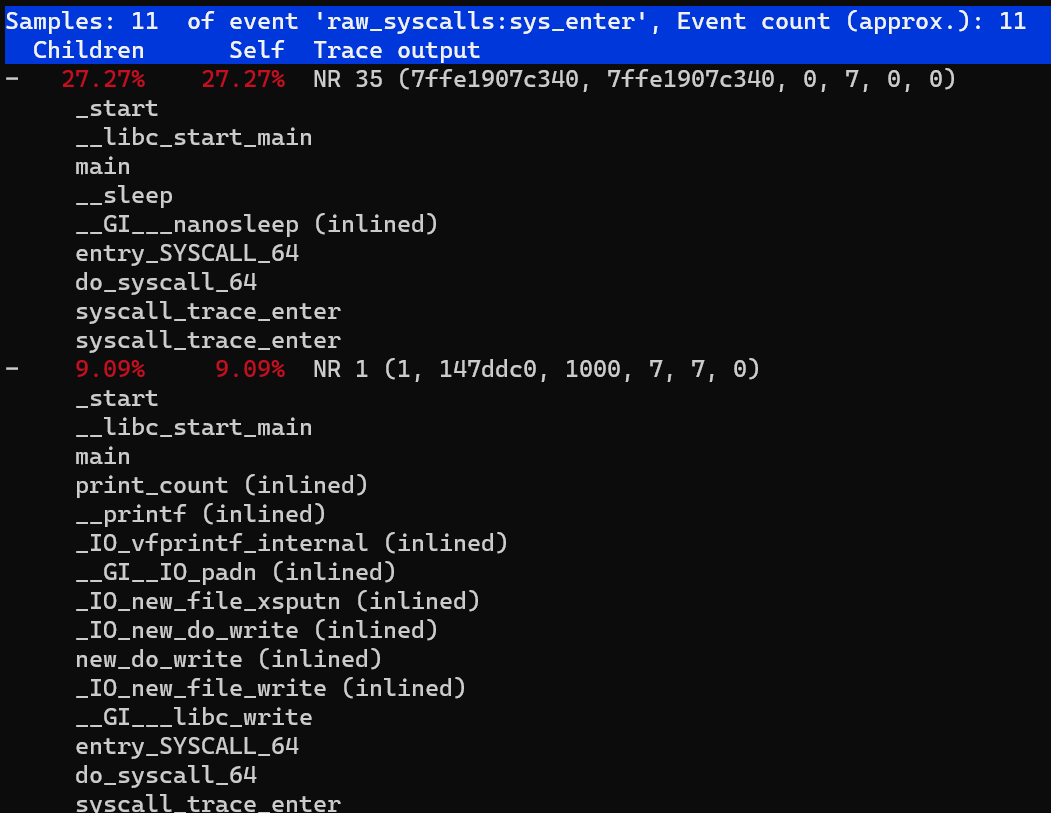
- タスクのグループをトレースします。たとえば、バックグラウンドで実行されている2つのbpfツールがあります。それらのシステム呼び出しの使用状況を確認する場合は、最初にそれらをperf_event cgroupに追加してから、perftraceを実行します。
mkdir /sys/fs/cgroup/perf_event/bpftools/
echo 22542>>/sys/fs/cgroup/perf_event/bpftools/tasks
echo 20514>>/sys/fs/cgroup/perf_event/bpftools/tasks
perf trace -G bpftools -a -- sleep 10
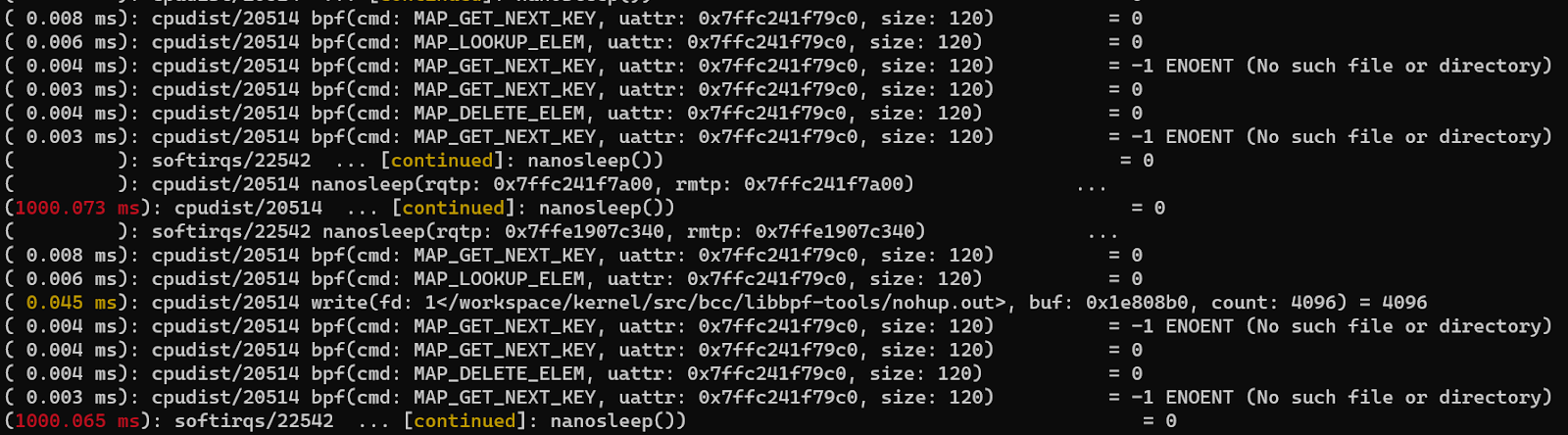
ここでは、perf-traceの使い方を紹介します。使い方については、マニュアルをご覧ください。上記から、perf-traceの機能が非常に強力で、pidやtidでフィルタリングできることがわかります。しかし、コンテナとK8S環境の便利なサポートはないようです。次に紹介するツールは、コンテナとK8S環境用です。
Traceloop
Traceloopに少し慣れていないかもしれませんが、BCCに関しては、それに精通している必要があります。 BCCのフロントエンドはPython / C ++であり、そのiovisorの下にgobpfと呼ばれる別のプロジェクトがあります。これはBCCのgoバインディングです。 Traceloopは、gobpfライブラリに基づいて開発されています。このプロジェクトの主なターゲットアプリケーションシナリオは、コンテナとK8S環境です。原理は比較的単純であり、そのアーキテクチャを図に示します。
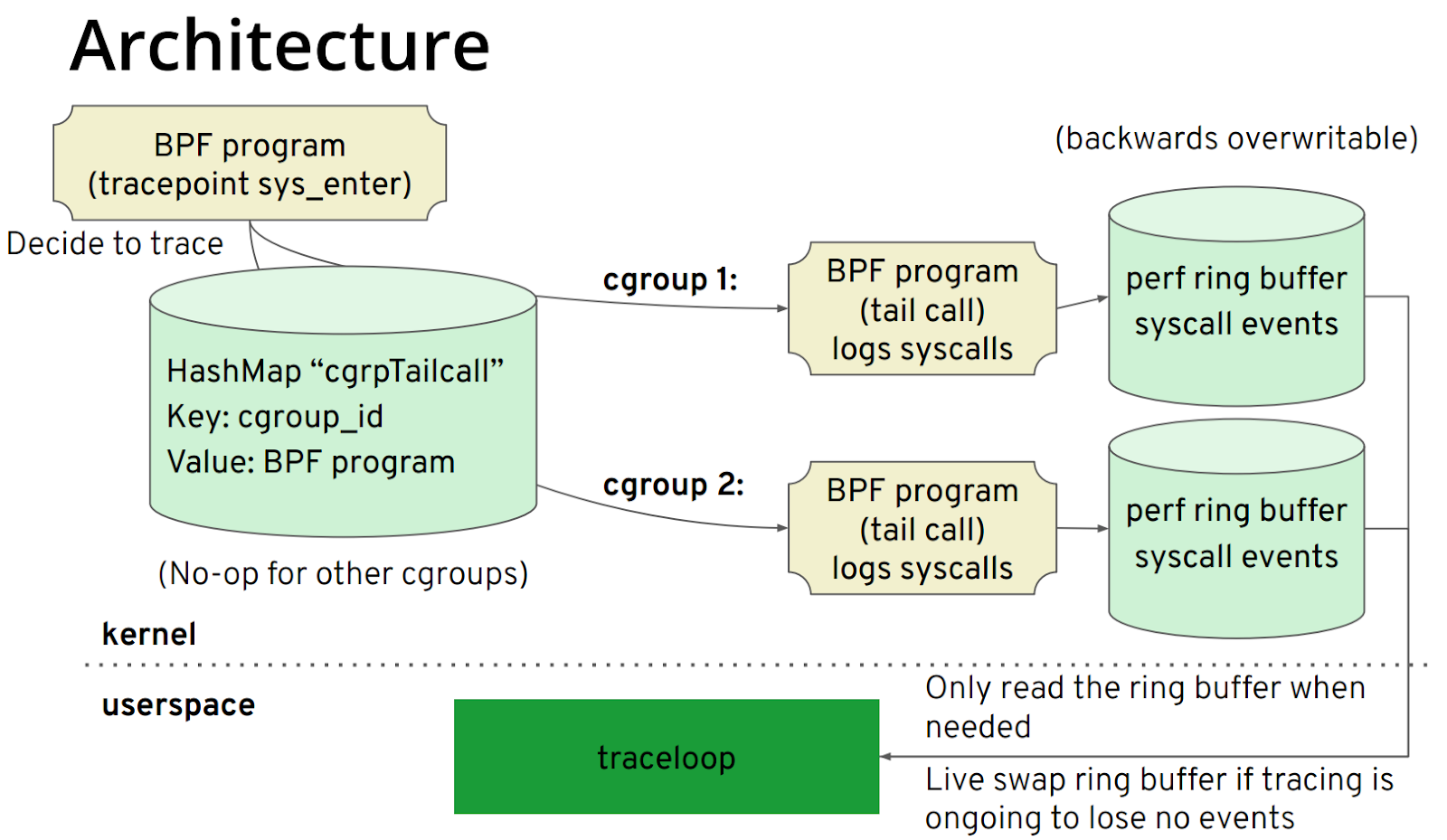
コアステップは次のとおりです。
- bpfヘルパーを使用してcgroupIDを取得し、pidとtidの代わりにcgroupidに従ってフィルタリングします。
- 各cgroupIDはbpfテール呼び出しに対応します。このようにして、このcgroupidに対応するperfリングバッファを書き込むことができます。
- ユーザースペースは、cgroupIDに従って対応するパフォーマンスリングバッファーを読み取ります。
cgroup IDを取得する現在の方法は、bpfヘルパーbpf_get_current_cgroup_idを介して取得されることに注意してください。このIDは、cgroupv2でのみ使用できます。したがって、cgroupv2が有効になっている環境にのみ適用できます。このプロジェクトチームがnsproxyデータ構造などを読み取ってcgroupv1をサポートするかどうかは定かではないため、ここでは簡単に紹介します。 K8Sバージョン1.19がcgroupv2のサポートを開始するので、cgroupv2ができるだけ早く普及することを願っています。以下は、簡単なデモンストレーションのためにCentos8バージョン4.18カーネルを使用しています。traceloopが終了したときにシステム呼び出し情報をダンプします。
sudo -E ./traceloop cgroups --dump-on-exit /sys/fs/cgroup/system.slice/sshd.service
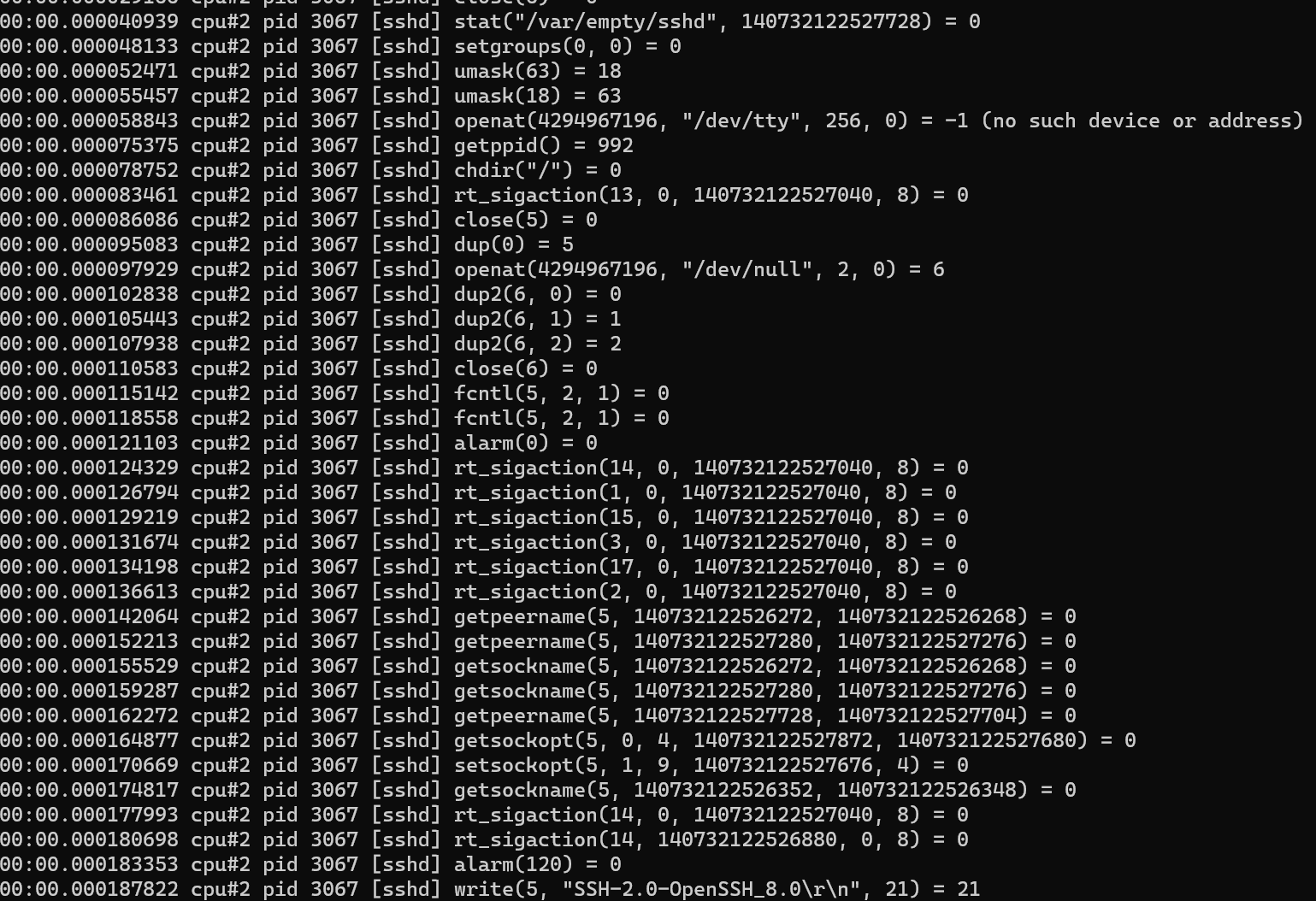
出力からわかるように、その出力は、cgroupをフィルタリングすることを除いて、strace / perftraceに似ています。 Centos8はcgroupv2をUbuntuのように/ sys / fs / cgroup / unifiedにマウントせず、/ sys / fs / cgroupに直接マウントすることに注意してください。使用する前に mount -tcgroup2を実行することをお勧めします。マウント情報を決定します。
K8Sプラットフォームの場合、チームはtraceloopをInspektor Gadgetプロジェクトに統合し、kubectlプラグインを介して実行します。パイプネットワークは詳細なgifの例を示しているため、ここではあまり紹介しません。cgroupv2が必要な友人は試すことができます。試してみる。
Benchmark
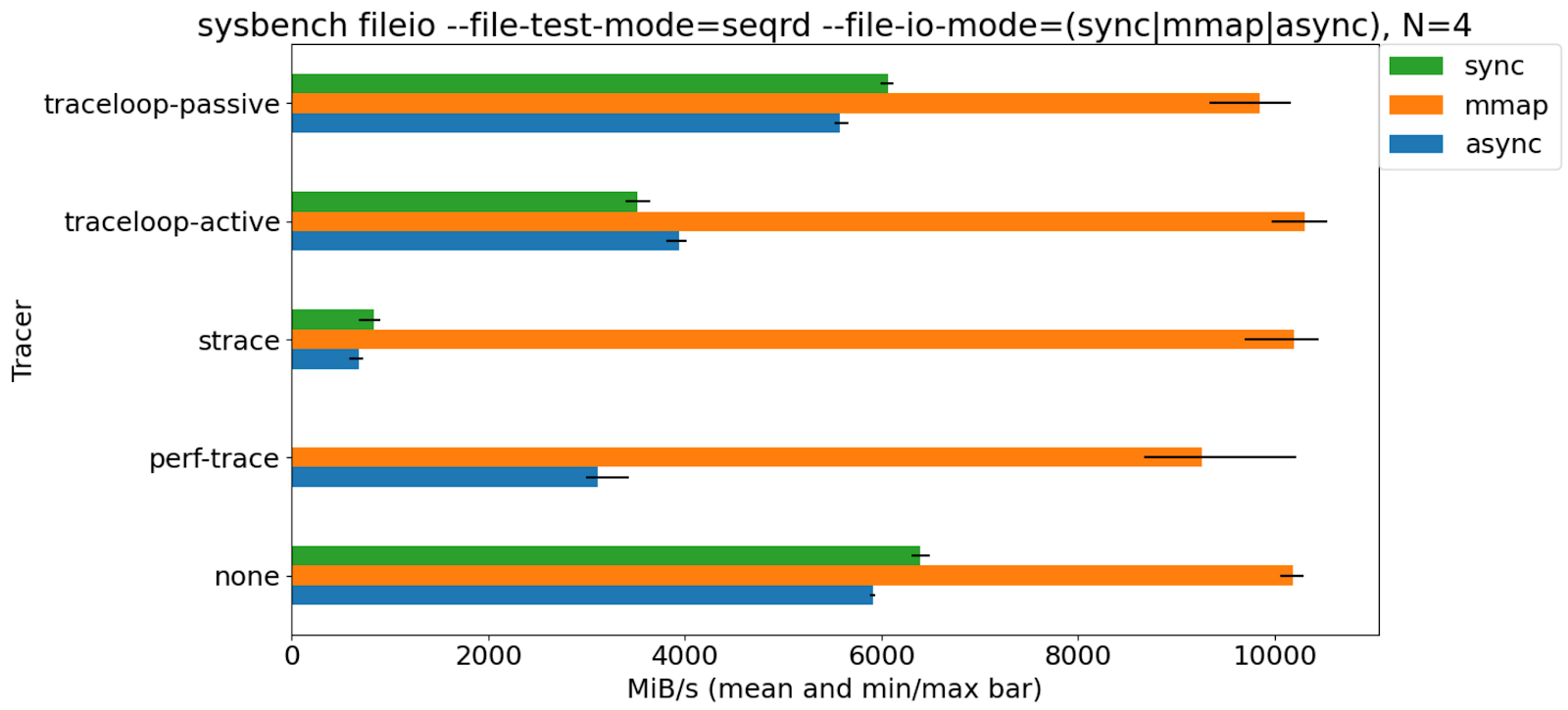
ベンチマーク結果から、straceによって引き起こされるターゲットプログラムのパフォーマンスが最大で、次にperf traceが続き、traceloopが最小です。
総括する##
straceは、「このソフトウェアをこのマシンで実行できないのはなぜですか?」という関連する問題を解決するための強力なツールですが、システム呼び出しの遅延やその他の問題を分析するには、perftraceが適しています。これもBPFの実装に基づいています。cgroupv2を使用している場合コンテナ、K8S環境、traceloopがより便利になります。