Python空の列を持つ行を削除する方法
1. 概要
dropna()メソッドは、DataFrameタイプのデータのnull値(欠落値)を見つけ、null値が配置されている行/列を削除し、新しいDataFrameを戻り値として返すことができます。
2. 機能説明
関数形式:dropna(axis = 0、how = 'any'、thresh = None、subset = None、inplace = False)
パラメータ:
軸:軸。 0または「インデックス」は行による削除を意味し、1または「列」は列による削除を意味します。
方法:フィルターメソッド。 「any」は、行/列に複数のnull値がある限り、行/列が削除されることを意味します。「all」は、行/列がすべてnull値であることを意味し、行/列が削除されます。
thresh:空でない要素の最小数。 intタイプ、デフォルトはNoneです。行/列の空でない要素の数がこの値より少ない場合、行/列は削除されます。
サブセット:サブセット。リスト、要素は行または列のインデックスです。 axis = 0または 'index'の場合、サブセット内の要素は列のインデックスです。axis= 1または 'column'の場合、サブセット内の要素は行のインデックスです。サブセットによって制限されるサブエリアは、行/列を削除するかどうかを判断するための条件付き判断エリアです。
インプレース:インプレースで交換するかどうか。ブール値。デフォルトはFalseです。 Trueの場合、操作は元のDataFrameで実行され、戻り値はNoneです。
3. 例
DataFrameデータを作成します。
importnumpyasnp
importpandasaspd
a=np.ones((11,10))foriinrange(len(a)):
a[i,:i]=np.nan
d=pd.DataFrame(data=a)print(d)
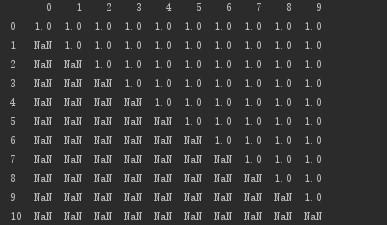
行ごとに削除:null値がある場合は、行を削除します
# 行ごとに削除:null値がある場合は、行を削除します
print(d.dropna(axis=0,how='any'))
行ごとに削除:すべてのデータが空です。つまり、行を削除します
# 行ごとに削除:すべてのデータが空です。つまり、行を削除します
print(d.dropna(axis=0,how='all'))

列ごとに削除:列に空でない要素が5つ未満の場合は、列を削除します
# 列ごとに削除:列に空でない要素が5つ未満の場合は、列を削除します
print(d.dropna(axis='columns',thresh=5))
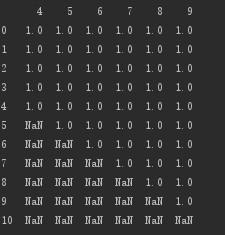
サブセットを設定します。列0、5、6、および7がすべて空の行を削除します。
# サブセットを設定します。列0、5、6、および7がすべて空の行を削除します。
print(d.dropna(axis='index',how='all',subset=[0,5,6,7]))
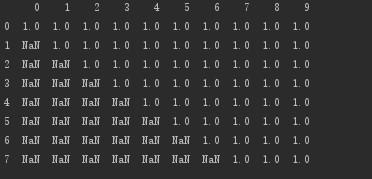
サブセットを設定します:行5、6、および7のnull値を持つ列を削除します
# サブセットを設定します:行5、6、および7のnull値を持つ列を削除します
print(d.dropna(axis=1,how='any',subset=[5,6,7]))
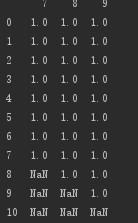
インプレース変更

# インプレース変更
print(d.dropna(axis=0,how='any',inplace=True))print("==============================")print(d)
拡張の例:
コード
import pandas as pd
data = pd.read_excel('test.xlsx',sheet_name='Sheet1')
datanota = data[data['営業担当者'].notna()]print(datanota)
出力結果
D:\Python\Anaconda\python.exe D:/Python/test/EASdeal/test.py
市の販売額営業担当者
0 北京10000張リリ
1 上海50000Xiaoxiao
2 深セン60,000ベンベンベン
3 チェンドゥ40000ダダ
Process finished with exit code 0
これまでのところ、pythonで空の行を削除する方法に関するこの記事をここで紹介します。空の行の関連するpython削除方法については、ZaLou.Cnの以前の記事を検索するか、以下の関連記事を引き続き参照してください。将来的にはZaLou.Cnをたくさんサポートしてください!
Recommended Posts