Pythonがファイルディレクトリでどのように動作するか
概要
I / O操作には、画面の入力と出力だけでなく、ファイルの読み取りと書き込みも含まれます。Pythonには、ファイルとフォルダーに関連する操作を実行するために必要な多くのメソッドと関数が用意されています。この記事では、主に2つの簡単な小さな例を使用して、学習と共有のみを目的としたフォルダーとファイルでのPythonのアプリケーションについて簡単に説明します。不備がある場合は、修正してください。
知識ポイントを含む
osモジュール:osモジュールは、ファイルとディレクトリを処理するための非常に豊富な方法を提供します。
Openメソッド:openメソッドは、読み取りおよび書き込み用にファイルを開くために使用されます。
例1:指定されたディレクトリ内のすべてのファイルサイズを取得し、最大のファイルと最小のファイルを見つけます
分解手順:
フォルダの下のすべてのサブファイルとサブフォルダをトラバースし(再帰が必要)、各ファイルのサイズを計算します
すべてのファイルの合計サイズを計算します
最大のファイルと最小のファイルを見つける
コアコード
メソッドget_file_sizeを定義して、KBとMBの2つの単位で単一ファイルのサイズを取得します。重要なポイントは次のとおりです。
- os.path.getsizeは、指定されたファイルのサイズを取得するために使用されます。単位はバイトです。
- roundは、指定された小数を保持する丸め関数です。
def get_file_size(file_path, KB=False, MB=False):"""ファイルサイズを取得する"""
size = os.path.getsize(file_path)if KB:
size =round(size /1024,2)
elif MB:
size =round(size /1024*1024,2)else:
size = size
return size
指定されたファイルディレクトリをトラバースして辞書に保存するメソッドlist_filesを定義します。重要なポイントは次のとおりです。
- os.path.isfileは、指定されたパスがファイルであるかフォルダーであるかを判別するために使用されます。
- os.listdirは、指定されたディレクトリ内のすべてのファイルとフォルダを取得してリストを返すために使用されますが、フルパスではなく、現在のフォルダの名前のみを返します。
- os.path.joinは、2つのパスを結合するために使用されます
def list_files(root_dir):"""ファイルを反復処理する"""if os.path.isfile(root_dir): #ファイルの場合
size =get_file_size(root_dir, KB=True)
file_dict[root_dir]= size
else:
# フォルダの場合はトラバースします
for f in os.listdir(root_dir):
# スプライシングパス
file_path = os.path.join(root_dir, f)if os.path.isfile(file_path):
# ファイルの場合
size =get_file_size(file_path, KB=True)
file_dict[file_path]= size
else:list_files(file_path)
以下に示すように、合計サイズと最大および最小のファイルを計算します。
ディクショナリ値のサイズを比較することにより、対応するキーの名前が返されます。重要なポイントは次のとおりです。
- max_file = max(file_dict, key=lambda x: file_dict[x])
- min_file = min(file_dict, key=lambda x: file_dict[x])
if __name__ =='__main__':list_files(root_dir)
# print(len(file_dict))
# ファイルディレクトリサイズを計算する
total_size =0
# 辞書のキーをトラバースします
for file in file_dict:
total_size += file_dict[file]print('total size is : %.2f'% total_size)
# 最大および最小のファイルを見つける
max_file =max(file_dict, key=lambda x: file_dict[x])
min_file =min(file_dict, key=lambda x: file_dict[x])print('max file is : ', max_file,'\n file size is :', file_dict[max_file])print('min file is : ', min_file,'\n file size is :', file_dict[min_file])
例2:2つのテキストファイルの内容を組み合わせてファイルに保存する
2つのファイルの内容は、次の図に示すとおりです。
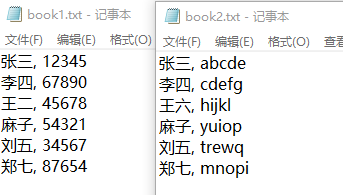
分解手順:
- 2つのファイルの内容を読み取り、それらを解析してキーと値を取得し、それらを辞書に保存します(2つの辞書はそれぞれ2つのファイルの内容を保存します)。
- 最初の辞書をトラバースし、2番目の辞書で同じキーの値を見つけます。存在しない場合は、最初のコンテンツのみが表示されます。存在する場合は、マージされます。
- 2番目の辞書をトラバースし、最初の辞書にないキーの値を見つけて、それを蓄積します。
- スプライスされたリストをファイルに保存します。
コアコード
2つのファイルの内容を読み取る関数read_bookを定義します。重要なポイントは次のとおりです。
- open関数はファイルを開くために使用され、ファイルのエンコードはUTF-8です。
- readlinesは、すべての行を読み取り、リストを返すために使用されます。
- splitは、文字列を配列に分割するために使用されます。
def read_book():"""コンテンツを読む"""
# ファイルを読む
file1 =open('book1.txt','r', encoding='UTF-8')
lines1 = file1.readlines()
file1.close()for line in lines1:
line = line.strip() #空白にする
content = line.split(',')
book1[content[0]]= content[1]
# 別の方法、別のファイルを読む,閉じる必要はありません。自動的に閉じます
withopen('book2.txt','r', encoding='UTF-8')as file2:
lines2 = file2.readlines()for line in lines2:
line = line.strip() #空白にする
content = line.split(',')
book2[content[0]]= content[1]
コンテンツをマージして保存する関数を定義します。重要なポイントは次のとおりです。
- appendは、配列に新しい要素を追加するために使用されます。
- dict.keys関数は、すべてのキーを返すために使用されます。
- 結合関数は、配列を文字列に変換し、対応する文字で分割するために使用されます。
- writelinesは、すべての行をファイルに書き込むために使用されます。
- 構文では、実行が終了すると、リソースが自動的に閉じて解放されます。
def merge_book():"""コンテンツをマージする"""
lines =[] #空のリストを定義する
header ='名前\t電話\tテキスト\n'
lines.append(header)
# 最初の辞書をトラバースする
for key in book1:
line =''if key in book2.keys():
line = line +'\t'.join([key, book1[key], book2[key]])
line +='\n'else:
line = line +'\t'.join([key, book1[key],' *****'])
line +='\n'
lines.append(line)
# 2番目のものをトラバースし、最初のものに含まれていないものを書き込みます
for key in book2:
line =''if key not in book1.keys():
line = line +'\t'.join([key,' *****', book2[key]])
line +='\n'
lines.append(line)
# book3に書き込む
withopen('book3.txt','w', encoding='UTF-8')as f:
f.writelines(lines)
全体的な呼び出しは次のとおりです。
if __name__ =='__main__':
# コンテンツを読む
read_book()
# コンテンツをマージする
merge_book()
# print(book1)
# print(book2)
最後のスプライシング後に生成されたファイルは次のとおりです。

上記の2つの例を通じて、ファイルおよびディレクトリ操作のいくつかの方法と手順を大まかに理解できます。
Recommended Posts