Excelを比較し、Pythonウィンドウ関数を学ぶ

**総記事245 /張Junhong **
Sqlに精通している学生は、Sqlのウィンドウ関数について聞いたことがあるはずです。ウィンドウ関数をマスターすれば、Sqlに習熟していると言え、Pythonにも同様のウィンドウ関数があると感じます。
例を見てみましょう。以下は、特定のプラットフォームでの一定期間における1日あたりの売上高の表です。ビジネスに精通している人は常識を持っている必要があります。つまり、空と空の間のデータは、電気など、直接比較できないことがよくあります。取引プラットフォームでの月曜日と日曜日の注文量。日と日の比較はありませんが、週7日は基本的にすべてのビジネス状況をカバーするため、ほとんどの状況は週と週の間で比較可能です。
週と週の間の時間が長いと、週の計算方法が関係します。自然な週に従って計算すると、1年は約52週間になります。いわゆるビッグデータの時代では、データは間違いなく少し小さいので、どうすればよいですか。比較的完全なビジネスシナリオをカバーできるだけでなく、データポイントを増やすこともできますか? 1つの方法は、スライドして追加し、スライドして7日間追加することです。たとえば、これは火曜日から次の月曜日までの7日間で、比較的完全なビジネスシナリオをカバーします。たとえば、今週の金曜日から次の木曜日も7日間で、これもカバーします。より包括的なビジネスシナリオ。
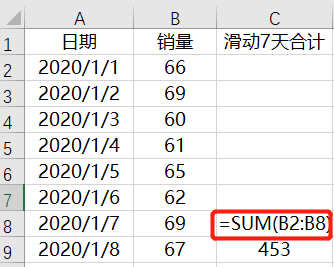
現在、毎日のデータがありますが、7日間のスライディング合計をどのように達成できますか?実際、Excelでは比較的簡単です。7行目に式の最初の7行を追加するための式を直接記述し、式を入力して7日間のスライド追加を完了することができます。以下に示すように:
この7日間のスライディングサム関数をPythonで実装する場合は、ローリング関数を直接使用できます。ローリング関数で最も重要なパラメーターの1つは、スライディング日を示すために使用されるウィンドウです。具体的な実装コードは次のとおりです。
import pandas as pd
df = pd.read_csv(r''python_rolling.csv')
df.rolling(window =7).sum()
上記のコードを実行すると、次の結果が得られます。

結果はExcelで得られた結果と完全に一致していることがわかります。
dfでローリングのみを実行する場合、dfは指定された日数だけスライドし、スライド後の日数は計算しません。次に、スライドデータに対して合計関数を呼び出して、スライドデータに対して合計操作を実行します。 dfをローリングした後、合計以外の操作を実行できます。より一般的に使用される操作は次のとおりです。
カウント:count()
平均を見つける:men()
最適な値を見つける:min()、max()
分散を見つける:var()
標準偏差を見つける:std()
これらの一般的に使用される要約操作に加えて、7日間のスライドの値を合計してから1を加算するなどのカスタム関数を使用することもできます。これは、次の方法で実現できます。
import numpy as np
def div(x):return np.sum(x)+1
df.rolling(window =7).agg(div)
上記のコードを実行して、次の結果を取得します。

ご覧のとおり、最初の累積値は453で、これは452に1を加算します。
最初に関数をカスタマイズしてから、aggを介して関数を呼び出し、カスタム関数の機能を実現します。
上記は、Pythonスライディングウィンドウ関数の使用法の基本的な紹介です。