Centos7はhadoop2.10高可用性(HA)を構築します
この記事では、centos7でhadoop2.10高可用性クラスターを構築する方法を紹介します。最初に、6台のマシンを準備します。2nn(namenode); 4 dn(datanode); 3 jns(journalnodes)
| IP | ホスト名 | プロセス |
|---|---|---|
| 192.168.30.141 | s141 | nn1(namenode),zkfc(DFSZKFailoverController),zk(QuorumPeerMain) |
| 192.168.30.142 | s142 | dn(datanode), jn(journalnode),zk(QuorumPeerMain) |
| 192.168.30.143 | s143 | dn(datanode), jn(journalnode),zk(QuorumPeerMain) |
| 192.168.30.144 | s144 | dn(datanode), jn(journalnode) |
| 192.168.30.145 | s145 | dn(datanode) |
| 192.168.30.146 | s146 | nn2(namenode),zkfc(DFSZKFailoverController) |
各マシンのjpsプロセス:
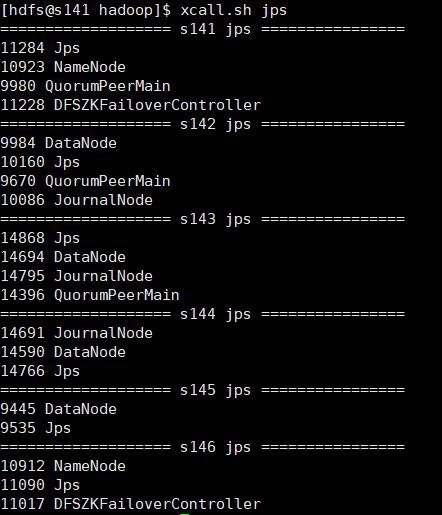
vmware仮想マシンを使用しているため、マシンを構成した後、残りのマシンのクローンを作成し、ホスト名とIPを変更して、各マシンの構成が統一されるようにします。各マシン構成は、hdfsユーザーとユーザーを追加します。グループ化して、jdk環境を構成し、hadoopをインストールします。今回は、hdfsユーザーの下で可用性の高いクラスターを構築します。参照できるのは、centos7 buildhadoop2.10疑似配布モードです。
可用性の高いクラスターをインストールするための手順と詳細は次のとおりです。
1. 各マシンのホスト名とホストを設定します
ホストファイルを変更します。ホストを設定したら、ホスト名を使用してマシンにアクセスできます。これはより便利です。次のように変更します。
127.0.0.1 locahost
192.168.30.141 s141
192.168.30.142 s142
192.168.30.143 s143
192.168.30.144 s144
192.168.30.145 s145
192.168.30.146 s146
- sshパスワードなしログインを設定します。s141とs146はどちらもネームノードであるため、これら2つのマシンからパスワードなしですべてのマシンにログインすることをお勧めします。hdfsとrootの両方にパスワードなしログインを設定することをお勧めします。
s141をnn1に、s146をnn2に設定します。sshを介して他のマシンに秘密なしでログインできるようにするには、s141とs146が必要です。したがって、s141とs146マシンのhdfsユーザーの下でキーペアを生成し、s141とs146の公開キーを設定する必要があります。それを他のマシンに送信し、〜/ .ssh / authorized_keysファイルに入れます。これにより、公開キーを追加するすべてのマシン(自分自身を含む)でより正確になります。
s141およびs146マシンでキーペアを生成します。
ssh-keygen -t rsa -P ''-f ~/.ssh/id_rsa
id_rsa.pubファイルの内容をs141-s146マシンの/home/hdfs/.ssh/authorized_keysに追加します。他のマシンには当面authorized_keysファイルがないため、他のマシンにすでにauthorized_keysがある場合は、id_rsa.pubの名前をauthorized_keysに変更できます。ファイルがid_rsa.pubのコンテンツをファイルに追加できるようになった後、リモートレプリケーションでscpコマンドを使用できます。
他のマシンにコピーされたs141マシン公開鍵
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s145:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s146:/home/hdfs/.ssh/id_rsa_141.pub
s146マシンの公開鍵を他のマシンにコピーします
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s145:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s146:/home/hdfs/.ssh/id_rsa_146.pub
各マシンで、catを使用してauthorized_keysファイルにキーを追加できます
cat id_rsa_141.pub >> authorized_keys
cat id_rsa_146.pub >> authorized_keys
このとき、authorized_keysファイルのアクセス許可を644に変更する必要があります(sshシークレットログインの失敗は、このアクセス許可の問題が原因であることが多いことに注意してください)
chmod 644 authorized_keys
- hadoop構成ファイルを構成します($ {hadoop_home} / etc / hadoop /)
構成の詳細:
注:s141とs146の構成はまったく同じで、特にsshです。
- ネームサービスを構成する
[ hdfs-site.xml]<property><name>dfs.nameservices</name><value>mycluster</value></property>
- dfs.ha.namenodes.[nameservice ID]
[ hdfs-site.xml]<!--myuclusterの下の名前ノードの2つのID--><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property>
- dfs.namenode.rpc-address.[nameservice ID].[name node ID]
[ hdfs-site.xml]
各nnのrpcアドレスを構成します。
< property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>s141:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>s146:8020</value></property>
- dfs.namenode.http-address.[nameservice ID].[name node ID]
webuiポートを構成します
[ hdfs-site.xml]<property><name>dfs.namenode.http-address.mycluster.nn1</name><value>s141:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>s146:50070</value></property>
- dfs.namenode.shared.edits.dir
ノード共有編集ディレクトリに名前を付けます。3つのジャーナルノードノードを選択します。ここでは、s142、s143、s1443台のマシンを選択します。
[ hdfs-site.xml]<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://s142:8485;s143:8485;s144:8485/mycluster</value></property>
- dfs.client.failover.proxy.provider.[nameservice ID]
HAフェイルオーバー用にJavaクラスを構成し(構成は固定されています)、クライアントはそれを使用してアクティブなノードを判別します。
[ hdfs-site.xml]<property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property>
- dfs.ha.fencing.methods
スクリプトリストまたはjavaクラス、nn。災害復旧保護のアクティブ化された状態。
[ hdfs-site.xml]<property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hdfs/.ssh/id_rsa</value></property>
- fs.defaultFS
hdfsファイルシステムネームサービスを構成します。ここでのMyclusterは、上記で構成されたdfs.nameservicesです。
[ core-site.xml]<property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property>
- dfs.journalnode.edits.dir
JNストアが編集を保存するローカルパスを構成します。
[ hdfs-site.xml]<property><name>dfs.journalnode.edits.dir</name><value>/home/hdfs/hadoop/journal</value></property>
完全な構成ファイル:
core-site.xml
<? xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>fs.defaultFS</name><value>hdfs://mycluster/</value></property><property><name>hadoop.tmp.dir</name><value>/home/hdfs/hadoop</value></property></configuration>
hdfs-site.xml
<? xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.hosts</name><value>/opt/soft/hadoop/etc/dfs.include.txt</value></property><property><name>dfs.hosts.exclude</name><value>/opt/soft/hadoop/etc/dfs.hosts.exclude.txt</value></property><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>s141:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>s146:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>s141:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>s146:50070</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://s142:8485;s143:8485;s144:8485/mycluster</value></property><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hdfs/.ssh/id_rsa</value></property><property><name>dfs.journalnode.edits.dir</name><value>/home/hdfs/hadoop/journal</value></property></configuration>
mapred-site.xml
<? xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
yarn-site.xml
<? xml version="1.0"?><configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>s141</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
- 展開の詳細
1 )jnノードでそれぞれjnプロセス(s142、s143、s144)を開始します
hadoop-daemon.sh start journalnode
2 )jnを開始した後、2つのNN間でディスクメタデータの同期を実行します
a)まったく新しいクラスターの場合は、最初にファイルシステムをフォーマットし、1つのnnでのみ実行する必要があります。
[s141|s146]
hadoop namenode -format
b)非HAクラスターをHAクラスターに変換する場合は、元のNNのメタデータを別のNNにコピーします。
1.ステップ1
s141マシンで、hadoopデータをs146に対応するディレクトリにコピーします。
scp -r /home/hdfs/hadoop/dfs hdfs@s146:/home/hdfs/hadoop/
2.ステップ2
新しいnn(フォーマットされていないnn、ここではs146)で次のコマンドを実行して、スタンバイ状態のブートを実現します。注:s141namenodeは開始状態である必要があります(実行可能:hadoop-daemon.sh start namenode)。
hdfs namenode -bootstrapStandby
s141 nameノードが開始されていない場合、図に示すように失敗します。
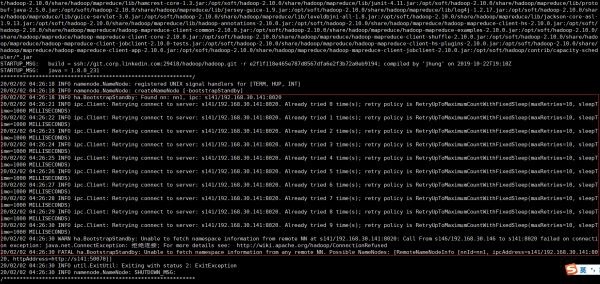
s141 nameノードを起動した後、s141でコマンドを実行します。
hadoop-daemon.sh start namenode
次に、standby bootコマンドを実行します。注:図に示すように、フォーマットするかどうかを確認し、Nを選択します。
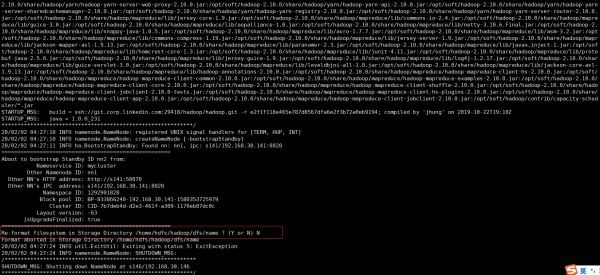
- ステップ3
いずれかのNNで次のコマンドを実行して、jnノードへの編集ログの送信を完了します。
hdfs namenode -initializeSharedEdits
実行中にjava.nio.channels.OverlappingFileLockExceptionエラーが報告された場合:
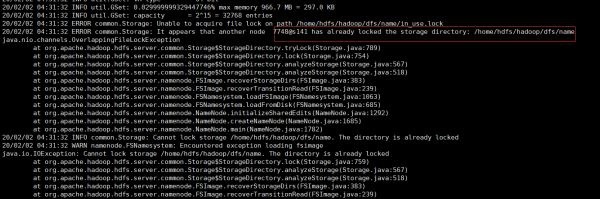
namenodeが開始中であり、namenodeノードを停止する必要があることを説明します(hadoop-daemon.sh stop namenode)
実行後、s142、s143、およびs144に編集データがあるかどうかを確認します。ここで、編集ログデータを含む本番myclusterディレクトリを次のように確認します。
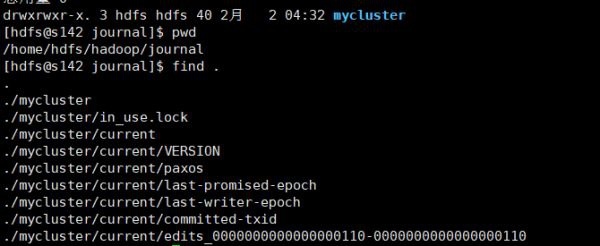
4.ステップ4
すべてのノードを起動します。
s141で名前ノードとすべてのデータノードを開始します。
hadoop-daemon.sh start namenode
hadoop-daemons.sh start datanode
s146で名前ノードを開始します
hadoop-daemon.sh start namenode
この時点で、ブラウザでhttp://192.168.30.141:50070/とhttp://192.168.30.146:50070/にアクセスすると、両方のネームノードがスタンバイになっていることがわかります。
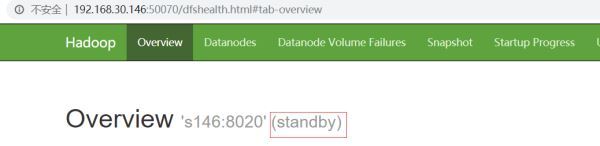
このとき、コマンドを手動で使用して、そのうちの1つをアクティブ状態に切り替える必要があります。ここでは、s141(nn1)をアクティブに設定します。
hdfs haadmin -transitionToActive nn1
S141は現在アクティブです
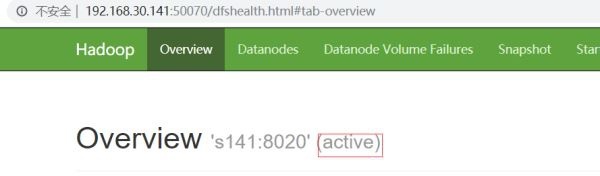
hdfs haadmin一般的に使用されるコマンド:
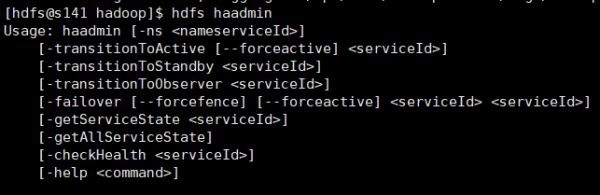
これまでのところ、手動の災害復旧の高可用性構成は完了していますが、この方法は賢くなく、災害復旧を自動的に検知できないため、自動災害復旧構成を以下に紹介します。
- 自動災害復旧構成
zookeeperquarumとzk災害復旧コントローラー(ZKFC)の2つのコンポーネントを導入する必要があります
zookeeperクラスターをセットアップし、s141、s142、s143 3台のマシンを選択し、zookeeperをダウンロードします:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.6
1)動物園の飼育係を解凍します。
tar -xzvf apache-zookeeper-3.5.6-bin.tar.gz -C /opt/soft/zookeeper-3.5.6
2)環境変数を構成し、/ etc / profileにzk環境変数を追加して、/ etc / profileファイルを再コンパイルします。
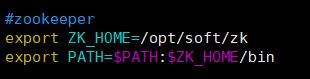
次のようにコードコードをコピーします。
source /etc/profile
3)zk構成ファイルを構成します。3台のマシンの構成ファイルが統合されます。
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage,/tmp here is just
# example sakes.
dataDir=/home/hdfs/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase thisif you need to handle more clients
# maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
# autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
# autopurge.purgeInterval=1
server.1=s141:2888:3888
server.2=s142:2888:3888
server.3=s143:2888:3888
4)それぞれ
s141の/ home / hdfs / zookeeper(zoo.cfg構成ファイルで構成されたdataDirパス)ディレクトリーに、値1(zoo.cfg構成ファイルのserver.1に対応)でmyidファイルを作成します。
s142の/ home / hdfs / zookeeper(zoo.cfg構成ファイルで構成されたdataDirパス)ディレクトリーに、値2(zoo.cfg構成ファイルのserver.2に対応)でmyidファイルを作成します。
s143の/ home / hdfs / zookeeper(zoo.cfg構成ファイルで構成されたdataDirパス)ディレクトリーに、値3(zoo.cfg構成ファイルのserver.3に対応)でmyidファイルを作成します。
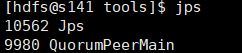
5)各マシンで個別にzkを起動します
zkServer.sh start
起動が成功すると、zkプロセスが表示されます。
hdfs関連の構成を構成します。
1)hdfsのすべてのプロセスを停止します
stop-all.sh
2)自動災害復旧を有効にするようにhdfs-site.xmlを構成します。
[ hdfs-site.xml]<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property>
3)core-site.xmlを構成し、zkの接続アドレスを指定します。
< property><name>ha.zookeeper.quorum</name><value>s141:2181,s142:2181,s143:2181</value></property>
4)上記の2つのファイルをすべてのノードに配布します。
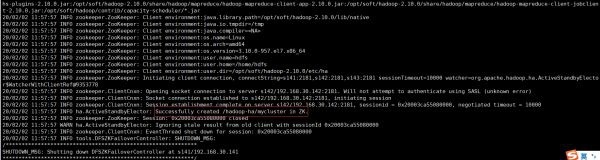
5)NN(s141)のいずれかで、ZKでHA状態を初期化します。
hdfs zkfc -formatZK
次の結果は成功を示しています。
zkをチェックインすることもできます。

6)hdfsクラスターを開始します
start-dfs.sh
各マシンプロセスを表示します。
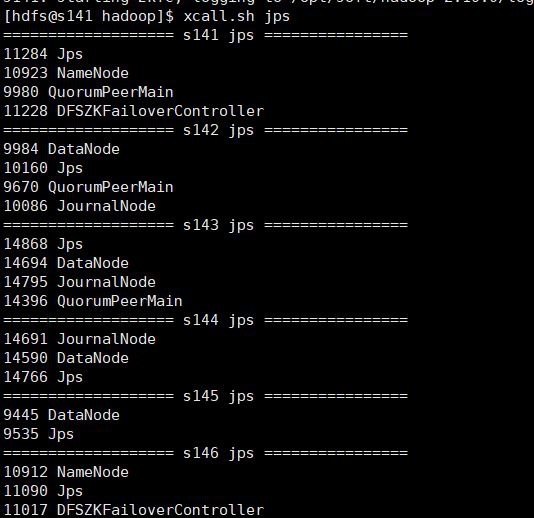
正常に開始し、webuiを見てください
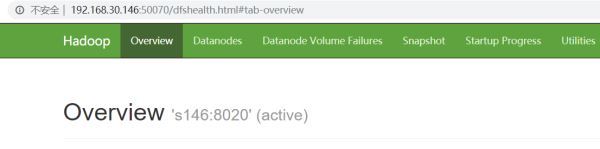
s146がアクティブです
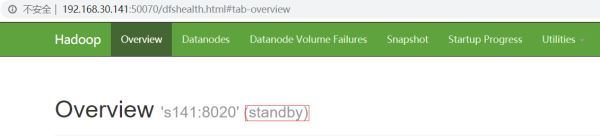
s141はスタンバイ状態です
これまでのところ、hadoop自動災害復旧HAが構築されています
総括する
上記は、Hadoop 2.10高可用性(HA)を構築するためのcentos7の導入です。これがすべての人に役立つことを願っています!