Python Automation(20)| Python操作のいくつかの方法について話すPDF(マージ、分割、ウォーターマーク、暗号化)

I.はじめに ###
みなさん、こんにちは。PythonでPDFを操作する場合について、以前に[**?PDF Bulk Merge **](https://mp.weixin.qq.com/s?__biz=MzI1MTUyMjc1Mg==&mid=2247485552&idx=1&sn=7e8d4ea5f5754b20d6d1acc545074b82&scene=21#wechat_redirect)を作成しました。この場合の本来の目的は、便利なスクリプトを提供することであり、原理の説明はあまりありません。これは、PDF処理用の非常に実用的なモジュール PyPDF2です。この記事では、このモジュールを分析します。主に、
osモジュールの包括的なアプリケーションglobモジュールの包括的なアプリケーションPyPDF2モジュールの操作
2.基本操作
多くの場合、PyPDF2インポートモジュールのコードは次のとおりです。
from PyPDF2 import PdfFileReader, PdfFileWriter
ここでは、次の2つのメソッドがインポートされます。
PdfFileReaderはリーダーとして理解できますPdfFileWriterはライターとして理解できます
次に、いくつかのケースを通じて、これら2つのツールの素晴らしさをさらに理解します。使用されているサンプルファイルは、5つの請求書のpdfです。
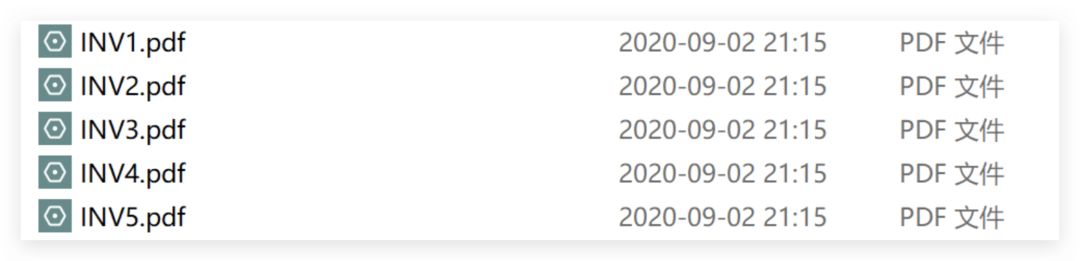
各請求書のPDFは、次の2ページで構成されています。

3、マージ
最初のタスクは、** 5つの請求書pdfを10ページに結合**することです。ここで、リーダーとライターはどのように連携する必要がありますか?
ロジックは次のとおりです。
- 読者はすべてのpdfを一度読みます
- リーダーは、読み取ったコンテンツをライターに渡します
- ライターが出力を新しいpdfに統合
ここには重要な知識のポイントもあります。リーダーは、読み取ったコンテンツをページごとにライターに配信することしかできません。
したがって、ロジックのステップ1とステップ2は、実際には独立したステップではありませんが、リーダーがpdfを読み取った後、pdfのすべてのページをループし、ページごとに書き込みます。端末。最後に、すべての読み取り作業が終了するまで待ってから出力してください。
コードを見ると、アイデアがより明確になります。
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxxxxx'
pdf_writer =PdfFileWriter()for i inrange(1,6):
pdf_reader =PdfFileReader(path +'/INV{}.pdf'.format(i))for page inrange(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))withopen(path + r'\PDFをマージ\merge.pdf','wb')as out:
pdf_writer.write(out)
最終出力ではすべてのコンテンツを同じライターに配信する必要があるため、ライターの初期化はループ本体の外側で行う必要があります。
ループ本体内にある場合は、** pdfにアクセスして読み取るたびに新しいライターが生成されます**。そのため、ライターに渡された各リーダーのコンテンツは繰り返し上書きされます。 、合併要件を達成できません!
ループ本体の先頭のコード:
for i inrange(1,6):
pdf_reader =PdfFileReader(path +'/INV{}.pdf'.format(i))
目的は、各サイクルで新しいpdfファイルを読み取り、その後の操作のためにリーダーに渡すことです。実際、この書き込み方法はあまりお勧めできません。各pdf名は非常に規則的であるため、循環する数を直接手動で指定できます。より良い方法は、 globモジュールを使用することです。
import glob
for file in glob.glob(path +'/*.pdf'):
pdf_reader =PdfFileReader(path)
コードでは、 pdf_reader.getNumPages():リーダーのページ数を取得でき、 rangeを使用すると、リーダーのすべてのページをトラバースできます。
pdf_writer.addPage(pdf_reader.getPage(page))は、現在のページをライターに渡すことができます。
最後に、 withを使用して新しいpdfを作成し、ライターのpdf_writer.write(out)メソッドで出力します。
第四に、分割
マージ操作におけるリーダーとライターの協力を理解していれば、分割は簡単に理解できます。ここでは、例として「INV1.pdf」を2つの別々のpdfドキュメントに分割することを取り上げます。ロジックのストローク:
- PDFドキュメントを読むためのリーダー
- リーダーはページごとにライターに渡されます
- Writerは、ページを取得するたびにすぐに出力します
このコードロジックを通じて、ライターの初期化と出力の位置は、ループの外側ではなく、PDFループの各ページを読み取るループ本体内にある必要があることも理解できます。
コードは非常に単純です。
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxx'
pdf_reader =PdfFileReader(path +'\INV1.pdf')for page inrange(pdf_reader.getNumPages()):
# 各ページに移動して、ライターを1人ずつ生成します
pdf_writer =PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
# ライターはページを追加するとすぐにpdfを出力します
withopen(path +'\INV1-{}.pdf'.format(page +1),'wb')as out:
pdf_writer.write(out)
5、透かし
今回の作業は、次の画像を透かしとして INV1.pdfに追加することです。
1つ目は準備作業です。透かしとして使用する必要のある画像をWordに挿入し、適切な位置を調整してPDFファイルとして保存します。次に、コードをコーディングでき、「copy」モジュールを追加で使用する必要があります。具体的な説明を次の図に示します。
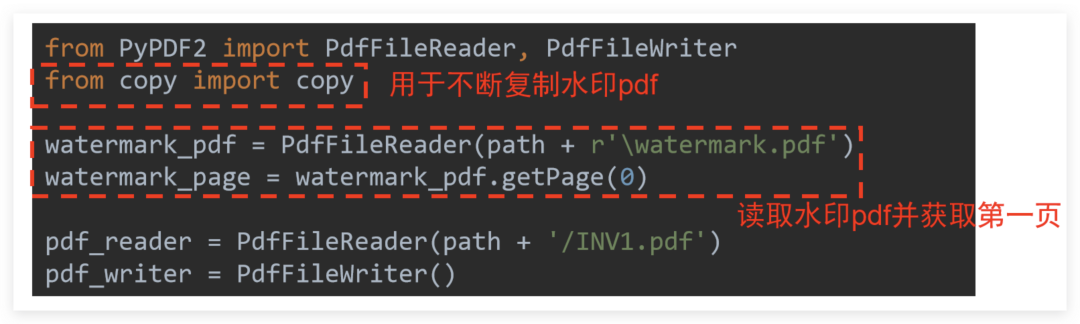
リーダーとライターを初期化し、最初に透かしPDFページを読むことです。コアコードは少し理解しにくいです。
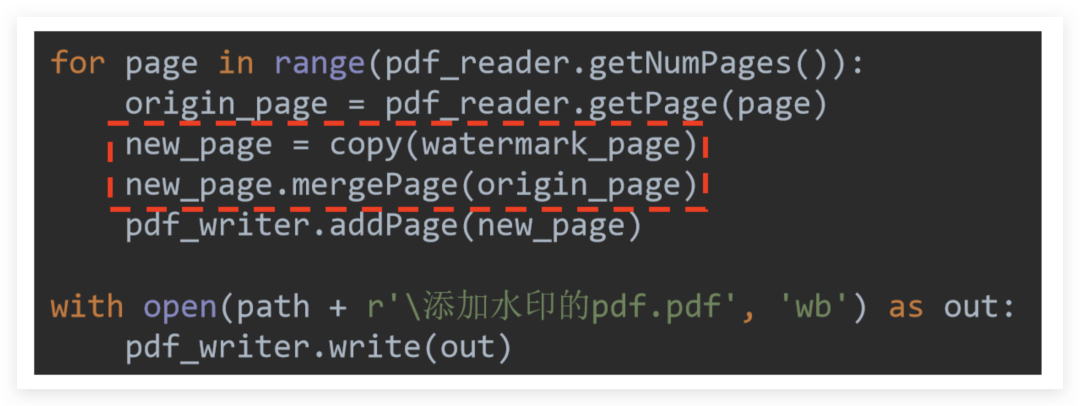
透かしは基本的に透かしを入れたPDFページと透かしを入れる必要があるすべてのページをマージします
透かしを入れる必要のあるPDFはページ数が多く、透かしを入れたPDFは1ページしかないため、透かしを入れたPDFを直接マージすると、最初のページが追加され、透かしを入れたPDFページがなくなるので抽象的に理解できます。**
したがって、直接マージすることはできませんが、透かしを入れたPDFページを新しいページスタンバイ new_pageに継続的に「コピー」してから、 .mergePageメソッドを使用して各ページとのマージを完了し、マージされたPDFページをマージする必要があります。このページは、最終的な統合出力のためにライターに渡されます。
.mergePageの使用に関して:次のpage.mergePageに表示されます(上のページに表示されます)、最終的な効果を図に示します。

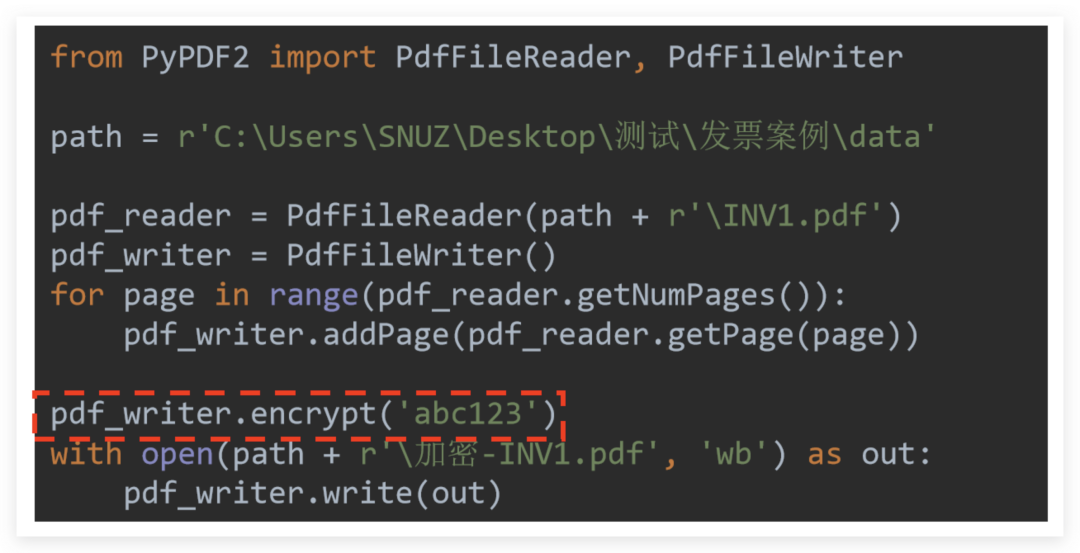
6、暗号化
暗号化は非常に簡単です。覚えておいてください:「暗号化はライターの暗号化用です」
したがって、関連する操作が完了した後にのみ、 pdf_writer.encrypt(password)を呼び出す必要があります。
例として、単一のPDFの暗号化を取り上げます。
最後に書かれました
もちろん、PDFのマージ、分割、暗号化、および透かし入れに加えて、Pythonを使用してExcelとWordを組み合わせて、より多くの自動化要件を実現することもできます。これらは、読者が自分で開発する必要があります。
最後に、Pythonオフィス自動化のコアの1つが、複雑なタスクを自動化するためのバッチ操作フリーハンズであることを皆さんが理解できることを願っています。