How to avoid running away when deleting the library
Delay node solution##
Deleting a database is also an old slogan. It can be seen that data is accidentally deleted during the operation and maintenance of the database, or the developed code has bugs, which causes accidental deletion of data. However, there are many solutions for recovering or preventing accidental deletion. For example, the SQL management system first submits the SQL to be executed to the administrator for review, and then the administrator backs up a mirror database, executes the SQL on the mirror, and executes it. Restore the image. In this way, the possibility of misoperation can be greatly reduced by passing through layers of checks.
In addition, the binlog log can also be used to recover data from misoperations, so all databases running online will enable the binlog log function. There is also the delay node to be introduced in this section: in a Replication cluster, you can set a delay node, the data synchronization time of this node is slower than other nodes in the cluster, when other nodes have misoperation, if the delay The data of the node can be recovered from the delayed node without being affected.
But if the existing databases are all PXC clusters, can this solution be used without Replication clusters? It is also possible. The PXC cluster and the Replication cluster are not mutually exclusive. We can set a node in the PXC cluster as the Master, and then add a delay node to the Slave, so that these two nodes form a Replication cluster for data synchronization OK. As follows:
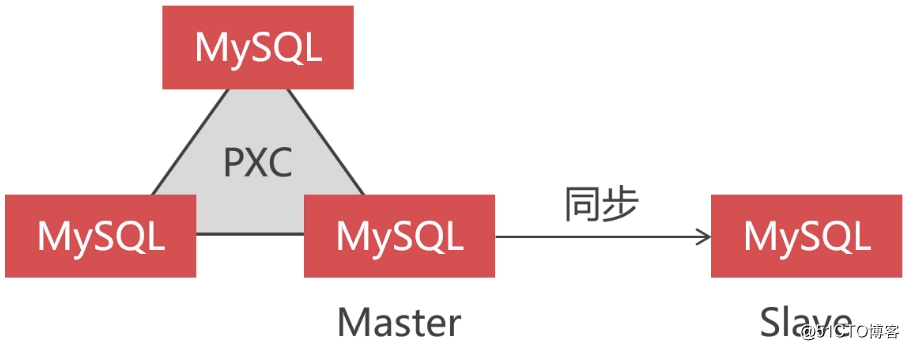
This section will briefly demonstrate how to build a delay node under this heterogeneous cluster. Here I have prepared a PXC cluster and a database used as a delay node in advance:
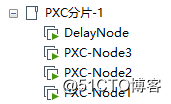
Here, the PXC-Node3 in the PXC cluster is used as the Master, and it forms a master-slave with DelayNode, and DelayNode naturally acts as a delay node.
For the construction of PXC cluster and Replication cluster, you can refer to the following articles, which will not be explained here due to limited space:
- Build a PXC cluster under CentOS8
- Build a highly available Replication cluster to archive large amounts of cold data
Configure delay node for PXC node###
Next, start hands-on practice. First, you need to stop the MySQL service on these two nodes:
systemctl stop mysqld
The configuration files of the master and slave nodes must enable GTID, otherwise the delay node cannot be used to retrieve data. The configuration to be added to the master node is as follows:
[ root@PXC-Node3 ~]# vim /etc/percona-xtradb-cluster.conf.d/mysqld.cnf
[ mysqld]...
# Set the id of the node
server_id=3
# Open binlog
log_bin=mysql_bin
# Turn on GTID
gtid_mode=ON
enforce_gtid_consistency=1
The configuration that needs to be added from the node is as follows:
[ root@delay-node ~]# vim /etc/my.cnf
[ mysqld]...
server_id=102
log_bin=mysql_bin
# The slave node needs to turn on the relay_log
relay_log=relay_bin
gtid_mode=ON
enforce_gtid_consistency=1
After completing the configuration of the configuration file, start these two nodes:
systemctl start mysqld
Then configure the master-slave relationship between Slave and Master, enter the MySQL command line terminal of Master, and query the binary log currently being used by the Master and the current execution binary log location through the following statement:
mysql> flush logs;--Refresh log
mysql> show master status;+----------------------+----------+--------------+------------------+-------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+----------------------+----------+--------------+------------------+-------------------+| PXC-Node3-bin.000003|154||||+----------------------+----------+--------------+------------------+-------------------+1 row inset(0.00 sec)
After recording the above execution results, enter the MySQL command line terminal of Slave and execute the following statements respectively:
mysql> stop slave;--Stop master-slave synchronization
mysql> change master to master_log_file='PXC-Node3-bin.000003', master_log_pos=154, master_host='192.168.190.134', master_port=3306, master_user='admin', master_password='Abc_123456';--Configure the connection information of the Master node and where to start copying from the Master binary log
mysql> start slave;--Start master-slave synchronization
- **Tips: **Usually configuring master-slave synchronization will create a separate account for synchronization. Here, for the sake of simplicity, the existing account is used directly. In addition, if you do not want to set the binlog offset of the main library, you can use the
master_auto_position=1parameter
After configuring the master-slave relationship, use the show slave status\G; statement to view the master-slave synchronization status. The values of Slave_IO_Running and Slave_SQL_Running are both Yes to indicate that the master-slave synchronization status is normal:
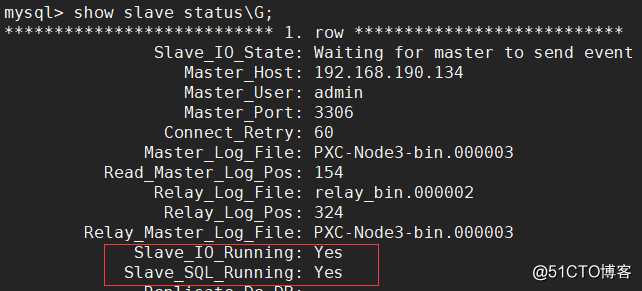
After the master-slave relationship configuration is completed, then test whether the master-slave data synchronization is normal. Execute some SQL statements on the Master, as follows:
mysql> create database test_db;
mysql> use test_db;
mysql> CREATE TABLE `student`(`id`int(11) NOT NULL,`name`varchar(20) NOT NULL,
PRIMARY KEY(`id`));
mysql> INSERT INTO `test_db`.`student`(`id`,`name`)VALUES(1,'Jack');
After the execution is complete, check whether there is normal synchronization on the Slave:
mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema || sys || test_db |+--------------------+5 rows inset(0.00 sec)
mysql> use test_db;
mysql> select *from student;+----+------+| id | name |+----+------+|1| Jack |+----+------+1 row inset(0.00 sec)
mysql>
After verifying that the master and slave nodes can synchronize data normally, we can set the synchronization delay of the slave node. Execute the following statements on the Slave node:
mysql> stop slave;
mysql> change master to master_delay=1200;--Set the synchronization delay to 1200 seconds
mysql> start slave;
Similarly, after reconfiguring the master-slave relationship, you need to confirm that the master-slave synchronization status is normal:
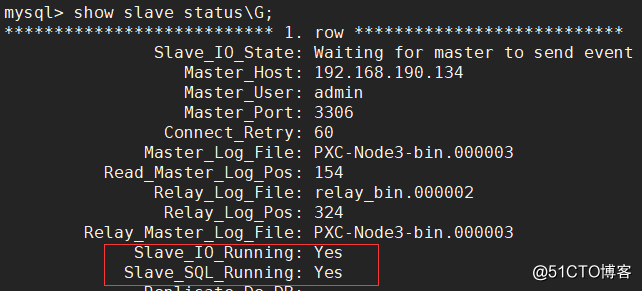
Simulate accidental deletion of data###
Then demonstrate the function of the delay node. First go to the Master node and delete the data in the student table to simulate the accidental deletion:
mysql> use test_db;
mysql>deletefrom student;--Delete all data in the student table
mysql> select *from student;--No data can be queried on Master
Empty set(0.00 sec)
mysql>
At this time, due to the delayed synchronization, the deleted data can still be queried normally on the Slave node:
mysql> use test_db;
mysql> select *from student;+----+------+| id | name |+----+------+|1| Jack |+----+------+1 row inset(0.00 sec)
mysql>
Now it's GTID's turn to play. We have to let the Slave node skip the GTID of the delete operation, and then let the Master restore the data from the Slave. Otherwise, if the slave synchronizes the GTID, the data on the slave node will also be deleted. Even if the master data is restored before synchronization, it will cause the problem of inconsistent master and slave data.
GTID is recorded in the binlog. Since the accidental deletion is performed on the Master, first use the show master logs; statement to query the name of the binlog log on the Master node:
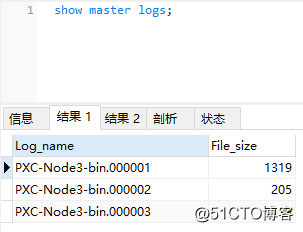
Next, we need to find the record of the accidental deletion operation and its GTID in the binlog file. Because the serial number of the binlog file is increasing, the most recent operation is generally recorded in the binlog file with the largest serial number. Therefore, execute the show binlog events in'PXC-Node3-bin.000003'; statement, and find the record of the accidental deletion operation and its GTID from the result set. As shown below:
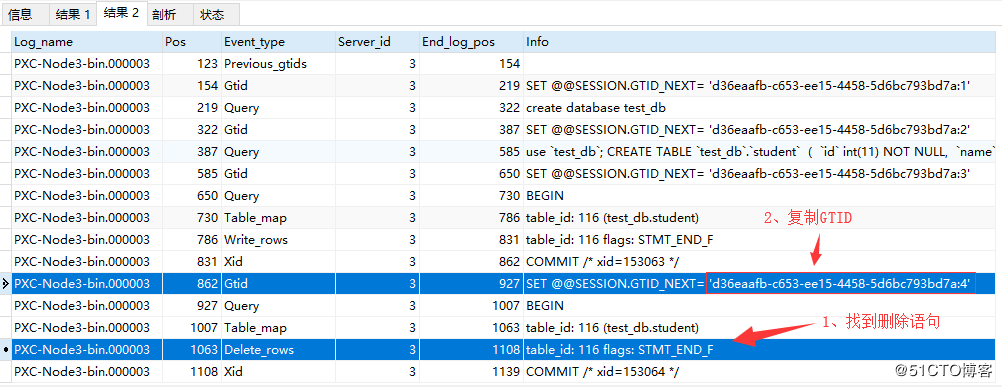
After finding the GTID of the accidental deletion operation on the Master node, copy the GTID. Then execute the following statements on the Slave node:
mysql> stop slave;--Stop master-slave synchronization
mysql>set gtid_next='d36eaafb-c653-ee15-4458-5d6bc793bd7a:4';--Set GTID to be skipped
mysql> begin; commit;--Open and commit the transaction, that is, simulate the Slave to synchronize the GTID, and the subsequent synchronization will not be performed, thus achieving the skipping effect
mysql>set gtid_next='automatic';--Restore gtid settings
mysql> change master to master_delay=0;--Setting the synchronization delay to 0 is to skip the GTID for immediate synchronization
mysql> start slave;
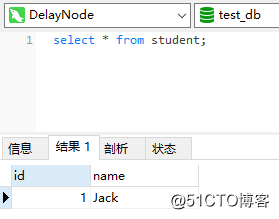
After completing the above operations, there are still accidentally deleted data on the Slave at this time:
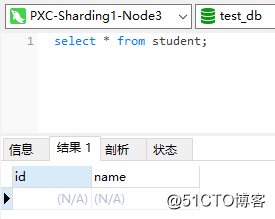
And the student table on the Master is still empty:
After completing the above operations, restore the synchronization delay setting:
mysql> stop slave;
mysql> change master to master_delay=1200;--Set the synchronization delay to 1200 seconds
mysql> start slave;
Recover the data deleted by mistake by the Master node###
After letting the Slave node skip the GTID of the accidental deletion operation, it can start to restore the data of the Master node. First stop the business system's read and write operations on the PXC cluster where the Master node is located to avoid data confusion during the restoration process. Then export the data of the Slave node:
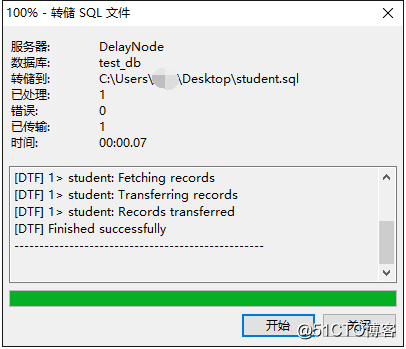
Create a temporary database on the Master node. This is to import the data into the business database after the temporary database verifies the correctness of the data to avoid accidents:
create database temp_db;
Then import the data:
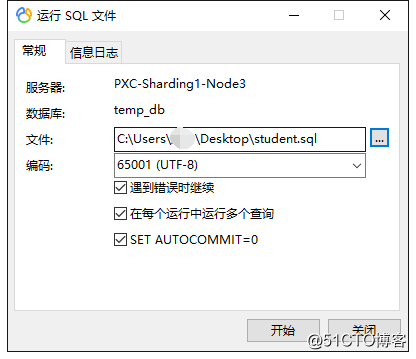
Rename the data table on the Master node:
rename table test_db.student to test_db.student_bak;
Migrate the data table of the temporary database to the business database:
rename table temp_db.student to test_db.student;
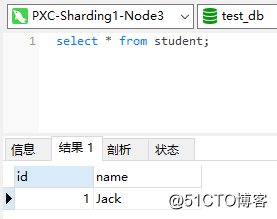
At this point, the accidentally deleted data on the Master node is successfully restored:
Log flashback scheme##
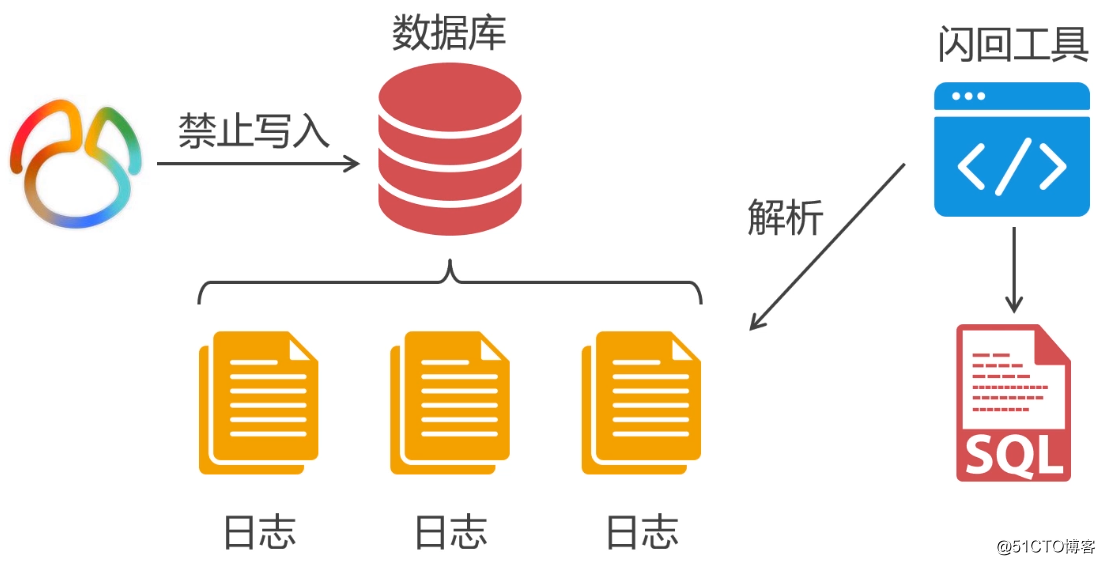
As mentioned earlier, in addition to the solution of delayed nodes, data recovery can also be achieved by using binlog logs. This method of recovering data is usually called log flashback. The reason why this scheme is introduced here is because the delay node scheme has certain limitations: once the problem is not found and solved in the delay phase, then after the master-slave data is synchronized, the slave node cannot be used to achieve Recovery of accidental deletion.
The log flashback solution is simpler than the delayed node solution, no additional nodes are required, and the current node can be used to recover data. However, this solution is not all-powerful. For example, the binlog log does not record the data deleted by operations such as drop table and truncate table, so it cannot be recovered through the log. However, these two programs do not conflict, and can be used at the same time to increase the possibility of data recovery.
The premise of log flashback is to turn on the binlog log, and then parse the binlog log into SQL through some flashback tools, and then convert the delete statement in SQL into an insert statement, or find the insert of the data that was deleted by mistake Statement. Finally, these insert` statements are executed again in the database, so that data recovery is realized:
There are many flashback tools. In this article, binlog2sql is used, which is an open source MySQL log flashback tool written by Dianping based on Python.
Install binlog2sql
The installation steps of the tool are as follows:
# Install front tools
[ root@PXC-Node3 ~]# yum install -y epel-release
[ root@PXC-Node3 ~]# yum install -y git python3-pip
# Clone the source code library of binlog2sql and enter the source directory
[ root@PXC-Node3 ~]# git clone https://github.com/danfengcao/binlog2sql.git && cd binlog2sql
# Install the Python library that binlog2sql depends on
[ root@PXC-Node3 ~/binlog2sql]# pip3 install -r requirements.txt
Configure the following parameters in the MySQL configuration file, because binlog2sql is parsed based on binlog in row format:
[ mysqld]...
binlog_format = row
binlog_row_image = full
Simulate accidental deletion of data###
I have a product table here with the following data:
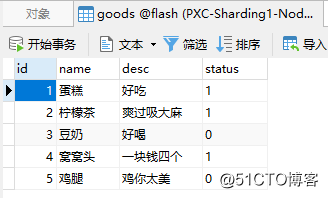
Use the delete statement to delete the data in the table to simulate accidental deletion:
deletefrom flash.goods;
Then insert some data to simulate the newly added data after accidental deletion:
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(6,'apple','xxxx','1');
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(7,'banana','xxxx','1');
Restore data through binlog2sql###
Preparation before recovery:
- Stop application of read and write operations to the database to avoid overwriting newly written data after restoration
- Hot backup of the database to ensure that the restoration work is foolproof. For backup related content, please refer to: [Detailed explanation of various database backup and restoration postures] (https://blog.51cto.com/zero01/2468469)
- Clear all records of the data table that needs to restore data to avoid conflicts between primary key and unique key constraints
Because the item table is to be restored, all records in the item table are cleared:
deletefrom flash.goods;
It was mentioned earlier that recent operations are generally recorded in the binlog file with the largest serial number, so the binlog file name in the database must be queried:
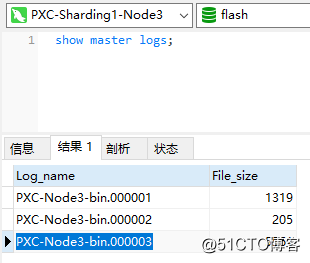
Then use binlog2sql to parse the specified binlog log, the specific commands are as follows:
[ root@PXC-Node3 ~/binlog2sql]# python3 binlog2sql/binlog2sql.py -uadmin -p'Abc_123456'-dflash -tgoods --start-file='PXC-Node3-bin.000003'>/home/PXC-Node3-bin.000003.sql
binlog2sql/binlog2sql.py: the executed Python file- u: account used to connect to the database- p: the password of the database account- d: Specify the name of the logical library- t: specify the name of the data table- - start-file: specify the file name of the binlog to be parsed/home/PXC-Node3-bin.000003.sql: Specify which file to write the SQL generated by the analysis
Then check the parsed SQL content: cat /home/PXC-Node3-bin.000003.sql. Here is a screenshot of the useful part, as shown in the figure below, you can see that the delete statement and the insert statement have the data we want to restore:

The next step is to get these statements. Either convert the delete statement into an insert statement, or directly copy the SQL statement of the insert part to the database for execution. I will copy the insert statement directly here:
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(1,'cake','good to eat','1'); #start 3170 end 3363 time 2020-01-2718:00:11
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(2,'lemon tea','Cool off smoking marijuana','1'); #start 3459 end 3664 time 2020-01-2718:00:56
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(3,'Soy milk','Delicious','0'); #start 3760 end 3953 time 2020-01-2718:01:10
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(4,'Wowotou','A dollar for four','1'); #start 4049 end 4254 time 2020-01-2718:01:37
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(5,'Chicken leg','Chicken you are so beautiful','0'); #start 4350 end 4549 time 2020-01-2718:02:08
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(6,'apple','xxxx','1'); #start 5052 end 5243 time 2020-01-2718:06:24
INSERT INTO `flash`.`goods`(`id`,`name`,`desc`,`status`)VALUES(7,'banana','xxxx','1'); #start 5339 end 5530 time 2020-01-2718:06:24
After executing the above SQL, you can see that the deleted data in the product table has been successfully restored:
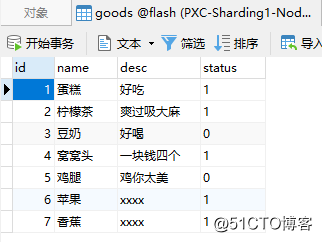
Recommended Posts