Python data visualization: who are the big names in Python?
Learn with an attitude
I talked about the related knowledge of proxy pool and Cookies before, here is the crawling of Sogou search WeChat official account articles, put them into practice.
In Cui Da's book, he used proxy IP to respond to Sogou's anti-climbing measures, because the same IP visits the web page too frequently, and the verification code page will be redirected.
However, the times are advancing, and the anti-crawl of Sogou Search is also being updated. Now it is a double check of IP plus Cookies.
/ 01 / Web Analysis

Get WeChat official account article information, title, beginning, official account, and release time.
The request method is GET, the request URL is the red box part, and the following information is useless.
/ 02 / Anti-crawl cracking
When does the picture above happen?
Two, one is to visit the page repeatedly with the same IP, and the other is to visit the page repeatedly with the same Cookie.
Both are available, and it hangs faster! I only succeeded once in the complete crawl...
Because I set nothing at first, and then the verification code page appeared. After using the proxy IP, the verification code page will still be redirected, and the crawling will be successful until the cookies are finally changed.
01 Proxy IP settings
def get_proxies(i):"""
Get proxy IP
"""
df = pd.read_csv('sg_effective_ip.csv', header=None, names=["proxy_type","proxy_url"])
proxy_type =["{}".format(i)for i in np.array(df['proxy_type'])]
proxy_url =["{}".format(i)for i in np.array(df['proxy_url'])]
proxies ={proxy_type[i]: proxy_url[i]}return proxies
The acquisition and use of the agent will not be repeated here. As mentioned in the previous article, interested friends can check it out by themselves.
After two days of practice, the free IP is really useless, and I found out my real IP in a few seconds.
02 Cookies settings
def get_cookies_snuid():"""
Get the SNUID value
"""
time.sleep(float(random.randint(2,5)))
url ="http://weixin.sogou.com/weixin?type=2&s_from=input&query=python&ie=utf8&_sug_=n&_sug_type_="
headers ={"Cookie":"ABTEST=Your parameters;IPLOC=CN3301;SUID=Your parameters;SUIR=Your parameters"}
# HEAD request,The header of the requested resource
response = requests.head(url, headers=headers).headers
result = re.findall('SNUID=(.*?); expires', response['Set-Cookie'])
SNUID = result[0]return SNUID
In general, the setting of Cookies is the most important in the entire anti-crawl, and the key is to dynamically change the SNUID value.
I won’t elaborate on the reason here. After all, I realized it only when I read the post of the Great God on the Internet, and the understanding is still very shallow.
There is only one successful crawl for 100 pages, 75 pages, 50 pages, and even the situation of hanging at the last crawl...
I don't want to be trapped in the quagmire of "climbing-anti-climbing-anti-anti-climbing". The things after the crawler are my real purpose, such as data analysis, data visualization.
Therefore, those who have a lot of votes hurry up and can only worship Sogou engineers.
/ 03 / Data Acquisition
01 Construct request header
head ="""
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.9
Connection:keep-alive
Host:weixin.sogou.com
Referer:'http://weixin.sogou.com/',
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
"""
# Does not contain SNUID value
cookie = 'Your cookies'
def str_to_dict(header):
"""
Construct request header,Different request headers can be constructed in different functions
"""
header_dict = {}
header = header.split('\n')
for h in header:
h = h.strip()
if h:
k, v = h.split(':', 1)
header_dict[k] = v.strip()
return header_dict
02 Get web page information
def get_message():"""
Get web page related information
"""
failed_list =[]for i inrange(1,101):print('First'+str(i)+'page')print(float(random.randint(15,20)))
# Set delay,This is what Du Niang found,Said to set a delay of more than 15s,Will not be blocked
time.sleep(float(random.randint(15,20)))
# Change the SNUID value every 10 pages
if(i-1)%10==0:
value =get_cookies_snuid()
snuid ='SNUID='+ value +';'
# Set cookies
cookies = cookie + snuid
url ='http://weixin.sogou.com/weixin?query=python&type=2&page='+str(i)+'&ie=utf8'
host = cookies +'\n'
header = head + host
headers =str_to_dict(header)
# Set proxy IP
proxies =get_proxies(i)try:
response = requests.get(url=url, headers=headers, proxies=proxies)
html = response.text
soup =BeautifulSoup(html,'html.parser')
data = soup.find_all('ul',{'class':'news-list'})
lis = data[0].find_all('li')for j in(range(len(lis))):
h3 = lis[j].find_all('h3')
# print(h3[0].get_text().replace('\n',''))
title = h3[0].get_text().replace('\n','').replace(',',',')
p = lis[j].find_all('p')
# print(p[0].get_text())
article = p[0].get_text().replace(',',',')
a = lis[j].find_all('a',{'class':'account'})
# print(a[0].get_text())
name = a[0].get_text()
span = lis[j].find_all('span',{'class':'s2'})
cmp = re.findall("\d{10}", span[0].get_text())
# print(time.strftime("%Y-%m-%d", time.localtime(int(cmp[0])))+'\n')
date = time.strftime("%Y-%m-%d", time.localtime(int(cmp[0])))withopen('sg_articles.csv','a+', encoding='utf-8-sig')as f:
f.write(title +','+ article +','+ name +','+ date +'\n')print('First'+str(i)+'Page success')
except Exception as e:print('First'+str(i)+'Page failed')
failed_list.append(i)continue
# Get page number failed
print(failed_list)
def main():get_message()if __name__ =='__main__':main()
Finally, the data was successfully obtained.


/ 04 / Data Visualization
01 Number of WeChat articles published TOP10
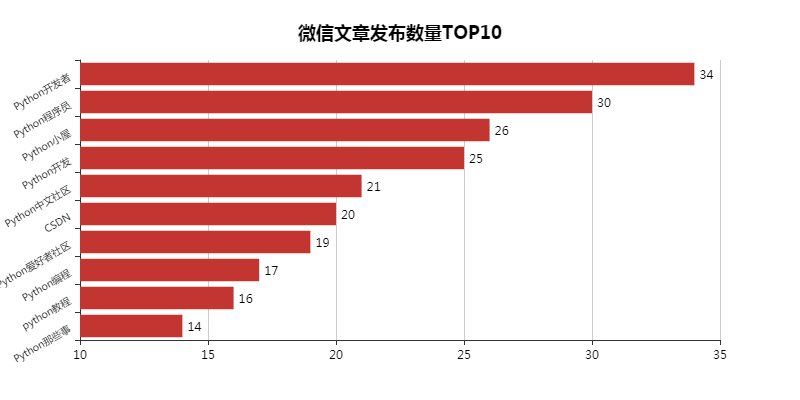
Sort the searched WeChat articles here, and found these ten Python bigwigs.
In fact, I want to know whether they are team operations or individual operations. But no matter what, pay attention first.
This result may also be related to my search with the keyword Python. At first glance, the names of the official accounts are all with Python (except CSDN).
from pyecharts import Bar
import pandas as pd
df = pd.read_csv('sg_articles.csv', header=None, names=["title","article","name","date"])
list1 =[]for j in df['date']:
# Get article publication year
time = j.split('-')[0]
list1.append(time)
df['year']= list1
# Select articles published in 2018 and count them
df = df.loc[df['year']=='2018']
place_message = df.groupby(['name'])
place_com = place_message['name'].agg(['count'])
place_com.reset_index(inplace=True)
place_com_last = place_com.sort_index()
dom = place_com_last.sort_values('count', ascending=False)[0:10]
attr = dom['name']
v1 = dom['count']
bar =Bar("The number of WeChat articles published TOP10", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0, is_label_show=True, is_legend_show=False, label_pos='right', is_yaxis_inverse=True, is_splitline_show=False)
bar.render("The number of WeChat articles published TOP10.html")
02 WeChat article publication time distribution
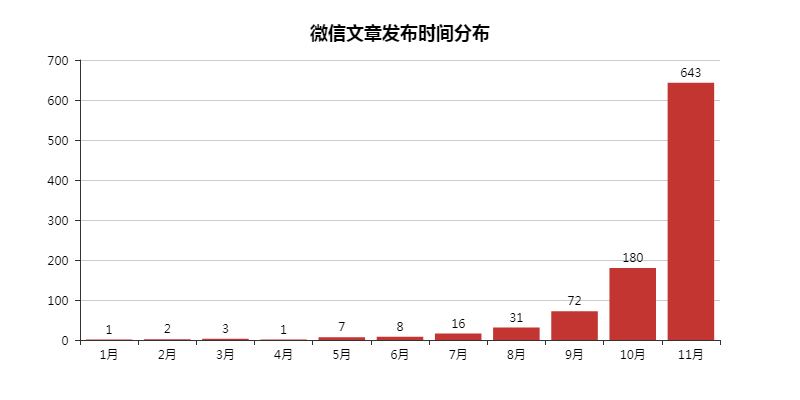
Because the articles found here will be before 2018, delete them here, and verify the publication time of the remaining articles.
After all, information is time-sensitive. If I search for old information, it won’t be interesting, let alone the changing Internet industry.
import numpy as np
import pandas as pd
from pyecharts import Bar
df = pd.read_csv('sg_articles.csv', header=None, names=["title","article","name","date"])
list1 =[]
list2 =[]for j in df['date']:
# Get the year and month of article publication
time_1 = j.split('-')[0]
time_2 = j.split('-')[1]
list1.append(time_1)
list2.append(time_2)
df['year']= list1
df['month']= list2
# Select articles published in 2018 and make monthly statistics on them
df = df.loc[df['year']=='2018']
month_message = df.groupby(['month'])
month_com = month_message['month'].agg(['count'])
month_com.reset_index(inplace=True)
month_com_last = month_com.sort_index()
attr =["{}".format(str(i)+'month')for i inrange(1,12)]
v1 = np.array(month_com_last['count'])
v1 =["{}".format(int(i))for i in v1]
bar =Bar("WeChat article publication time distribution", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True)
bar.render("WeChat article publication time distribution.html")
03 Title, beginning of article word cloud
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import pandas as pd
import jieba
df = pd.read_csv('sg_articles.csv', header=None, names=["title","article","name","date"])
text =''
# for line in df['article'].astype(str):(Previous word cloud code)for line in df['title']:
text +=' '.join(jieba.cut(line, cut_all=False))
backgroud_Image = plt.imread('python_logo.jpg')
wc =WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\STZHONGS.TTF',
max_words=2000,
max_font_size=150,
random_state=30)
wc.generate_from_text(text)
img_colors =ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')
# wc.to_file("article.jpg")(Previous word cloud code)
wc.to_file("title.jpg")print('Build word cloud success!')

The word cloud of the title of the official account article, because the search is based on the keyword Python, then Python must be indispensable.
Then crawlers, data analysis, machine learning, artificial intelligence appeared in the word cloud. You know the main purpose of Python at present!
However, Python can also be used for web development, GUI development, etc. It is not reflected here, and it is obviously not mainstream.

The word cloud at the beginning of the public account article, remember that when writing the essay before, the teacher did not say that the beginning basically determines your score, so be sure to quote the words of celebrities at the beginning (the ancients have cloud...).
Recommended Posts