LinuxにHadoopクラスターをインストールします(CentOS7 + hadoop-2.8.0)
1 hadoopをダウンロード#
このブログ投稿で使用されているhadoopは2.8.0です。
ダウンロードアドレス選択ページを開きます。
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
示されているように:

私が使用するアドレスは次のとおりです。
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
2 3台の仮想マシンをインストールしてSSHパスワードフリーログインを実現#
2.1 3台のマシンをインストールします##
ここで使用されているLinuxシステムはCentOS7です(実際、Ubuntuも非常に優れていますが、ここにCentOS7デモがあります)。インストール方法は、必要に応じて、このブログ投稿を参照してください。
http://blog.csdn.net/pucao_cug/article/details/71229416
3台のマシンをインストールします。マシン名はhserver1、hserver2、hserver3と呼ばれます(マシン名がそのように呼ばれていないことを示します。後でhostnameコマンドで変更できます)。
示されているように:
注:次の一連の認証の問題を回避するために、rootアカウントを使用してログインし、直接操作します。
ifconfigコマンドを使用して、これら3台のマシンのIPを表示します。私のマシン名とipの対応は次のとおりです。
192.168.119.128 hserver1
192.168.119.129 hserver2
192.168.119.130 hserver3
2.2 マシン名を確認してください##
後続の操作の便宜のために、マシンのホスト名が必要なものであることを確認してください。例としてマシン192.168.119.128を取り上げ、rootアカウントでログインしてから、hostnameコマンドを使用してマシン名を表示します
示されているように:
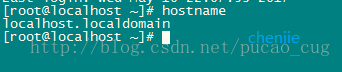
マシン名が私たちが望むものではないことがわかりました。ただし、これは簡単に処理できます。名前を変更します。コマンドは次のとおりです。
hostname hserver1
示されているように:

実行が完了したら、変更されているかどうかを確認し、hostnameコマンドを入力します。
示されているように:

同様に、他の2台のマシンの名前をそれぞれhserver2とhserver3に変更します。
2.3 / etc / hostsファイルを変更します##
これら3台のマシンの/ etc / hostsファイルを変更し、次のコンテンツをファイルに追加します。
[ plain]view plaincopy
- 192.168.119.128 hserver1
- 192.168.119.129 hserver2
- 192.168.119.130 hserver3
示されているように:

注:IPアドレスは私のものと同じである必要はありません。マッピングが正しい限り、これは単なるマッピングです。変更方法については、vimコマンドを使用するか、ローカルマシンにhostsファイルの内容を書き込むことができます。 Linuxマシンをカバーしてもらいます。
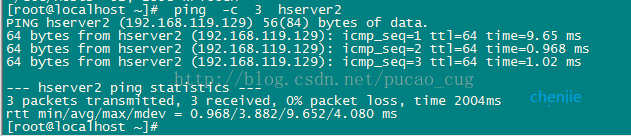
構成が完了したら、pingコマンドを使用して、3台のマシンが相互にpingできるかどうかを確認します。例としてhserver1を取り上げ、コマンドを実行する場所を示します。
ping -c 3 hserver2
示されているように:
注文の実行:
ping -c 3 hserver3
示されているように:
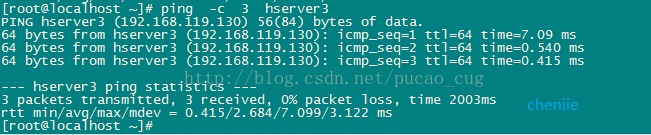
pingが機能する場合、マシンは相互接続され、ホストは正しく構成されています。
2.4 3台のマシンの秘密鍵ファイルを生成します##
例としてhserve1を取り上げ、コマンドを実行して空の文字列で秘密鍵を生成します(公開鍵は後で使用されます)。コマンドは次のとおりです。
ssh-keygen -t rsa -P ''
示されているように:
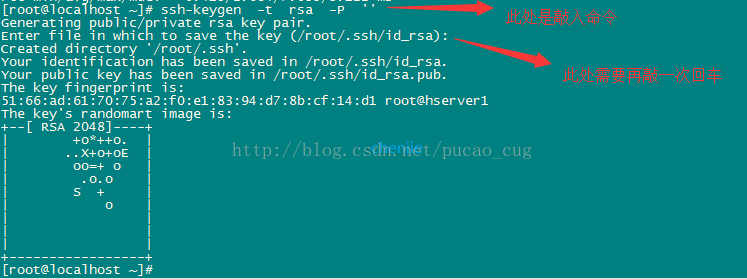
現在rootアカウントを使用しているため、秘密鍵ファイルは/root/.ssh/ディレクトリに保存されており、コマンドを使用して表示できます。コマンドは次のとおりです。
ls /root/.ssh/
示されているように:

同じ方法を使用して、hserver2とhserver3の秘密鍵を生成します(コマンドはまったく同じであり、変更する必要はありません)。
2.5 hserver1 ##にauthorized_keysファイルを作成します
次に行うことは、3台のマシンの/root/.ssh/ディレクトリに同じ内容のファイルを保存することです。ファイル名はauthorized_keysです。ファイルの内容は、3台のマシン用に生成した公開キーです。便宜上、次のステップは、hserver1でauthorized_keysファイルを生成し、3台のマシンで生成された公開キーをhserver1のauthorized_keysファイルに追加してから、authorized_keysファイルをhserver2とhserver3にコピーすることです。
まず、コマンドを使用して、hserver1の/root/.ssh/ディレクトリにauthorized_keysという名前のファイルを生成します。コマンドは次のとおりです。
touch /root/.ssh/authorized_keys
示されているように:

このコマンドを使用して、生成が成功したかどうかを確認できます。コマンドは次のとおりです。
ls /root/.ssh/
示されているように:

次に、hserver1の/root/.ssh/id_rsa.pubファイルの内容、hserver2の/root/.ssh/id_rsa.pubファイルの内容、およびhserver3の/root/.ssh/id_rsa.pubファイルの内容をこのauthorized_keysにコピーします。このファイルには、コピーする方法がたくさんあります。catコマンドとvimコマンドを使用して取得するか、3台のマシンの/root/.ssh/id_rsa.pubファイルをローカルに直接ダウンロードして、authorized_keysファイルをローカルで編集できます。幸い、これら3台のマシンにアップロードしてください。
hserver1マシン上の/root/.ssh/id_rsa.pubの内容は次のとおりです。
[ plain]view plaincopy
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD8fTIVorOxgDo81yCEgcJTstUcyfOBecL+NZ/OLXCEzaBMw5pLV0UNRX6SZnaAgu/erazkz4sw74zfRIMzEeKKCeNcZ6W78cg+ZNxDcj8+FGeYqY5+nc0YPhXFVI7AwFmfr7fH5hoIT14ClKfGklPgpEgUjDth0PeRwnUTvUy9A1x76npjAZrknQsnoLYle7cVJZ/zO3eGxS75YEdTYDMv+UMiwtcJg7UxOqR+9UT3TO+xLk0yOl8GIISXzMhdCZkmyAH+DmW56ejzsd+JWwCMm177DtOZULl7Osq+OGOtpbloj4HCfstpoiG58SM6Nba8WUXWLnbgqZuHPBag/Kqjroot@hserver1
hserver2マシン上の/root/.ssh/id_rsa.pubの内容は次のとおりです。
[ plain]view plaincopy
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC29kPkYz4c3bd9Qa1TV8kCR0bUNs4f7/dDcR1NKwrgIiecN7zPEWJpjILtlm3niNNx1j5R49QLTLBKKo8PE8mid47POvNypkVRGDeN2IVCivoAQ1T7S8bTJ4zDECGydFYyKQfS2nOAifAWECdgFFtIp52d+dLIAg1JC37pfER9f32rd7anhTHYKwnLwR/NDVGAw3tMkXOnFuFKUMdOJ3GSoVOZf3QHKykGIC2fz/lsXZHaCcQWvOU/Ecd9e0263Tvqh7zGWpF5WYEGjkLlY8v2sioeZxgzog1LWycUTMTqaO+fSdbvKqVj6W0qdy3Io8bJ29Q3S/6MxLa6xvFcBJEXroot@hserver2
hserver2マシン上の/root/.ssh/id_rsa.pubの内容は次のとおりです。
[ plain]view plaincopy
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1a2o10ttv2570GpuUZy7g9o7lIkkeed7ba25VvFEBcUroQIZ+NIAiVIMGPRiOqm7X4bTLWj5EOz5JXG2l8rwA6CFnWfW3U+ttD1COLOrv2tHTiJ1PhQy1jJR/LpC1iX3sNIDDs+I0txZFGTCTRMLmrbHVTl8j5Yy/CTYLuC7reIZjzpHP7aaS2ev0dlbQzeB08ncjA5Jh4X72qQMOGPUUc2C9oa/CeCvI0SJbt8mkHwqFanZz/IfhLJIKhupjtYsqwQMmzLIjHxbLRwUGoWU6X4e76OkUz/xyyHlzBg1Vu2F9hjoXPW80VmupIRSXFDliDBJ8NlXXQN47wwYBG28broot@hserver3
マージ後、hserver1マシンの/root/.ssh/authorized_keysファイルの内容は次のとおりです。
[ plain]view plaincopy
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD8fTIVorOxgDo81yCEgcJTstUcyfOBecL+NZ/OLXCEzaBMw5pLV0UNRX6SZnaAgu/erazkz4sw74zfRIMzEeKKCeNcZ6W78cg+ZNxDcj8+FGeYqY5+nc0YPhXFVI7AwFmfr7fH5hoIT14ClKfGklPgpEgUjDth0PeRwnUTvUy9A1x76npjAZrknQsnoLYle7cVJZ/zO3eGxS75YEdTYDMv+UMiwtcJg7UxOqR+9UT3TO+xLk0yOl8GIISXzMhdCZkmyAH+DmW56ejzsd+JWwCMm177DtOZULl7Osq+OGOtpbloj4HCfstpoiG58SM6Nba8WUXWLnbgqZuHPBag/Kqjroot@hserver1
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC29kPkYz4c3bd9Qa1TV8kCR0bUNs4f7/dDcR1NKwrgIiecN7zPEWJpjILtlm3niNNx1j5R49QLTLBKKo8PE8mid47POvNypkVRGDeN2IVCivoAQ1T7S8bTJ4zDECGydFYyKQfS2nOAifAWECdgFFtIp52d+dLIAg1JC37pfER9f32rd7anhTHYKwnLwR/NDVGAw3tMkXOnFuFKUMdOJ3GSoVOZf3QHKykGIC2fz/lsXZHaCcQWvOU/Ecd9e0263Tvqh7zGWpF5WYEGjkLlY8v2sioeZxgzog1LWycUTMTqaO+fSdbvKqVj6W0qdy3Io8bJ29Q3S/6MxLa6xvFcBJEXroot@hserver2
- ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1a2o10ttv2570GpuUZy7g9o7lIkkeed7ba25VvFEBcUroQIZ+NIAiVIMGPRiOqm7X4bTLWj5EOz5JXG2l8rwA6CFnWfW3U+ttD1COLOrv2tHTiJ1PhQy1jJR/LpC1iX3sNIDDs+I0txZFGTCTRMLmrbHVTl8j5Yy/CTYLuC7reIZjzpHP7aaS2ev0dlbQzeB08ncjA5Jh4X72qQMOGPUUc2C9oa/CeCvI0SJbt8mkHwqFanZz/IfhLJIKhupjtYsqwQMmzLIjHxbLRwUGoWU6X4e76OkUz/xyyHlzBg1Vu2F9hjoXPW80VmupIRSXFDliDBJ8NlXXQN47wwYBG28broot@hserver3
示されているように:

2.6 authorized_keysファイルを他のマシンにコピーします##
Authorized_keysファイルはすでにhserver1マシンの/root/.ssh/ディレクトリにあり、ファイルの内容はすでにOKです。次に、ファイルをhserver2の/root/.ssh/とhserver3の/ root /にコピーします。 ssh /。
コピーする方法はたくさんありますが、最も簡単な方法はSecureFX視覚化ツールを使用することです。
コピーが完了すると、3台のマシンの/root/.sshディレクトリにそのようなファイルがあることがわかります。
示されているように:
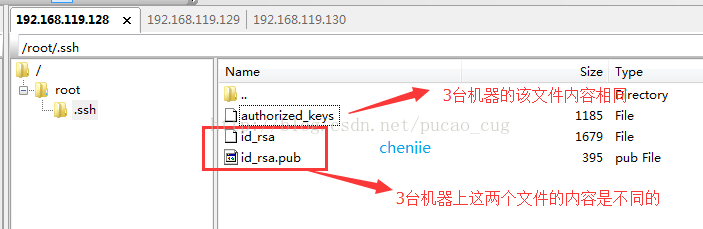
上の図から明らかなように、3台のマシンの/root/.sshには同じ名前のファイルがありますが、authorized_keysファイルの内容のみが同じです。
2.7 パスワードなしのログインにsshを使用してテストします##
2.7.1 hserver1 ###でテストします
次のコマンドを入力します。
ssh hserver2
示されているように:

次のコマンドを入力します。
終了入力
示されているように:

次のコマンドを入力します。
ssh hserver3
示されているように:

次のコマンドを入力します。
終了入力
示されているように:

2.7.2 hserver2 ###でテストします
メソッドは2.7.1と似ていますが、コマンドがsshhserver1とsshhserver3になっている点が異なりますが、各sshが完了した後、exitを実行する必要があります。そうしないと、後続のコマンドが別のマシンで実行されます。 。
2.7.3 hserver3 ###でテストします
メソッドは2.7.1と似ていますが、コマンドがsshhserver1とsshhserver2になっている点が異なりますが、各sshが完了した後、exitを実行する必要があります。そうしないと、後続のコマンドが別のマシンで実行されます。 。
3 jdkとhadoopをインストールします#
管理者権限や権限の取得などの面倒な一連の操作を保存し、チュートリアルを合理化するために、ここではすべてrootアカウントでのログインとroot権限での操作について説明します。
3.1 JDKをインストールします##
jdkのインストールについては、ここでは詳しく説明していません。必要に応じて、ブログ投稿を参照できます(ブログ投稿ではubuntuを使用していますが、jdkのインストールはCentOSでも同じです)。
http://blog.csdn.net/pucao_cug/article/details/68948639
3.2 hadoopをインストールする##
注:次の手順は、3台すべてのマシンで繰り返す必要があります。
3.2.1 ファイルをアップロードして解凍します###
図に示すように、optディレクトリにhadoopという名前の新しいディレクトリを作成し、ダウンロードしたhadoop-2.8.0.tarをこのディレクトリにアップロードします。
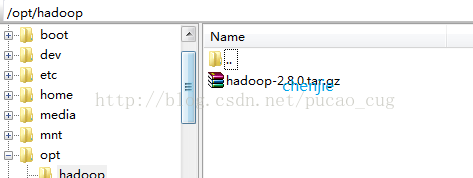
ディレクトリを入力して、次のコマンドを実行します。
cd /opt/hadoop
解凍コマンドを実行します。
tar -xvf hadoop-2.8.0.tar.gz
注:3台のマシンすべてで上記の操作を実行する必要があり、解凍後、hadoop-2.8.0という名前のディレクトリが取得されます。
3.2.2 複数のディレクトリを作成します###
/ rootディレクトリにいくつかのディレクトリを作成し、コピーして貼り付け、次のコマンドを実行します。
[ plain]view plaincopy
- mkdir /root/hadoop
- mkdir /root/hadoop/tmp
- mkdir /root/hadoop/var
- mkdir /root/hadoop/dfs
- mkdir /root/hadoop/dfs/name
- mkdir /root/hadoop/dfs/data
3.2.3 etc / hadoop ###の一連の構成ファイルを変更します
/opt/hadoop/hadoop-2.8.0/etc/hadoopディレクトリ内の一連のファイルを変更します。
3.2.3.1 core-site.xmlを変更します####
/opt/hadoop/hadoop-2.8.0/etc/hadoop/core-site.xmlファイルを変更します
に
< /configuration>
3.2.3.2 hadoop-env.sh ####を変更します
/opt/hadoop/hadoop-2.8.0/etc/hadoop/hadoop-env.shファイルを変更します
JAVA_HOME = $ {JAVA_HOME}をエクスポートします
着替える:
export JAVA_HOME=/opt/java/jdk1.8.0_121
説明:独自のJDKパスに変更します
3.2.3.3 hdfs-site.xmlを変更します####
/opt/hadoop/hadoop-2.8.0/etc/hadoop/hdfs-site.xmlファイルを変更します
に
< property>
< /property>
< property>
< /property>
< property>
< /property>
< property>
< /property>
注:dfs.permissionsをfalseに設定した後、権限を確認せずにdfs上のファイルを生成できるようにすることができます。これは便利ですが、誤って削除しないようにする必要があります。trueに設定するか、プロパティノードを直接削除してください。デフォルトはtrueです。
3.2.3.4 mapred-site.xml ####を作成および変更します
このバージョンには、mapred-site.xml.templateという名前のファイルがあります。ファイルをコピーして、名前をmapred-site.xmlに変更します。コマンドは次のとおりです。
[ plain]view plaincopy
- cp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml
この新しく作成されたmapred-site.xmlファイルをで変更します。
< /property>
< property>
< /property>
< property>
< /property>
3.2.3.5 スレーブファイルを変更する####
/opt/hadoop/hadoop-2.8.0/etc/hadoop/slavesファイルを変更し、内部のlocalhostを削除して、次のコンテンツを追加します。
[ plain]view plaincopy
- hserver2
- hserver3
3.2.3.6 糸サイト.xmlファイルを変更します####
/opt/hadoop/hadoop-2.8.0/etc/hadoop/yarn-site.xmlファイルを変更します。
に
< property>
< /property>
< /property>
注:yarn.nodemanager.vmem-check-enabledは、仮想メモリのチェックを無視することを意味します。仮想マシンにインストールする場合、この構成は非常に便利であり、後続の操作で問題を引き起こすのは簡単ではありません。物理マシン上にあり、十分なメモリがある場合、この構成は削除できます。
4 ハドゥープを開始#
4.1 namenode ##で初期化を実行します
hserver1はネームノードであるため、hserver2とhserver3は両方ともデータノードであり、hserver1のみを初期化する必要があります。つまり、hdfsがフォーマットされます。
hserver1マシンの/opt/hadoop/hadoop-2.8.0/binディレクトリに入ります。つまり、次のコマンドを実行します。
cd /opt/hadoop/hadoop-2.8.0/bin
初期化スクリプトを実行します。つまり、次のコマンドを実行します。
./hadoop namenode -format
示されているように:
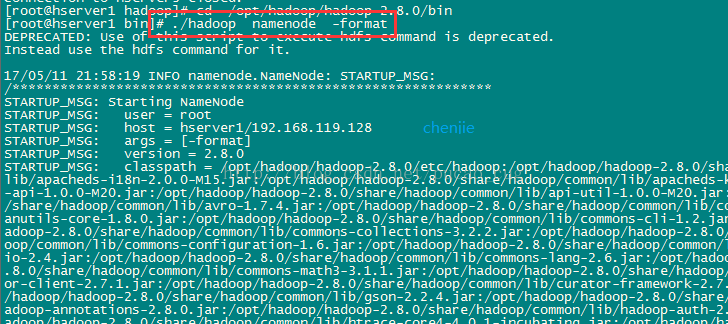
次の図に示すように、エラーが報告されない場合は、数秒待ってから実行を成功させることができます。
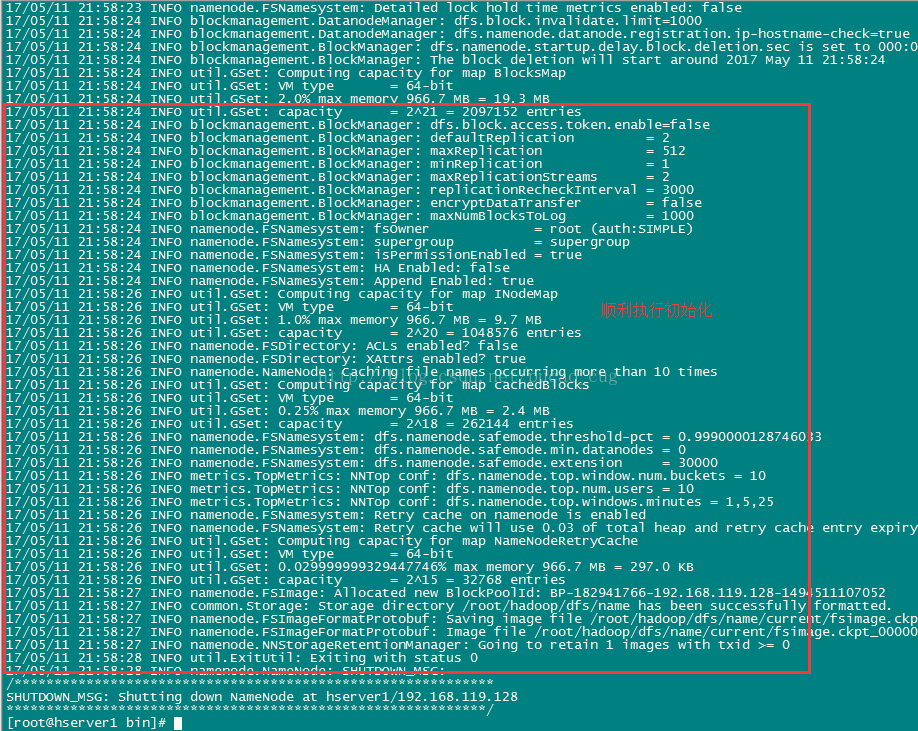
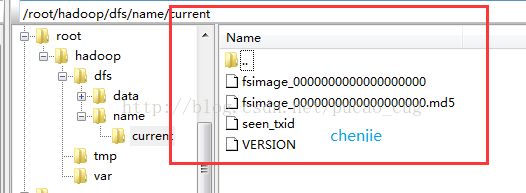
フォーマットが成功すると、/ root / hadoop / dfs / name /ディレクトリに現在のディレクトリが追加され、ディレクトリに一連のファイルがあることがわかります。
示されているように:
4.2 namenode ##でstartコマンドを実行します
hserver1はネームノードであるため、hserver2とhserver3は両方ともデータノードであり、hserver1で起動コマンドを実行するだけで済みます。
hserver1マシンの/opt/hadoop/hadoop-2.8.0/sbinディレクトリに入ります。つまり、次のコマンドを実行します。
cd /opt/hadoop/hadoop-2.8.0/sbin
初期化スクリプトを実行します。つまり、次のコマンドを実行します。
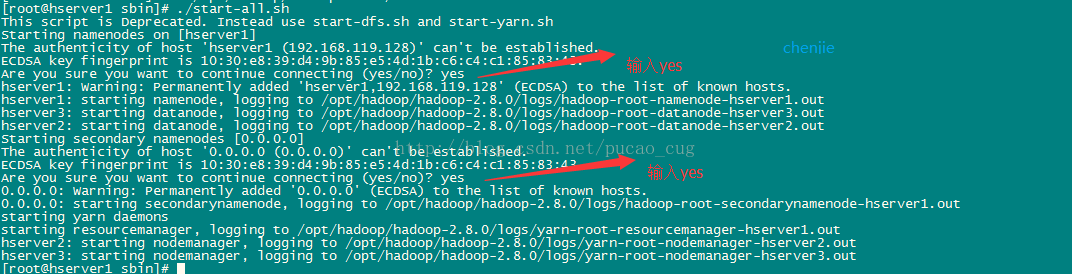
./start-all.sh
上記の起動コマンドを初めて実行するときは、インタラクティブな操作を実行する必要があります。Q&Aインターフェイスでyesと入力し、Enterキーを押します。
示されているように:
5 hadoop#をテストします
Hadoopが開始されました。Hadoopが正常かどうかをテストする必要があります。
コマンドを実行してファイアウォールをオフにします。CentOS7では、コマンドは次のとおりです。
systemctl stop firewalld.service
示されているように:

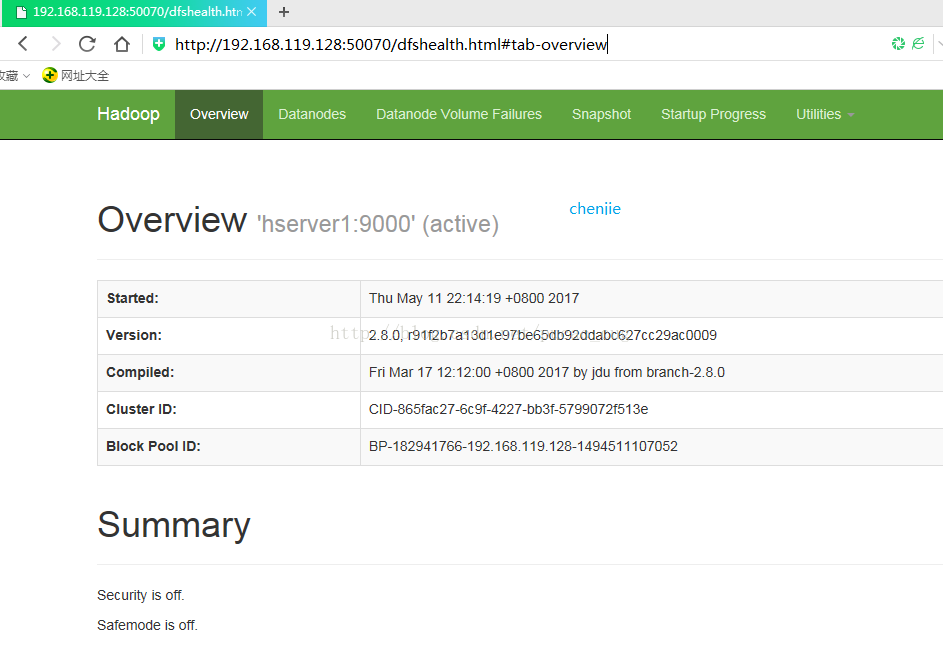
hserver1はnamanodeであり、このマシンのIPは192.168.119.128です。ローカル・コンピューターで次のアドレスにアクセスしてください。
概要ページに自動的にジャンプします
示されているように:
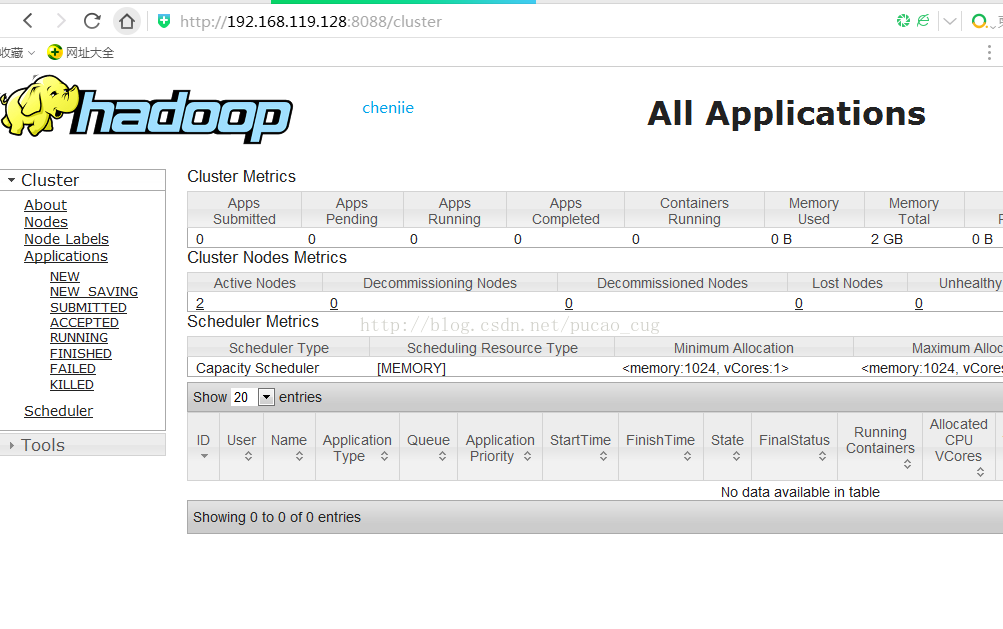
ローカルブラウザで次のアドレスにアクセスします。
クラスターページに自動的にジャンプします
示されているように:
Recommended Posts