Python3外部モジュールの使用
[ TOC]
0 x00クイックスタート####
(1) 外部モジュールのリスト
説明:Python外部モジュールは、Pythonの力の存在であると言えます。これにより、Python言語は非常に拡張可能になり、多くの使用方法と非常に簡単に使用できます。これは、日常の運用および保守の開発と学習において特に重要です。
#>>> dir(random) #モジュール内の関数を表示および使用する,前提条件はモジュールを導入する必要があります,高レベルの使用法のインポートでは、モジュールがモジュールエイリアスとして導入されます;
#>>> help(random) #モジュールヘルプ
import urllib #ウェブサイトリクエストモジュール
import lxml #lxml importetreeからのxpath解析ライブラリモジュール
# フォームExcel処理
import cvs #cvsフォームモジュール
import xlwt #エクセルフォームモジュール
import xlsxwriter #エクセルファイルモジュール
# 他の記事で紹介
import psutil #システムパフォーマンス情報モジュール
import exifread #画像exif情報モジュール
import ruamel.yaml #YAML解析モジュール
import dnspython #DNS解決情報モジュール
import pycurl #Web検出モジュール
0 x01外部モジュールの詳細な説明####
urllibモジュール#####
urllibは、主にWebページのリクエスト用に、以下の4つのモジュールを含むパッケージです。
[ ドキュメントアドレス](https://docs.python.org/3/library/urllib.html)
urllib.requestは、urlを開いて読み取るために使用されます
urllib.errorには、urllib.requestによって引き起こされた例外が含まれています(URLERROR(要求例外)-> HTTPERROR(Webページ応答コード例外300〜599))
urllib.parseはurlを解析します
urllib.robotparserは、robots.txtファイルを解析するために使用されます
場合:
# 文法
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None) #リクエスト設定リクエストのオブジェクトを返します
urllib.request.urlopen(url, data=None,[timeout,]*, cafile=None, capath=None, cadefault=False, context=None) #ウェブサイトをリクエストする
urllib.request.ProxyHandler(proxies=None) #Proxyhandlerパラメータを作成するためのプロキシアドレスを設定する辞書です{'の種類':'プロキシIP:港'}リターンハンドラ
urllib.request.build_opener([handler,...]) #オープナーバインディングプロキシリソースを作成する,オープナーオープンツールオブジェクトのインストールに戻る
urllib.request.install_opener(opener) #オープナーをインストールする
# POST requestThe data argument must be a bytes object in standard application/x-www-form-urlencoded format;
urllib.parse.urlencode(data, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
urllib.parse.quote("サイバーセキュリティ") #中国のURLを解析する
# 場合
import urllib.request
import urllib.error
url ="http://weiyigeek.github.io"
data ={'action':'postValue'} #リクエスト後のパラメータを設定する
data = urllib.parse.urlencode(data).encode('utf-8') #同等:アプリケーション/x-www-form-urlencoded; charset=UTF-8
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0') #リクエストヘッダーを設定する
#-----------------------------------------------------#
try:
res = urllib.request.urlopen("https://weiyigeek.github.io",context=ssl._create_unverified_context()) #SSLリクエストをサポートする
print("リクエストURL:\n",res.geturl())print("ステータスコード:",res.getcode())print("戻りメッセージヘッダー:\n",res.info())print("ヘッダー情報の要求:",req.headers) #これはリクエストであることに注意してください()クラスメソッドによって返されるオブジェクト
except HTTPError as e: #[注] HTTPErrorはURLErrorより上である必要があります
print("サーバー応答エラー:",e.code)print("特定のエラーページを印刷します",e.read().encode('utf-8'))
except URLError as e: #HTTPErrorが含まれています
print("サーバーリンクに失敗しました:",e.reason)else:print("リクエストは成功しました!")
############ の結果########################
# リクエストURL:http://weiyigeek.github.io
# ステータスコード:200
# 戻りメッセージヘッダー:
# Server: nginx/1.15.9
# Date: Fri,12 Apr 201910:57:51 GMT
# Content-Type: text/html; charset=utf-8
# Content-Length:15278
# Last-Modified: Wed,10 Apr 201901:12:59 GMT
# Connection: close
# ETag:"5cad431b-3bae"
# Accept-Ranges: bytes
# ヘッダー情報の要求:{'User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'}
lxmlモジュール#####
xpathを使用するには、最初にlxmlライブラリをダウンロードする必要があります。xpathは、pythonの別のライブラリlxmlの単なる要素セレクタです。
参照:[https://cuiqingcai.com/2621.html](https://cuiqingcai.com/2621.html)
# pipを使用してlxmlライブラリをダウンロードします
pip install lxml
from lxml import etree
## いくつかのコードを省略してください、dom_treeは、解析したetreeオブジェクトです。
dom_tree = etree.HTML(html)
## 文1:
dom_tree.xpath('/html/body/div/a/@href')
## ステートメント2:
dom_tree.xpath('//div/a/@href')
## ステートメント2:
dom_tree.xpath('//div[@class="info-co"]/a/@href')クラス属性を使用する
dom_tree.xpath('//div/a/@href') #すべてのリンクURLを返します
dom_tree.xpath('//div/a/text()') #すべてのリンクの名前を取得します
実際のケース:
# リクエストウェブサイトのhtmlを取得する
dom_tree = etree.HTML(html)
links = dom_tree.xpath("//div/span[@class='info-col row2-text']/a") #xpathオブジェクトを返す
for i in links:print(i.text)for index inrange(len(links_yaoshi)):print(index)print(links[index].text)print(links_yaoshi[index].text)print(links_danjia[index].text)
# xpathの検索結果と抽出結果を使用できることに注意してください "|「複数の結果を抽出するため、最終的なコードは次のようになります。
data = dom_tree.xpath("//div[@class='info-table']/li")
info = data[0].xpath('string(.)').extract()[0]print(data[0].xpath('string(.)').strip()) #最初の行の結果を印刷するだけです
# 学ぶ価値がある
dataRes = dom_tree.xpath("//div/span[@class='info-col row2-text']/a | //div/span[@class='c-prop-tag2'] | //span[@class='info-col price-item minor']")
0 x02フォームデータ処理####
csvモジュール#####
(1) csv.reader:csvファイルを読み取り、反復タイプを返します
(2) csv.writer(IO、dialect、delimiter):csvファイルを書き込むためのテンプレートを設定します
(3) DictReader:CSVファイルも読み取り、辞書タイプを返します
(4) DictWriter:辞書をCSVファイルに書き込む
(5) writerow:データの行をcsvファイルに挿入し、以下のリストの各項目をセルに入れます
場合:
#! /usr/bin/python3
# Python3は、csvモジュールを使用してcsvファイルを読み書きします
import csv
# ケース1:出力データをCSVファイルに書き込む
data =[("Mike","male",24),("Lee","male",26),("Joy","female",22)]
data1 =[[x]for x inrange(10)if x %2==0]
data2 =['テスト','w','私は中国人です'] #文字間,セグメンテーション
# ファイルを開き、で開くモードを設定します。ファイルを特に閉じる必要はありません。
# Python3.4、空白行の問題を解決するための新しい方法
withopen('demo.csv','w+',newline='',encoding='utf-8')as csvfile:
# 方言はcsvファイルを開く方法です。デフォルトはexcel、delimiterです。="\t"パラメータは、書き込み時にセパレータを参照します
csvwriter = csv.writer(csvfile,dialect=("excel"),delimiter=',')for each in data:print(">>>",each)
csvwriter.writerow(each)
csvwriter.writerow(data2) #一行で書く
# データの行をcsvファイルに挿入し、以下のリストの各項目をセルに配置します(ループを使用して複数の行を挿入できます)
csvwriter.writerow(["A","B","C","D"])
# ケース2:csvファイルを開いてデータを読み取る
withopen('demo.csv','r+',encoding='utf-8')as f:
res = csv.reader(f)for x in res:print(x[0])
# csvには3列のデータがあり、3つの変数はトラバーサル読み取りに使用されます。
for title, year, director in reader:
list.append(year)print(title,"; ", year ,"; ", director)withopen("test.csv","r", encoding ="utf-8")as f:
reader = csv.DictReader(f) #辞書オブジェクトを読む
column =[row for row in reader]>python demo6.1.py
>>>(' Mike','male',24)>>>('Lee','male',26)>>>('Joy','female',22)
Mike
Lee
Joy
テスト
xlwtモジュール#####
説明:execlテーブルデータの読み取り、書き込み、挿入、削除などのために、豊富な計算機能とチャートをサポートします。
公式サイトからダウンロード:[http://pypi.python.org/pypi/xlwt](http://pypi.python.org/pypi/xlwt)
基本的な方法:
xlwt.Workbook(encoding ='エンコード形式')
workbook.add_sheet('テーブル名')
worksheet.write(0,0,"データを書き込む")
workbook.save('ストレージファイル名')
実際のケース:
#! /usr/bin/env python
# - *- coding: utf-8-*-import xlwt
def main():
workbook = xlwt.Workbook(encoding='utf-8') #ワークブックを作成する
worksheet = workbook.add_sheet('シート名') #ワークブックを作成する
# 0から挿入
worksheet.write(0,0,'Hello') # write_string()
worksheet.write(1,0,'World') # write_string()
worksheet.write(2,0,2) # write_number()
worksheet.write(3,0,3.00001) # write_number()
worksheet.write(4,0,'=SIN(PI()/4)') # write_formula()
worksheet.write(5,0,'') # write_blank()
worksheet.write(6,0, None) # write_blank()
linenum =7
# 2次元配列を使用してメインを決定します,セルにコンテンツを書き込む
worksheet.write(linenum,0,"ID")
worksheet.write(linenum,1,"ルートドメイン")
worksheet.write(linenum,2,"メールボックスをバインドする")
worksheet.write(linenum,3,"DNSサーバー1")
worksheet.write(linenum,4,"DNSサーバー2")
worksheet.write(linenum,5,"状態")
# エクセルドキュメントを保存する
workbook.save('Excel_Workbook.xls')print("書き込みが完了しました!")if __name__ =='__main__':main()

WeiyiGeek.excelフォーム処理
xlsxwriterモジュール#####
説明:複数のワークシートのテキスト/番号/式およびチャートを操作できるEXCELのxlsxwritermモジュールを操作します。
モジュールの機能:
- 互換性ExceファイルはExcel2003 / 2007およびその他のバージョンをサポートし、すべてのExcelセル形式をサポートします
- セルのマージ/注釈/自動フィルタリング、豊富なマルチフォーマット文字列などを実行できます。
- PNG / jpg画像、カスタムチャートのグループ化をサポート
- メモリ最適化モードは、大きなファイルの書き込みをサポートします
モジュールのインストール:
pip3 install xlsxwriter
# マニュアル
1. エクセルファイルオブジェクトを作成する
2. ワークシートオブジェクトを作成する
3. チャートオブジェクトを作成する
4. excelのフォーマットオブジェクトを定義します
モジュール方式:
#1. ワークブッククラス
obj=Class.Workbook(filename[,options]) #このクラスは、XlsxWriterのWorkbookオブジェクトを作成します。オプションは、dictタイプはオプションのパラメーターであり、通常、最初のワークシートコンテンツの形式として使用されます。
worksheet=obj.dd_worksheet([sheetname]) #メソッドは新しいワークシートを追加するために使用されます。sheetnameはワークシートの名前です。デフォルトはsheet1です。
format=obj.add_format([properties]) #メソッドを使用して、ワークシートに新しいフォーマットオブジェクトを作成し、セルを太字でフォーマットします/normal
format.set_border(1) #フォーマットオブジェクトのセル境界を太字で定義(1ピクセル)フォーマット
format.set_bg_color('#999999') #オブジェクトの背景表示を定義します
format.set_blod() #太字で表示
format.set_num_format('0.00') #太字にするセル境界の形式を1ピクセルで定義します;
format.set_align('center')
chart=obj.add_chart(options) #ワークシートにチャートオブジェクトを作成するために使用され、内部的に挿入されます_chart()達成する方法、パラメータはdictタイプで、アイコンの辞書属性を指定します
obj.close() #役割はワークシートファイルを閉じることです
#2. ワークシートクラス:
# Worksheetオブジェクトを直接インスタンス化することはできませんが、Workbookオブジェクトを介してaddを呼び出します。_worksheet()コアクラスであるexcelワークシートを表す作成方法
worksheet.write(row, col,*args) #通常のデータをセルに書き込むために使用されます。
# さまざまなデータタイプの書き込みプロセスを簡素化するために、writeメソッドは他のより具体的なデータタイプメソッドのエイリアスとして使用されています
write_row('A1',書き込まれたデータ(一文字/アレイ),フォーマットタイプ) #A1から始まる行を書く
write_cloumn('A2',書き込まれたデータ(一文字/アレイ),フォーマットタイプ) #A2から始まる列を書く)write_string():文字列型データを書き込む
wirte_number():デジタルデータを書き込む
write_blank():空の型データを書き込む
write_formula():式データを書き込む
write_datetime():日付タイプデータを書き込む
wirte_boolean():論理データを書き込む
write_url():ハイパーリンクデータを書き込む
worksheet.set_row(row, height, cell_format, options) #行セルの属性を設定するために使用されます。
# オプション辞書タイプ、設定行非表示(非表示)、レベル(組み合わせ分類)、折りたたまれた(折りたたまれた)
worksheet.set_column(first_col, last_col, width, cell_format, options) #セルの1つ以上の列のプロパティを設定するために使用されます
worksheet.insert_image(row, col, image[, options]) #指定されたセルに画像を挿入するために使用され、PNG、JPEG、BMP、指定された画像の場所などのさまざまな形式をサポートします/割合/接続URL情報。
#3. チャートクラスの実際のチャートコンポーネント、エリア、バーチャート、ヒストグラム、ラインチャート、スキャッターチャートなどを含むサポート。
# チャートオブジェクトはワークブックを通じて追加されます_チャートメソッドはによって作成されます{type,「チャートタイプ」}チャートタイプを指定するための辞書
workbook.add_char({'type':"column"})
エリア:エリアスタイルのチャート
バー:バーグラフ
列:ヒストグラム
線:線スタイルチャート
パイ:パイチャート
スキャッター:スキャッターチャート
在庫:ストックスタイルチャート
レーダー:レーダースタイルチャート
# 指定された位置に挿入します
chart.add_series(options) #データ系列を追加するために使用されるチャートパラメータオプションは、チャート系列オプションを設定するために使用される辞書タイプです。
# 一般的な方法:
カテゴリ:チャートカテゴリのラベル範囲を設定します。
値:チャートのデータ範囲を設定します。
line:幅、色などを含むチャートの線のプロパティを設定します。
name:"凡例表としての参照-つまり、右側の棒グラフ"
# 他の一般的な方法は
chart.set_y_axis(options) #チャートのy軸サブタイトルを設定する
chart.set_x_axis(options) #チャートのX軸サブタイトルを設定する
# name:x軸の名前を設定します
# name_font:x軸のフォントを設定します
# num_font:x軸のデジタルフォント属性を設定します。
chart.set_size(options) #アイコンサイズを設定する{'width':'1024','height':768}
chart.set_title(options)#チャートの上にタイトルを設定します。パラメータオプションは辞書タイプであり、チャートシリーズオプションの設定に使用される辞書です。
chart.set_style(style_id)#チャートスタイル、スタイルを設定するために使用されます_idは、さまざまなスタイルを表すさまざまな番号です
chart.set_table(options) #x軸をデータテーブル形式に設定します
worksheet.insert_chart(row,col,chartObj) #セットチャートをワークブックに挿入します
簡単な例
workbook = xlsxwriter.Workbook('Chart.xlsx')
worksheet =workbook.add_worksheet()
chart = workbook.add_chart({'type':'cloumn'})
format1 = workbook.add_format()
format1.set_border(1)
format2 = workbook.add_format()
format2.set_align('center')
worksheet.write_row('A1',書き込まれたデータ(一文字/アレイ),format1) #A1から始まる行を書く
worksheet.write_cloumn('A2',書き込まれたデータ(一文字/アレイ),format2) #A2から始まる列を書く)for i inrange(2,7)
worksheet.write_formula('I'+i,'=AVERAGE(B'+i+':H'+i+')'.format1) #B2から:H2の平均
# チャートにデータを追加する場合も同様です(強調)
chart.add_series({'categories':'=Sheet1!B1:H1', #x軸列の下のグラフとして説明されます
' values':'=Sheet1!$B$'+i+':$H$'+1, #チャートデータ領域の割り当て
' line':{'color':'black'},'name': u'凡例表としての参照-つまり、右側の棒グラフ', #デフォルトはシリーズ1です})
chart.set_x_axis({'name':u'週数'})
chart.set_y_axis({'name':u' Mb/s '})
worksheet.insert_chart('AB', chart)
workbook.close() #ドキュメントを閉じる
モジュールの例:
#! /usr/bin/env python
# coding=utf-8import xlsxwriter
# 新しいExcelファイルを作成し、ワークシートを追加します
workbook = xlsxwriter.Workbook('demo.xlsx') #ワークブックを作成する
# 新しいワークブックを作成する
worksheet1 = workbook.add_worksheet() #ワークシートシートを作成する1(デフォルトのテーブル名)
worksheet2 = workbook.add_worksheet('testSheet2') #ワークシートtestsheet2を作成する
# ワークシートに新しいフォーマットオブジェクトを作成して、セルをフォーマットして太字にします
bold = workbook.add_format({'bold': True}) #方法1
bold = workbook.add_format();bold.set_bold() #方法2
# データはワークブックに書き込まれます,注:2つのメソッドは、実際にはエイリアスのみです。A1と(0,0)ウェイポジショニング
worksheet.write('A1','Hello') #要約テーブルに簡単なテキストを書き込む
worksheet.write_string(0,1,'World') #単純なテキスト文字列タイプのデータを合計テーブルに書き込みます
worksheet.write('A2',123.456) #数値データを書き込む
worksheet.write_number(1,1,123456) #座標に従って書く
worksheet.write('A3', None) #空のデータタイプを書き込む
worksheet.write_blank(2,1,'') #空のデータタイプを書き込む
worksheet.write('A4','=SUM(A1:B2)') #式データを書き込む
worksheet.write_formula(3,1,'=SIN(PI()/4)')
worksheet.write('A5', datetime.datetime.strftime('2019-08-09','y%-m%-d%'),workbook.add_format({'num_format':'yyyy-mm-dd'})) #日付タイプデータの書き込み
worksheet.write_datatime(4,1,datetime.datetime.strftime('2019-08-09','y%-m%-d%'),workbook.add_format({'num_format':'yyyy-mm-dd'}))
worksheet.write('A6', True) #論理型データを書き込む
worksheet.write_boolean(5,1, False)
worksheet.write('A7','http://baidu.com') #ハイパーリンクデータタイプの書き込み
worksheet.write_url(6,1,'http://www.python.org')
# 1つ以上の列セル属性を設定します
worksheet1.set_column(0,1,10, bold) #セルA〜Bの幅を10ピクセルの厚さに設定します
worksheet1.set_column('C:D',20) #セルC〜Dの幅を20ピクセルに設定します
worksheet1.set_column('E:G', None, None,{'hidden':1}) #セルEからGを非表示
# セル属性の1つ以上の行を設定します
worksheet1.set_row(0,30,bold) #すべての1行単位と30ピクセルの高さを設定して、太字を定義します
worksheet1.set_row(1,30,workbook,add_format({'italic':True})) #イタリックを定義するには、すべての1行単位と30ピクセルの高さを設定します
worksheet1.set_row(6, None, None,{'hidden':1}) #行6を非表示
# 2番目のセルブックにpythonを挿入します-logo.png画像のハイパーリンクはhttpです://python.org
worksheet2.insert_image('A1','python-logo.jpg',{'url':'http://python.org'})
worksheet2.insert_image('A3','python-logo.jpg') #写真を挿入
# チャーチャートの例
chart = workbook.addchart({type,'column'}) #列を作成する(円筒形)アイコン
# チャートにデータを追加する
chart.add_series({'categories':'=testSheet2!$A$1:$A$5','values':'=testSheet2!$B$1:$B3','line':{'color':'red'},'name':
})
# チャートX軸表示を設定
chart.set_x_axis({'name':'x name','name_font':{'size':14,'bold': True}'num_font':{'italic': True}})
# x軸をデータテーブル形式に設定します
chart.set_table()
# チャートサイズ
chart.set_size({'width':720,'height':576})
# チャートタイトル
chart.set_title({'name':"Table Title Demo"})
# チャートスタイル
chart.set_style(37)
# チャートをワークブックに挿入する
worksheet2.insert_chart('A7', chart)
workbook.close() #ワークブックを閉じる
WeiyiGeek.
0 x04ファイル変換####
1. PDFMinerモジュール#####
PDFMinerは、PDFドキュメントからテキスト情報を抽出して分析することに焦点を当てたツールです。特定のページ番号の特定の場所にある情報だけでなく、フォントなどの情報も取得できます。
インストールモジュールの説明:
# 最初にPDFMinerをインストールし、Python3に注意してpdfminer3kをインストールします
# Windowsにpdfminer3kをインストールする
pip install pdfminer3k
# Linuxにpdfminerをインストールする
pip install pdfminer
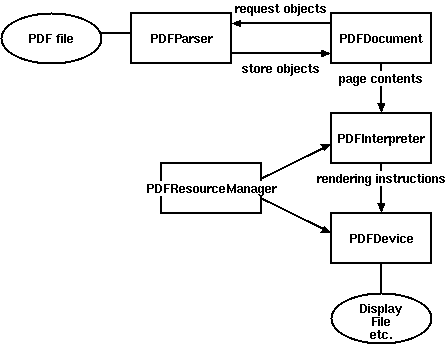
動作原理図:
WeiyiGeek.
pdfファイルの解析に使用されるクラス:
- PDFParser:ファイルからデータを取得する
- PDFDocument:取得したデータを保存し、PDFParserは相互に関連しています
- PDFPageInterpreter:ページコンテンツの処理
- PDFDevice:必要な形式に変換します
- PDFResourceManager:フォントや画像などの共有リソースを保存するために使用されます。
レイアウト分析は、PDFドキュメントの各ページのLTPageオブジェクトを返します。このオブジェクトとページに含まれる子オブジェクトは、ツリー構造を形成します。
写真が示すように:
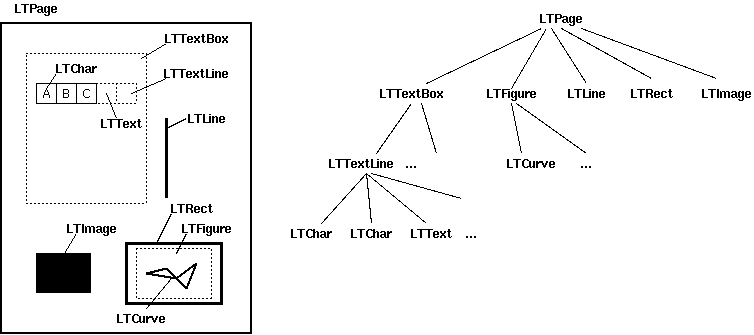
LTPage:ページ全体に LTTextBox、LTFigure、LTImage、LTRect、LTCurve、LTLineサブオブジェクトが含まれる可能性があることを示します。
- LTTextBox:テキストブロックのグループが長方形の領域に含まれる可能性があることを示します。このボックスは幾何学的分析によって作成されたものであり、必ずしもテキストの論理的な境界を表すわけではないことに注意してください。 LTTextLineオブジェクトのリストが含まれています。 get_text()メソッドを使用して、テキストコンテンツを返します。
- LTTextLine:単一のテキスト行を表すLTCharオブジェクトのリストが含まれます。文字の配置は、テキストの書き込みモードに応じて、水平または垂直のいずれかになります。 get_text()メソッドを使用して、テキストコンテンツを返します。
- LTAnno:テキスト内の文字は、実際にはUnicode文字列として表されます。 LTCharオブジェクトには実際の境界がありますが、LTAnoオブジェクトにはないことに注意してください。これらは「仮想」文字であり、2つの文字(スペースなど)の関係に基づいてレイアウト分析後に挿入されます。
- LTImage:画像オブジェクトを表します。埋め込まれた画像はJPEGまたはその他の形式にすることができますが、現在PDFMinerはグラフィックオブジェクトにあまり力を入れていません。
- LTLine:直線を表します。テキストまたは図面を分離するために使用できます。
- LTRect:長方形を表します。フレームに使用できる別の画像または番号。
- LTCurve:一般的なベジエ曲線を表します
Recommended Posts