Pythonデータの視覚化:Pythonの有名人は誰ですか?
態度で学ぶ
プロキシプールとCookieの関連知識については前に説明しましたが、これがSogou検索のWeChat公式アカウント記事のクロールです。
Cui Daの本では、同じIPがWebページに頻繁にアクセスし、検証コードページにジャンプするため、プロキシIPを使用してSogouの登山防止対策に対応しました。
しかし、時代は進み、そごうサーチのアンチクロールも更新されており、IPとCookieのダブルチェックになっています。
/ 01 / Web分析

WeChatの公式アカウントの記事情報、タイトル、開始、公式アカウント、およびリリース時間を取得します。
リクエストメソッドはGET、リクエストURLは赤いボックス部分であり、以下の情報は役に立ちません。
/ 02 /クロール防止クラッキング
上の写真はいつ起こりますか?
2つは、1つは同じIPでページに繰り返しアクセスすることであり、もう1つは同じCookieでページに繰り返しアクセスすることです。
両方とも利用可能で、より速くハングします!私は完全なクロールで一度だけ成功しました...
最初は何も設定しなかったので、確認コードページが表示されました。プロキシIPを使用した後も、確認コードページはリダイレクトされ、Cookieが最終的に変更されるまでクロールは成功します。
01 プロキシIP設定
def get_proxies(i):"""
プロキシIPを取得する
"""
df = pd.read_csv('sg_effective_ip.csv', header=None, names=["proxy_type","proxy_url"])
proxy_type =["{}".format(i)for i in np.array(df['proxy_type'])]
proxy_url =["{}".format(i)for i in np.array(df['proxy_url'])]
proxies ={proxy_type[i]: proxy_url[i]}return proxies
エージェントの取得と使用はここでは繰り返されません。前の記事で述べたように、興味のある友人は自分でそれをチェックすることができます。
2日間の練習の後、無料のIPは本当に役に立たなくなり、数秒で実際のIPを見つけました。
02 クッキーの設定
def get_cookies_snuid():"""
SNUID値を取得する
"""
time.sleep(float(random.randint(2,5)))
url ="http://weixin.sogou.com/weixin?type=2&s_from=input&query=python&ie=utf8&_sug_=n&_sug_type_="
headers ={"Cookie":"ABTEST=あなたのパラメータ;IPLOC=CN3301;SUID=あなたのパラメータ;SUIR=あなたのパラメータ"}
# HEADリクエスト,要求されたリソースのヘッダー
response = requests.head(url, headers=headers).headers
result = re.findall('SNUID=(.*?); expires', response['Set-Cookie'])
SNUID = result[0]return SNUID
一般に、Cookieの設定は、アンチクロール全体で最も重要であり、重要なのはSNUID値を動的に変更することです。
その理由についてはここでは詳しく説明しません。結局のところ、インターネットで大神の投稿を読んだときに初めて気づきましたが、理解はまだ非常に浅いです。
100ページ、75ページ、50ページ、さらには最後のクロールでハングする状況でさえ、成功したクロールは1つだけです...
「クライミング・アンチ・クライミング・アンチ・アンチ・クライミング」の泥沼に巻き込まれたくない。データ分析、[データ視覚化](https://cloud.tencent.com/product/yuntu?from=10680)など、クローラーの後のものが私の本当の目的です。
そのため、票数の多い方は急いでそごうエンジニアしか崇拝できません。
/ 03 /データ取得
01 リクエストヘッダーの作成
head ="""
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.9
Connection:keep-alive
Host:weixin.sogou.com
Referer:'http://weixin.sogou.com/',
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
"""
# SNUID値が含まれていません
cookie = 'あなたのクッキー'
def str_to_dict(header):
"""
リクエストヘッダーを作成する,さまざまなリクエストヘッダーをさまざまな関数で作成できます
"""
header_dict = {}
header = header.split('\n')
for h in header:
h = h.strip()
if h:
k, v = h.split(':', 1)
header_dict[k] = v.strip()
return header_dict
02 Webページ情報を取得する
def get_message():"""
Webページ関連情報を取得する
"""
failed_list =[]for i inrange(1,101):print('最初'+str(i)+'ページ')print(float(random.randint(15,20)))
# 遅延を設定する,これはDuNiangが見つけたものです,15秒以上の遅延を設定すると言われています,ブロックされません
time.sleep(float(random.randint(15,20)))
# 10ページごとにSNUID値を変更します
if(i-1)%10==0:
value =get_cookies_snuid()
snuid ='SNUID='+ value +';'
# クッキーを設定する
cookies = cookie + snuid
url ='http://weixin.sogou.com/weixin?query=python&type=2&page='+str(i)+'&ie=utf8'
host = cookies +'\n'
header = head + host
headers =str_to_dict(header)
# プロキシIPを設定する
proxies =get_proxies(i)try:
response = requests.get(url=url, headers=headers, proxies=proxies)
html = response.text
soup =BeautifulSoup(html,'html.parser')
data = soup.find_all('ul',{'class':'news-list'})
lis = data[0].find_all('li')for j in(range(len(lis))):
h3 = lis[j].find_all('h3')
# print(h3[0].get_text().replace('\n',''))
title = h3[0].get_text().replace('\n','').replace(',',',')
p = lis[j].find_all('p')
# print(p[0].get_text())
article = p[0].get_text().replace(',',',')
a = lis[j].find_all('a',{'class':'account'})
# print(a[0].get_text())
name = a[0].get_text()
span = lis[j].find_all('span',{'class':'s2'})
cmp = re.findall("\d{10}", span[0].get_text())
# print(time.strftime("%Y-%m-%d", time.localtime(int(cmp[0])))+'\n')
date = time.strftime("%Y-%m-%d", time.localtime(int(cmp[0])))withopen('sg_articles.csv','a+', encoding='utf-8-sig')as f:
f.write(title +','+ article +','+ name +','+ date +'\n')print('最初'+str(i)+'ページの成功')
except Exception as e:print('最初'+str(i)+'ページが失敗しました')
failed_list.append(i)continue
# ページ番号の取得に失敗しました
print(failed_list)
def main():get_message()if __name__ =='__main__':main()
最後に、データは正常に取得されました。


/ 04 /データの視覚化
**01 公開されたWeChat記事の数TOP10 **
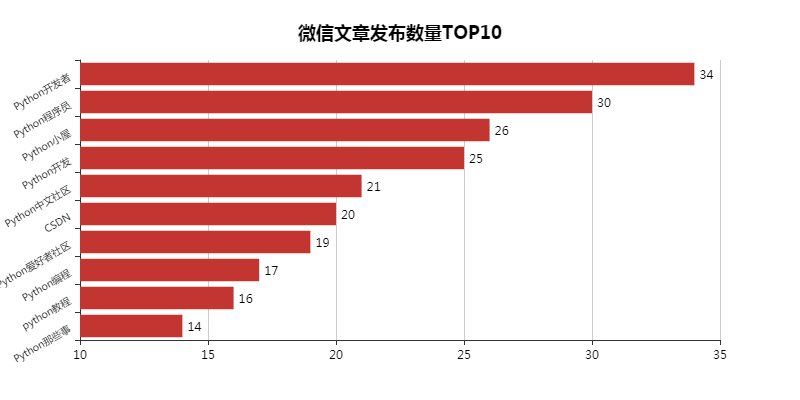
検索したWeChatの記事をここで並べ替えると、これらの10個のPythonビッグウィッグが見つかりました。
実は、チーム運営なのか個人運営なのか知りたいです。しかし、何があっても、最初に注意を払ってください。
この結果は、キーワードPythonを使用した検索にも関連している可能性があります。一見すると、公式アカウントの名前はすべてPythonを使用しています(CSDNを除く)。
from pyecharts import Bar
import pandas as pd
df = pd.read_csv('sg_articles.csv', header=None, names=["title","article","name","date"])
list1 =[]for j in df['date']:
# 記事の発行年を取得する
time = j.split('-')[0]
list1.append(time)
df['year']= list1
# 2018年に公開された記事を選択し、それらを数えます
df = df.loc[df['year']=='2018']
place_message = df.groupby(['name'])
place_com = place_message['name'].agg(['count'])
place_com.reset_index(inplace=True)
place_com_last = place_com.sort_index()
dom = place_com_last.sort_values('count', ascending=False)[0:10]
attr = dom['name']
v1 = dom['count']
bar =Bar("TOP10に掲載されたWeChat記事の数", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0, is_label_show=True, is_legend_show=False, label_pos='right', is_yaxis_inverse=True, is_splitline_show=False)
bar.render("TOP10に掲載されたWeChat記事の数.html")
02 WeChat記事の公開時間の分布
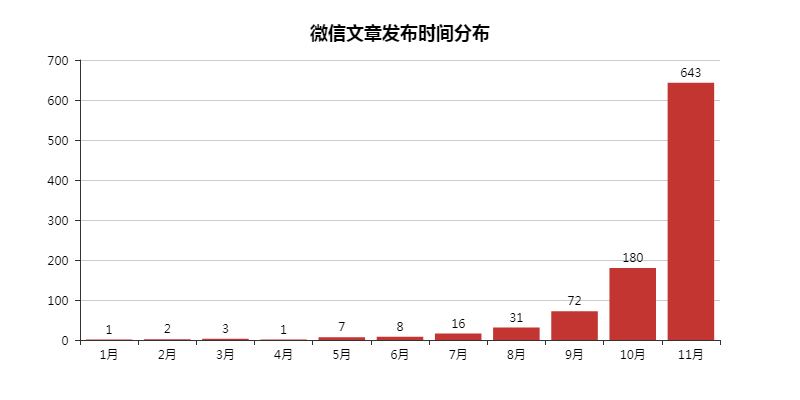
ここで見つかった記事は2018年より前になるため、ここで削除し、残りの記事の公開時間を確認してください。
結局のところ、情報は時間に敏感です。古い情報を検索しても、変化するインターネット業界は言うまでもなく、面白くありません。
import numpy as np
import pandas as pd
from pyecharts import Bar
df = pd.read_csv('sg_articles.csv', header=None, names=["title","article","name","date"])
list1 =[]
list2 =[]for j in df['date']:
# 記事の発行年月を取得する
time_1 = j.split('-')[0]
time_2 = j.split('-')[1]
list1.append(time_1)
list2.append(time_2)
df['year']= list1
df['month']= list2
# 2018年に公開された記事を選択し、それらの月次統計を作成します
df = df.loc[df['year']=='2018']
month_message = df.groupby(['month'])
month_com = month_message['month'].agg(['count'])
month_com.reset_index(inplace=True)
month_com_last = month_com.sort_index()
attr =["{}".format(str(i)+'月')for i inrange(1,12)]
v1 = np.array(month_com_last['count'])
v1 =["{}".format(int(i))for i in v1]
bar =Bar("WeChat記事の公開時間分布", title_pos='center', title_top='18', width=800, height=400)
bar.add("", attr, v1, is_stack=True, is_label_show=True)
bar.render("WeChat記事の公開時間分布.html")
03 タイトル、記事の冒頭ワードクラウド
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import pandas as pd
import jieba
df = pd.read_csv('sg_articles.csv', header=None, names=["title","article","name","date"])
text =''
# for line in df['article'].astype(str):(前の単語のクラウドコード)for line in df['title']:
text +=' '.join(jieba.cut(line, cut_all=False))
backgroud_Image = plt.imread('python_logo.jpg')
wc =WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\STZHONGS.TTF',
max_words=2000,
max_font_size=150,
random_state=30)
wc.generate_from_text(text)
img_colors =ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')
# wc.to_file("論文.jpg")(前の単語のクラウドコード)
wc.to_file("題名.jpg")print('ワードクラウドの成功を構築する!')

公式アカウント記事のタイトルのワードクラウド。検索はキーワードPythonに基づいているため、Pythonは不可欠である必要があります。
その後、クローラー、データ分析、機械学習、人工知能がワードクラウドに登場しました。あなたは現在Pythonの主な目的を知っています!
ただし、PythonはWeb開発、GUI開発などにも使用できます。ここには反映されておらず、明らかに主流ではありません。

パブリックアカウントの記事の冒頭にある単語の雲は、前にエッセイを書いたときに、教師が基本的に最初にあなたのスコアを決定するとは言わなかったことを覚えておいてください。したがって、最初に有名人の言葉を引用してください(古代人は雲を持っています...)。
Recommended Posts