pythonはダウンロードソフトウェアをコンパイルします
毎年恒例のpythonappletプログラミングシリーズの1つ-再開可能なダウンロード用のダウンロードソフトウェア。 #
[ 1. HTTP再開可能送信の原則](https://www.leavesongs.com/#http)##
実際、HTTP再開可能送信の原理は比較的単純で、HTTPデータパケットにRangeヘッダーを追加できます。このヘッダーは、範囲内のバイトストリームをダウンロードするために要求された範囲をバイト単位で指定します。といった:
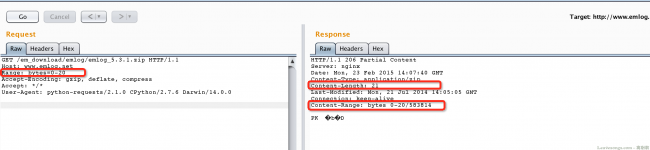
上の図に示すように、データパケットを送信するときに要求されたコンテンツの範囲を選択し、パケットを返して、対応する長さのコンテンツを取得します。したがって、ダウンロードするときに、ターゲットファイルを多数の「小片」に分割し、すべての小片がダウンロードされるまで、一度に1つの小片をダウンロードできます([範囲]を使用して小片の範囲を示します)。
ネットワークが中断されたり、エラーによってダウンロードが終了したりした場合、ダウンロードされた「小さなブロック」とまだダウンロードされていない「小さなブロック」を記録するだけで済みます。次回ダウンロードするときは、ダウンロードされていない小さなブロックの範囲をRangeに入力して、再開可能なアップロードを形成できるようにします。
実際、同じ原則がThunderのようなマルチスレッドダウンローダーにも当てはまります。ターゲットファイルを細かく分割し、それらをさまざまなスレッドに配布してダウンロードし、最後に統合して整合性を確認します。
[ 2. Pythonでファイルをダウンロードする方法](https://www.leavesongs.com/#python)##
以前に紹介したリクエストライブラリをHTTPリクエストライブラリとして引き続き使用します。
最初にこのドキュメントを見てください:[http://docs.python-requests.org/en/latest/user/advanced/#body-content-workflow](http://docs.python-requests.org/en/latest/user/advanced/#body-content-workflow)、要求時にsteam = Trueが設定されている場合、接続はすぐには閉じられません。すべての情報が読み取られるか、応答が呼び出されるまで、ストリームの形式で本文を読み取ります。 close接続を閉じます。
したがって、大きなファイルをダウンロードする場合は、ファイル全体がダウンロードされるのを待ってから戻るのではなく、steamをTrueに設定してゆっくりとダウンロードしてください。
stackoverflowの一部の学生は、簡単なダウンロードデモを行いました。
def download_file(url):
local_filename = url.split('/')[-1]
# NOTE the stream=True parameter
r = requests.get(url, stream=True)withopen(local_filename,'wb')as f:for chunk in r.iter_content(chunk_size=1024):if chunk: # filter out keep-alive newchunks
f.write(chunk)
f.flush()return local_filename
これは基本的に私たちのコアダウンロードコードです。
[ 3.大きなファイルのダウンロードと組み合わせてアップロードを再開します](https://www.leavesongs.com/#_1)##
さて、これら2つの知識ポイントを組み合わせた小さなプログラムを書いてみましょう。再開可能なアップロードをサポートするダウンローダーです。
最初に、注意が必要なポイント、または追加できる機能を検討できます。
- ユーザーのカスタマイズ:cookie、referer、user-agentを定義できます。たとえば、一部のダウンロードサイトでは、ダウンロードを許可する前にユーザーのログインを確認します。
- 多くのサーバーは再開可能なアップロードをサポートしていませんが、どのように判断しますか?
- プログレスバーの表現方法は?
- ファイルの合計サイズを知る方法は? HEADリクエストを使用しますか?サーバーがHEADリクエストをサポートしていない場合はどうなりますか?
- ダウンロードしたファイル名(ヘッダーにファイル名があり、URLにもファイル名があり、ユーザーがファイル名を指定することもできます)、どうすればよいですか?また、Windowsがファイル名を許可しない文字も考慮してください。
- 複数のスレッドを結合するかどうか、ブロックに分割する方法。
実際、考えてみると、まだまだ疑問が多く、しばらく解決できないところもあります。まず、各質問への回答について考えます。
- ヘッダーはユーザーがカスタマイズできます
- 公式ダウンロードの前に、HEADリクエストを実行して、サーバーのステータスコードが206であるかどうか、ヘッダーにRange-contentなどのマークがあるかどうかを確認し、再開可能なアップロードをサポートしているかどうかを判断します。
- 最初は進行状況バーを使用できず、現在のダウンロードサイズと合計サイズのみを表示します
- HEADリクエストのRange-content内のファイルの合計サイズと一致するか、content-lengthサイズを取得します(再開可能なアップロードがサポートされていない場合、合計content-lengthが返されます)。 HEADリクエストがサポートされていない場合、またはコンテンツタイプがない場合は、合計サイズを0に設定します(とにかく、ダウンロードを妨げることはありません)。
- ファイル名の優先順位:ユーザー定義>ヘッダーのcontent-disposition> urlの定義トラブルを回避するために、ここでは、content-dispositionの定義を無視して、linuxのwgetと同じです。保存したユーザー名を指定しない場合は、URLの最後の「/」以降の内容がユーザー名として使用されます。
- 安定性と単純さのために、マルチスレッドを実行しないでください。マルチスレッドを行わない場合は、ブロックを1KBなどの小さなブロックに分割し、最初からダウンロードして、1つのKと1つのKを入力できます。これにより、多くのトラブルを回避できます。ダウンロードが中断された場合、ダウンロードされたバイト数を確認するだけで、次のバイトからダウンロードを続行できます。
これらの質問を解決した後、私たちは書き始めました。実は、ペンを始めなかったときは、質問が思い浮かびませんでしたが、基本的には途中で突然発見した問題でした。
def download(self, url, filename, headers ={}):
finished = False
block = self.config['block']
local_filename = self.remove_nonchars(filename)
tmp_filename = local_filename +'.downtmp'if self.support_continue(url): #ブレークポイント再開のサポート
try:withopen(tmp_filename,'rb')as fin:
self.size =int(fin.read())+1
except:
self.touch(tmp_filename)finally:
headers['Range']="bytes=%d-"%(self.size,)else:
self.touch(tmp_filename)
self.touch(local_filename)
size = self.size
total = self.total
r = requests.get(url, stream = True, verify = False, headers = headers)if total >0:
print "[+] Size: %dKB"%(total /1024)else:
print "[+] Size: None"
start_t = time.time()withopen(local_filename,'ab')as f:try:for chunk in r.iter_content(chunk_size = block):if chunk:
f.write(chunk)
size +=len(chunk)
f.flush()
sys.stdout.write('\b'*64+'Now: %d, Total: %s'%(size, total))
sys.stdout.flush()
finished = True
os.remove(tmp_filename)
spend =int(time.time()- start_t)
speed =int(size /1024/ spend)
sys.stdout.write('\nDownload Finished!\nTotal Time: %ss, Download Speed: %sk/s\n'%(spend, speed))
sys.stdout.flush()
except:import traceback
print traceback.print_exc()
print "\nDownload pause.\n"finally:if not finished:withopen(tmp_filename,'wb')as ftmp:
ftmp.write(str(size))
これがダウンロード方法です。まず、ifステートメントがself.support_continue(url)を呼び出して、ブレークポイントの再開をサポートしているかどうかを判断します。サポートされている場合は、一時ファイルからダウンロードされたバイト数を読み取ります。ファイルが存在しない場合はエラーがスローされ、サイズはデフォルトで0になります。これは、バイトがダウンロードされていないことを意味します。
次に、URLを要求し、ダウンロード接続を取得して、forループをダウンロードします。現時点では、例外をキャッチする必要があります。例外が発生すると、プログラムを終了させることはできませんが、通常、現在ダウンロードされているバイトサイズを一時ファイルに書き込みます。次回ダウンロードするときにこのファイルを読み取り、Rangeをbytes =(size + 1)-、つまり現在のバイトの次のバイトから最後までの範囲に設定します。この範囲からダウンロードを開始して、ブレークポイントの再開を実現します。
再開可能なアップロードをサポートするかどうかを判断する方法では、ターゲットファイルサイズを取得する機能も考慮されます。
def support_continue(self, url):
headers ={'Range':'bytes=0-4'}try:
r = requests.head(url, headers = headers)
crange = r.headers['content-range']
self.total =int(re.match(ur'^bytes 0-4/(\d+)$', crange).group(1))return True
except:
pass
try:
self.total =int(r.headers['content-length'])
except:
self.total =0return False
通常を使用してサイズを一致させ、headers ['content-length']を直接取得して、0に設定します。
コアコードは基本的にこれらであり、いくつかの設定があります。githubにアクセスして直接確認できます:[https://github.com/phith0n/py-wget/blob/master/py-wget.py](https://github.com/phith0n/py-wget/blob/master/py-wget.py)
emlogの最新のインストールパッケージを取得するために実行します。
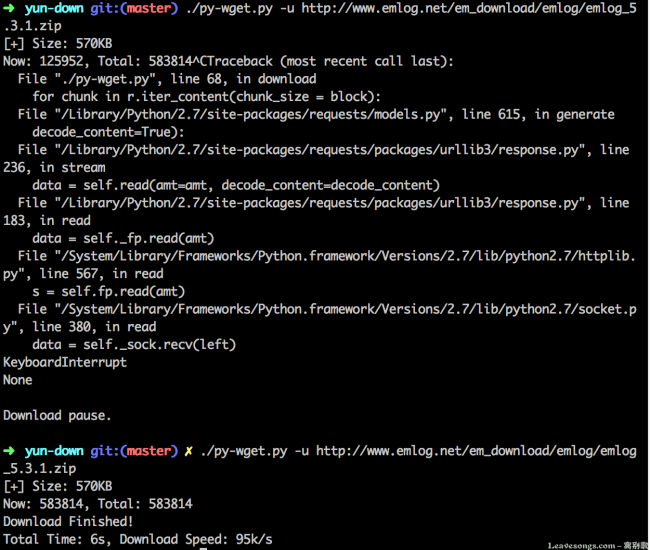
途中でContrl + Cを押して手動でダウンロードを中断しましたが、その後もダウンロードを続けて「ブレークポイント再開」を実現しました。しかし、実際のテストプロセスでは、再開できるリクエストはそれほど多くないため、再開可能な送信をサポートしていないファイル、つまり再ダウンロードを扱います。
ダウンロードされた圧縮パッケージは通常どおり解凍されます。これにより、ダウンロードの整合性が完全に証明されます。
小さなアニメーションを作成しました:
私のこの小さなスクリプトをツールとして使用したい場合は、githubの下の手順を確認できます:[https://github.com/phith0n/py-wget](https://github.com/phith0n/py-wget)。