Pythonファイルの読み取りおよび書き込み操作
ファイルの読み取り
open()メソッドを使用してファイルを開きます(open()は反復可能なファイルオブジェクトを返します):
>>> f =open('test.txt','r')
rはテキストファイルを意味し、rbはバイナリファイルです。 (modeパラメーターのデフォルト値はrです)
ファイルが存在しない場合、 open()関数は IOErrorのエラーをスローし、ファイルが存在しないことを通知するエラーコードと詳細情報を提供します。
>>> f=open('test.txt','r')Traceback(most recent call last):
File "<stdin>", line 1,in<module>
FileNotFoundError:[Errno 2] No such file or directory:'test.txt'
ファイルオブジェクトはオペレーティングシステムのリソースを占有し、オペレーティングシステムが同時に開くことができるファイルの数も制限されるため、ファイルは使用後に閉じる必要があります。
>>> f.close()
ファイルの読み取りおよび書き込み中に IOErrorが発生する可能性があるため、エラーが発生すると、次のf.close()は呼び出されません。したがって、エラーの有無に関係なくファイルを正しく閉じることができるようにするために、 try ... finallyを使用して次のことを実行できます。
try:
f =open('/path/to/file','r')print(f.read())finally:if f:
f.close()
しかし、毎回それほど現実的にするのは面倒なので、Pythonは withステートメントを導入して、自動的にclose()メソッドを呼び出します。
withopen('/path/to/file','r')as f:print(f.read())
pythonファイルオブジェクトは、read()、readline()、readlines()の3つの「読み取り」メソッドを提供します。各メソッドは変数を受け入れて、毎回読み取るデータの量を制限できます。
- read()は毎回ファイル全体を読み取ります。通常、ファイルの内容を文字列変数に入れるために使用されます。ファイルが使用可能なメモリよりも大きい場合は、安全のために、
read(size)メソッドを繰り返し呼び出して、毎回最大サイズのバイトを読み取ることができます。 - readlines()の違いは、後者は.read()と同じように、ファイル全体を一度に読み取ることです。 .readlines()は、ファイルの内容を自動的に行のリストに分析します。これは、Pythonのfor ... in ...構造で処理できます。
- readline()は一度に1行しか読み取りません。これは通常、readlines()よりもはるかに低速です。 Readline()は、ファイル全体を一度に読み取るのに十分なメモリがない場合にのみ使用する必要があります。
注:これらの3つの方法は、各行の終わりにある「\ n」を読み取るためのものであり、デフォルトでは「\ n」は削除されないため、手動で削除する必要があります。
In[2]:withopen('test1.txt','r')as f1:
list1 = f1.readlines()
In[3]: list1
Out[3]:['111\n','222\n','333\n','444\n','555\n','666\n']
'\ n'を削除します
In[4]:withopen('test1.txt','r')as f1:
list1 = f1.readlines()for i inrange(0,len(list1)):
list1[i]= list1[i].rstrip('\n')
In[5]: list1
Out[5]:['111','222','333','444','555','666']
read()およびreadline()の場合、「\ n」も読み込まれますが、印刷中に通常どおり表示できます(印刷中の「\ n」は新しい行を意味すると見なされるため)
In[7]:withopen('test1.txt','r')as f1:
list1 = f1.read()
In[8]: list1
Out[8]:'111\n222\n333\n444\n555\n666\n'
In[9]:print(list1)111222333444555666
In[10]:withopen('test1.txt','r')as f1:
list1 = f1.readline()
In[11]: list1
Out[11]:'111\n'
In[12]:print(list1)111
pythonインタビューの質問の例:
2つのファイルがあり、それぞれにIPアドレスの行が多く、2つのファイルで同じIPアドレスを見つけます。
# coding:utf-8import bisect
withopen('test1.txt','r')as f1:
list1 = f1.readlines()for i inrange(0,len(list1)):
list1[i]= list1[i].strip('\n')withopen('test2.txt','r')as f2:
list2 = f2.readlines()for i inrange(0,len(list2)):
list2[i]= list2[i].strip('\n')
list2.sort()
length_2 =len(list2)
same_data =[]for i in list1:
pos = bisect.bisect_left(list2, i)if pos <len(list2) and list2[pos]== i:
same_data.append(i)
same_data =list(set(same_data))print(same_data)
主なポイントは次のとおりです。(1)使用(2)行末の「\ n」を処理する(3)バイナリ検索を使用してアルゴリズムの効率を向上させます。 (4)setを使用して、重複をすばやく削除します。
ファイルを書き込む###
ファイルの書き込みはファイルの読み取りと同じですが、唯一の違いは、 open()関数が呼び出されると、テキストファイルの書き込みまたはバイナリファイルの書き込みを示すために識別子 'w'または' wb'が渡されることです。
>>> f =open('test.txt','w') #もし'wb'バイナリファイルを書き込む手段
>>> f.write('Hello, world!')>>> f.close()
注:「w」のモードはJiangziです。そのようなファイルがない場合は作成します。ある場合は、元のファイルの内容が最初にクリアされてから、新しいものが書き込まれます。したがって、元のコンテンツをクリアせずに新しいコンテンツを直接追加する場合は、「a」モードを使用します。
write()を繰り返し呼び出してファイルを書き込むことはできますが、 f.close()を呼び出してファイルを閉じる必要があります。ファイルを書き込むとき、オペレーティングシステムは多くの場合、データをすぐにディスクに書き込むのではなく、メモリキャッシュに入れ、空きができたらゆっくりと書き込みます。 close()メソッドが呼び出された場合にのみ、オペレーティングシステムは、書き込まれていないすべてのデータがディスクに書き込まれることを保証します。 close()の呼び出しを忘れた結果、データの一部のみがディスクに書き込まれ、残りは失われます。したがって、安全のために withステートメントを使用してください。
withopen('test.txt','w')as f:
f.write('Hello, world!')
pythonファイルオブジェクトは、write()とwritelines()の2つの「書き込み」メソッドを提供します。
- write()メソッドはread()メソッドとreadline()メソッドに対応し、文字列をファイルに書き込みます。
- writelines()メソッドはreadlines()メソッドに対応し、** list **の操作でもあります。 文字列のリストをパラメータとして受け取り、ファイルに書き込みます。新行文字は自動的に追加されないため、明示的に新行文字を追加する必要があります。
f1 =open('test1.txt','w')
f1.writelines(["1","2","3"])
# このときtest1.txtの内容は:123
f1 =open('test1.txt','w')
f1.writelines(["1\n","2\n","3\n"])
# このときtest1.txtの内容は:
# 1
# 2
# 3
**open()**のモードパラメータについて:
' r ':読む
' w ':書く
' a ':追加
' r + '== r + w(読み取りと書き込み、ファイルが存在しない場合、エラー(IOError)が報告されます)
' w + '== w + r(読み取りと書き込み、ファイルが存在しない場合は作成します)
' a + '== a + r(追加および書き込み可能、ファイルが存在しない場合はファイルが作成されます)
同様に、バイナリファイルの場合は、bを追加するだけです。
' rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
JSON
JSON(JavaScript Object Notation、JSオブジェクト表記)は軽量のデータ交換フォーマットです。 JSONデータ形式は、実際にはpythonの辞書形式であり、Pythonのリストである角括弧で囲まれた配列を含めることができます。
pythonには、json形式を処理するための特別なモジュールがあります-jsonおよびpicleモジュール
Jsonモジュールには、ダンプ、ダンプ、ロード、ロードの4つのメソッドがあります。
ピクルスモジュールは、ダンプ、ダンプ、ロード、ロードの4つの機能も提供します。
1.ダンプとダンプ:
ダンプとダンプのシリアル化方法
strへのシリアル化が完了しただけをダンプします。
dumpはファイル記述子を渡し、シリアル化されたstrをファイルに保存する必要があります
ソースコードを表示:
def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False,**kw):
# Serialize ``obj`` to a JSON formatted ``str``.
# シリアル番号「obj」データタイプは、JSON形式の文字列に変換されます
def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False,**kw):"""Serialize ``obj``as a JSON formatted stream to ``fp``(a
``. write()``-supporting file-like object).
私はそれを2つのアクションとして理解しています。1つのアクションは「obj」をJSON形式の文字列に変換することであり、もう1つのアクションは文字列をファイルに書き込むことです。つまり、ファイル記述子fpが必須パラメーターです。"""
サンプルコード:
>>> import json
>>> json.dumps([]) #ダンプは、すべての基本的なデータタイプを文字列としてフォーマットできます
'[]'>>> json.dumps(1) #デジタル
'1'>>> json.dumps('1') #ストリング
'"1"'>>> dict ={"name":"Tom","age":23}>>> json.dumps(dict) #辞書
'{" name": "Tom", "age": 23}'
a ={"name":"Tom","age":23}withopen("test.json","w", encoding='utf-8')as f:
# インデントは非常に使いやすく、辞書を保存するようにフォーマットされています。デフォルトは「なし」、0未満はゼロスペースです。
f.write(json.dumps(a, indent=4))
# json.dump(a,f,indent=4) #上記と同じ効果
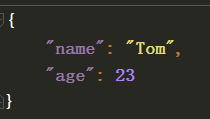
保存されたファイルの効果:
2.ロードとロード
ロードおよびロードの逆シリアル化方法
完了した逆シリアル化のみをロードし、
loadはファイル記述子のみを受け取り、ファイルの読み取りと逆シリアル化を完了します
ソースコードを表示:
def loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None,**kw):"""Deserialize ``s``(a ``str`` instance containing a JSON document) to a Python object.
str型を含むJSONドキュメントをpythonオブジェクトに逆シリアル化します"""
def load(fp, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None,**kw):"""Deserialize ``fp``(a ``.read()``-supporting file-like object containing a JSON document) to a Python object.
JSON形式のデータを含む読み取り可能なファイルをpythonオブジェクトにシリアル化します"""
例:
>>> json.loads('{"name":"Tom", "age":23}'){'age':23,'name':'Tom'}import json
withopen("test.json","r", encoding='utf-8')as f:
aa = json.loads(f.read())
f.seek(0)
bb = json.load(f) #jsonと.loads(f.read())print(aa)print(bb)
# 出力:
{' name':'Tom','age':23}{'name':'Tom','age':23}
3.jsonおよびpicleモジュール
jsonモジュールとpicleモジュールには、dumps、dump、loads、loadの4つの方法があり、使用法は同じです。
シリアル化されたjsonモジュールが一般的な形式であり、他のプログラミング言語で認識される通常の文字列である必要はありません。
pythonのみがシリアル化されたpicleモジュールは認識でき、他のプログラミング言語は文字化けした文字として認識しません
ただし、picleは関数をシリアル化できますが、他のファイルは関数を使用する必要があり、ファイル内にファイル定義が必要です(定義とパラメーターは同じである必要があり、内容は異なる場合があります)
- pythonオブジェクト(obj)とjsonオブジェクトの対応
+- - - - - - - - - - - - - - - - - - - +- - - - - - - - - - - - - - - +| Python | JSON |+===================+===============+| dict | object |+-------------------+---------------+| list, tuple | array |+-------------------+---------------+| str | string |+-------------------+---------------+| int, float | number |+-------------------+---------------+| True |true|+-------------------+---------------+| False |false|+-------------------+---------------+| None |null|+-------------------+---------------+
V.まとめ
- jsonシリアル化方法:
ダンプ:ファイル操作なしダンプ:シリアル化+ファイルの書き込み
- json逆シリアル化方法:
ロード:ファイル操作なしロード:ファイルの読み取り+逆シリアル化
- jsonモジュールによってシリアル化されたデータはより一般的です
picleモジュールによってシリアル化されたデータはpythonでのみ利用可能ですが、強力であり、シリアル番号機能にすることができます
-
jsonモジュールがシリアル化および逆シリアル化できるデータタイプについては、pythonオブジェクト(obj)とjsonオブジェクトの対応表を参照してください。
-
indent = 4を使用してファイルをフォーマットおよび書き込みます
OS.PATH
split
ディレクトリ名を分割し、ディレクトリ名とベース名で指定されたタプルを返します
Split a pathname. Returns tuple "(head, tail)" where "tail" is
everything after the final slash. Either part may be empty.
>>> os.path.split("/tmp/f1.txt")('/tmp','f1.txt')>>> os.path.split("/home/test.sh")('/home','test.sh')
splitext
ファイル名を分割し、ファイル名と拡張子で構成されるタプルを返します
Split the extension from a pathname.
Extension is everything from the last dot to the end, ignoring
leading dots. Returns "(root, ext)"; ext may be empty.
>>> os.path.splitext("/home/test.sh")('/home/test','.sh')>>> os.path.splitext("/tmp/f1.txt")('/tmp/f1','.txt')
# ファイル名を変更する:>>> os.rename('test.txt','test.py')
# ファイルを削除する:>>> os.remove('test.py')
# 現在のディレクトリの絶対パスを表示する:>>> os.path.abspath('.')'/Users/michael'
# ディレクトリに新しいディレクトリを作成し、最初に新しいディレクトリのフルパスを表示します:>>> os.path.join('/Users/michael','testdir')'/Users/michael/testdir'
# 次に、ディレクトリを作成します:>>> os.mkdir('/Users/michael/testdir')
# ディレクトリを削除する:>>> os.rmdir('/Users/michael/testdir')
Recommended Posts