Example of how to automatically download pictures in python
I have been idle these days, and there is always an invisible force lingering around me, making me slack and lethargic.

However, how can a social animal with professional ethics like me doze off during work? I can't help but fall into contemplation. . . .

Suddenly the IOS colleague next to me asked: "Hey, brother, I found the pictures of a website very interesting, can you help me save them and improve my development inspiration? '
As a strong social animal, how can I say that I can’t do it? At that time, I agreed without thinking:'oh, It's simple. Wait for me a few minute.'

Click on the photo website given by the colleague,
The website looks like this:
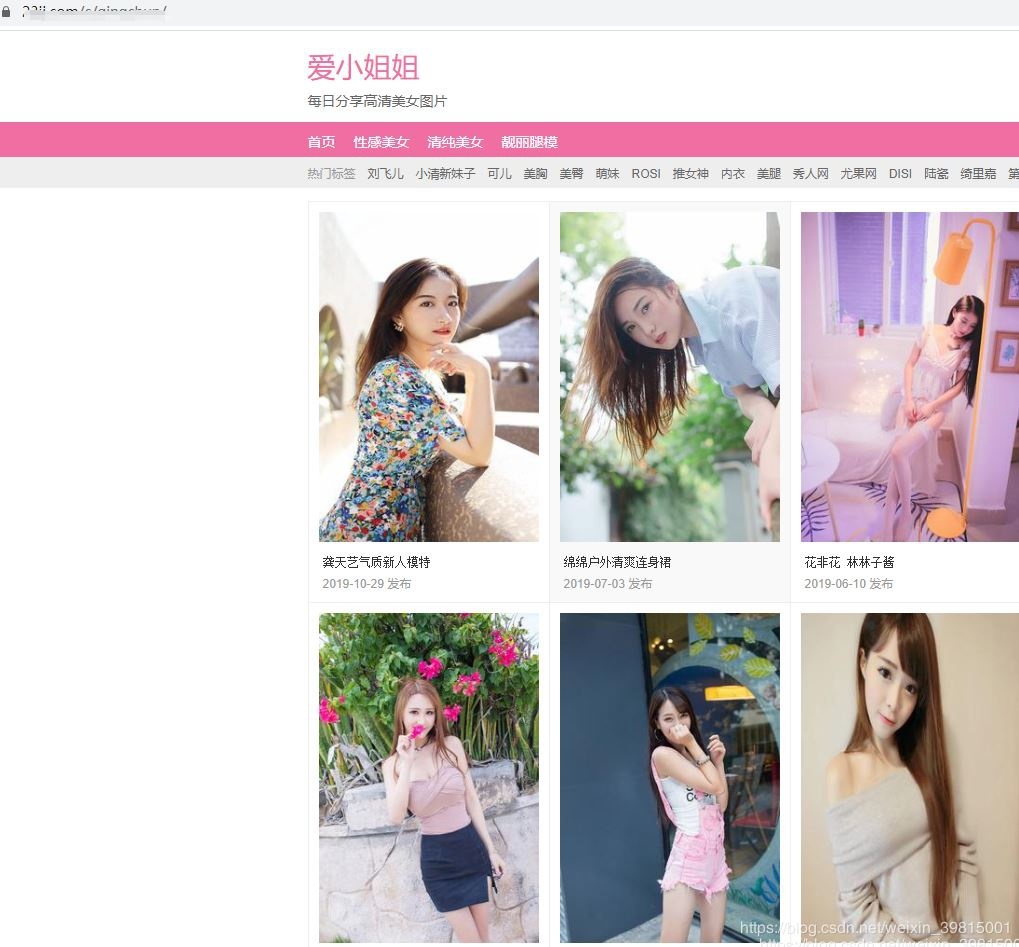
After I flipped through dozens of pages, I suddenly felt a little bit up. I thought in my heart, "No, didn't I come to learn? But how can the thing of seeing beautiful women's pictures be related to learning?'

After contemplating for a while, a flash of inspiration suddenly flashed in my mind, "Want to write a crawler without python, and catch all the pictures of this website in one go."

Do what you say, do it yourself, ask which crawler is better,'Life is short, I use python'.
First, I found the python installation package downloaded half a year ago in my computer, and clicked the installation relentlessly. After the environment was installed, I analyzed the web page structure briefly. Let's start with a simple version of the crawler
# Grab a picture of Miss Ai and save it locally
import requests
from lxml import etree as et
import os
# Request header
headers ={
# User agent
' User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# Base address of the page to be crawled
base_url =''
# Basic path for saving pictures
base_dir ='D:/python/code/aixjj/'
# save Picture
def savePic(pic_url):
# If the directory does not exist, create a new one
if not os.path.exists(base_dir):
os.makedirs(base_dir)
arr = pic_url.split('/')
file_name = base_dir+arr[-2]+arr[-1]print(file_name)
# Get image content
response = requests.get(pic_url, headers = headers)
# Write picture
withopen(file_name,'wb')as fp:for data in response.iter_content(128):
fp.write(data)
# Observe that this website has only 62 pages in total, so it loops 62 times
for k inrange(1,63):
# Request page address
url = base_url+str(k)
response = requests.get(url = url, headers = headers)
# Request status code
code = response.status_code
if code ==200:
html = et.HTML(response.text)
# Get the address of all pictures on the page
r = html.xpath('//li/a/img/@src')
# Get the next page url
# t = html.xpath('//div[@class="page"]/a[@class="ch"]/@href')[-1]for pic_url in r:
a ='http:'+pic_url
savePic(a)print('First%The picture on page d has been downloaded'%(k))print('The End!')
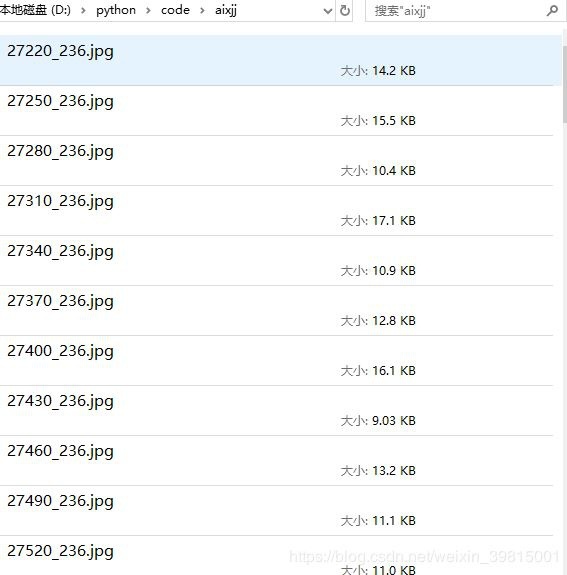
Try to run the crawler, hey, I didn't expect it to work:

After a while, the guy next to me came again: "Hey bro, you can be okay, but the speed is too slow. My inspiration will be wiped out by the long wait. Can you improve it? '

How to improve the efficiency of crawlers? After thinking about it, the company's computer is a great quad-core CPU, or try a multi-process version. Then the following multi-process version was produced
# Multi-process version-grab the pictures of Miss Ai and save them locally
import requests
from lxml import etree as et
import os
import time
from multiprocessing import Pool
# Request header
headers ={
# User agent
' User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# Base address of the page to be crawled
base_url =''
# Basic path for saving pictures
base_dir ='D:/python/code/aixjj1/'
# save Picture
def savePic(pic_url):
# If the directory does not exist, create a new one
if not os.path.exists(base_dir):
os.makedirs(base_dir)
arr = pic_url.split('/')
file_name = base_dir+arr[-2]+arr[-1]print(file_name)
# Get image content
response = requests.get(pic_url, headers = headers)
# Write picture
withopen(file_name,'wb')as fp:for data in response.iter_content(128):
fp.write(data)
def geturl(url):
# Request page address
# url = base_url+str(k)
response = requests.get(url = url, headers = headers)
# Request status code
code = response.status_code
if code ==200:
html = et.HTML(response.text)
# Get the address of all pictures on the page
r = html.xpath('//li/a/img/@src')
# Get the next page url
# t = html.xpath('//div[@class="page"]/a[@class="ch"]/@href')[-1]for pic_url in r:
a ='http:'+pic_url
savePic(a)if __name__ =='__main__':
# Get a list of links to crawl
url_list =[base_url+format(i)for i inrange(1,100)]
a1 = time.time()
# Use the process pool method to create processes, the number of processes created by default=Computer audit
# Define the number of processes pool yourself=Pool(4)
pool =Pool()
pool.map(geturl,url_list)
pool.close()
pool.join()
b1 = time.time()print('operation hours:',b1-a1)
With the mentality of giving it a try, I ran a multi-process version of the crawler. He didn't expect it to work again. With the support of our great quad-core CPU, the crawler speed has increased by 3~4 times.
After a while, the buddy turned his head again: "You are a lot faster, but it is not the most ideal state. Can you crawl a hundred and eighty pictures in a blink of an eye? After all, my inspiration comes 'S go fast too'
I:'…'
Quietly open Google, search how to improve crawler efficiency, and give a conclusion:
Multi-process: When intensive CPU tasks need to make full use of multi-core CPU resources (servers, a large number of parallel computing), use multi-process.
Multithreading: It is appropriate to use multithreading for intensive I/O tasks (network I/O, disk I/O, database I/O).
Oh, isn't this an I/O intensive task? I will write a multi-threaded crawler first. Thus, the third paragraph was born:
import threading #Import threading module
from queue import Queue #Import the queue module
import time #Import the time module
import requests
import os
from lxml import etree as et
# Request header
headers ={
# User agent
' User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# Base address of the page to be crawled
base_url =''
# Basic path for saving pictures
base_dir ='D:/python/code/aixjj/'
# save Picture
def savePic(pic_url):
# If the directory does not exist, create a new one
if not os.path.exists(base_dir):
os.makedirs(base_dir)
arr = pic_url.split('/')
file_name = base_dir+arr[-2]+arr[-1]print(file_name)
# Get image content
response = requests.get(pic_url, headers = headers)
# Write picture
withopen(file_name,'wb')as fp:for data in response.iter_content(128):
fp.write(data)
# Crawl article details page
def get_detail_html(detail_url_list, id):while True:
url = detail_url_list.get() #The get method of Queue is used to extract elements from the queue
response = requests.get(url = url, headers = headers)
# Request status code
code = response.status_code
if code ==200:
html = et.HTML(response.text)
# Get the address of all pictures on the page
r = html.xpath('//li/a/img/@src')
# Get the next page url
# t = html.xpath('//div[@class="page"]/a[@class="ch"]/@href')[-1]for pic_url in r:
a ='http:'+pic_url
savePic(a)
# Crawl the article list page
def get_detail_url(queue):for i inrange(1,100):
# time.sleep(1) #Delay 1s, simulation is faster than crawling article details
# The put method of the Queue queue is used to put elements in the Queue queue. Since the Queue is a first-in-first-out queue, the URL that was put first will also be gotten out first.
page_url = base_url+format(i)
queue.put(page_url)print("put page url {id} end".format(id = page_url))#Print out the URLs of which articles have been obtained
# Main function
if __name__ =="__main__":
detail_url_queue =Queue(maxsize=1000) #Use Queue to construct a thread-safe first-in first-out queue with a size of 1000
# A thread is responsible for crawling the list url
thread = threading.Thread(target=get_detail_url, args=(detail_url_queue,))
html_thread=[]
# In addition, create three threads responsible for grabbing pictures
for i inrange(20):
thread2 = threading.Thread(target=get_detail_html, args=(detail_url_queue,i))
html_thread.append(thread2)#BCD thread crawling article details
start_time = time.time()
# Start four threads
thread.start()for i inrange(20):
html_thread[i].start()
# Wait for all threads to end, thread.join()The function represents that the parent process has been blocked until the child thread is completed.
thread.join()for i inrange(20):
html_thread[i].join()print("last time: {} s".format(time.time()-start_time))#After all four ABCD threads are finished, the total crawling time is calculated in the main process.
After a rough test, I came to the conclusion:'Oh my god, this is too fast.'
Throw the multi-threaded version of the crawler on the face of the colleague’s QQ portrait with the text:'Take it, roll quickly'
So far, this article on the example of how to automatically download pictures in python is introduced. For more related python automatic download pictures, please search for the previous articles of ZaLou.Cn or continue to browse the related articles below. Hope you will support ZaLou more in the future. Cn!
Recommended Posts