乾物| Pythonを使用してmysqlデータベースを操作する

著者|タオ
ソース|ほとんど知っている
この記事では、主にpythonでpymysqlライブラリを使用してmysqlデータベースを操作する方法について説明します。
まず、最も一般的な操作を見てください。
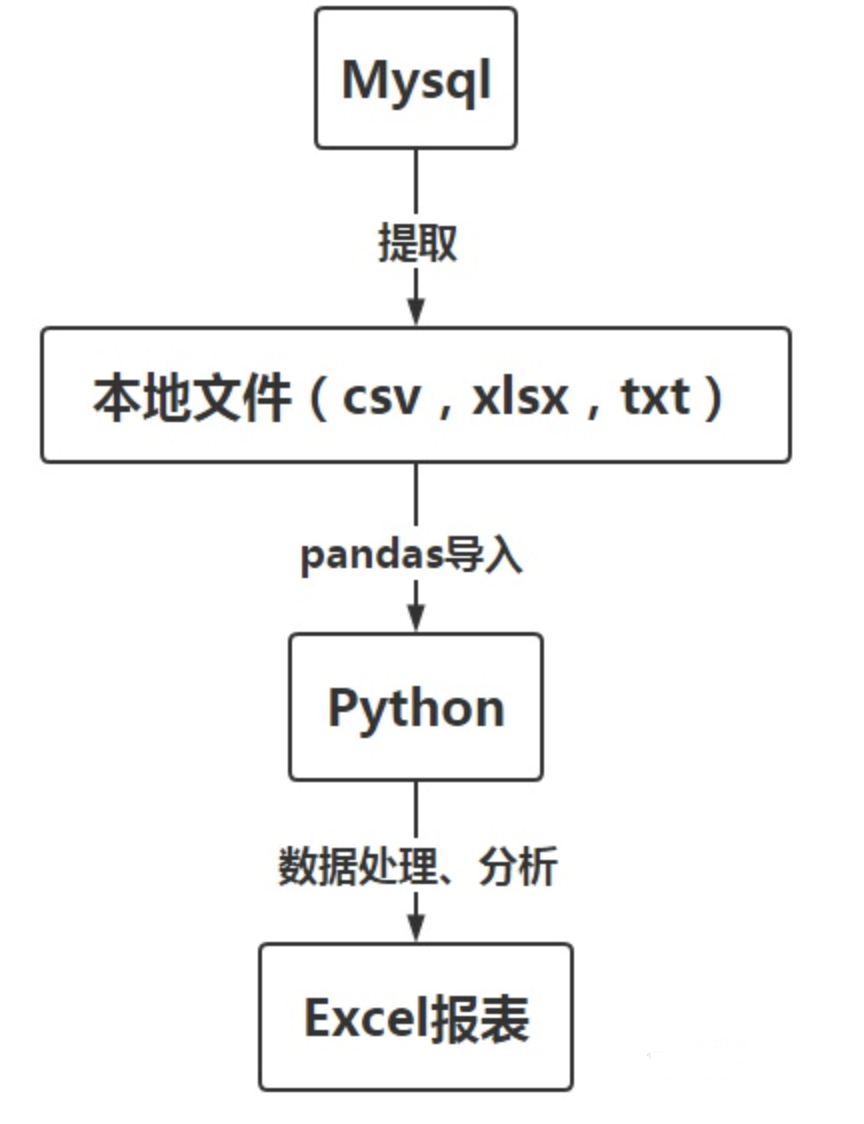
- データベースから必要なフィールドを選択します(単純なデータ集約処理)
- 検索したデータをローカルファイル(csv、txt、xlsxなど)にエクスポートします
- パンダのread_excel(csv、txt)を使用して、ローカルファイルをpythonの変数に変換し、それに応じてデータを処理および分析します
- pandas to_excel(csv、txt)を使用して、処理されたデータをローカルファイルにエクスポートします
しかし、2番目のステップが多すぎると思いませんか?なぜエクスポートしてからインポートする必要があるのですか?この中間ステップは時間の無駄です。理想的なステップは次のようになります。
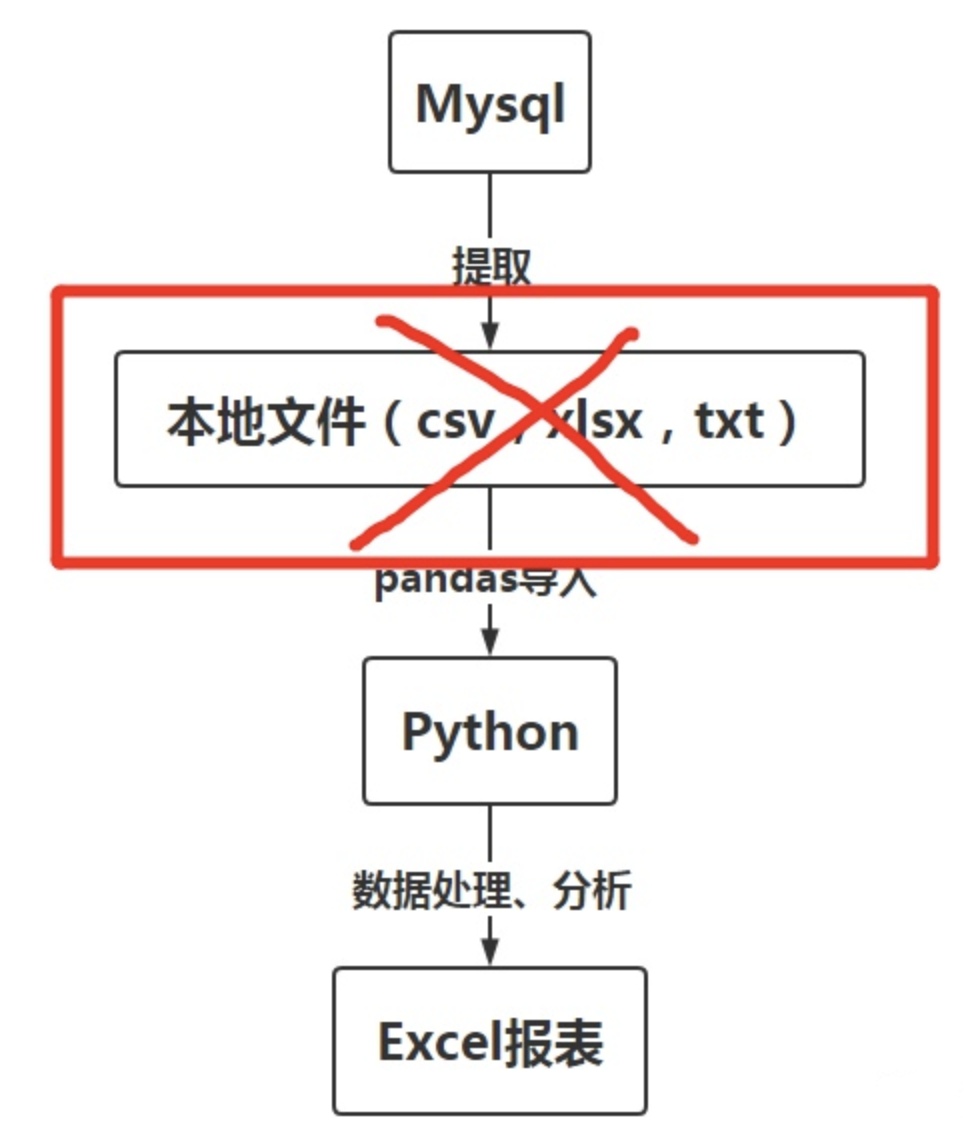
- mysqlのデータをpythonにインポートします
- pythonを使用してデータを処理および分析する
- 優れたレポートにエクスポート
これはあなたをより快適に感じさせますか?だから問題は、mysqlのデータを直接pythonに直接インポートする方法ですか?
これにより、今日の重要なポイントがわかります。
- 最初の方法:read_sql
- 2番目の方法:pymysql
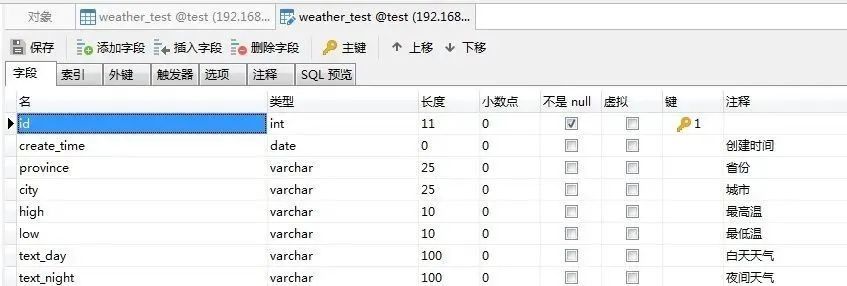
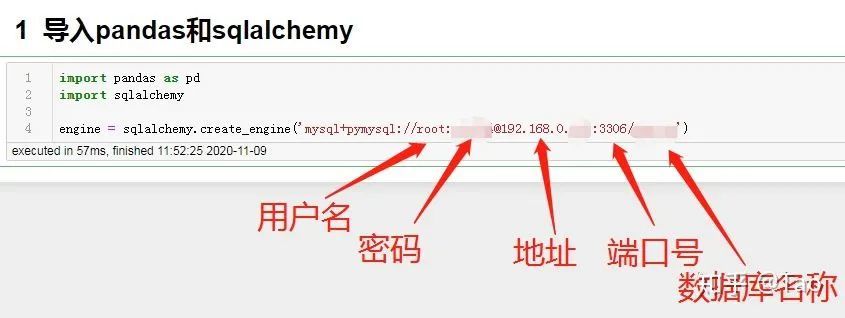
今日のデータベース情報を最初に見てください。
host:192.168.0.***port:3306
user:root
パスワード:********

データベース:テスト
テーブル名:weather_test
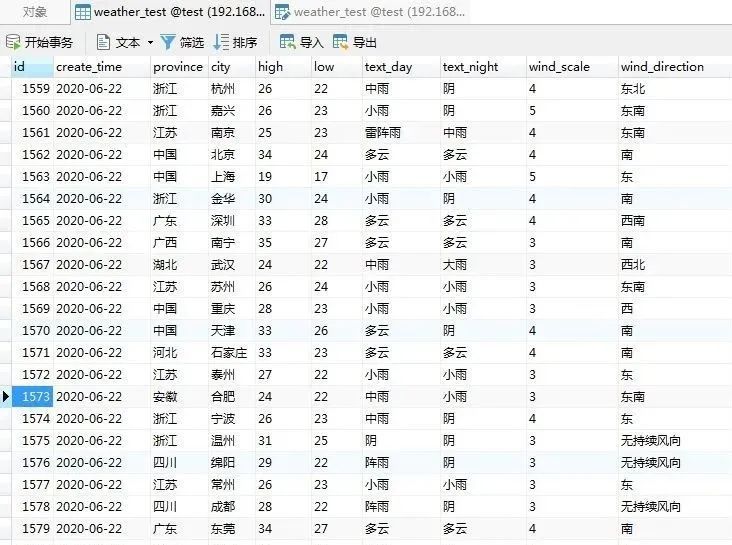
フィールドとデータ:
1
read_sql()
read_sql(sql,con,index_col='None',coerce_float='True',params='None',parse_dates='None',columns='None',chunksize:None='None')
read_sqlメソッドは、パンダで使用され、データベースで指定されたSQLステートメントクエリを実行するか、指定されたテーブル全体をクエリし、クエリ結果を** DataFrameタイプ**で返します。
各パラメーターの意味は次のとおりです。
- sql:実行するSQLステートメント
- con:データベースへの接続に必要なエンジン。SQLalchemyやpymysqlなどの他のデータベース接続パッケージで確立されます。
- index_col:インデックスとして選択する列
- coerce_float:数値文字列をfloatに変換します
- parse_dates:日付文字列の列を日時データに変換します
- 列:保持する列を選択します
- チャンクサイズ:毎回出力されるデータの行数
1. 最初にパンダとsqlalchemyをインポートします

2. 接続を作成
3. sqlコードを記述し、sqlコードを実行し、戻り値を取得します
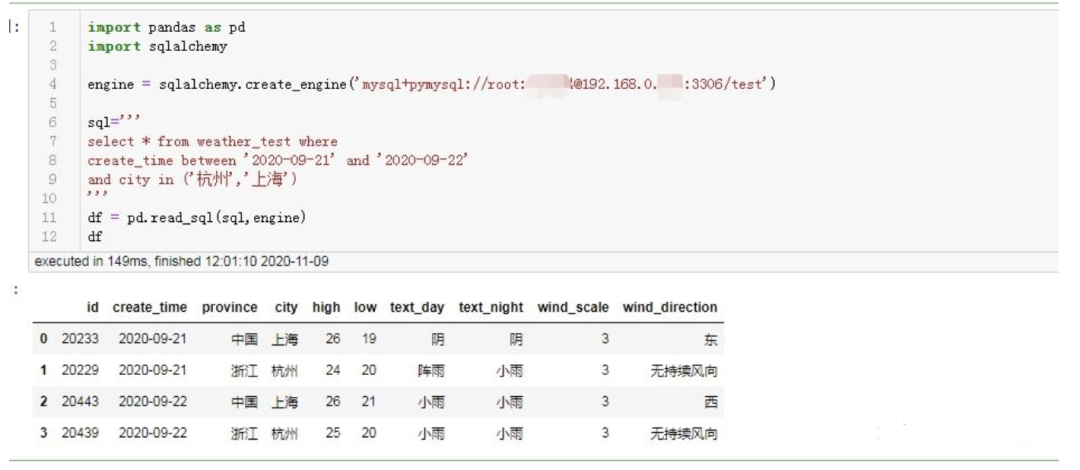
import pandas as pd
import sqlalchemy
engine = sqlalchemy.create_engine('mysql+pymysql://root:******@192.168.0.***:3306/test')
sql='''
select *from weather_test where
create_time between '2020-09-21' and '2020-09-22'
and city in('杭州','上海')'''
df = pd.read_sql(sql,engine)
df
pymysqlを使用して接続とクエリを確立することもできます
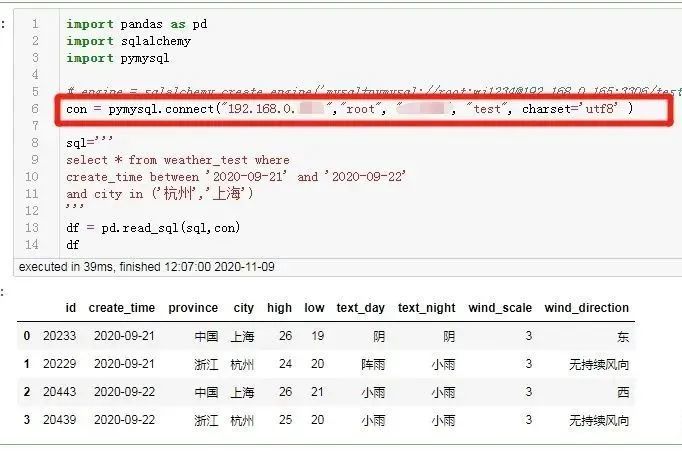
これまでのところ、パンダでread_sqlメソッドを使用して、データベースからデータを1回取得するだけです。
2
PyMySQL
PyMySQLは、Python3.xバージョンのMySQLサーバーに接続するために使用されるライブラリであり、データベースに簡単に接続して操作できます。
1. インストール
最初にcmdを開き、pip install pymysqlと入力して、pymysqlライブラリをインストールします
2. pymysqlを使用してデータベースを操作します
次に、jupyterノートブックを開き、データベースの操作を開始します
2.1 最初にパンダ、pymysqlをインポートします
import pandas as pd
import pymysql
2.2 次に、データベースへの接続を作成します

import pandas as pd
import pymysql
# データベース接続を開く
db = pymysql.connect("192.168.0.***","root","******","test", charset='utf8')
connect()メソッドを使用して、データベースへの接続を確立します。必要な主なパラメーターは、図にすでにマークされています。** Charsetは、中国の文字化けコードを防ぐためにutf8を推奨しています**。確立された接続オブジェクトを変数名dbに割り当てます。
2.3 cursor()メソッドを使用して操作カーソルを取得します

import pandas as pd
import pymysql
# データベース接続を開く
db = pymysql.connect("192.168.0.***","root","******","test", charset='utf8')
# カーソルを使用()操作カーソルを取得する方法
cursor = db.cursor()
カーソルはデータを処理する方法です。結果セット内のデータを表示または処理するために、カーソルは結果セット内の1つ以上の行でデータを参照する機能を提供します。
カーソルはポインタと見なすことができ、結果の任意の位置を指定して、ユーザーが指定した位置でデータを処理できるようにします。素人の用語では、**操作データとデータベース結果の取得はカーソルを介して操作する必要があります。 **カーソルを取得しないと、クエリされたデータを取得できません。
最も一般的に使用されるデフォルトのカーソルはカーソルです。返されるデータ形式はタプルです。残りのカーソルタイプには、DictCursor、SSCursor、SDictCursorなどがあります。SSの先頭にあるカーソルはストリームカーソルと呼ばれ、CursorおよびDictCursorカーソルは次のことができます。すべてのデータが一度に返され、ストリーミングカーソルはクエリデータを1つずつインテリジェントに返すため、このタイプのカーソルは、メモリが少なく、ネットワーク帯域幅が小さく、データ量が多いアプリケーションシナリオに適しています。
DictCursor:データを辞書(Dict)形式で返します
SSCursor:ストリーミングカーソルはタプル形式のデータを返します
SSDictCursor:ストリーミングカーソルは辞書(Dict)形式のデータを返します
他のカーソルを使用する場合は、cursor()メソッドに対応するパラメーターを追加するだけです。
cursor = db.cursor(pymysql.cursors.SSDictCursor)
2.4 sqlコードを記述し、sqlコードを実行します
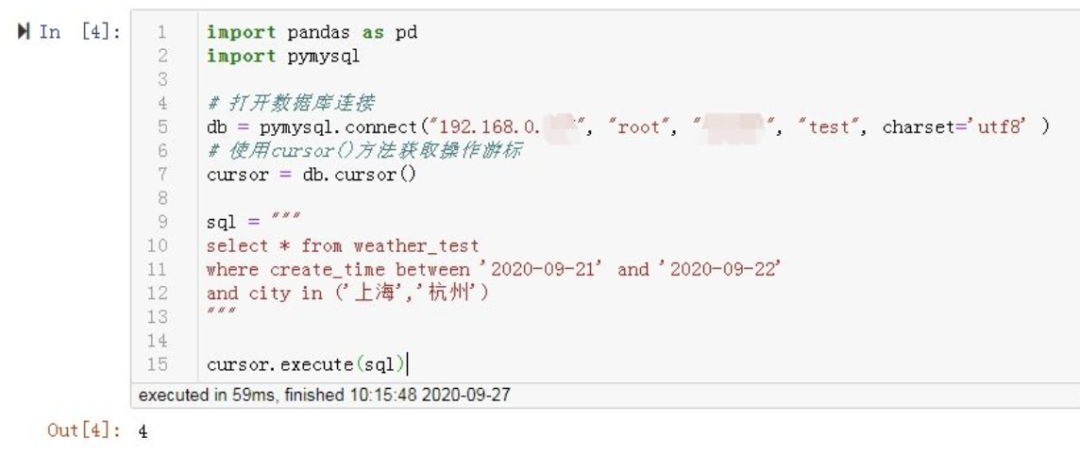
簡単なSQLステートメントを記述します。目的は2020-09-21〜2020-09-22の2日間の上海と杭州の天気をチェックし、記述されたSQLステートメントを文字列形式に変更して変数名sqlに割り当てることです。 ** execute()**メソッドを使用すると、定義されたカーソルを介して記述されたSQLステートメントを実行でき、数値4が出力されていることがわかります。これは、クエリされたデータセットに合計4つのデータが含まれていることを意味します。
2.5 返されたクエリ結果を取得します
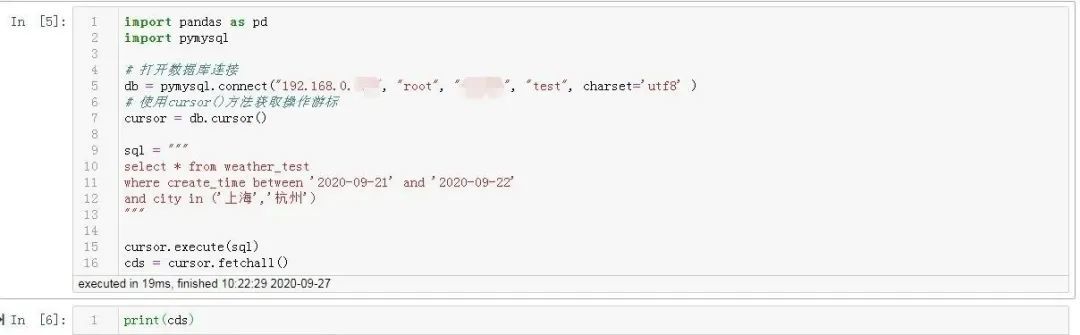
fetchall()メソッドを使用して、定義されたカーソルを介して照会された完全なデータセットを取得し、それを変数名cdsに割り当てます。
cds変数を出力すると、データが取得されたことがわかります。次に、一般的に使用されるDataFrame形式に変更する必要があります。
fetchall()メソッドに加えて、返されたデータを取得するための2つのメソッドfetchone()とfetchmany(size)があります。
fetchall():すべてのデータを返します
fetchone():次のデータに戻る
fetchmany(size):次のサイズのデータを返します
2.6 取得したデータをDataFrame形式に変換します
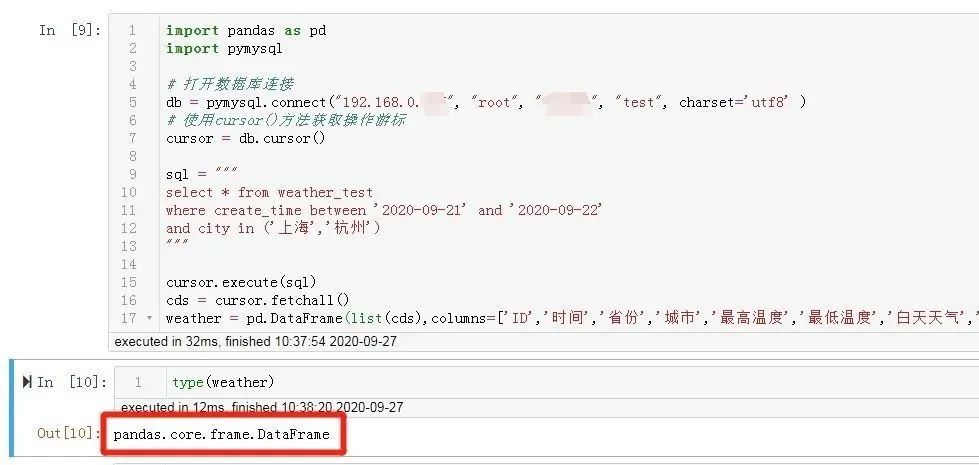
タプル形式のcds変数をリストに変換してから、パンダのDataFrame()メソッドを使用してcdsをDataFrame形式に変換し、列名を変更して、天気変数名に割り当てます。
データを見るために天気を出力する
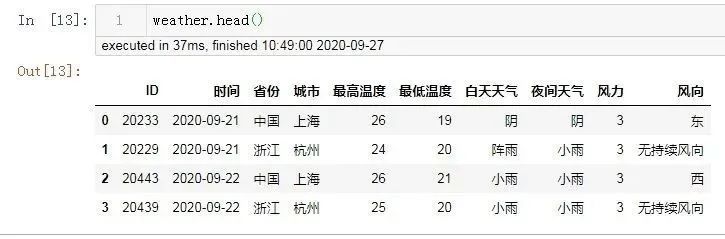
2.7 カーソルを閉じ、データベース接続を閉じます
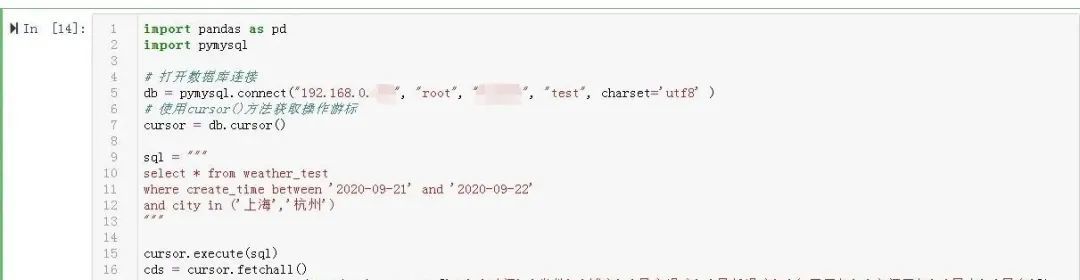
import pandas as pd
import pymysql
# データベース接続を開く
db = pymysql.connect("192.168.0.***","root","******","test", charset='utf8')
# カーソルを使用()操作カーソルを取得する方法
cursor = db.cursor()
sql ="""
select *from weather_test
where create_time between '2020-09-21' and '2020-09-22'
and city in('上海','杭州')"""
cursor.execute(sql)
cds = cursor.fetchall()
weather = pd.DataFrame(list(cds),columns=['ID','時間','州','市','最高温度','最低気温','日中の天気','夜の天気','風力','風向き'])
cursor.close() #カーソルを閉じる
db.close() #データベース接続を閉じる
pymysqlを使用して接続オブジェクトを作成すると、mysqlとの長いtcp接続が作成されます。このオブジェクトのcloseメソッドが呼び出されない限り、長い接続は切断されず、リソースは常に占有されます。 、実行後にカーソルとデータベース接続を閉じることを忘れないでください
上記は、pythonを使用してデータベースにクエリを実行する最も簡単な方法です。他の追加、削除、および変更はこれに似ており、自分でプレイできます。
- END -
この記事は共有と推奨読書のために転載されています。侵害がある場合は、背景に連絡して削除してください
Recommended Posts