Python文字列
注意内容:Pythonエスケープ文字
**注の日付:2017-10-24 **
文字列の基本的な内容は基本的なデータタイプで導入されているので、ここでは繰り返しません。
- Pythonエスケープ文字
- Python文字列演算子
- Pythonトリプルクォート
- Pythonの文字列組み込み関数
Pythonエスケープ文字
文字に特殊な文字を使用する必要がある場合、Pythonはバックスラッシュ()を使用して文字をエスケープします。次の表:

その中で、\ nと\ tが最も一般的に使用され、次にエスケープ引用符とエスケープバックスラッシュが続きます
Python文字列演算子
次の表では、変数aの値は文字列「Hello」であり、b変数の値は「Python」です。

a ="Hello"
b ="Python"print("a +b出力結果:", a + b)print("a *2出力結果:", a *2) #2回の内容を出力し、*n、前の文字列をn回出力します
print("a[1]出力結果:", a[1]) #添え字から値を取る
print("a[1:4]出力結果:", a[1:4]) #傍受文字列添え字1-4printを除く4以内の文字('hello world'[-1]) #負の数は逆の順序で値を取るので、-1は最後の添え字の値です
print('hello world'[0:]) #0から開始し、次のすべての値を取ります
print('hello world'[:5]) #0から開始し、添え字5ifまでインターセプトします("H"in a):print("Hは変数aにあります")else:print("Hは変数aにありません")if("M" not in a):print("Mは変数aにありません")else:text-align: left;print("Mは変数aにあります")print(r'\n')print(R'\n')
# printステートメントの前にrを追加して、これが生の文字列であることを示します。これにより、一部の特殊文字がエスケープされます。
print(r'c:\test\abc\123')
# 資本化も可能です
print(R'c:\test\abc\123')
# 文字列を宣言するときに書くこともできます
s=r'c:\test\abc\123'print(s)
動作結果:
a + b出力:HelloPython
a * 2出力結果:HelloHello
a [1]出力結果:e
a [1:4]出力結果:ell
Hは変数aにあります
Mは変数aにありません
\n
\n
より一般的に使用されるものには、+、*、[]、[:]およびメンバー演算子があります。
Python文字列のフォーマット
Pythonは、フォーマットされた文字列の出力をサポートしています。この方法では非常に複雑な式を使用できますが、最も基本的な使用法は、文字列形式の文字%sを使用して文字列に値を挿入することです。
Pythonでは、文字列の書式設定はC言語のprintf関数と同じ構文を使用します。単純な使用法のみを使用する場合は、printfとして使用できます。コード例:
print("私の名前は%今年は%d歳!"%('シャオミン',10))
動作結果:
私の名前はシャオミンです。10歳です。
文字列の書式設定はめったに使用されません。それは味のないものです。そのようなものがあるかどうかだけを知ってください。
Python文字列フォーマット記号:

オペレーター補助命令のフォーマット:
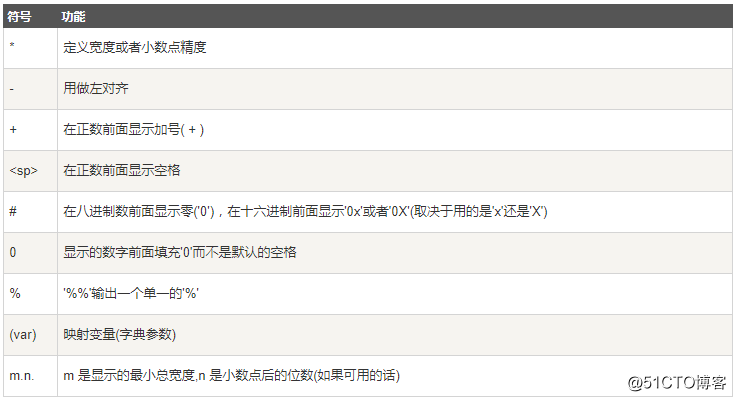
Pythonの三重引用符
Pythonの三重引用符を使用すると、文字列を複数行にまたがることができます。文字列には、改行、タブ、その他の特殊文字を含めることができます。コード例:
para_str ="""これは複数行の文字列の例です
複数行の文字列はタブを使用できます
TAB( \t )。
改行も使用できます[ \n ]。
"""
print(para_str)
動作結果:
これは複数行の文字列の例です
複数行の文字列はタブを使用できます
TAB ( )。
改行を使用することもできます[
]。
Pythonの文字列組み込み関数
Python文字列の一般的に使用される組み込み関数は次のとおりです。
| シリアル番号 | 方法と説明 |
|---|---|
| 1 | Capitalize()は文字列の最初の文字を大文字に変換します |
| 2 | center(width、fillchar)は、中央に指定された幅の文字列を返します。fillcharは塗りつぶされた文字であり、デフォルトはスペースです。 |
| 3 | count(str、beg = 0、end = len(string))は、文字列内のstrの出現回数を返します。begまたはendが指定されている場合は、指定された範囲内のstrの出現回数を返します。 |
| 4 | bytes.decode(encoding =” utf-8”、errors =” strict”)Python3にはdecodeメソッドはありませんが、bytesオブジェクトのdecode()メソッドを使用して、特定のbytesオブジェクトをデコードできます。このbytesオブジェクトはstrで使用できます。リターンをエンコードするencode()。 |
| 5 | encode(encoding = 'UTF-8'、errors = 'strict')encodingで指定されたエンコード形式で文字列をエンコードします。エラーが発生した場合、エラーで「ignore」または「replace」が指定されていない限り、ValueError例外がデフォルトで報告されます |
| 6 | ceendswith(suffix、beg = 0、end = len(string))文字列がobjで終わるかどうかを確認し、begまたはendが指定されている場合は、指定された範囲がobjで終わるかどうかを確認します。はいの場合はTrueを返し、そうでない場合はFalseを返します。 |
| 7 | expandtabs(tabsize = 8)は、文字列内のタブシンボルをスペースに変換します。タブシンボルのデフォルトのスペース数は8です。 |
| 8 | find(str、beg = 0 end = len(string))strが文字列に含まれているかどうかを確認します。範囲begとendが指定されている場合は、指定された範囲内に含まれているかどうかを確認します。含まれている場合は開始インデックス値を返し、そうでない場合は戻ります。 1 |
| 9 | index(str、beg = 0、end = len(string))はfind()メソッドと同じですが、strが文字列にない場合に例外が報告される点が異なります。 |
| 10 | isalnum()は、文字列に少なくとも1つの文字があり、すべての文字が文字または数字の場合はTrueを返し、それ以外の場合はFalseを返します |
| 11 | isalpha()は、文字列に少なくとも1つの文字があり、すべての文字が文字である場合はTrueを返し、それ以外の場合はFalseを返します |
| 12 | isdigit()は、文字列に数字のみが含まれている場合はTrueを返し、それ以外の場合はFalseを返します。 |
| 13 | islower()は、文字列に大文字と小文字が区別される文字が少なくとも1つ含まれている場合、Trueを返します。これらの(大文字と小文字が区別される)文字はすべて小文字です。それ以外の場合は、False |
| 14 | isnumeric()文字列に数字のみが含まれている場合はTrueを返し、そうでない場合はFalseを返します |
| 15 | isspace()文字列に空白のみが含まれている場合はTrueを返し、そうでない場合はFalseを返します。 |
| 16 | istitle()は、文字列にタイトルが付いている場合はTrueを返します(title()を参照)。そうでない場合はFalseを返します |
| 17 | isupper()文字列に大文字と小文字が区別される文字が少なくとも1つ含まれていて、これらの(大文字と小文字が区別される)文字がすべて大文字の場合はTrueを返し、そうでない場合はFalseを返します |
| 18 | join(seq)は、指定された文字列を区切り文字として受け取り、seq内のすべての要素(文字列表現)を新しい文字列にマージします |
| 19 | len(string)は文字列の長さを返します |
| 20 | ljust(width [、fillchar])は、元の文字列が左寄せされ、fillcharで長さ幅に入力された新しい文字列を返します。fillcharのデフォルトはスペースです。 |
| 21 | lower()は、文字列内のすべての大文字を小文字に変換します。 |
| 22 | lstrip()は、文字列の左側のスペースまたは指定された文字を切り取ります。 |
| 23 | maketrans()は、文字マッピングの変換テーブルを作成します。2つのパラメーターを受け入れる最も単純な呼び出しメソッドの場合、最初のパラメーターは変換される文字を示す文字列であり、2番目のパラメーターも変換のターゲットを示す文字列です。 |
| 24 | max(str)は、文字列strの最大の文字を返します。 |
| 25 | min(str)は、文字列strの最小の文字を返します。 |
| 26 | replace(old、new [、max])文字列のstr1をstr2に置き換えます。maxが指定されている場合、置き換えは最大回数を超えません。 |
| 27 | rfind(str、beg = 0、end = len(string))はfind()関数に似ていますが、右から検索します。 |
| 28 | rindex(str、beg = 0、end = len(string))はindex()に似ていますが、右から始まります。 |
| 29 | rjust(width、[、fillchar])は、元の文字列が右寄せされ、fillchar(デフォルトのスペース)で長さ幅に入力された新しい文字列を返します |
| 30 | rstrip()は、文字列の最後のスペースを削除します。 |
| 31 | split(str =””、num = string.count(str))num = string.count(str))文字列をインターセプトするための区切り文字としてstrを使用します。numに指定された値がある場合、num個のサブストリングのみがインターセプトされます |
| 32 | splitlines([keepends])は行( '\ r'、 '\ r \ n'、\ n ')で区切られ、各行を要素として含むリストを返します。パラメーターkeependsがFalseの場合、改行は含まれません。Trueの場合、newline文字は保持されます。 |
| 33 | startupwith(str、beg = 0、end = len(string))文字列がobjで始まるかどうかを確認します。ある場合は、Trueを返し、そうでない場合はFalseを返します。 begとendで値を指定する場合は、指定した範囲内で確認してください。 |
| 34 | strip([chars])は、文字列に対してlstrip()とrstrip()を実行します |
| 35 | swapcase()は、文字列内で大文字を小文字に、小文字を大文字に変換します |
| 36 | title()は「titled」文字列を返します。これは、すべての単語が大文字で始まり、残りの文字が小文字であることを意味します(istitle()を参照) |
| 37 | translate(table、deletechars =””)は、strで指定されたテーブル(256文字を含む)に従って文字列の文字を変換し、フィルターで除外する文字をdeletecharsパラメーターに配置します |
| 38 | upper()は、文字列内の小文字を大文字に変換します |
| 39 | zfill(width)は長さwidthの文字列を返し、元の文字列は右揃えになり、前面は0で埋められます |
| 40 | isdecimal()は、文字列に10進文字のみが含まれているかどうかを確認し、含まれている場合はtrueを返し、含まれていない場合はfalseを返します。 |
一般的に使用されるいくつかの関数コードの例:
s ="hello..."
upper ="HELLO..."print("sの最初の文字を大文字に変換します。", str.capitalize(s))print("s内の「l」の出現回数:", s.count("l"))print("'で終わりますか...'終わり:", s.endswith("..."))print("'で終わりますかh’开头:", s.startswith("h"))print("sの「o」の添え字は(見つからない場合は、-1):", s.find("o"))print("sの「o」の添え字は次のとおりです(見つからない場合は、例外がスローされます)。", s.index("o"))print("sの「o」を「c」に置き換えます。", s.replace("o","c"))print("sの最大の文字は次のとおりです。",max(s))print("sの最小文字は次のとおりです。",min(s))print("大文字を小文字に変換します。", upper.lower())print("sを大文字に変換します。", s.upper())print("タイトルを付ける:", s.title())
seq =("a","b","c","d","e") #文字列シーケンス
print("seqの文字を組み合わせる:","".join(seq))print("seqの長さは次のとおりです。",len(seq)) #文字列シーケンスも使用できます
print("sの長さは次のとおりです。",len(s))
s2 ="a,b,c,d,e,f,g"print("s2の文字列をコンマで区切ります", s2.split(","))
s3 ="This is swapcase method test"print("s3の文字列の大文字を小文字に、小文字を大文字に変換します。", s3.swapcase())
s4 =" Test "print("s4の左右のスペースを削除します。", s4.strip())
操作結果:
sの最初の文字を大文字に変換します:こんにちは...
sでの「l」の出現数:2
sの「...」で終わるかどうか:True
sの「h」で始めるかどうか:True
sの「o」の添え字は次のとおりです(見つからない場合は-1を返します):4
sの「o」の添え字は次のとおりです(見つからない場合は例外がスローされます):4
sの「o」を「c」に置き換えます:hellc .. ..
sの最大の文字は次のとおりです。o
sの最小文字は次のとおりです。
大文字を小文字に変換します:こんにちは...
sを大文字に変換します:HELLO .. ..
タイトルs:こんにちは...
seqの文字を組み合わせる:abcde
seqの長さは次のとおりです:5
sの長さは次のとおりです:8
s2の文字列をコンマで区切ります['a'、 'b'、 'c'、 'd'、 'e'、 'f'、 'g']
s3の文字列の大文字を小文字に、小文字を大文字に変換します。これはSWAPCASEメソッドテストです。
s4の左右のスペースを削除します:テスト
Recommended Posts