Pythonの基本4
このセクションの内容
- リストおよびタプル操作
- 文字列操作
- 辞書操作
- 収集操作
- ファイル操作
- 文字のエンコードとトランスコーディング
1. リストおよびタプル操作###
このリストは、将来最も一般的に使用されるデータタイプの1つです。リストを通じて、最も便利なデータの保存、変更、およびその他の操作を実現できます。
定義リスト
names =['Alex',"Tenglan",'Eric']
添え字でリスト内の要素にアクセスします。添え字は0からカウントを開始します
>>> names[0]'Alex'>>> names[2]'Eric'>>> names[-1]'Eric'>>> names[-2] #あなたはそれを逆にすることもできます
' Tenglan'
スライス:複数の要素を取ります
>>> names =["Alex","Tenglan","Eric","Rain","Tom","Amy"]>>> names[1:4] #添え字1と添え字4の間の数字を取ります。1を含み、4を除きます。['Tenglan','Eric','Rain']>>> names[1:-1] #添え字1を-値1、含まない-1['Tenglan','Eric','Rain','Tom']>>> names[0:3]['Alex','Tenglan','Eric']>>> names[:3] #最初から取った場合、0は無視でき、効果は前文と同じです。
[' Alex','Tenglan','Eric']>>> names[3:] #あなたが最後のものを取りたいなら、あなたは書いてはいけません-1.書く唯一の方法
[' Rain','Tom','Amy']>>> names[3:-1] #そのような-1は含まれません
[' Rain','Tom']>>> names[0::2] #次の2つは代表であり、他のすべての要素は1つを取る
[' Alex','Eric','Tom']>>> names[::2] #前文と同じ効果
[' Alex','Eric','Tom']
追加
>>> names
[' Alex','Tenglan','Eric','Rain','Tom','Amy']>>> names.append("私はここでは新人です")>>> names
[' Alex','Tenglan','Eric','Rain','Tom','Amy','私はここでは新人です']
インサート
>>> names
[' Alex','Tenglan','Eric','Rain','Tom','Amy','私はここでは新人です']>>> names.insert(2,"エリックの正面から無理やり挿入")>>> names
[' Alex','Tenglan','エリックの正面から無理やり挿入','Eric','Rain','Tom','Amy','私はここでは新人です']>>> names.insert(5,"エリックの後ろから挿入して、新しいポーズを試してください")>>> names
[' Alex','Tenglan','エリックの正面から無理やり挿入','Eric','Rain','エリックの後ろから挿入して、新しいポーズを試してください','Tom','Amy','私はここでは新人です']
変更
>>> names
[' Alex','Tenglan','エリックの正面から無理やり挿入','Eric','Rain','エリックの後ろから挿入して、新しいポーズを試してください','Tom','Amy','私はここでは新人です']>>> names[2]="変える時">>> names
[' Alex','Tenglan','変える時','Eric','Rain','エリックの後ろから挿入して、新しいポーズを試してください','Tom','Amy','私はここでは新人です']
削除
>>> del names[2]>>> names
[' Alex','Tenglan','Eric','Rain','エリックの後ろから挿入して、新しいポーズを試してください','Tom','Amy','私はここでは新人です']>>> del names[4]>>> names
[' Alex','Tenglan','Eric','Rain','Tom','Amy','私はここでは新人です']>>>>>> names.remove("Eric") #指定した要素を削除します
>>> names
[' Alex','Tenglan','Rain','Tom','Amy','私はここでは新人です']>>> names.pop() #リストの最後の値を削除します
' 私はここでは新人です'>>> names
[' Alex','Tenglan','Rain','Tom','Amy']
拡張
>>> names
[' Alex','Tenglan','Rain','Tom','Amy']>>> b =[1,2,3]>>> names.extend(b)>>> names
[' Alex','Tenglan','Rain','Tom','Amy',1,2,3]
コピー
>>> names
[' Alex','Tenglan','Rain','Tom','Amy',1,2,3]>>> name_copy = names.copy()>>> name_copy
[' Alex','Tenglan','Rain','Tom','Amy',1,2,3]
統計
>>> names
[' Alex','Tenglan','Amy','Tom','Amy',1,2,3]>>> names.count("Amy")2
並べ替えと反転
>>> names
[' Alex','Tenglan','Amy','Tom','Amy',1,2,3]>>> names.sort() #ソート
Traceback(most recent call last):
File "<stdin>", line 1,in<module>
TypeError: unorderable types:int()<str() #3.異なるデータタイプを0で一緒にソートすることはできません
>>> names[-3]='1'>>> names[-2]='2'>>> names[-1]='3'>>> names
[' Alex','Amy','Amy','Tenglan','Tom','1','2','3']>>> names.sort()>>> names
['1','2','3',' Alex','Amy','Amy','Tenglan','Tom']>>> names.reverse() #逆行する
>>> names
[' Tom','Tenglan','Amy','Amy','Alex','3','2','1']
添え字を取得
>>> names
[' Tom','Tenglan','Amy','Amy','Alex','3','2','1']>>> names.index("Amy")2 #見つかった最初の添え字のみを返す
タプル####
タプルは実際にはリストに似ており、一連の番号も格納しますが、一度作成すると変更できないため、読み取り専用リストとも呼ばれます。
文法
names =("alex","jack","eric")
2つのメソッドしかありません。1つはカウント、もう1つはインデックスで、これで完了です。
プログラム演習####
目を閉じて、次のプログラムを書いてください。
手順:ショッピングカートの手順
要求する:
- プログラムを開始した後、ユーザーに給与を入力させ、商品のリストを印刷します
- ユーザーが製品番号に基づいて製品を購入できるようにする
- ユーザーが製品を選択した後、残高が十分であるかどうかを確認し、十分である場合は直接差し引き、十分でない場合は通知します
- いつでも引き出すことができ、引き出し、購入した商品を印刷し、残高
product_list=[('Iphone',5800),('Mac Pro',9800),('Bike',800),('Watch',10600),('Coffee',31),('Alex Python',120)]
shopping_list=[] #空のショッピングカートを作成する
salary=input("Input your salary:") #残高を入力してください
if salary.isdigit(): #それが数字かどうかを判断する
salary=int(salary)while True:for index,item inenumerate(product_list): #インデックスを列挙する
print(index,item)
user_choice=input("購入することを選択します?>>>:") #選択インデックスを入力してください
if user_choice.isdigit(): #入力が数値かどうかを判断します
user_choice=int(user_choice)if user_choice <len(product_list) and user_choice >=0: #入力した数値が0以上で、製品リストの長さ未満
p_item = product_list[user_choice] #pを割り当てる_アイテム変数
if p_item[1]<= salary: #残高が以下かどうかを判断します
shopping_list.append(p_item) ##カートに追加
salary-=p_item[1] #それに応じて合計残高が減少します
print("Added %s into shopping cart,your current balance is \033[31;1m%s\033[0m"%(p_item, salary)) #購入した商品と残額を印刷する
else:print("\033[41;1mあなたのバランスは残っているだけです[%s]ラ、ウールを買う\033[0m"% salary) #残りの金額が現在の製品価格よりも少ないことを印刷します
else:print("product code [%s] is not exist!"% user_choice) #現在、製品のシリアル番号はありません
elif user_choice =='q': #脱落
print("--------shopping list------") #製品リストを印刷する
for p in shopping_list:print(p)print("Your current balance:", salary) #残りの金額を印刷する
exit()else:print("invalid option") #数ではない
2. 文字列操作
機能:変更できません
name.capitalize()最初の文字を大文字にする
name.casefold()すべて大文字から小文字
name.center(50,"-")出力'---------------------Alex Li----------------------'
name.count('lex')lexの発生をカウントします
name.encode()文字列をバイト形式にエンコードします
name.endswith("Li")文字列がLiで終わるかどうかを判断します
" Alex\tLi".expandtabs(10)出力'Alex Li'、ウィル\スペースtが変換される時間
name.find('A')Aを探す,見つかった場合はインデックスを返し、見つからなかった場合は返します-1
format :>>> msg ="my name is {}, and age is {}">>> msg.format("alex",22)'my name is alex, and age is 22'>>> msg ="my name is {1}, and age is {0}">>> msg.format("alex",22)'my name is 22, and age is alex'>>> msg ="my name is {name}, and age is {age}">>> msg.format(age=22,name="ale")'my name is ale, and age is 22'
format_map
>>> msg.format_map({'name':'alex','age':22})'my name is alex, and age is 22'
msg.index('a')文字列のインデックスを返します。
'9 aA'.isalnum() True
'9'. isdigit()整数ですか
name.isnumeric
name.isprintable
name.isspace
name.istitle
name.isupper
"|". join(['alex','jack','rain'])'alex|jack|rain'
maketrans
>>> intab ="aeiou" #This is the string having actual characters.>>> outtab ="12345" #This is the string having corresponding mapping character
>>> trantab = str.maketrans(intab, outtab)>>>>>> str ="this is string example....wow!!!">>> str.translate(trantab)'th3s 3s str3ng 2x1mpl2....w4w!!!'
msg.partition('is')出力('my name ','is',' {name}, and age is {age}')>>>"alex li, chinese name is lijie".replace("li","LI",1)'alex LI, chinese name is lijie'
msg.スワップケースケーススワップ
>>> msg.zfill(40)'00000my name is {name}, and age is {age}'>>> n4.ljust(40,"-")'Hello 2orld-----------------------------'>>> n4.rjust(40,"-")'-----------------------------Hello 2orld'>>> b="ddefdsdff_ハハ">>> b.isidentifier() #文字列をマーカーとして使用できるかどうか、つまり、文字列が変数の命名規則に準拠しているかどうかを確認します
True
3. 辞書操作###
ディクショナリはキーと値のデータタイプです。学校で使用したようなディクショナリを使用して、対応するページの詳細な内容をストロークと文字で確認できます。
文法:
info ={'stu1101':"TengLan Wu",'stu1102':"LongZe Luola",'stu1103':"XiaoZe Maliya",}
辞書の特徴:
- dictは順序付けられていません
- キーは一意である必要があるため、本質的に
増加する
>>> info["stu1104"]="葵ソラ">>> info
{' stu1102':'LongZe Luola','stu1104':'葵ソラ','stu1103':'XiaoZe Maliya','stu1101':'TengLan Wu'}
変更
>>> info['stu1101']="ムトラン">>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya','stu1101':'ムトラン'}
削除
>>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya','stu1101':'ムトラン'}>>> info.pop("stu1101") #標準の削除ポーズ
' ムトラン'>>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya'}>>> del info['stu1103'] #姿勢を変えて削除する
>>> info
{' stu1102':'LongZe Luola'}>>> info ={'stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya'}>>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya'} #ランダムに削除
>>> info.popitem()('stu1102','LongZe Luola')>>> info
{' stu1103':'XiaoZe Maliya'}
検索
>>> info ={'stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya'}>>>>>>"stu1102"in info #標準的な使用法
True
>>> info.get("stu1102") #入手します
' LongZe Luola'>>> info["stu1102"] #上記と同じですが、以下を参照してください
' LongZe Luola'>>> info["stu1105"] #キーが存在しない場合、エラーが報告され、getは報告されず、存在しない場合にのみNoneを返します。
Traceback(most recent call last):
File "<stdin>", line 1,in<module>
KeyError:'stu1105'
マルチレベルの辞書のネストと操作
av_catalog ={"ヨーロッパとアメリカ":{"www.youporn.com":["たくさん無料,世界最大","平均品質"],"www.pornhub.com":["たくさん無料,また大きい","yourpornよりも高品質"],"letmedothistoyou.com":["主にselfies,高品質の写真がたくさん","リソースが少ない,遅い更新"],"x-art.com":["高品質,本当に高い","すべての料金,バイパスしてください"]},"日本と韓国":{"tokyo-hot":["品質についてどれほど不明確か,个人已经不喜欢日本と韓国范了","有料だそうです"]},"本土":{"1024":["すべて無料,それはすばらしい,良い人は安全です","サーバーは海外にあります,スロー"]}}
av_catalog["本土"]["1024"][1]+=",クローラーで這うことができます"print(av_catalog["本土"]["1024"])
# ouput
[' すべて無料,それはすばらしい,良い人は安全です','サーバーは海外にあります,スロー,クローラーで這うことができます']
その他のポジション
# values
>>> info.values()dict_values(['LongZe Luola','XiaoZe Maliya'])
# keys
>>> info.keys()dict_keys(['stu1102','stu1103'])
# setdefault
>>> info.setdefault("stu1106","Alex")'Alex'>>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya','stu1106':'Alex'}>>> info.setdefault("stu1102","ロンゼロラ")'LongZe Luola'>>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya','stu1106':'Alex'}
# update
>>> info
{' stu1102':'LongZe Luola','stu1103':'XiaoZe Maliya','stu1106':'Alex'}>>> b ={1:2,3:4,"stu1102":"ロンゼロラ"}>>> info.update(b)>>> info
{' stu1102':'ロンゼロラ',1:2,3:4,'stu1103':'XiaoZe Maliya','stu1106':'Alex'}
# items
info.items()dict_items([('stu1102','ロンゼロラ'),(1,2),(3,4),('stu1103','XiaoZe Maliya'),('stu1106','Alex')])
# リストからデフォルトのdictを生成する,説明できない穴があります、これを少なく使ってください
>>> dict.fromkeys([1,2,3],'testd'){1:'testd',2:'testd',3:'testd'}
ループディクテーション
# キー入力情報の方法1:print(key,info[key])
# kの方法2,v in info.items(): #最初にdictをlistに変換します,データが大きい場合は使用しないでください
print(k,v)
プログラムの練習
プログラム:3レベルメニュー
請求:
- 州、市、郡の3レベルのメニューを印刷する
- 前のレベルに戻ることができます
- いつでもプログラムを終了できます
menu ={'北京':{'ハイディアン':{'ウダオコウ':{'soho':{},'NetEase':{},'google':{}},'中関村':{'IQIYI':{},'車の家':{},'youku':{},},'シャンディ':{'Baidu':{},},},'チャンピン':{'シャヘ':{'老人':{},'Beihang':{},},'Tiantongyuan':{},'ホイロングアン':{},},'チャオヤン':{},'東城':{},},'上海':{'ミンハン':{"人民広場":{'フライドチキンショップ':{}}},'Zhabei':{'列車戦争':{'Ctrip':{}}},'プドン':{},},'シャンドン':{},}
exit_flag = False
current_layer = menu
layers =[menu]while not exit_flag:for k in current_layer:print(k)
choice =input(">>:").strip()if choice =="b":
current_layer = layers[-1]
# print("change to laster", current_layer)
layers.pop()
elif choice not in current_layer:continueelse:
layers.append(current_layer)
current_layer = current_layer[choice]
3年間のメニュー文学青年版
4. 収集操作###
コレクションは、データの順序付けられていない非反復的な組み合わせであり、その主な機能は次のとおりです。
- 複製、リストをコレクションに変換すると、自動的に複製が解除されます
- 関係テスト、2つのデータセット間の交差、差異、結合、およびその他の関係をテストします
一般的な操作
s =set([3,5,9,10]) #値のセットを作成します
t =set("Hello") #ユニークなキャラクターのセットを作成する
a = t | s #tとsの和集合
b = t & s #tとsの交点
c = t – s #差分セット(アイテムはtにありますが、sにはありません)
d = t ^ s #対称差分セット(項目はtまたはsにありますが、両方には表示されません)
基本操作:
t.add('x') #1つ追加します
s.update([10,37,42]) #に複数のアイテムを追加します
削除を使用()1つのアイテムを削除できます:
t.remove('H')len(s)セットの長さ
x in s
xがsのメンバーであるかどうかをテストします
x not in s
xがsのメンバーでないかどうかをテストします
s.issubset(t)
s <= t
sのすべての要素がtにあるかどうかをテストします
s.issuperset(t)
s >= t
tのすべての要素がsにあるかどうかをテストします
s.union(t)
s | t
sとtのすべての要素を含む新しいセットを返します
s.intersection(t)
s & t
sとtの共通要素を含む新しいセットを返します
s.difference(t)
s - t
sには要素を含むが、tには含まない新しいセットを返す
s.symmetric_difference(t)
s ^ t
sとtで繰り返されない要素を含む新しいセットを返します
s.copy()
セット「s」の浅いコピーを返す
5. ファイル操作
ファイル操作プロセス
- ファイルを開き、ファイルハンドルを取得して、変数に割り当てます
- ハンドルを介してファイルを操作する
- ファイルを閉じる
既存の文書は次のとおりです
Somehow, it seems the love I knew was always the most destructive kind
どういうわけか、私が経験する愛は常に最も破壊的な種類です
Yesterday when I was young
私が若くて軽薄だった昨日
The taste of life was sweet
人生の味は甘い
As rain upon my tongue
舌先の雨のように
I teased at life asif it were a foolish game
私は愚かなゲームとして人生をからかう
The way the evening breeze
夜のそよ風のように
May tease the candle flame
ろうそくの炎をからかう
The thousand dreams I dreamed
私はそれについて何千回も夢見てきました
The splendid things I planned
私の計画のそれらの素晴らしい青写真
I always built to last on weak and shifting sand
しかし、私はいつも腐りやすいクイックサンドの上にそれを構築します
I lived by night and shunned the naked light of day
私は歌い、その日の裸の太陽から逃れるために歌います
And only now I see how the time ran away
年がどのように経過するかを見ることができるのは今だけです
Yesterday when I was young
私が若くて軽薄だった昨日
So many lovely songs were waiting to be sung
私が歌うのを待っている甘い歌がたくさんあります
So many wild pleasures lay in store for me
私が楽しむのを待っているたくさんの欲望の幸せがあります
And so much pain my eyes refused to see
私の目にはとても痛みがありますが、私は目をつぶっています
I ran so fast that time and youth at last ran out
私は速く走り、ついに時間と若さがなくなった
I never stopped to think what life was all about
私は人生の意味について考えるのをやめません
And every conversation that I can now recall
私が今覚えているすべての会話
Concerned itself with me and nothing else at all
私以外は何も思い出せない
The game of love I played with arrogance and pride
私は傲慢と傲慢でラブゲームをします
And every flame I lit too quickly, quickly died
私が点火したすべての炎はあまりにも速く消えました
The friends I made all somehow seemed to slip away
私が作った友達はみんな無意識のうちに去っているようだった
And only now I'm left alone to end the play, yeah
ステージでこのファースを終わらせるのは私だけです
Oh, yesterday when I was young
ああ昨日私が若くて軽薄だったとき
So many, many songs were waiting to be sung
私が歌うのを待っている甘い歌がたくさんあります
So many wild pleasures lay in store for me
私が楽しむのを待っているたくさんの欲望の幸せがあります
And so much pain my eyes refused to see
私の目にはとても痛みがありますが、私は目をつぶっています
There are so many songs in me that won't be sung
歌われることのない曲が多すぎます
I feel the bitter taste of tears upon my tongue
舌の涙の苦味を味わった
The time has come for me to pay for yesterday
いよいよ昨日の代金を支払う時が来ました
When I was young
私が若くて軽薄だったとき
基本操作
f =open('lyrics') #ファイルを開く
first_line = f.readline()print('first line:',first_line) #行を読む
print('私は仕切りです'.center(50,'-'))
data = f.read()#残っているものをすべて読む,ファイルが大きい場合は使用しないでください
print(data) #ドキュメントを印刷する
f.close() #ファイルを閉じる
ファイルを開くためのモードは次のとおりです。
- r、読み取り専用モード(デフォルト)。
- w、書き込み専用モード。 [判読不能;存在しない場合は作成、存在する場合はコンテンツを削除;]
- a、追加モード。 [読み取り可能;存在しない場合は作成;存在する場合はコンテンツのみを追加;]
"+" ファイルの読み取りと書き込みを同時に実行できることを示します
- r +は、ファイルの読み取りと書き込みができます。 [読み取り可能;書き込み可能;追加可能]
- w +、書き込みと読み取り
- a +、と同じ
" 「U」は、読み取るときに\ r \ n \ r \ nを自動的に\ nに変換できることを意味します(rまたはr +モードと同じ)
- rU
- r+U
" b "はバイナリファイルを処理することを意味します(例:ISOイメージファイルを送信およびアップロードするためのFTP、Linuxは無視できます、Windowsはバイナリファイルを処理するときにマークを付ける必要があります)
- rb
- wb
- ab
その他の構文
def close(self): # real signature unknown; restored from __doc__
"""
Close the file.
A closed file cannot be used for further I/O operations.close() may be
called more than once without error."""
pass
def fileno(self,*args,**kwargs): # real signature unknown
""" Return the underlying file descriptor (an integer). """
pass
def isatty(self,*args,**kwargs): # real signature unknown
""" True if the file is connected to a TTY device. """
pass
def read(self, size=-1): # known caseof _io.FileIO.read
"""
すべてを読むことができない場合があることに注意してください
Read at most size bytes, returned as bytes.
Only makes one system call, so less data may be returned than requested.
In non-blocking mode, returns None if no data is available.
Return an empty bytes object at EOF."""
return""
def readable(self,*args,**kwargs): # real signature unknown
""" True if file was opened in a read mode. """
pass
def readall(self,*args,**kwargs): # real signature unknown
"""
Read all data from the file, returned as bytes.
In non-blocking mode, returns as much as is immediately available,
or None if no data is available. Return an empty bytes object at EOF."""
pass
def readinto(self): # real signature unknown; restored from __doc__
""" Same as RawIOBase.readinto(). """
pass #使用しないでください,それが何のために使われるのか誰も知らない
def seek(self,*args,**kwargs): # real signature unknown
"""
Move to newfile position and return the file position.
Argument offset is a byte count. Optional argument whence defaults to
SEEK_SET or 0(offset from start of file, offset should be >=0); other values
are SEEK_CUR or 1(move relative to current position, positive or negative),
and SEEK_END or 2(move relative to end of file, usually negative, although
many platforms allow seeking beyond the end of a file).
Note that not all file objects are seekable."""
pass
def seekable(self,*args,**kwargs): # real signature unknown
""" True if file supports random-access. """
pass
def tell(self,*args,**kwargs): # real signature unknown
"""
Current file position.
Can raise OSError for non seekable files."""
pass
def truncate(self,*args,**kwargs): # real signature unknown
"""
Truncate the file to at most size bytes and return the truncated size.
Size defaults to the current file position,as returned by tell().
The current file position is changed to the value of size."""
pass
def writable(self,*args,**kwargs): # real signature unknown
""" True if file was opened in a write mode. """
pass
def write(self,*args,**kwargs): # real signature unknown
"""
Write bytes b to file,return number written.
Only makes one system call, so not all of the data may be written.
The number of bytes actually written is returned. In non-blocking mode,
returns None if the write would block."""
pass
ステートメント付き
ファイルを開いた後にファイルを閉じるのを忘れないようにするために、コンテキストを管理できます。
これは:
withopen('log','r')as f:...
このように、with codeブロックが実行されると、内部ファイルリソースは自動的に閉じられ、解放されます。
Python 2.7以降、複数のファイルのコンテキストを同時に管理することをサポートします。
withopen('log1')as obj1,open('log2')as obj2:
pass
プログラムの練習
プログラム1:単純なシェルsed置換機能を実装する
手順2:haproxy構成ファイルを変更する
要求する:
1、 小切手
入力:www.oldboy.org
現在のバックエンドですべてのレコードを取得します
2、 新着
入る:
arg ={'bakend':'www.oldboy.org','record':{'server':'100.1.7.9','weight':20,'maxconn':30}}3.削除
入る:
arg ={'bakend':'www.oldboy.org','record':{'server':'100.1.7.9','weight':20,'maxconn':30}}
要求する
global
log 127.0.0.1 local2
daemon
maxconn 256
log 127.0.0.1 local2 info
defaults
log global
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
option dontlognull
listen stats :8888
stats enable
stats uri /admin
stats auth admin:1234
frontend oldboy.org
bind 0.0.0.0:80
option httplog
option httpclose
option forwardfor
log global
acl www hdr_reg(host)-i www.oldboy.org
use_backend www.oldboy.org if www
backend www.oldboy.org
server 100.1.7.9100.1.7.9 weight 20 maxconn 3000
元の構成ファイル
6. 文字のエンコードとトランスコーディング###
詳細記事:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
知っておく必要があります:
- python2のデフォルトのエンコーディングはASCIIであり、python3のデフォルトはunicodeです
- Unicodeはutf-32(4バイトを占める)、utf-16(2バイトを占める)、utf-8(1〜4バイトを占める)に分けられるため、utf-16が最も一般的に使用されるユニコードバージョンです。ただし、utf8はスペースを節約するため、utf-8は引き続きファイルに保存されます。
- py3では、encodeはトランスコーディング中に文字列をバイトタイプに変更し、decodeはデコード中にバイトを文字列に戻します
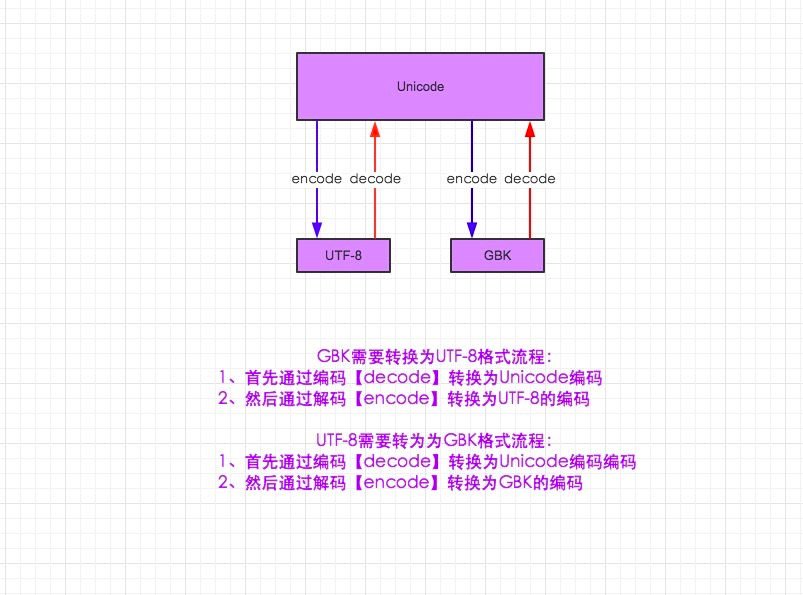
上の写真はpy2にのみ適用されます
#- *- coding:utf-8-*-
__ author__ ='Alex Li'import sys
print(sys.getdefaultencoding())
msg ="北京天南門広場が大好き"
msg_gb2312 = msg.decode("utf-8").encode("gb2312")
gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk")print(msg)print(msg_gb2312)print(gb2312_to_gbk)in python2
#- *- coding:gb2312 -*- #これも削除できます
__ author__ ='Alex Li'import sys
print(sys.getdefaultencoding())
msg ="北京天南門広場が大好き"
# msg_gb2312 = msg.decode("utf-8").encode("gb2312")
msg_gb2312 = msg.encode("gb2312") #デフォルトはユニコードです,デコードする必要はありません,スーパープラスお楽しみください
gb2312_to_unicode = msg_gb2312.decode("gb2312")
gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8")print(msg)print(msg_gb2312)print(gb2312_to_unicode)print(gb2312_to_utf8)in python3
- 内蔵機能
Recommended Posts