Ubuntu14.04パート2でPrometheusをクエリする方法
前書き ##
Prometheusは、オープンソースの監視システムおよび時系列データベースです。 Ubuntu 14.04パート1でPrometheusをクエリする方法では、3つのデモンストレーションサービスインスタンスを設定して、合成メトリックをPrometheusサーバーに公開します。これらの指標を使用して、Prometheusクエリ言語を使用して時系列を選択およびフィルタリングする方法、ディメンションを集計する方法、およびレートと導関数を計算する方法を学習しました。
このチュートリアルの第2部では、第1部から設定を作成し、より高度なクエリ手法とパターンを学習します。このチュートリアルの後、値ベースのフィルタリング、設定操作、ヒストグラムなどを適用する方法を学習します。
このチュートリアルを完了するには、 sudoコマンドを使用できる非rootアカウントを持つUbuntu ** server **が必要であり、ファイアウォールがオンになっています。サーバーをお持ちでない学生は、[こちら](https://cloud.tencent.com/product/cvm?from=10680)から購入できますが、個人的には、無料のTencent Cloud [Developer Lab](https://cloud.tencent.com/developer/labs?from=10680)を使用して実験し、[サーバーを購入]( https://cloud.tencent.com/product/cvm?from=10680)。
準備 ##
このチュートリアルは、Ubuntu14.04パート1のPrometheusで概説されている設定を照会する方法に基づいています。少なくとも、チュートリアルの手順1と2に従って、Prometheusサーバーと3つの監視対象のデモサービスインスタンスを設定する必要があります。ただし、前半で説明したクエリ言語技術も活用するので、十分に活用することをお勧めします。
ステップ1-値でフィルタリングし、しきい値を使用する
このセクションでは、返された時系列をその値に基づいてフィルタリングする方法を学習します。
値ベースのフィルタリングの最も一般的な使用法は、単純なデジタルアラームしきい値です。たとえば、合計 500ステータスリクエストレートが1秒あたり0.2を超える、過去15分間の平均であるHTTPパスを検索したい場合があります。これを行うには、すべての 500ステータス要求率を照会し、式の最後にフィルター演算子> 0.2を追加するだけです。
rate(demo_api_request_duration_seconds_count{status="500",job="demo"}[15m])>0.2
コンソールビューでは、結果は次のようになります。

ただし、バイナリアルゴリズムと同様に、Prometheusは単一のスカラー数によるフィルタリングをサポートするだけではありません。別のシリーズのセットに基づいて、時系列のセットをフィルタリングすることもできます。同様に、要素はタグのセットによって照合され、一致した要素間にフィルター演算子が適用されます。右側のおよびの要素と一致する左側の要素のみが、フィルターを通過して出力の一部になります。 on(<labels> ) 、group_left(<labels> )、group_right(<labels> )句は、ここでは算術演算子と同じように機能します。
たとえば、 job、 instance、 method、および pathの任意の組み合わせに対して 500ステータスレートを選択でき、 200ステータスレートは 500ステータスの少なくとも50倍以下です。このようなレート:
rate(demo_api_request_duration_seconds_count{status="500",job="demo"}[5m])*50>on(job, instance, method, path)rate(demo_api_request_duration_seconds_count{status="200",job="demo"}[5m])
これは次のようになります。
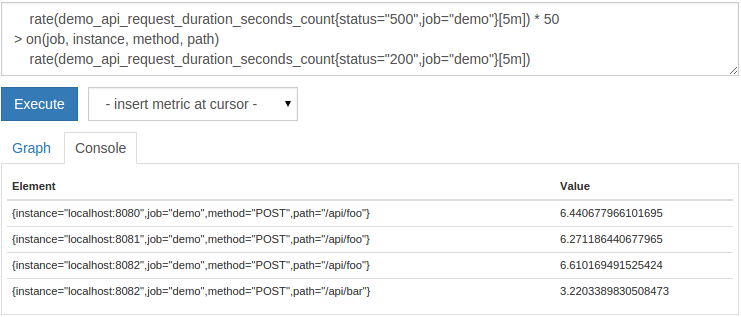
prometheusは、 >に加えて、フィルタリングの目的で、通常の > =、 <=、 <、 !=、および ==の比較演算子もサポートします。
これで、単一の値に基づいて、またはラベルが一致する別の時系列値のセットに基づいて、時系列のセットをフィルタリングする方法がわかりました。
ステップ2-セット演算子を使用する
このセクションでは、Prometheusのセット演算子を使用して時系列セットを相互に関連付ける方法を学習します。
通常、別のセットに基づいて時系列のセットをフィルタリングする必要があります。この目的のために、Prometheusは andセット演算子を提供します。オペレーターの左側にある各シリーズについて、右側に同じラベルが付いているシリーズを見つけようとします。一致するものが見つかった場合、左側のシリーズが出力の一部になります。右側に一致するシリーズがない場合、そのシリーズは出力から省略されます。
たとえば、90%の遅延が50ミリ秒(0.05秒)を超えるHTTPエンドポイントを選択できますが、1秒あたり複数の要求を受信するディメンションの組み合わせに制限されます。ここでは、 histogram_quantile()関数を使用してパーセンタイルを計算します。この機能の正確な役割については、次のセクションで説明します。現在、各サブディメンションの90パーセンタイル遅延のみを計算します。発生したエラー遅延をフィルタリングし、1秒あたりの複数の要求を受信する遅延のみを保持するために、次のクエリを実行できます。
histogram_quantile(0.9,rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m]))>0.05
and
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])>1
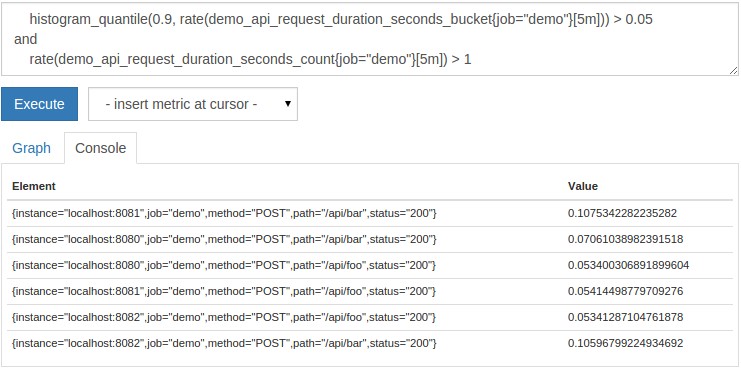
交差点を使用する代わりに、2セットの時系列から和集合を構築したい場合があります。 Prometheusは、この目的のためにセット演算子 またはを提供します。その結果、操作の左側のシリーズと、一致するラベルが設定されていない右側の左側のシリーズが発生します。たとえば、10未満または30を超えるすべてのリクエストレートを一覧表示するには、次のクエリを実行してください。
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])<10
or
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])>30
結果は次のようにグラフに表示されます。
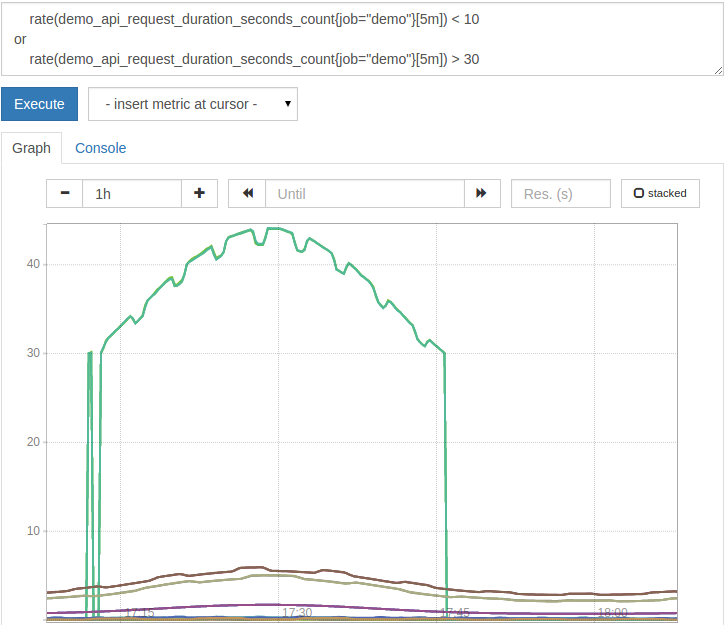
ご覧のとおり、チャートで値フィルターを使用してアクションを設定すると、チャートのタイムステップに一致するかどうかに応じて、同じチャートに時系列が表示されたり消えたりする可能性があります。一般に、アラートルールにはこのタイプのフィルターロジックのみを使用することをお勧めします。
これで、ラベル付き時系列を使用して交差点と和集合を構築する方法をマスターしました。
ステップ3-ヒストグラムを使用する
このセクションでは、ヒストグラムメトリックを解釈する方法と、それらからクォンタイル(パーセンタイルの一般的な形式)を計算する方法を学習します。
Prometheusはヒストグラムインジケーターをサポートしており、サービスが一連の値の分布を記録できるようにします。ヒストグラムは通常、要求の遅延や応答サイズなどの測定値を追跡しますが、基本的に、特定の分布に従って振幅が変動する任意の値を追跡できます。 Prometheusヒストグラムは、クライアント側でデータをサンプリングします。つまり、多くの構成可能な(遅延などの)ストレージ領域を使用して観測値を計算し、これらのバケットを個別の時系列として公開します。
内部的には、ヒストグラムは時系列のセットとして実装され、各時系列は特定のバケットの数を表します(たとえば、「10ミリ秒未満の要求」、「25ミリ秒未満の要求」、「50ミリ秒未満の要求」など)。バケットカウンターは累積的です。つまり、値の大きいバケットには、値の小さいすべてのバケットの数が含まれます。ヒストグラムの一部である各時系列で、対応するバケットは特別な「le」(以下)ラベルで示されます。これにより、追跡した既存のディメンションにディメンションが追加されます。
たとえば、デモサービスは、APIリクエスト期間の分布を追跡するヒストグラム demo_api_request_duration_seconds_bucketをエクスポートします。このヒストグラムは、追跡されたサブディメンションごとに26個のバケットを導出するため、このインジケーターには多数の時系列があります。まず、例からリクエストのタイプの元のヒストグラムを見てみましょう。
demo_api_request_duration_seconds_bucket{instance="localhost:8080",method="POST",path="/api/bar",status="200",job="demo"}
26のシリーズが表示されます。各シリーズは、ラベル「le」で識別される観測バケットを表します。

ヒストグラムは、「リクエストの完了に100ミリ秒以上かかるものはいくつありますか?」などの質問に答えるのに役立ちます。 (ヒストグラムが100ms境界のバケットで構成されている場合)。一方、「クエリ完了の99%の遅延はどれくらいですか?」などの関連する質問に答えたい場合がよくあります。ヒストグラムバケットが十分に細かい場合は、 histogram_quantile()関数を使用して計算できます。この関数は、入力としてヒストグラムメトリック( leバケットラベルを持つ一連のシリーズ)を必要とし、対応するクォンタイルを出力します。比較パーセンテージでは、その範囲は0〜100パーセンタイルです。つまり、ターゲット桁仕様の「histogram_quantile()」関数は、「0」〜「1」の入力範囲として期待します(つまり、90パーセンタイル)。クォンタイルはクォンタイル 0.9に対応します。
たとえば、次のように、すべてのディメンションの90%パーセントAPIレイテンシを計算してみることができます。
# BAD!histogram_quantile(0.9, demo_api_request_duration_seconds_bucket{job="demo"})
これはあまり有用でも信頼性もありません。単一のサービスインスタンスが再起動されると、バケットカウンターがリセットされます。通常、インジケーターの全時間ではなく、「現在」の遅延(たとえば、過去5分間に測定)を確認する必要があります。これは、基本的なヒストグラムバケットカウンターに rate()関数を適用することで実現できます。このカウンターは、カウンターリセットを処理し、指定された時間枠内の各バケットの増加率のみを考慮します。
次のように、過去5分間のAPIレイテンシの90%を計算します。
# GOOD!histogram_quantile(0.9,rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m]))
これははるかに優れており、次のようになります。

ただし、これは90パーセンタイル*のサブディメンション( job、 instance、 path、 method、および status)のそれぞれを考慮します。同様に、これらすべての次元に関心があるわけではなく、それらのいくつかをまとめたい場合もあります。幸い、Prometheusの sum集計演算子をhistogram_quantile()関数と組み合わせて、クエリ時間でディメンションを集計できます。
次のクエリは90パーセントの遅延を計算しますが、結果を job、 instance、および pathのサイズでのみ分割できます。
histogram_quantile(0.9,
sum without(status, method)(rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m])))
注: leは、histogram_quantile()関数を適用する前に、常にバケットラベルを集計に保持します。これにより、バケットグループを操作し、そこからクォンタイルを計算できるようになります。
この図は次のようになります。
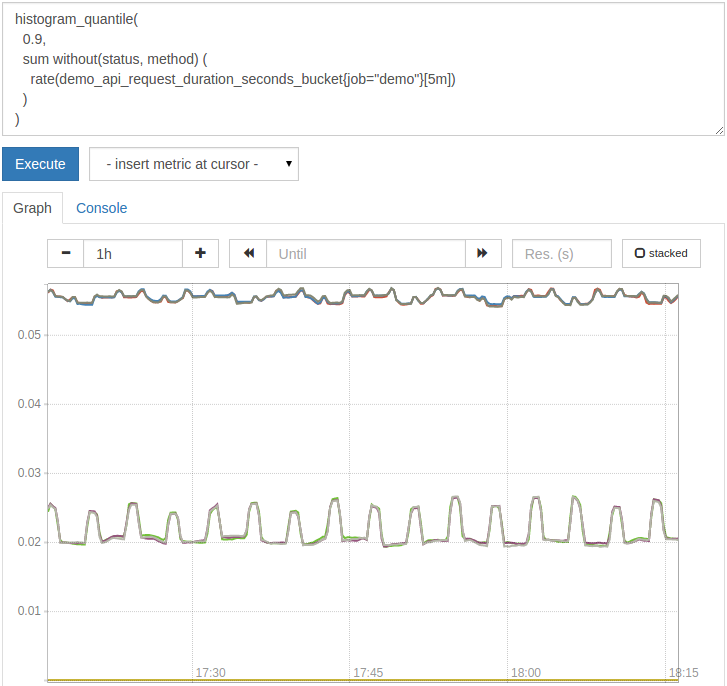
ヒストグラムからクォンタイルを計算すると、常に一定量の統計エラーが発生します。このエラーは、バケットサイズ、観測値の分布、および計算するターゲットクォンタイルによって異なります。
これで、ヒストグラムメジャーを解釈する方法と、さまざまな時間枠でそれらからクォンタイルを計算する方法を理解しました。また、特定のディメンションを動的に集計することもできます。
ステップ4-タイムスタンプインジケーターを使用する
このセクションでは、タイムスタンプを含むメトリックの使用方法を学習します。
プロメテウスエコシステムのコンポーネントは、多くの場合、タイムスタンプを公開します。たとえば、これは、バッチジョブが最後に正常に完了したとき、構成ファイルが最後に正常に再ロードされたとき、またはコンピューターが起動されたときなどです。慣例により、時間は1970年1月1日のUTC以降のUnixタイムスタンプ(秒単位)として表されます。
たとえば、デモサービスは、最後に成功したシミュレーションバッチジョブを公開します。
demo_batch_last_success_timestamp_seconds{job="demo"}
このバッチジョブは毎分実行されるようにシミュレートされましたが、すべての試行の25%で失敗しました。失敗した場合、 demo_batch_last_success_timestamp_secondsメトリックは、別の正常な実行が発生するまで最後の値を維持します。
元のタイムスタンプグラフを描画すると、次のようになります。
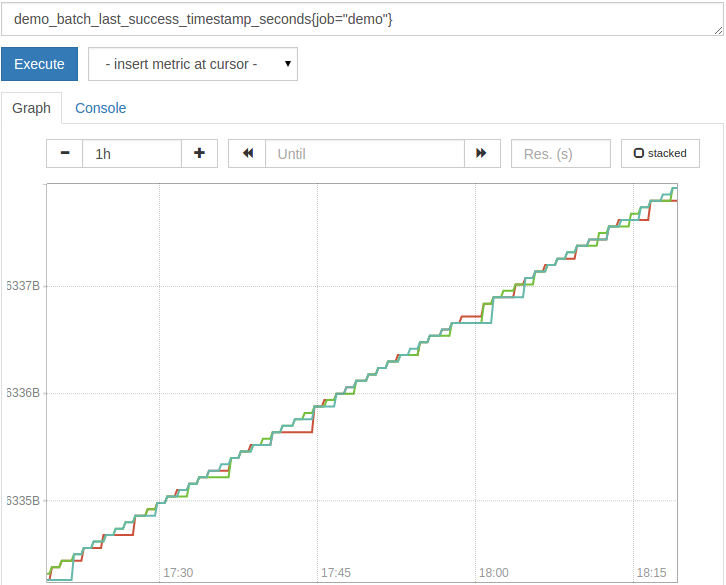
ご覧のとおり、元のタイムスタンプ値自体は通常あまり役に立ちません。代わりに、タイムスタンプ値の経過時間を知りたいことがよくあります。一般的なパターンは、 time()関数によって提供されるように、現在の時刻から測定のタイムスタンプを差し引くことです。
time()- demo_batch_last_success_timestamp_seconds{job="demo"}
これにより、バッチジョブが最後に正常に実行されてからの秒数が生成されます。

この年齢を秒から時間に変換する場合は、結果を「3600」で割ることができます。
( time()- demo_batch_last_success_timestamp_seconds{job="demo"})/3600
このような表現は、描画やアラートに役立ちます。上記のようにタイムスタンプの経過時間を視覚化すると、行が直線的に増加する鋸歯状のグラフが表示され、バッチジョブが正常に完了すると定期的に「0」にリセットされます。鋸歯状のスパイクが大きくなりすぎる場合は、バッチジョブが長時間完了していないことを意味します。 >式にしきい値フィルターを追加し、生成された時系列にアラートを出すことによってアラートを出すこともできます(ただし、このチュートリアルではアラートルールを紹介しません)。
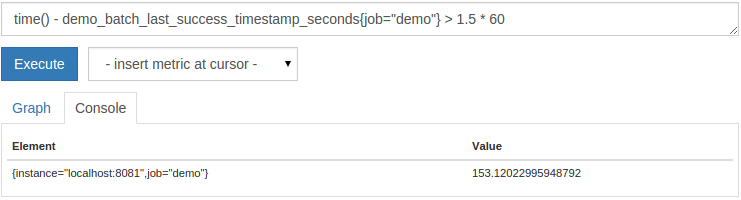
バッチジョブが過去1.5分間に完了しなかったインスタンスを単純に一覧表示するには、次のクエリを実行できます。
time()- demo_batch_last_success_timestamp_seconds{job="demo"}>1.5*60
これで、生のタイムスタンプメトリックを相対年齢に変換する方法がわかりました。これはグラフやアラートに役立ちます。
ステップ5-topk / bottomk関数を並べ替えて使用する
このステップでは、クエリ出力を並べ替える方法、または一連のシリーズの最大値または最小値のみを選択する方法を学習します。
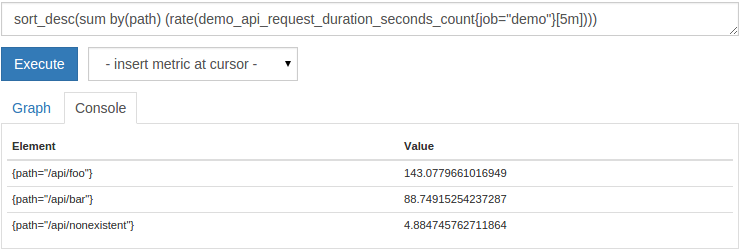
テーブルコンソールビューでは、出力系列を出力系列の値で並べ替えると便利なことがよくあります。これを実現するには、 sort()(昇順)関数と sort_desc()(降順)関数を使用できます。たとえば、値でソートされた各ルートの要求率を最高から最低まで表示するには、次のクエリを実行できます。
sort_desc(sum by(path)(rate(demo_api_request_duration_seconds_count{job="demo"}[5m])))
ソートされた出力は次のとおりです。
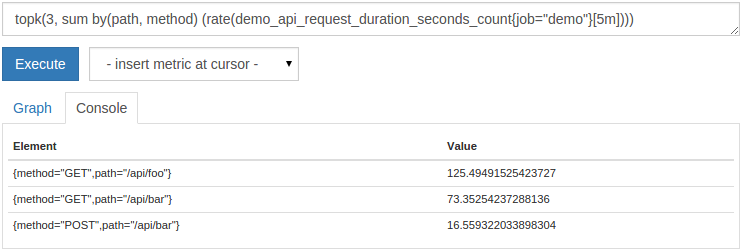
または、すべてのシリーズを表示するのではなく、Kが最大または最小のシリーズのみを表示することに関心がある場合があります。この目的のために、prometheusは topk()および bottomk()関数を提供します。それらはそれぞれ、K値(選択するシリーズの数)と任意の式を取り、フィルタリングする必要のある時系列のセットを返します。たとえば、各パスとメソッドの上位3つのリクエストレートのみを表示するには、次のクエリを実行できます。
topk(3, sum by(path, method)(rate(demo_api_request_duration_seconds_count{job="demo"}[5m])))
並べ替えはコンソールビューでのみ役立ちますが、 topk()と bottomk()はグラフでも役立ちます。出力には、グラフの時間範囲全体で平均化された上位または下位のK系列は表示されないことに注意してください。代わりに、出力は、チャートの各解像度ステップの上位または下位のK系列を再計算します。したがって、上部または下部のKシリーズは実際にはチャートの範囲内で変化する可能性があり、チャートには合計でKシリーズよりも多くが表示される場合があります。
これで、Kが最大または最小のシリーズのみを並べ替えまたは選択する方法を学習しました。
ステップ6-スクレイプされたインスタンスの状態を確認します
このステップでは、インスタンスのスクラッチヘルスを経時的にチェックする方法を学習します。
この部分をより面白くするために、3つのバックグラウンドデモサービスインスタンス(ポート8080でリッスン)の最初のインスタンスを終了しましょう。
pkill -f ---listen-address=:8080
プロメテウスがターゲットを引っ掻くときはいつでも、メトリック名と「ジョブ」と「インスタンス」で削り取られたインスタンスのラベルを含む複合サンプル「up」を保存します。スクレーピングが成功した場合は、サンプルの値を「1」に設定します。スクラッチが失敗した場合は、「0」に設定してください。したがって、現在の「上」または「下」のインスタンスを簡単に照会できます。
up{job="demo"}
これで、インスタンスがダウンとして表示されます。
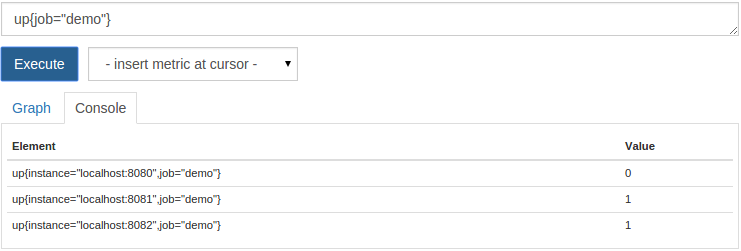
インスタンスをのみ表示するには、値 0をフィルタリングできます。
up{job="demo"}==0
これで、終了したインスタンスのみが表示されます。

または、閉じたインスタンスの総数を取得するには、次のようにします。
count by(job)(up{job="demo"}==0)
これにより、「1」が表示されます。

これらのタイプのクエリは、基本的なスクラッチヘルスアラートに役立ちます。
注:インスタンスが閉じられていない場合、このクエリは、カウントが「0」の単一の出力系列ではなく、空の結果を返します。これは、 count()集計演算子が入力として次元の時系列のセットを必要とし、出力シーケンスが byまたは without句に従ってグループ化できるためです。どの出力グループも、既存の入力系列にのみ基づくことができます。入力系列がまったくない場合、出力は生成されません。
これで、インスタンスのヘルスステータスを照会する方法がわかりました。
結論として ##
このチュートリアルでは、Ubuntu 14.04 Part 1でPrometheusの進行状況を照会する方法を構築し、より高度な照会手法とパターンを紹介しました。シリーズの値に基づいてシリーズをフィルタリングする方法、ヒストグラムからクォンタイルを計算する方法、タイムスタンプベースのインジケーターを処理する方法などを学びました。
これらのチュートリアルでは、考えられるすべてのクエリの使用例を網羅できるわけではありませんが、Prometheusを使用して実際のクエリ、ダッシュボード、アラートを作成するときに、サンプルクエリが役立つことを願っています。
Prometheus関連のチュートリアルのクエリの詳細については、[Tencent Cloud + Community](https://cloud.tencent.com/developer?from=10680)にアクセスして詳細を確認してください。
参照:「Ubuntu14.04パート2でPrometheusを照会する方法」
Recommended Posts