Ubuntu14.04にMemSQLをインストールする方法
前書き ##
MemSQLは、従来のデータベースよりも高速な読み取りおよび書き込み操作を提供できるメモリデータベースです。新技術でも【MySQL】(https://cloud.tencent.com/product/cdb?from=10680)プロトコルと書いてありますので、なじみのある使い方です。
MemSQLは、JSONサポートやデータ挿入機能など、MySQLの最新の最新機能を採用しています。 MySQLに対するMemSQLの最大の利点の1つは、大規模並列処理と呼ばれる単一のクエリを複数のノードに分割して、より高速な読み取りクエリを実現できることです。
このチュートリアルでは、単一のUbuntu 14.04サーバーにMemSQLをインストールし、パフォーマンスベンチマークを実行し、コマンドラインのMySQLクライアントを介してJSONデータを挿入します。
前提条件
このチュートリアルに従うには、次のものが必要です。
-
Ubuntu 14.04 x64 Tencent [CVM](https://cloud.tencent.com/product/cvm?from=10680)、少なくとも8 GB RAM、サーバーを持たない学生は[here](https://cloud.tencent.com/product/cvm?from=10680)から購入できますが、個人的には無料のTencent Cloud [開発者実験]を使用することをお勧めします部屋](https://cloud.tencent.com/developer/labs?from=10680)をテストし、インストールを学び、[サーバーを購入](https://cloud.tencent.com/product/cvm?from=10680)します。
-
sudo権限を持つ非rootユーザー。
ステップ1-MemSQLをインストールする
このセクションでは、MemSQLインストール用の作業環境を準備します。
MemSQLの最新バージョンは、[ダウンロードページ](http://www.memsql.com/download/)にリストされています。 MemSQLを正しく実行するためのサーバーのダウンロードと準備を管理するプログラムであるMemSQLOpsをダウンロードしてインストールします。執筆時点では、MemSQLOpsの最新バージョンは4.0.35です。
まず、MemSQLインストールパッケージファイルをWebサイトからダウンロードします。
wget http://download.memsql.com/memsql-ops-4.0.35/memsql-ops-4.0.35.tar.gz
次に、パッケージを抽出します。
tar -xzf memsql-ops-4.0.35.tar.gz
抽出パッケージは、 memsql-ops-4.0.35という名前のフォルダーを作成しました。フォルダ名にはバージョン番号が付いているので、ダウンロードしたバージョンがこのチュートリアルで指定したバージョンよりも小さい場合は、ダウンロードしたバージョンを含むフォルダになります。
ディレクトリをこのフォルダに変更します。
cd memsql-ops-4.0.35
次に、先ほど抽出したインストールパッケージの一部であるインストールスクリプトを実行します。
sudo ./install.sh
スクリプトからの出力が表示されます。しばらくすると、このホストにMemSQLのみをインストールするかどうかを尋ねられます。今後のチュートリアルでは、複数のマシンにMemSQLをインストールする方法を紹介します。したがって、このチュートリアルの目的のために、肯定的に** y to **と入力してみましょう。
...
Do you want to install MemSQL on this host only?[y/N] y
2015- 09- 0414:30:38: Jd0af3b [INFO] Deploying MemSQL to 45.55.146.81:33062015-09-0414:30:38: J4e047f [INFO] Deploying MemSQL to 45.55.146.81:33072015-09-0414:30:48: J4e047f [INFO] Downloading MemSQL:100.00%2015-09-0414:30:48: J4e047f [INFO] Installing MemSQL
2015- 09- 0414:30:49: Jd0af3b [INFO] Downloading MemSQL:100.00%2015-09-0414:30:49: Jd0af3b [INFO] Installing MemSQL
2015- 09- 0414:31:01: J4e047f [INFO] Finishing MemSQL Install
2015- 09- 0414:31:03: Jd0af3b [INFO] Finishing MemSQL Install
Waiting for MemSQL to start...
これで、MemSQLクラスターがUbuntuサーバーにデプロイされました。ただし、上記のログから、MemSQLが2回インストールされていることがわかります。
MemSQLは、アグリゲーターノードとリーフノードの2つの異なる役割として実行できます。以前にMemSQLをインストールする理由は、クラスターを実行するために少なくとも1つのアグリゲーターノードと少なくとも1つのリーフノードが必要なためです。
アグリゲーターはインターフェースMemSQLです。外の世界から見ると、MySQLによく似ています。同じポートでリッスンし、MySQLおよび標準のMySQLライブラリと通信することを期待するツールを接続できます。アグリゲーターの仕事は、すべてのMemSQLリーフノードを理解し、MySQLクライアントを処理し、そのクエリをMemSQLに変換することです。
リーフノード実際に保存されたデータ。リーフノードは、アグリゲーターノードからデータの読み取りまたは書き込みの要求を受信すると、クエリを実行し、結果をアグリゲーターノードに返します。 MemSQLを使用すると、複数のホスト間でデータを共有できます。各リーフノードにはデータの一部があります。 (単一のリーフノードを使用している場合でも、データはそのリーフノード内で分割されます。)
複数のリーフノードがある場合、アグリゲーターはMySQLクエリをクエリに関与する必要のあるすべてのリーフノードに変換する役割を果たします。次に、すべてのリーフノードから応答を受信し、結果をクエリに集約して、MySQLクライアントに返します。これは、並列クエリを管理する方法です。
シングルホストセットアップでは、同じマシンでアグリゲーターノードとリーフノードを実行しますが、他の多くのマシンでリーフノードを追加できます。
ステップ2-ベンチマークを実行する
MemSQLインストールスクリプトの一部としてインストールされるMemSQLOpsツールを使用して、MemSQLをすばやく実行する方法を見てみましょう。
Webブラウザーで、「http:// your_server_ip:9000」にアクセスします
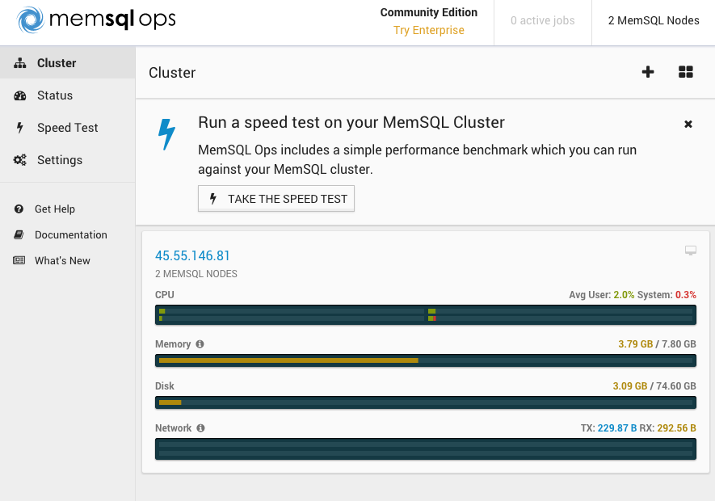
MemSQL Opsツールは、クラスターの概要を提供します。メインアグリゲーターノードとリーフノードの2つのMemSQLノードがあります。
スタンドアロンのMemSQLノードで速度テストを実行してみましょう。左側のメニューで[** Speed Test **]をクリックし、[START TEST **]をクリックします。以下は、表示される可能性のある結果の例です。
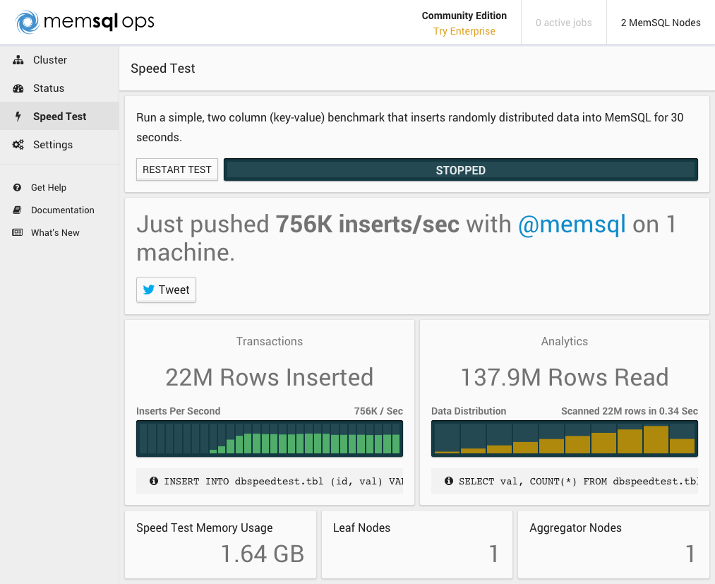
このチュートリアルでは、複数のサーバーにMemSQLをインストールする方法については説明しませんが、比較のために、3つの8GB Ubuntu 14.04ノード(1つのアグリゲーターノードと2つのリーフノード)を備えたMemSQLクラスターのベンチマークテストを示します。

リーフノードの数を2倍にすることで、挿入率をほぼ2倍にすることができます。 行の読み取りセクションを見ると、3ノードのクラスターが同時に単一ノードのクラスターよりも12M多い行を同時に読み取ることができることがわかります。
**ステップ3-mysql-client **を介してMemSQLと対話する##
クライアントにとって、MemSQLはMySQLのように見えます。それらはすべて同じプロトコルを持っています。 MemSQLクラスターとの通信を開始するために、最初にmysql-clientをインストールしましょう。
まず、aptを更新して、次のステップで最新のクライアントをインストールできるようにします。
sudo apt-get update
次に、MySQLクライアントをインストールします。これにより、 mysql実行コマンドが得られます。
sudo apt-get install mysql-client-core-5.6
これで、MySQLクライアントを使用してMemSQLに接続する準備が整いました。 ** root **ユーザーとしてポート3306でホスト 127.0.0.1に接続します(これはローカルホストのIPアドレスです)。また、プロンプトメッセージを memsql>にカスタマイズします。
mysql -u root -h 127.0.0.1-P 3306--prompt="memsql> "
数行の出力の後に、 memsql>プロンプトが表示されます。
データベースを一覧表示します。
show databases;
この出力が表示されます。
+- - - - - - - - - - - - - - - - - - - - +| Database |+--------------------+| information_schema || memsql || sharding |+--------------------+3 rows inset(0.01 sec)
** tutorial **という名前の新しいデータベースを作成します。
create database tutorial;
次に、 useコマンドを使用して、新しいデータベースの使用に切り替えます。
use tutorial;
次に、 idフィールドと emailフィールドを持つ usersテーブルを作成します。これら2つのフィールドにタイプを指定する必要があります。 idをbigintに設定し、長さ255のvarcharを電子メールで送信しましょう。また、 idフィールドがプライマリキーであり、 emailフィールドを空にすることはできないことをデータベースに通知します。
create table users(id bigint auto_increment primary key, email varchar(255) not null);
最後のコマンドの実行時間が非常に短い(15〜20秒)ことに気付くかもしれません。 MemSQLがこの新しいテーブルを作成する速度の主な理由が1つあります。それは、コードの生成です。
内部的には、MemSQLはコード生成を使用してクエリを実行します。つまり、新しいタイプのクエリが検出されるたびに、MemSQLはクエリを表すコードを生成してコンパイルする必要があります。次に、このコードをクラスターに送信して実行します。これにより、実際のデータの処理は高速化されますが、準備コストが高くなります。 MemSQLは、事前に生成されたクエリを再利用するために最善を尽くしますが、構造を見たことがない新しいクエリは遅くなります。
ユーザーテーブルに戻り、テーブル定義を確認します。
describe users;
+- - - - - - - +- - - - - - - - - - - - - - +- - - - - - +- - - - - - +- - - - - - - - - +- - - - - - - - - - - - - - - - +| Field | Type | Null | Key | Default | Extra |+-------+--------------+------+------+---------+----------------+| id |bigint(20)| NO | PRI | NULL | auto_increment || email |varchar(255)| NO || NULL ||+-------+--------------+------+------+---------+----------------+2 rows inset(0.00 sec)
それでは、usersテーブルにいくつかのサンプルメールを挿入しましょう。この構文は、MySQLデータベースに使用するものと同じです。
insert into users(email)values('[email protected]'),('[email protected]'),('[email protected]');
Query OK,3 rows affected(1.57 sec)
Records:3 Duplicates:0 Warnings:0
次に、usersテーブルをクエリします。
select *from users;
入力したデータを確認できます。
+- - - - +- - - - - - - - - - - - - - - - - - - +| id | email |+----+-------------------+|2| [email protected] ||1| [email protected] ||3| [email protected] |+----+-------------------+3 rows inset(0.07 sec)
**ステップ4-JSON ** ##を挿入してクエリする
MemSQLはJSONタイプを提供するため、このステップでは、着信イベントを使用するためのイベントテーブルを作成します。テーブルには、(ユーザーの場合と同じように) idフィールドとJSONタイプの eventフィールドが含まれます。
create table events(id bigint auto_increment primary key, event json not null);
いくつかのイベントを挿入しましょう。 JSONでは、「email」フィールドを参照します。このフィールドは、手順3で挿入したユーザーIDを参照します。
insert into events(event)values('{"name": "sent email", "email": "[email protected]"}'),('{"name": "received email", "email": "[email protected]"}');
これで、挿入したばかりのイベントを確認できます。
select *from events;
+- - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | event |+----+-----------------------------------------------------+|2|{"email":"[email protected]","name":"received email"}||1|{"email":"[email protected]","name":"sent email"}|+----+-----------------------------------------------------+2 rows inset(3.46 sec)
次に、JSONの name属性がテキスト" emailreceived "であるすべてのイベントをクエリできます。
select *from events where event::$name ='received email';
+- - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | event |+----+-----------------------------------------------------+|2|{"email":"[email protected]","name":"received email"}|+----+-----------------------------------------------------+1 row inset(5.84 sec)
クエリを変更して、 name属性に「emailsent」というテキストが含まれるクエリを見つけてください。
select *from events where event::$name ='sent email';
+- - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | event |+----+-------------------------------------------------+|1|{"email":"[email protected]","name":"sent email"}|+----+-------------------------------------------------+1 row inset(0.00 sec)
この最新のクエリは、前のクエリよりもはるかに高速に実行されます。これは、クエリのパラメータのみを変更したため、MemSQLはコード生成をスキップできるためです。
分散SQLデータベースに対していくつかの高度な操作を実行しましょう:非プライマリキーで2つのテーブルを結合しましょう。結合値の1つはJSON値にネストされていますが、異なるJSON値はフィルタリングされています。
まず、メールをイベント名「受信メール」と照合して、ユーザーテーブルのすべてのフィールドをイベントテーブルに追加するように要求します。
select *from users left join events on users.email = events.event::$email where events.event::$name ='received email';
+- - - - +- - - - - - - - - - - - - - - - - +- - - - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | email | id | event |+----+-----------------+------+-----------------------------------------------------+|2| [email protected] |2|{"email":"[email protected]","name":"received email"}|+----+-----------------+------+-----------------------------------------------------+1 row inset(14.19 sec)
次に、同じクエリを試しますが、「送信された電子メール」イベントにのみフィルタリングします。
select *from users left join events on users.email = events.event::$email where events.event::$name ='sent email';
+- - - - +- - - - - - - - - - - - - - - - - +- - - - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | email | id | event |+----+-----------------+------+-------------------------------------------------+|1| [email protected] |1|{"email":"[email protected]","name":"sent email"}|+----+-----------------+------+-------------------------------------------------+1 row inset(0.01 sec)
前と同じように、2番目のクエリは最初のクエリよりもはるかに高速です。ベンチマークテストで見たように、数百万行を実行すると、コード生成のメリットが実を結びました。 JSONを理解する水平方向にスケーラブルなSQLデータベースを使用する柔軟性と、テーブル間を任意に接続する方法は、強力なユーザー機能です。
結論として ##
MemSQLをインストールし、ノードパフォーマンスのベンチマークテストを実行し、標準のMySQLクライアントを介してノードと対話し、MySQLでは利用できないいくつかの高度な機能を使用しました。これにより、メモリ内のSQLデータベースで何ができるかがわかります。
MemSQLが実際にデータを分散する方法、最適なパフォーマンスのためにテーブルを構築する方法、複数のノード間でMemSQLをスケーリングする方法、高可用性のためにデータを複製する方法、およびMemSQLを保護する方法を理解する方法はまだたくさんあります。
その他のUbuntuチュートリアルについては、[Tencent Cloud + Community](https://cloud.tencent.com/developer?from=10680)にアクセスして詳細を確認してください。
参照:「Ubuntu14.04にMemSQLをインストールする方法」
Recommended Posts