PythonによるWebスクレイピング
私も英語を学ぶ必要があるので、私は最近この本を読んでいます、それでそれを翻訳しましょう:
まず、この本はPython 3.Xに関するもので、主にBeautifulSoupについて説明しています。
第3章、クロールを開始する
前の本で言及された例は、静的な単一のWebページ(以前に作成したWebページのように)のデータをクロールするには十分すぎるほどです。この章では、複数のページまたは複数のサイトを含む実際のWebページのクロールを開始します。
クローラーは、Webページ間でデータをクロールできるため、クローラーと呼ばれます。これらのユニットは、いくつかの循環ユニットです。これらのユニットは、Webサイト(URL)からページをダウンロードし、このWebページから別のWebサイトを見つけて、続行します。 Webページなどをダウンロードします。
ネットワーク全体をクロールすることはできますが、毎回それほど多くの作業を必要としないことは確かです。前の本の例は静的な単一のWebページで非常にうまく実行できるため、クローラーを作成するときにクローラーをより効率的に機能させる方法を慎重に検討する必要があります。
(逐語的に翻訳するのはとても疲れます。後で一般的な考え方をめくってみましょう^。^)
- まず、ドメイン内のデータをクロールする方法を紹介します。
この本は「ウィキペディアの6度」と「ケビン・ベーコンの6度」のゲームの例を示しています。トーンを見ると、これは非常に有名なようです。それが何であるかはわかりません。誰がそれについて教えてくれますか。大まかな意味は、ウィキペディアの任意の2つのエントリを6つ以内の単語で接続できることです。
その後、本の中で例を挙げましたが、無知で許して、名前がわからないのです。
これ以上言うのは無意味です。コードに移動して、このゲームをプレイするには、まずWebページでリンクを見つけることを学ぶ必要があります。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a"):
if 'href' in link.attrs:
print(link.attrs['href'])
findAllパラメータが「a」である理由は、Webページをクリックしてソースコードを表示した後、エントリへのリンクがこの構造に含まれていることがわかるためです(おそらくそうあるべきです)
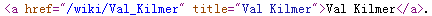
ただし、BeautifulSoupのlink.attrsは辞書タイプです。link.attrs['href']を使用して、リンクアドレスの値であるhrefを呼び出すことができます。
今日はこれですべてです。書いた途端に理解できなかったことがわかりました。
Recommended Posts