python操作kafka
Kafkaは、Apache Software Foundationによって開発され、ScalaとJavaで記述されたオープンソースのストリーム処理プラットフォームです。 Kafkaは、Webサイト内の消費者のすべてのアクションフローデータを処理できる、高スループットの分散型発行およびサブスクライブメッセージングシステムです。このようなアクション(Webブラウジング、検索、およびその他のユーザーアクション)は、現代のWebの多くのソーシャル機能における重要な要素です。これらのデータは通常、スループット要件のため、ログの処理とログの集約によって解決されます。ログデータおよびHadoopのようなオフライン分析システムの場合、リアルタイム処理の制限が必要ですが、これは実行可能なソリューションです。
Kafkaの単一マシンのスループットは100,000です。トピックが数十から数百になると、スループットが大幅に低下します。同じマシンで、Kafkaはトピックの数が多すぎないようにします。大規模なトピックをサポートする場合は、増やす必要があります。より多くのマシンリソース。
Kafkaのアーキテクチャの最も基本的な理解の1つ:複数のブローカーで構成され、各ブローカーはノードです。トピックを作成します。このトピックは複数のパーティションに分割でき、各パーティションは異なるブローカーに存在でき、各パーティションはデータの一部を入れてください。これは自然分散[メッセージキュー](https://cloud.tencent.com/product/cmq?from=10680)です。つまり、トピックのデータは複数のマシンに分散され、各マシンはデータの一部を配置します。
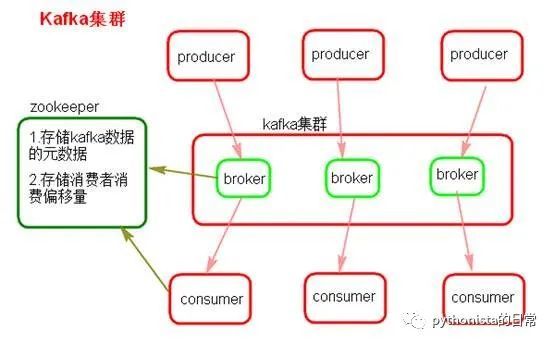
Kafka 0.8以降、レプリカメカニズムであるHAメカニズムが提供されます。各パーティションのデータは他のマシンと同期され、独自の複数のレプリカコピーを形成します。すべてのレプリカがリーダーを選出し、次に生産と消費がこのリーダーを扱い、他のレプリカがフォロワーになります。書き込むときは、リーダーがすべてのフォロワーにデータを同期する責任があります。読み取るときは、リーダーのデータを直接読み取るだけです。リーダーの読み取りと書き込みのみが可能ですか?非常にシンプルです。各フォロワーを自由に読み書きできる場合は、データの整合性の問題に注意する必要があります。システムの複雑さが高すぎて、問題が発生しやすくなります。 Kafkaは、障害耐性を向上させるために、パーティションのすべてのレプリカを異なるマシンに均等に分散します。
このように、いわゆる高可用性があります。ブローカーがダウンしても問題はなく、そのブローカーのパーティションは他のマシンにコピーを持っているからです。ダウンブローカーに特定のパーティションのリーダーがいる場合、この時点でフォロワーから新しいリーダーが再選出され、誰もがその新しいリーダーの読み取りと書き込みを続行できます。これは、いわゆる高可用性です。
データを書き込むとき、プロデューサーはリーダーに書き込み、次にリーダーはローカルディスクにデータを書き込み、次に他のフォロワーが主導権を握ってリーダーからデータをプルします。すべてのフォロワーがデータを同期すると、リーダーにackが送信され、リーダーがすべてのフォロワーからackを受信すると、正常な書き込みメッセージがプロデューサーに返されます。 (もちろん、これはモードの1つにすぎず、この動作は適切に調整できます)消費する場合、リーダーからのみ読み取られますが、すべてのフォロワーによってメッセージが正常にackに戻された場合にのみ、メッセージは次のようになります。消費者は読む。
kafka-pythonを使用して、プロジェクトでkafkaを操作します
- トピックを作成する
from kafka.admin import KafkaAdminClient, NewTopic
# カフカクラスター情報
bootstrap_servers ='127.0.0.1:9092'
# トピック名
jrtt_topic_name ="T100117_jrtt_grade_advertiser_public_info"
admin_client =KafkaAdminClient(bootstrap_servers=bootstrap_servers, client_id='T100117_gdt_grade_advertiser_get')
topic_list =[]
# 6 パーティション、2コピー
topic_list.append(NewTopic(name=jrtt_topic_name, num_partitions=6, replication_factor=2))
res = admin_client.create_topics(new_topics=topic_list, validate_only=False)
- kafkaのすべてのトピックを表示
from kafka import KafkaProducer, KafkaConsumer
# カフカクラスター情報
bootstrap_servers ='127.0.0.1:9092'
consumer =KafkaConsumer(bootstrap_servers=bootstrap_servers,)
all_topic = consumer.topics()print(all_topic)
- カフカプロデューサーコード
from kafka import KafkaClient, KafkaProducer
# カフカクラスター情報
bootstrap_servers ='127.0.0.1:9092'
jrtt_value ={"dev_app_type":2,"date":"20201111","agent_id":"1648892709542919","tenant_alias":"T100117","data":{"first_industry_name":"\\u6559\\u80b2\\u57f9\\u8bad","second_industry_name":"\\u4e2d\\u5c0f\\u5b66\\u6559\\u80b2","company":"\\u7f51\\u6613\\u6709\\u9053\\u4fe1\\u606f\\u6280\\u672f\\uff08\\u5317\\u4eac\\uff09\\u6709\\u9650\\u516c\\u53f8\\u676d\\u5dde\\u5206\\u516c\\u53f8","id":1683030511810573,"name":"ZS-\\u7f51\\u6613\\u4e50\\u8bfb-001"},"timestamp": time.time()}
producer =KafkaProducer(bootstrap_servers=bootstrap_servers,value_serializer=lambda v: json.dumps(v).encode('utf-8'))
# json形式のJrtt_値はKafkaに送信されます
producer.send(topic_name, value=jrtt_value)
- カフカ消費者
from kafka import KafkaProducer, KafkaConsumer
bootstrap_servers ='127.0.0.1:9092'
# トピックのプロデューサーによって生成されたメッセージコンテンツを受信します
consumer =KafkaConsumer(topic_name, bootstrap_servers=bootstrap_servers,)for index, msg inenumerate(consumer):
#
print("%s:%d:%d: key=%s value=%s"%(msg.topic, msg.partition, msg.offset, msg.key, msg.value))
Recommended Posts