word2vec操作のPython予備実装
I.はじめに
最初、word2vec環境のインストールは非常に複雑であり、Cygwinは長い間インストールした後、それを理解していませんでした。すると突然、C言語バージョンを使用する必要があるのはなぜですか?pythonバージョンを使用する必要があり、次にgensimを見つけました。gensimパッケージをインストールすることでword2vecを使用できますが、gensimはword2vecのスキップインのみを実装します。グラムモデル。他のモデルを使用したい場合は、他の言語でword2vecを学習する必要があります。
2.コーパスの準備
gensimパッケージを入手した後、txtファイルを直接渡すオンラインチュートリアルをたくさん読みましたが、txtファイルの外観とデータ形式の種類、多くのブログでは説明も、ダウンロード可能なtxtファイルも提供されていません。例として。さらに理解した結果、このtxtは多くのテキストを含む十分に分割されたファイルであることがわかりました。下の図に示すように、自分でトレーニングしたコーパスです。以前にクローラーでクロールした7000のニュースをコーパスとして選択し、単語のセグメンテーションを実行しました。単語の間にスペースを使用する必要があることに注意してください。
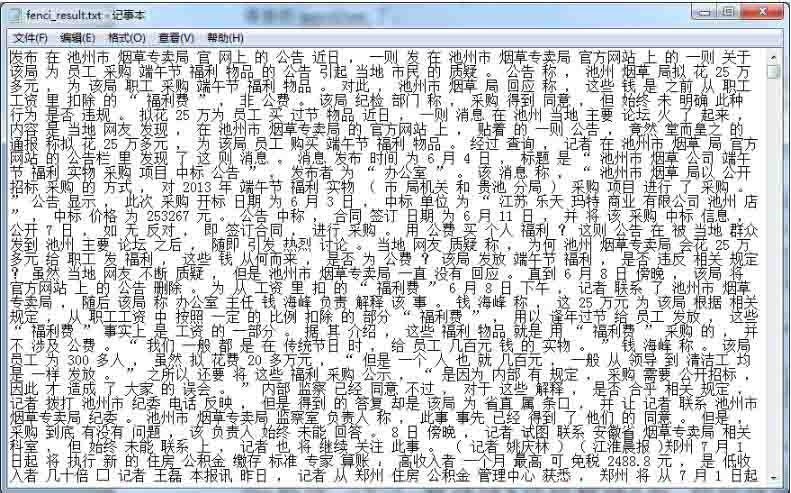
ここでは、参加者はどもる参加者を使用します。
コードのこの部分は次のとおりです。
import jieba
f1 =open("fenci.txt")
f2 =open("fenci_result.txt",'a')
lines =f1.readlines() #すべて読む
for line in lines:
line.replace('\t','').replace('\n','').replace(' ','')
seg_list = jieba.cut(line, cut_all=False)
f2.write(" ".join(seg_list))
f1.close()
f2.close()
コーパスにはもっと多くのテキストが必要であることに注意してください。インターネット上のコーパスには複数のGがあり、最初はニュースをコーパスとして使用しました。結果は非常に悪く、出力はすべて0です。次に、7000のニュースをコーパスとして使用し、単語のセグメンテーション後に取得したfenci_result.txtは2,000万でした。大きくはありませんが、予備的な結果を得ることができます。
3つ目は、gensimのword2vecトレーニングモデルを使用する
関連するコードは次のとおりです。
from gensim.modelsimport word2vec
import logging
# メインプログラム
logging.basicConfig(format='%(asctime)s:%(levelname)s: %(message)s', level=logging.INFO)
sentences =word2vec.Text8Corpus(u"fenci_result.txt") #コーパスをロード
model =word2vec.Word2Vec(sentences, size=200) #トレーニングスキップ-グラムモデル、デフォルトウィンドウ=5
print model
# 2つの単語の類似性を計算する/関連性
try:
y1 = model.similarity(u"国", u"国務院")
except KeyError:
y1 =0
print u"[国]と[州議会]の類似点は次のとおりです。", y1
print"-----\n"
#
# 単語の関連する単語リストを計算する
y2 = model.most_similar(u"タバコ管理", topn=20) #最も関連性の高い20
print u"[タバコ管理]に最も関連する言葉は次のとおりです。\n"for item in y2:
print item[0], item[1]
print"-----\n"
# 通信を見つける
print u"本-良品質-"
y3 =model.most_similar([u'品質', u'悪くない'],[u'本'], topn=3)for item in y3:
print item[0], item[1]
print"----\n"
# グループ外の単語を探しています
y4 =model.doesnt_match(u"本、本、教材".split())
print u"互換性のない単語:", y4
print"-----\n"
# 再利用のためにモデルを保存します
model.save(u"書評.model")
# 対応するロード方法
# model_2 =word2vec.Word2Vec.load("text8.model")
# C言語で解析できる形式で単語ベクトルを保存する
# model.save_word2vec_format(u"書評.model.bin", binary=True)
# 対応するロード方法
# model_3 =word2vec.Word2Vec.load_word2vec_format("text8.model.bin",binary=True)
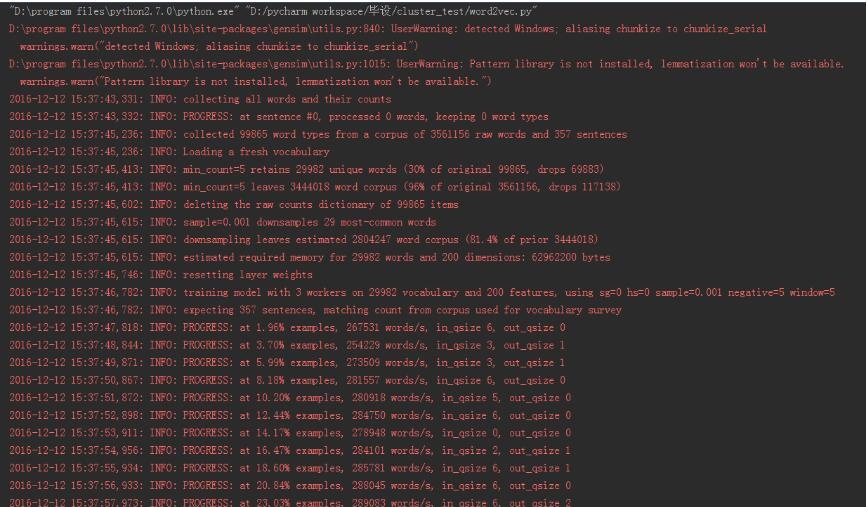
出力は次のとおりです。
" D:\program files\python2.7.0\python.exe""D:/pycharm workspace/セットアップ/cluster_test/word2vec.py"
D:\program files\python2.7.0\lib\site-packages\gensim\utils.py:840: UserWarning: detected Windows; aliasing chunkize to chunkize_serial
warnings.warn("detected Windows; aliasing chunkize to chunkize_serial")
D:\program files\python2.7.0\lib\site-packages\gensim\utils.py:1015: UserWarning: Pattern library is not installed, lemmatization won't be available.
warnings.warn("Pattern library is not installed, lemmatization won't be available.")2016-12-1215:37:43,331: INFO: collecting all words and their counts
2016- 12- 1215:37:43,332: INFO: PROGRESS: at sentence #0, processed 0 words, keeping 0 word types
2016- 12- 1215:37:45,236: INFO: collected 99865 word types from a corpus of3561156 raw words and 357 sentences
2016- 12- 1215:37:45,236: INFO: Loading a fresh vocabulary
2016- 12- 1215:37:45,413: INFO: min_count=5 retains 29982 unique words(30%of original 99865, drops 69883)2016-12-1215:37:45,413: INFO: min_count=5 leaves 3444018 word corpus(96%of original 3561156, drops 117138)2016-12-1215:37:45,602: INFO: deleting the raw counts dictionary of99865 items
2016- 12- 1215:37:45,615: INFO: sample=0.001 downsamples 29 most-common words
2016- 12- 1215:37:45,615: INFO: downsampling leaves estimated 2804247 word corpus(81.4%of prior 3444018)2016-12-1215:37:45,615: INFO: estimated required memory for29982 words and 200 dimensions:62962200 bytes
2016- 12- 1215:37:45,746: INFO: resetting layer weights
2016- 12- 1215:37:46,782: INFO: training model with3 workers on 29982 vocabulary and 200 features, using sg=0 hs=0 sample=0.001 negative=5 window=52016-12-1215:37:46,782: INFO: expecting 357 sentences, matching count from corpus used for vocabulary survey
2016- 12- 1215:37:47,818: INFO: PROGRESS: at 1.96% examples,267531 words/s, in_qsize 6, out_qsize 02016-12-1215:37:48,844: INFO: PROGRESS: at 3.70% examples,254229 words/s, in_qsize 3, out_qsize 12016-12-1215:37:49,871: INFO: PROGRESS: at 5.99% examples,273509 words/s, in_qsize 3, out_qsize 12016-12-1215:37:50,867: INFO: PROGRESS: at 8.18% examples,281557 words/s, in_qsize 6, out_qsize 02016-12-1215:37:51,872: INFO: PROGRESS: at 10.20% examples,280918 words/s, in_qsize 5, out_qsize 02016-12-1215:37:52,898: INFO: PROGRESS: at 12.44% examples,284750 words/s, in_qsize 6, out_qsize 02016-12-1215:37:53,911: INFO: PROGRESS: at 14.17% examples,278948 words/s, in_qsize 0, out_qsize 02016-12-1215:37:54,956: INFO: PROGRESS: at 16.47% examples,284101 words/s, in_qsize 2, out_qsize 12016-12-1215:37:55,934: INFO: PROGRESS: at 18.60% examples,285781 words/s, in_qsize 6, out_qsize 12016-12-1215:37:56,933: INFO: PROGRESS: at 20.84% examples,288045 words/s, in_qsize 6, out_qsize 02016-12-1215:37:57,973: INFO: PROGRESS: at 23.03% examples,289083 words/s, in_qsize 6, out_qsize 22016-12-1215:37:58,993: INFO: PROGRESS: at 24.87% examples,285990 words/s, in_qsize 6, out_qsize 12016-12-1215:38:00,006: INFO: PROGRESS: at 27.17% examples,288266 words/s, in_qsize 4, out_qsize 12016-12-1215:38:01,081: INFO: PROGRESS: at 29.52% examples,290197 words/s, in_qsize 1, out_qsize 22016-12-1215:38:02,065: INFO: PROGRESS: at 31.88% examples,292344 words/s, in_qsize 6, out_qsize 02016-12-1215:38:03,188: INFO: PROGRESS: at 34.01% examples,291356 words/s, in_qsize 2, out_qsize 22016-12-1215:38:04,161: INFO: PROGRESS: at 36.02% examples,290805 words/s, in_qsize 6, out_qsize 02016-12-1215:38:05,174: INFO: PROGRESS: at 38.26% examples,292174 words/s, in_qsize 3, out_qsize 02016-12-1215:38:06,214: INFO: PROGRESS: at 40.56% examples,293297 words/s, in_qsize 4, out_qsize 12016-12-1215:38:07,201: INFO: PROGRESS: at 42.69% examples,293428 words/s, in_qsize 4, out_qsize 12016-12-1215:38:08,266: INFO: PROGRESS: at 44.65% examples,292108 words/s, in_qsize 1, out_qsize 12016-12-1215:38:09,295: INFO: PROGRESS: at 46.83% examples,292097 words/s, in_qsize 4, out_qsize 12016-12-1215:38:10,315: INFO: PROGRESS: at 49.13% examples,292968 words/s, in_qsize 2, out_qsize 22016-12-1215:38:11,326: INFO: PROGRESS: at 51.37% examples,293621 words/s, in_qsize 5, out_qsize 02016-12-1215:38:12,367: INFO: PROGRESS: at 53.39% examples,292777 words/s, in_qsize 2, out_qsize 22016-12-1215:38:13,348: INFO: PROGRESS: at 55.35% examples,292187 words/s, in_qsize 5, out_qsize 02016-12-1215:38:14,349: INFO: PROGRESS: at 57.31% examples,291656 words/s, in_qsize 6, out_qsize 02016-12-1215:38:15,374: INFO: PROGRESS: at 59.50% examples,292019 words/s, in_qsize 6, out_qsize 02016-12-1215:38:16,403: INFO: PROGRESS: at 61.68% examples,292318 words/s, in_qsize 4, out_qsize 22016-12-1215:38:17,401: INFO: PROGRESS: at 63.81% examples,292275 words/s, in_qsize 6, out_qsize 02016-12-1215:38:18,410: INFO: PROGRESS: at 65.71% examples,291495 words/s, in_qsize 4, out_qsize 12016-12-1215:38:19,433: INFO: PROGRESS: at 67.62% examples,290443 words/s, in_qsize 6, out_qsize 02016-12-1215:38:20,473: INFO: PROGRESS: at 69.58% examples,289655 words/s, in_qsize 6, out_qsize 22016-12-1215:38:21,589: INFO: PROGRESS: at 71.71% examples,289388 words/s, in_qsize 2, out_qsize 22016-12-1215:38:22,533: INFO: PROGRESS: at 73.78% examples,289366 words/s, in_qsize 0, out_qsize 12016-12-1215:38:23,611: INFO: PROGRESS: at 75.46% examples,287542 words/s, in_qsize 5, out_qsize 12016-12-1215:38:24,614: INFO: PROGRESS: at 77.25% examples,286609 words/s, in_qsize 3, out_qsize 02016-12-1215:38:25,609: INFO: PROGRESS: at 79.33% examples,286732 words/s, in_qsize 5, out_qsize 12016-12-1215:38:26,621: INFO: PROGRESS: at 81.40% examples,286595 words/s, in_qsize 2, out_qsize 02016-12-1215:38:27,625: INFO: PROGRESS: at 83.53% examples,286807 words/s, in_qsize 6, out_qsize 02016-12-1215:38:28,683: INFO: PROGRESS: at 85.32% examples,285651 words/s, in_qsize 5, out_qsize 32016-12-1215:38:29,729: INFO: PROGRESS: at 87.56% examples,286175 words/s, in_qsize 6, out_qsize 12016-12-1215:38:30,706: INFO: PROGRESS: at 89.86% examples,286920 words/s, in_qsize 5, out_qsize 02016-12-1215:38:31,714: INFO: PROGRESS: at 92.10% examples,287368 words/s, in_qsize 6, out_qsize 02016-12-1215:38:32,756: INFO: PROGRESS: at 94.40% examples,288070 words/s, in_qsize 4, out_qsize 22016-12-1215:38:33,755: INFO: PROGRESS: at 96.30% examples,287543 words/s, in_qsize 1, out_qsize 02016-12-1215:38:34,802: INFO: PROGRESS: at 98.71% examples,288375 words/s, in_qsize 4, out_qsize 02016-12-1215:38:35,286: INFO: worker thread finished; awaiting finish of2 more threads
2016- 12- 1215:38:35,286: INFO: worker thread finished; awaiting finish of1 more threads
Word2Vec(vocab=29982, size=200, alpha=0.025)
[国]と[州議会]の類似点は次のとおりです:0.387535493256-----2016-12-1215:38:35,293: INFO: worker thread finished; awaiting finish of0 more threads
2016- 12- 1215:38:35,293: INFO: training on 17805780 raw words(14021191 effective words) took 48.5s,289037 effective words/s
2016- 12- 1215:38:35,293: INFO: precomputing L2-norms of word weight vectors
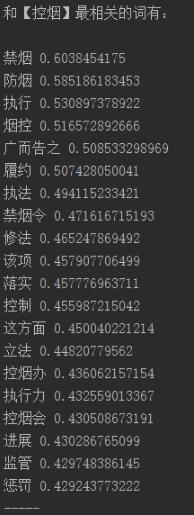
[タバコ管理]に最も関連する言葉は次のとおりです。
禁煙0.6038454175
防煙0.585186183453
0を実行します.530897378922
タバココントロール0.516572892666
アドバタイズ0.508533298969
パフォーマンス0.507428050041
施行0.494115233421
禁煙禁止0.471616715193
変更0.465247869492
アイテム0.457907706499
実装0.457776963711
コントロール0.455987215042
この側面0.450040221214
立法0.44820779562
たばこ管理事務所0.436062157154
実行0.432559013367
たばこ管理会議0.430508673191
進捗状況0.430286765099
監督0.429748386145
ペナルティ0.429243773222-----
本-良品質-
サバイバル0.613928854465
安定した0.595371186733
全体的に0.592055797577----
互換性のない言葉:非常に
- - - - - 2016- 12- 1215:38:35,515: INFO:ブックレビュー中のWord2Vecオブジェクトの保存.model, separately None
2016- 12- 1215:38:35,515: INFO: not storing attribute syn0norm
2016- 12- 1215:38:35,515: INFO: not storing attribute cum_table
2016- 12- 1215:38:36,490: INFO:保存された本のレビュー.model
Process finished with exit code 0


上記のword2vec操作のpython予備実装は、エディターによって共有されるすべてのコンテンツです。参照を提供したいと思います。
Recommended Posts