Pythonで正規表現を取得するための1つの記事
詳細な再モジュール###
この記事では、正規表現と Pythonの reモジュールについて詳しく説明します。
- 正規表現とは
- 正規表現機能
- メタキャラクターとその意味
- 詳細な再モジュール
- Regexモディファイア
- 正規表現の例

<!- - MORE-->
この記事の内容###
正規表現とは###
正規式(正規式)は、文字列の一致パターン(pattern)を記述し、文字列に特定のサブ文字列が含まれているかどうかの確認、一致した部分文字列の置換、または特定の条件を満たす文字列からの抽出に使用できます。サブストリングなど
正規表現関数###
通常の式を使用すると、次のことができます。
- 文字列内のパターンをテストします
たとえば、入力文字列をテストして、電話番号パターンまたはクレジットカード番号パターンが文字列に表示されているかどうかを確認できます。これはデータ検証と呼ばれます。 - 置換テキスト
通常の式を使用して、ドキュメント内の特定のテキストを識別したり、テキストを完全に削除したり、他のテキストに置き換えたりすることができます。 - パターンマッチングに基づいて文字列からサブ文字列を抽出します
必要なコンテンツなど、ドキュメント内または入力フィールド内の特定のテキストを、クローラーを介してWebページのコンテンツから直接検索できます。
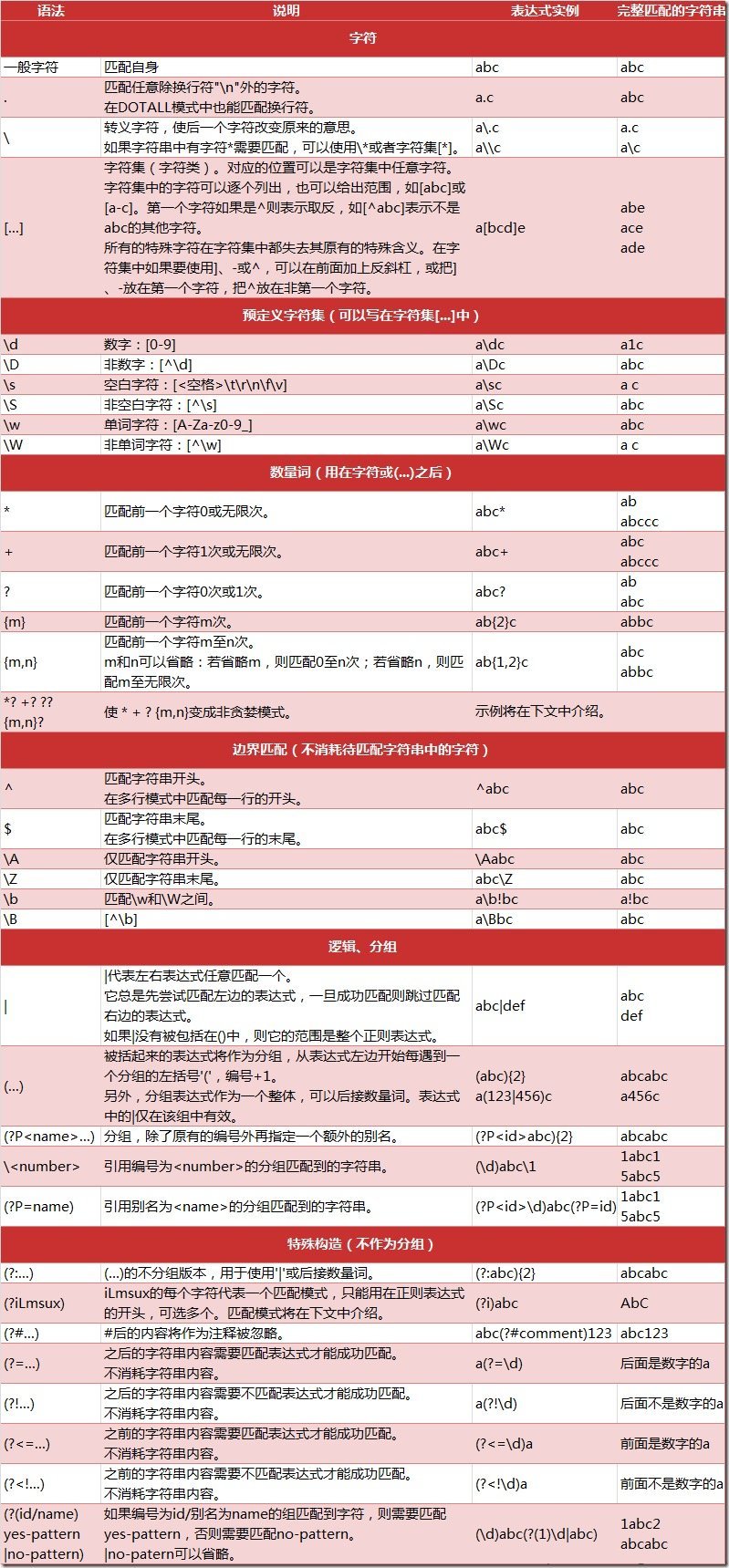
メタキャラクターとその意味###
一般的に使用されるメタ文字####
| 記号 | 意味 |
|---|---|
| ドット | 改行以外の文字と一致します |
| アスタリスク* | 0個以上の任意の文字に一致 |
| 疑問符? | 任意の文字を0または1に一致させます(非貪欲モード) |
| ^ | 開始位置 |
| $ | 終了位置 |
| \ s | 任意の空白に一致 |
| \ S | 空白以外のすべてに一致 |
| \ d | 数字に一致 |
| \ D | 数字以外に一致 |
| \ w | 単語の文字に一致し、数字と文字を含みます |
| \ W | 数字や文字を含む単語以外の文字に一致します |
| abcd | abcdの任意の文字に一致 |
| ^ abcd | abcd |
| 前のコンテンツと1回以上一致させる | |
| { n} | nワードに一致(固定) |
| { n、} | 少なくともn回一致する |
| { n、m) | nをm回一致させる |
| x | y |
| () | 括弧内の内容と一致してください |
メタキャラクター####
以下は、より完全なメタ文字マッチングテーブルです
| メタキャラクター | 説明 |
|---|---|
| \ | 次の文字トークン、後方引用符、またはオクタルエスケープ文字を入力します。たとえば、「\ n」は一致します\ n。 「\ N」は新行文字に一致します。シーケンス「\」は「\」に一致し、「(」は「(」に一致します。これは、多くのプログラミング言語の「エスケープ文字」の概念に相当します。 |
| ^ | 入力行の先頭に一致します。 RegExpオブジェクトのMultilineプロパティが設定されている場合、^は「\ n」または「\ r」の後の位置にも一致します。 |
| $ | 入力行の終わりに一致します。 RegExpオブジェクトのMultilineプロパティが設定されている場合、$は「\ n」または「\ r」の前の位置とも一致します。 |
| 前の部分式に何度でも一致させます。たとえば、zo *は、「z」、「zo」、「zoo」と一致させることができます。 * {0、}と同等です。 | |
| 前の部分式に1回以上一致します(1回以上)。たとえば、「zo +」は「zo」と「zoo」に一致できますが、「z」には一致しません。 + {1、}に相当します。 | |
| ? | 前の部分式に0回または1回一致します。たとえば、「do(es)?」は「do」または「does」と一致します。 ?{0,1}と同等です。 |
| {* n *} | * n は非負の整数です。一致は n *回確認されました。たとえば、「o {2}」は「Bob」の「o」と一致することはできませんが、「food」の2つのoと一致することはできます。 |
| {* n *、} | * n は非負の整数です。少なくとも n *回一致します。たとえば、「o {2、}」は「Bob」の「o」と一致することはできませんが、「foooood」のすべてのoと一致することはできます。 「O {1、}」は「o +」と同等です。 「O {0、}」は「o *」と同等です。 |
| {* n 、 m *} | * m および n は非負の整数であり、 n * <= * m です。少なくとも n 回一致し、最大 m *回一致します。たとえば、「o {1,3}」は、「fooooood」の最初の3つのoをグループとして照合し、最後の3つのoをグループとして照合します。 「O {0,1}」は「o?」と同等です。カンマと2つの数字の間にスペースを入れることはできないことに注意してください。 |
| ? | 文字が他の修飾子(、+、?、{ n }、{ n 、}、{ n 、 m *})の直後に続く場合、マッチングモードは貪欲ではありません。非貪欲モードは検索された文字列とできるだけ一致しませんが、デフォルトの貪欲モードは検索された文字列とできるだけ一致します。たとえば、文字列「oooo」の場合、「o +」は「o」と可能な限り一致して結果「oooo」を取得し、「o +?」は「o」と可能な限り一致せずに結果「o」を取得します。 o '、' o '、' o ' |
| . ドット | は「\ n」と「\ r」以外の任意の1文字に一致します。 「\ n」や「\ r」を含む任意の文字に一致させるには、「\ s \ S」のようなパターンを使用します。 (新しい行の文字と一致しません) |
| ( pattern) | パターンを一致させ、この一致を取得します。取得された一致は、生成されたMatchesコレクションから取得でき、SubMatchesコレクションはVBScriptで使用され、$ 0 ... $ 9プロパティはJScriptで使用されます。括弧文字を一致させるには、「(」または「)」を使用します。 |
| (?: pattern) | 非取得マッチング。パターンはマッチングされますが、マッチング結果は取得されず、後で使用するために保存されません。これは、or文字「( |
| (?= pattern) | 非取得マッチング、ポジティブポジティブプレチェック、文字列マッチングパターンの先頭で検索文字列とマッチング。後で使用するために一致を取得する必要はありません。たとえば、「Windows(?= 95 |
| (?! pattern) | 非取得マッチング、フォワードネガティブプレチェック、パターンと一致しない文字列の先頭にある検索文字列との一致。将来使用するために一致を取得する必要はありません。たとえば、「Windows(?!95 |
| (?<= パターン) | 非取得マッチング、逆正の事前チェック、正の正の事前チェックと同様ですが、反対方向です。たとえば、「(?<= 95 |
| (?<! patte_n) | 非取得マッチング、逆方向の負の事前チェック。順方向の負の事前チェックと同様ですが、方向が逆です。例えば"(? <!95 |
| x | y |
| xyz | 文字セット。含まれている任意の1文字に一致します。たとえば、「abc」は「plain」の「a」と一致させることができます。 |
| ^ xyz | 負の文字セット。含まれていない文字に一致します。たとえば、「^ abc」は、「plain」の「plin」の任意の文字と一致します。 |
| az | 文字範囲。指定された範囲内の任意の文字に一致します。たとえば、「az」は「a」から「z」までの任意の小文字のアルファベット文字に一致します。注:ハイフンが文字グループ内にあり、2つの文字の間にある場合にのみ、文字の範囲を表すことができます。ハイフンが文字グループの先頭から外れている場合は、ハイフン自体のみを表すことができます。 |
| ^ az | 負の文字範囲。指定された範囲内にない文字に一致します。たとえば、「^ az」は、「a」から「z」の範囲外の任意の文字に一致できます。 |
| \ b | 単語の境界、つまり単語とスペースの間の位置を一致させます(つまり、正規表現の「一致」には2つの概念があり、1つは一致する文字、もう1つは一致する位置です。ここで、\ bは一致する位置です。の)。たとえば、「er \ b」は「never」の「er」と一致しますが、「verb」の「er」とは一致しません。「\ b1 *」は、「1_23」の「1 *」と一致できますが、一致できません。 「21 * 3」の「1 *」。 |
| \ B | 単語以外の境界に一致します。 「Er \ B」は「verb」の「er」と一致できますが、「never」の「er」とは一致しません。 |
| \ cx | xで指定された制御文字と一致します。たとえば、\ cMはControl-Mまたはキャリッジリターン文字と一致します。 xの値は、AZまたはazのいずれかである必要があります。それ以外の場合は、cを文字通りの「c」文字として扱います。 |
| \ d | 数字に一致します。 0〜9に相当します。 grepは-P、perlの定期的なサポートを追加する必要があります |
| \ D | 数字以外の文字に一致します。 ^ 0-9に相当します。 grepは-P、perlの定期的なサポートを追加する必要があります |
| \ f | フォームフィード文字に一致します。 \ x0cおよび\ cLと同等です。 |
| \ n | は新しい行の文字に一致します。 \ x0aおよび\ cJと同等です。 |
| \ r | キャリッジリターン文字に一致します。 \ x0dおよび\ cMと同等です。 |
| \ ■ | スペース、タブ、フォームフィードなど、非表示の文字と一致します。 \ f \ n \ r \ t \ vと同等です。 |
| \ S | は表示されているすべての文字に一致します。 ^ \ f \ n \ r \ t \ vと同等です。 |
| \ t | タブ文字に一致します。 \ x09および\ cIと同等です。 |
| \ v | 垂直タブ文字に一致します。 \ x0bおよび\ cKと同等です。 |
| \ w | 下線を含むすべての単語文字に一致します。 「A-Za-z0-9_」と似ていますが同等ではありませんが、ここでの「単語」文字はUnicode文字セットを使用します。 |
| \ W | は単語以外の文字と一致します。 「^ A-Za-z0-9_」に相当します。 |
| \ x * n * | * n と一致します。ここで、 n *は16進数のエスケープ値です。 16進数のエスケープ値は2桁の長さである必要があります。たとえば、「\ x41」は「A」と一致します。 「\ X041」は「\ x04&1」と同等です。 ASCIIエンコーディングは正規表現で使用できます。 |
| * num * | は* num に一致します。ここで、 num *は正の整数です。得られた一致への参照。たとえば、「(。)\ 1」は2つの連続する同一の文字に一致します。 |
| * n * | 8進エスケープ値または後方参照を識別します。 * n が以前に少なくとも n 取得した部分式を持っている場合、 n は後方参照です。それ以外の場合、 n がオクタル数(0〜7)の場合、 n *はオクタルエスケープ値です。 |
| * nm * | 8進エスケープ値または後方参照を識別します。 * nm の前に少なくとも nm の部分式がある場合、 nm *は後方参照です。 * nm の前に少なくとも n の取得がある場合、 n は後方参照の後にテキスト m が続きます。上記の条件が満たされない場合、 n と m の両方がオクタル数(0〜7)の場合、 nm はオクタルエスケープ値 nm *と一致します。 |
| * nml * | * n が8桁(0〜7)で、 m と l の両方が8桁(0〜7)の場合、8進エスケープ値 nml *と一致します。 |
| \ u * n * | * n と一致します。ここで、 n *は4つの16進数で表されるUnicode文字です。たとえば、\ u00A9は著作権記号(©)と一致します。 |
| \ p {P} | 小文字のpはプロパティを意味し、Unicodeプロパティを意味し、Unicode正規式のプレフィックスとして使用されます。括弧内の「P」は、Unicode文字セットの7つの文字属性の1つである句読点文字を表します。他の6つの属性:L:文字、M:マーク記号(通常は単独で表示されない)、Z:区切り文字(スペース、改行など)、S:記号(数学記号、通貨記号など)、N:数字(アラビア数字、ローマ数字など); C:その他の文字。 **注:言語のこの構文部分はサポートされていません(例:javascript)。 * |
| <> | 単語(word)の先頭(\ <)と末尾(>)を一致させます。たとえば、正規表現<the> 「賢い人のために」という文字列の「the」と一致させることはできますが、「それ以外の場合」という文字列の「the」と一致させることはできません。注:このメタ文字は、すべてのソフトウェアでサポートされているわけではありません。 |
| ( ) | (と)の間の式を「グループ」として定義し、この式に一致する文字を一時領域に保存します(通常の式では最大9個まで保存できます)。\ 1を使用して引用する\ 9。 |
詳細な再モジュール###
reモジュールは、通常の式の問題を処理するためにpythonで提供されています。一般的に使用されるいくつかのメソッドを次に示します。
re.match
re.matchは、文字列の開始位置からパターンを一致させようとします。開始位置で一致が成功しなかった場合、match()はnoneを返します。
このメソッドは、通常の一致するオブジェクトを返します
構文
import re
re.match(pattern, string, flags=0)
パラメータ説明#####
| パラメータ | 説明 |
|---|---|
| パターン | 一致した正規表現 |
| string | 一致する文字列。 |
| フラグ | フラグ。大文字と小文字を区別する、複数行の照合など、通常の式の照合モードを制御するために使用されます。 |
demo
group()を介してコンテンツを取得しますspan()を介して範囲を取得します
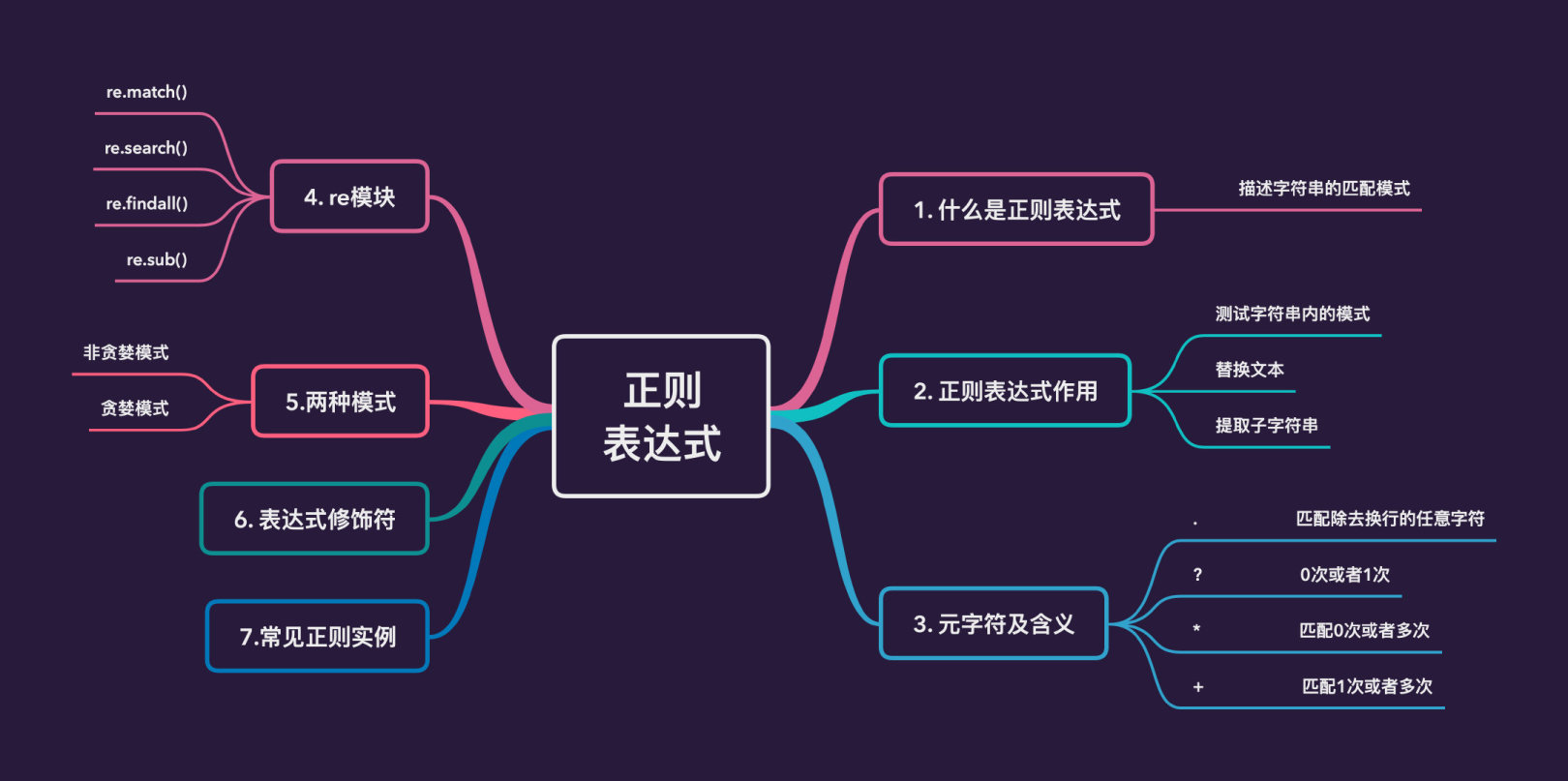
# 最も定期的な試合
content ="Hello 1234567 World_This is a Regex Demo"print(len(content))
result = re.match("^Hello\s\d+\s\w{10}.*?Demo$", content) #開始位置から一致する必要があります
# result = re.match("^Hello\s\d{7}\s\w{10}.*?Demo$", content)print(result)print(result.group())print(result.span())
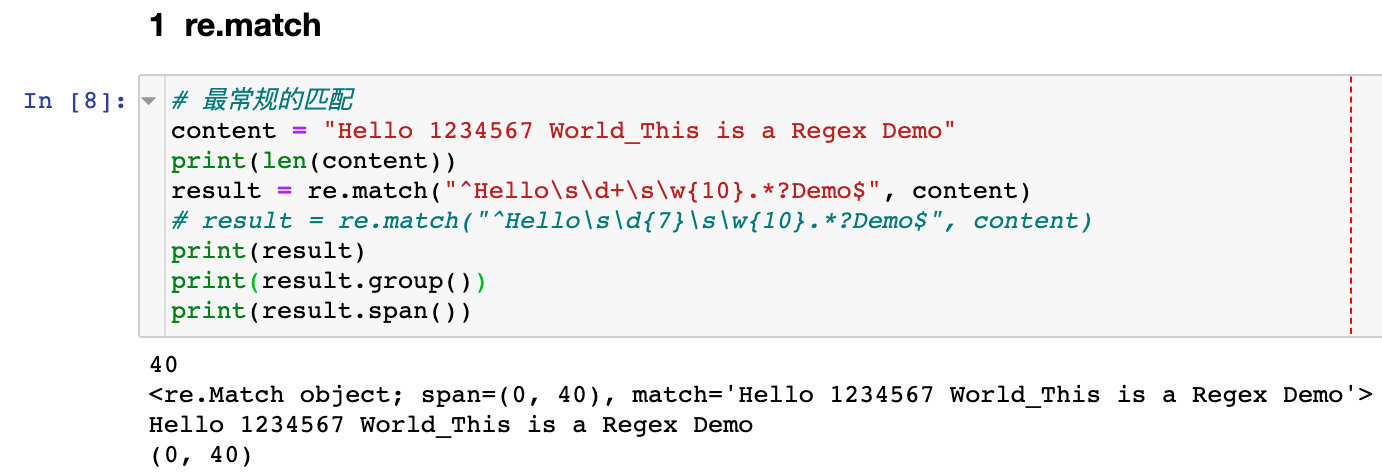
新行文字がある場合は、フラグ re.Sを使用します
# 新しい行がある場合は、フラグ記号を使用します
content ="""Hello 1234567 World_This is a Regex Demo.
My name is Peter
I am from shenzhen
"""
print(len(content))
result = re.match("^Hello\s\d+\s.*?shenzhen$", content, re.S)
# result = re.match("^Hello\s\d{7}\s\w{10}.*?Peter$", content)print(result)print(result.group())print(result.span())
line ="Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*?', line, re.M|re.I)if matchObj:print("matchObj.group() : ", matchObj.group()) #返されたすべてのコンテンツ
print("matchObj.group(1) : ", matchObj.group(1)) #最初に戻る()のコンテンツ
print("matchObj.group(2) : ", matchObj.group(2)) #2位
else:print("No match!!")

re.match 使用をできるだけ少なくする
re.match 使用をできるだけ少なくする
re.match 使用をできるだけ少なくする
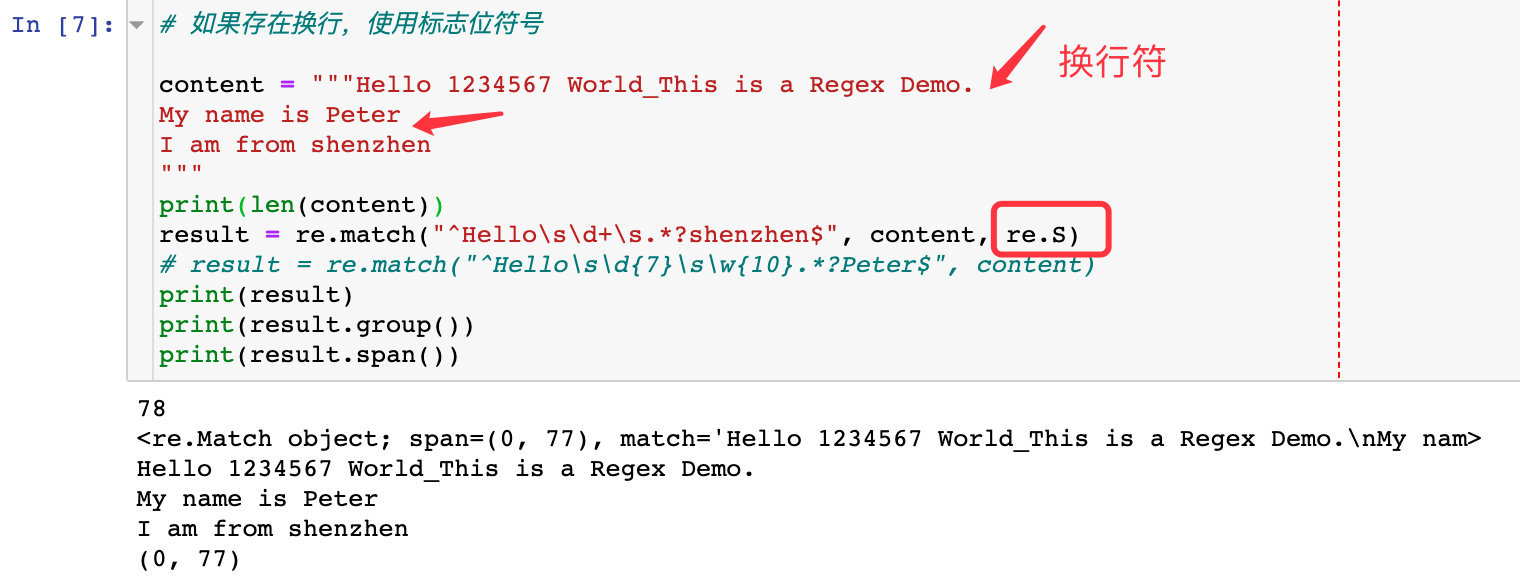
re.search
re.searchは文字列全体をスキャンし、最初に成功した一致を返します。それ以外の場合はNoneを返します。この方法では、開始位置から開始する必要はありません。要件を満たす最初のコンテンツが見つかると、検索を停止します
group(num)または groups()マッチングオブジェクト関数を使用して、マッチング式の結果を取得できます。
関数構文#####
re.search(pattern, string, flags=0)
パラメータ説明#####
| パラメータ | 説明 |
|---|---|
| パターン | 一致した正規表現 |
| string | 一致する文字列。 |
| フラグ | 大文字と小文字を区別する、複数行の照合など、通常の式の照合モードを制御するために使用されるフラグ |
demo
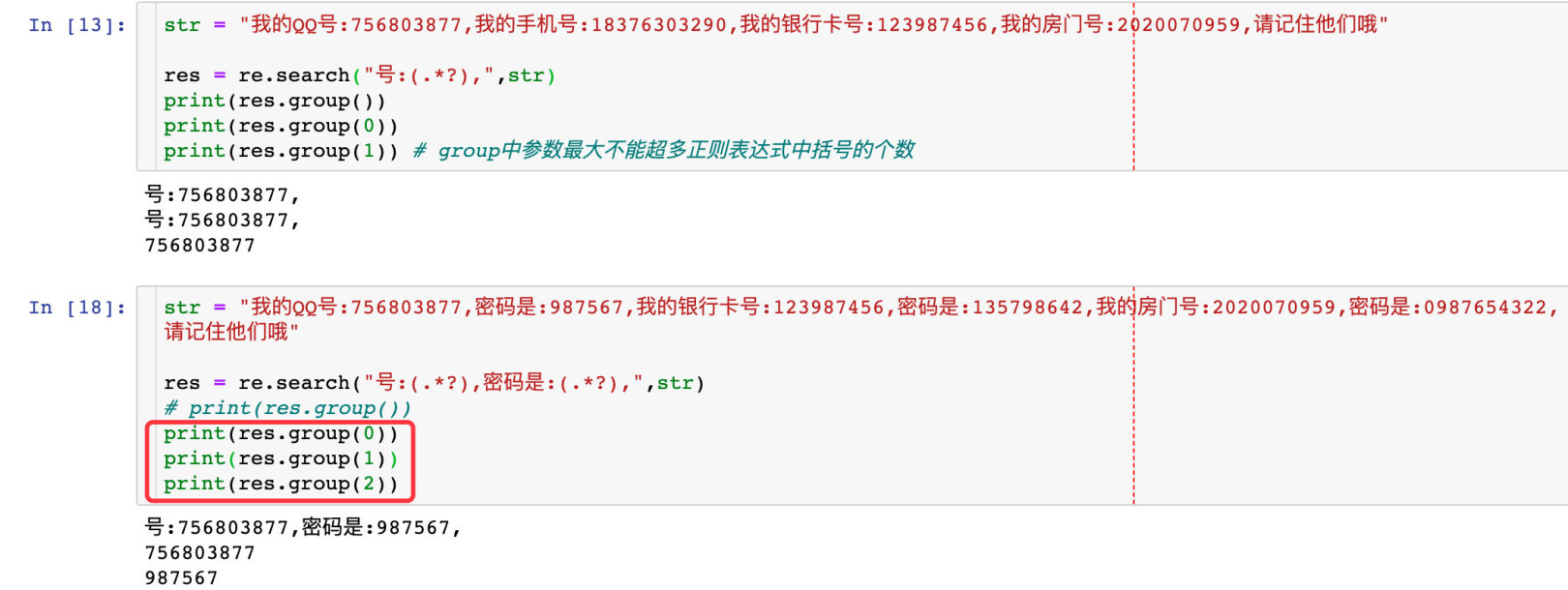
- 正常に一致した最初の要素を返します
- group()メソッドのパラメーターは括弧の数を超えることはできません
re.findall
re.findallは文字列全体をスキャンし、適格なすべての要素をリストの形式で返します。
文法#####
findall(pattern, string, flags=0)
パラメータ説明#####
| パラメータ | 説明 |
|---|---|
| パターン | 一致した正規表現 |
| string | 一致する文字列。 |
| フラグ | 大文字と小文字を区別する、複数行の照合など、通常の式の照合モードを制御するために使用されるフラグ |
demo
結果はリスト形式になります

抽出されたコンテンツに複数の 。*?が含まれている場合、戻り値はリストの形式のままですが、内部の要素はタプル形式になります

re.sub
正規表現を使用して、文字列内の特定のコンテンツを置き換えます
文法#####
re.sub(pattern, repl, string, count)
パラメータ説明#####
パラメータの意味は次のとおりです。
- 正規表現
- 置き換えられたコンテンツ
- 生の文字列
- 置換の数、デフォルトは0、すべてを置換
demo



サブ特殊処理####
re.subは、関数を使用して一致するアイテムの特別な処理を可能にします


2つのモード###
2つのモードが参照します:貪欲モードと非貪欲モード
3 記号####
通常の式では、次の3つの記号を使用することがよくあります。
- ドット:一致が新行文字以外の任意の文字であることを示します
- 疑問符?:0または1の一致を意味します
- アスタリスク*:0または任意の文字に一致することを意味します
demo
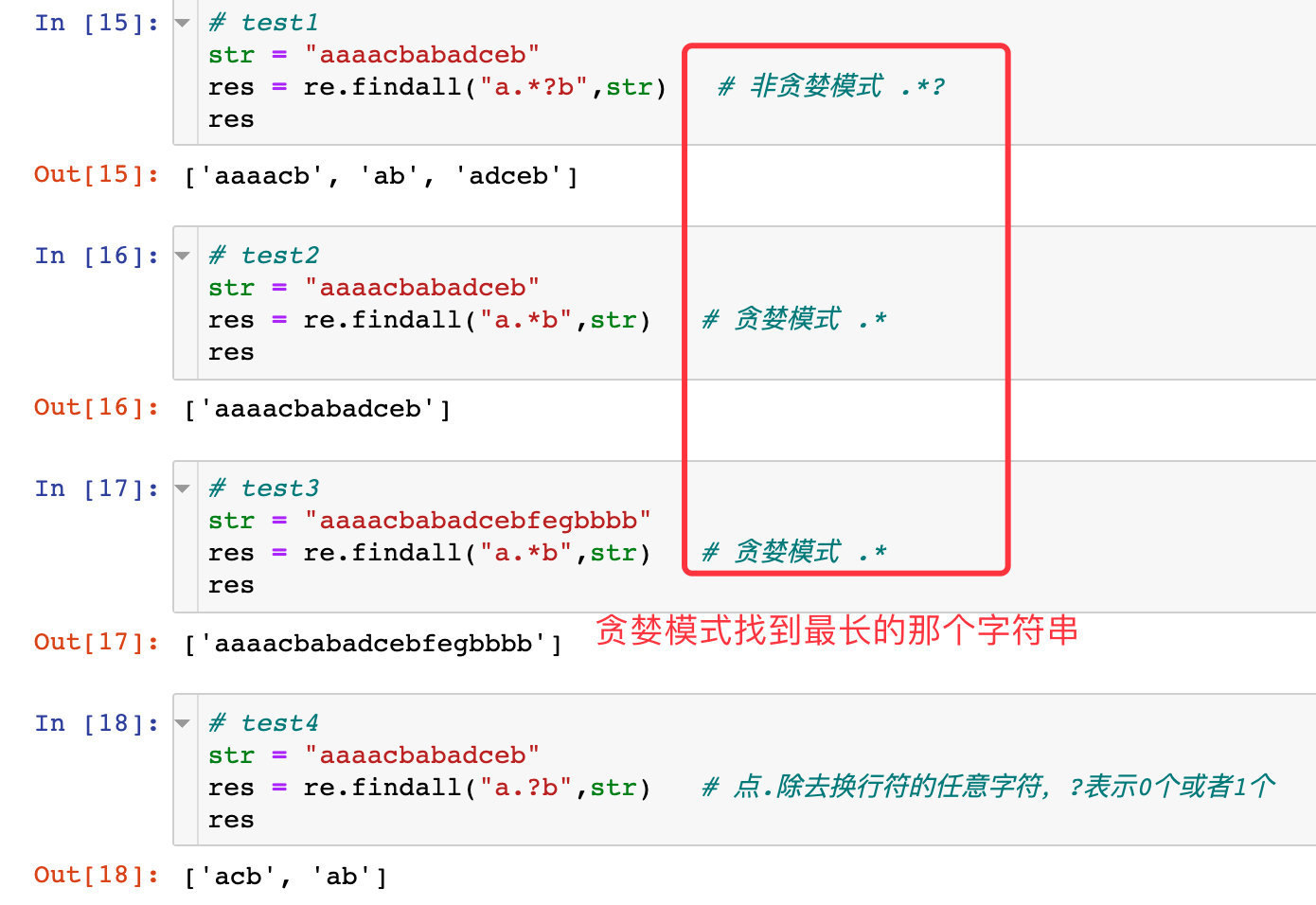
説明####
- 上記の非貪欲モードの例では、疑問符が使用されていますか? 、これは非貪欲モードを意味し、
aaaacbが要件を満たしていることと一致し始めると、最初のものが見つかります;次に再び一致し始め、abと一致します;再びadcebと一致します - 貪欲モードの例では、プログラムは要件を満たす最長の文字列を見つけます
- 最後の例では、
。?が使用されています。つまり、abの間に存在できる要素は0または1のみであるため、結果には2つのケースしかありません。
Regex修飾子-オプションのフラグ###
通常の式には、一致するパターンを制御するためのオプションのフラグ修飾子を含めることができます。修飾子はオプションのフラグとして指定されます。複数のフラグは、ビット単位のOR(|)で指定できます。たとえば、re.I | re.MはIフラグとMフラグに設定されます。
| 修飾子 | 説明 |
|---|---|
| re.I | 一致を大文字と小文字を区別しないようにする |
| re.L | ロケールを意識したマッチングを行う |
| re.M | 複数行のマッチング、^と$に影響 |
| re.S | newlineを含むすべての文字に一致させる |
| re.U | Unicode文字セットに従って文字を分析します。このフラグは\ w、\ W、\ b、\ Bに影響します。 |
| re.X | このフラグを使用すると、より柔軟な形式を使用して、通常の式をより簡単に記述できます。 |
正規表現の例###
文字マッチング####
| 例 | 説明 |
|---|---|
| python | 「python」に一致します。 |
文字クラス####
| 例 | 説明 |
|---|---|
| Ppython | 「Python」または「python」と一致するPpから一致する文字を選択してください |
| rubye | 「ruby」または「rube」に一致する1つの一致を選択する |
| aeiou | 括弧内の任意の文字に一致aeiou内の文字に一致 |
| 0- 9 | 任意の数に一致します。 0123456789と同様に、任意の桁数に一致します |
| az | 任意の小文字に一致 |
| AZ | 任意の大文字に一致 |
| a-zA-Z0-9 | 任意の文字と数字に一致 |
| ^ aeiou | aeiou文字を除くすべての文字** ^は反転操作を意味します** |
| ^0- 9 | 数字以外の文字に一致 |
特殊キャラクタークラス####
| 例 | 説明 |
|---|---|
| . | 「\ n」以外の任意の1文字に一致します。 '\ n'を含む任意の文字に一致させるには、 '。\ n'のようなパターンを使用します。 |
| \ d | 数字に一致します。 0〜9に相当します。 |
| \ D | は数字以外の文字に一致します。 ^ 0-9に相当します。 |
| \ s | スペース、タブ、フォームフィードなどを含むすべての空白文字に一致します。 \ f \ n \ r \ t \ vと同等です。 |
| \ S | は空白以外の文字に一致します。 ^ \ f \ n \ r \ t \ vと同等です。 |
| \ w | 下線を含むすべての単語文字に一致します。 「A-Za-z0-9_」に相当します。 |
| \ W | は単語以外の文字と一致します。 '^ A-Za-z0-9_'と同等です。 |
総括する###
参照###
[ 初心者コース-通常の表現](https://www.runoob.com/regexp/regexp-syntax.html)
[ python-regular expression](https://www.runoob.com/python/python-reg-expressions.html)
[ 定期的な表現のオンラインテスト](https://tool.oschina.net/regex#)
[ Python3-通常の式](https://www.w3cschool.cn/python3/python3-reg-expressions.html)
[ 通常の式の完了](https://blog.csdn.net/qq_28633249/article/details/77686976?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none- task-blog-BlogCommendFromMachineLearnPai2-1.nonecase)
[ 再モジュール](https://docs.python.org/zh-cn/3/library/re.html)
Recommended Posts