Python正規表現の簡単な紹介
正規表現は、データ(フォーマット)の検証、文字コンテンツの置換、文字列コンテンツの抽出などのプログラム開発でよく使用されますが、現在、多くの開発者は正規表現しか理解していないか、基本的に知っています。中古ステージ。通常の表現(Webクローラーなど)の大規模な使用に遭遇すると、基本的に盲目であると言えます。この記事では、Pythonを使用した正規表現について学習します。基本的にすべての言語が同様の方法で正規表現を使用するため、この記事を読む前に、Pythonの基本を習得するか、他の開発言語の基本的な知識を持っている必要があります。
ゼロ、正規表現の基本####
- 文字を抽出する(文字列)
文字列からコンテンツを取得する必要がある場合があります。このコンテンツは、文字または文字列の場合があります。逐語的な比較を使用してトラバースすると、時間と労力がかかるだけでなく、エラーが発生しやすくなります。次に、この時点で、正規の式で文字マッチング関数を使用できます。通常の式では、4つの文字照合方法が提供されます。次の表を参照してください。
| 構文 | 説明 | 例 | 一致する文字列 |
|---|---|---|---|
| . | 改行 "\ n" | ab | acb、adb、a2b、a〜b |
| | エスケープして、転送された文字の後に文字の元の意味を変更する | a [b \。\] c | abc、ac、a \ c | |
| [] | 括弧内の任意の文字に一致 | a [b、c、d、e] f | abd、acf、adf、aef |
| [^] | 括弧内の文字を除いて、他のすべての文字は | a [^ a、b、c、d、e] f | a1f、a#f、azf、agf |
- 事前定義された文字
いわゆる定義済み文字は、フォーマットされたコンテンツに一致するように通常の式で予約されている文字です。たとえば、番号を一致させる場合は** \ d 、空白文字を一致させる場合は \ s **です。事前定義された文字を使用して、要件を満たす文字列のコンテンツをすばやく一致させることができます。事前定義された文字照合の内容は、上記の文字照合方法でも照合できますが、コードの量は比較的多くなります。次の表に、事前定義された文字を示します。
| 構文 | 説明 | 例 | 一致する文字列 |
|---|---|---|---|
| ^ | 開始する文字列 | ^ 123 | 123abc、123321、123zxc |
| $ | どの文字列で終わるか | 123 $ | abc123、321123、zxc123 |
| \ b | 文字ではなく、単語の境界に一致する | \ basd \ b | asd |
| \ d | 一致番号0-9 | zx \ dc | zx1c、zx2c、zx5c |
| \ D | 非数字に一致 | zx \ Dc | zxvc、zx $ c、zx&c |
| \ s | 空白文字に一致 | zx \ sc | zx c |
| \ S | 空白以外の文字と一致する | zx \ Sc | zxac、zx1c、zxtc |
| \ w | 文字、数字、下線を一致させる | zx \ wc | zxdc、zx1c、zx_c |
| \ W | 文字以外、数字、下線に一致 | zx \ Wc | zx c、zx $ c、zx(c |
事前定義された文字には、次の点に注意する必要があります。
- \ bは位置にのみ一致します。この位置の一方の側は単語を構成する文字であり、もう一方の側は単語以外の文字、つまり文字列の最初または最後です。 \ bは幅がゼロです。
- \ w異なるエンコーディング言語での一致範囲は異なります。ASCIIコードを使用する言語では[a-zA-Z0-9_]と一致しますが、Unicodeコードを使用する言語では[a-zA-]と一致します。 Z0-9_]および中国語文字や全幅記号などの特殊文字。
- 数量限定
場合によっては、繰り返されるコンテンツを照合する必要があります。その後、数量制限モードを使用して操作できます。数量は次のように制限されています。
| 構文 | 説明 | 例 | 一致する文字列 |
|---|---|---|---|
| * | 0を何度も一致させる | zxc * | zx、zxccccc |
| + | 1を何度も一致させる | zxc + | zxc、zxccccc |
| ? | 0回または1回一致 | zxc? | zxc、zx |
| { m} | m回一致 | zxc {3} vb | zxcccvb |
| { m、} | m回以上一致 | zxc {3、} vb | zxcccvb、zxccccccccvb |
| {, n} | 0からn回一致 | zxc {、3} vb | zxvb、zxcvb、zxccvb、zxcccvb |
| { m、n} | mをn回一致させる | zxc {1,3} | zxcvb、zxccvb、zxcccvb |
- アサーション
アサーションは、ゼロ幅アサーションとも呼ばれ、アサーション式がTrueの場合の一致を指しますが、アサーション式の内容とは一致しません。 ^が始まりを表し、$が終わりを表し、\ bが単語の境界を表すように、プリアサーションと次の述語は同様の機能を持ちます。これらは特定の位置にのみ一致し、一致プロセス中に文字を占有しないため、ゼロ幅と呼ばれます。いわゆる位置とは、最初の文字の左側、最後の文字の右側、および文字列内の隣接する文字の中央を指します。ゼロ幅アサーション式には、次の4つのタイプがあります。
- ゼロ幅の否定的なレビューの後にアサートします(? <!exp),表达式不成立时匹配断言后面的位置,成立时不匹配。例如 \w+(?<zxc)\d,匹配不以 zxc 结尾的字符串;
- ゼロ幅のネガティブレビュー先読みアサーション(?!exp)。式はアサーションの前の位置と一致し、trueの場合は一致しません。例:\ d(?! zxc)\ w +、zxcで始まらない文字列に一致します。
- 事前アサーション(?= exp)は、アサーションがtrueの場合、アサーションの前の位置と一致します。たとえば、文字列「通常の式」の通常のreと一致させるには、re(?= gular);と記述します。
- アサーションを投稿します(?<= exp)。アサーションがtrueの場合、アサーションの後の位置を一致させます。たとえば、文字列「egexは通常の式を表します」の場合、regexとregular以外のreを一致させたい場合は、re(?!g )、式はreの右側の位置を制限し、その後に文字gが続きません。最初と最後の違いは、その位置の後の文字が括弧内の式と一致できるかどうかです。
- 貪欲/非貪欲
通常の式はできるだけ多くの文字に一致します。これは貪欲モードと呼ばれます。貪欲モードは通常の式のデフォルトモードです。ただし、貪欲モードでは不要な問題が発生する場合があります。たとえば、文字列「Jack123Chen123Chen」の「Jack123Chen」と一致させたいが、貪欲モードが「Jack123Chen123Chen」と一致する場合は、非貪欲を使用する必要があります。この問題を解決するためのモード、非貪欲モードの一般的に使用される表現は次のとおりです。
| 文法 | 説明 |
|---|---|
| *? | 0回以上一致しますが、繰り返しはできるだけ少なくします |
| +? | 1回以上一致しますが、繰り返しはできるだけ少なくします |
| ?? | 0または1に一致しますが、繰り返しはできるだけ少なくします |
| { m、}? | m回以上一致しますが、繰り返しはできるだけ少なくします |
| { m、n}? | m回またはn回一致しますが、繰り返しはできるだけ少なくします |
- その他
上記の内容は、通常の表現で一般的に使用されています。一般的に使用されていないが、同様に強力な文法を見てみましょう。
- ORマッチングは、マッチングブランチとも呼ばれます。これは、ブランチマッチングがある限り、一致と見なされることを意味します。これは、開発で使用するORステートメントと同様です。 ORマッチングでは、** | **を使用してブランチを分割します。たとえば、英語名を照合する必要がありますが、英語では、姓と名を・で区切るか、スペースで区切ることができます。その後、ORマッチングを使用してこの問題に対処します。形式は次のとおりです。[A-Za-z] +・[A-Za-z] + | [A-Za-z] + \ s [A-Za-z] +
- 複数のアイテムを1つのユニットに組み合わせた組み合わせで、このユニットは* +?|などの記号で変更でき、この組み合わせに一致する文字列を記憶して待機参照を提供できます。グループ化は()で表されます。たとえば、日付を取得するための正規式は、次のように記述できます。\ d {4}-(0 [1-9] | 1 [0-2])-(0 [1-9] | [12] [0-9] | 3 [01])。最初のグループ(0 [1-9] | 1 [0-2])はその月の通常の試合を表し、2番目のグループ(0 [1-9] | [12] [0-9] | 3 [01])は)その日の通常の試合を表します。
1.Pythonは通常の式を使用します####
Pythonでの正規式の使用は非常に簡単で、** re **モジュールは正規式のサポートを提供します。使用する3つのステップがあります:
- 正規表現文字列をパターンのインスタンスに変換します。
- Patternインスタンスを使用して、照合する文字を処理します。照合結果は** Match **インスタンスです。
- Matchインスタンスを使用して、後続の操作を実行します。
Pythonで一般的に使用されるreメソッドは、*** compile 、 match 、 search 、 findall ***、**の6つです。 * split と sub ***、以下はこれらの6つの方法を説明します。
- compile
compileメソッドの機能は、正規式文字列をPatternインスタンスに変換することです。これには、** pattern と flags **の2つのパラメーターがあります。patternパラメータータイプは文字列タイプであり、正規式文字列、flagsを受け取ります。タイプはintタイプで、受信したのは一致するパターンの番号です。flagsパラメーターはオプションです。デフォルト値は0です(大文字と小文字は区別されません)。モードに一致するフラグは次のとおりです。
| マッチングモード | 説明 |
|---|---|
| re.I | ケースを無視 |
| re.M | マルチラインマッチングモード |
| re.S | 任意のマッチングモード |
| re.L | 事前定義された文字マッチングモード |
| re.U | 限定文字マッチングモード |
| re.V | 詳細モード |
上記の6つのモードは、実際の開発ではめったに使用されません。理解する必要があります。コンパイルの使用は、次のように非常に簡単です。
import re
pattern = re.compile(r'\d')
- match
matchの機能は、Patternインスタンスを使用して文字列の左側から一致させることです。一致する場合はMatchインスタンスを返し、一致しない場合はNoneを返します。
import re
def getMatch(message):
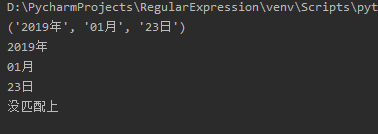
pattern = re.compile(r'(\d{4}[-年])(\d{2}[-月])(\d{2}日{0,1})')
match = re.match(pattern, message)if match:print(match.groups())for item in match.groups():print(item)else:print("一致しませんでした")if __name__ =='__main__':
message ="会議は2019年1月23日に始まります"getMatch(message)
message ="2019年の会議-01-23開催"getMatch(message)
コードでは、一致する文字列グループを取得するために使用される*** groups ***メソッドを使用します。ここに到着した後、多くの読者は、なぜ最初の段落が年、月、日と一致するのか疑問に思うでしょうが、2番目の段落は一致しないのですか?これは、matchメソッドが文字列の先頭から一致するためです。コード操作の結果は次のとおりです。
- search
検索方法は、検索方法が文字列全体に一致することを除いて、一致方法と同じです。前のセクションのコードのgetMatchメソッドを変更して、2番目の段落の年、月、日と一致させます。
import re
def getMatch(message):
pattern = re.compile(r'(\d{4}[-年])(\d{2}[-月])(\d{2}日{0,1})')
match = re.search(pattern, message)if match:print(match.groups())for item in match.groups():print(item)else:print("一致しませんでした")if __name__ =='__main__':
message ="会議は2019年1月23日に始まります"getMatch(message)
message ="2019年の会議-01-23開催"getMatch(message)
上記のコード操作の結果は次のとおりです。
[ 外部リンクの画像転送に失敗しました。ソースサイトにリーチ防止リンクメカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします(img-VmTrXNxa-1575984679614)(https://s2.ax1x.com/2019/12/03/QQ8fR1.png) ]
4. findall
findallメソッドの機能は、文字列全体を照合し、照合したすべての結果をリストの形式で返すことです。
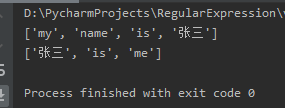
import re
def getMatch(message):
pattern = re.compile(r'\w+')
match = re.findall(pattern, message)if match:print(match)else:print("一致しませんでした")if __name__ =='__main__':
message ="私の名前は張さんです"getMatch(message)
message ="張さんは私です"getMatch(message)
コード実行結果は次のとおりです。
- split
splitメソッドは、指定された文字を使用して文字列を分割します。
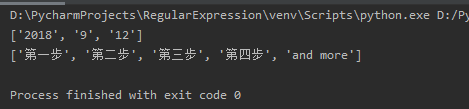
import re
def getMatch(message):
pattern = re.compile(r'-')
match = re.split(pattern, message)if match:print(match)else:print("一致しませんでした")if __name__ =='__main__':
message ="2018-9-12"getMatch(message)
message ="最初の一歩-第二段階-3番目のステップ-4番目のステップ-and more"getMatch(message)
上記のコード操作の結果は次のとおりです。
- sub
subメソッドは、文字列を置き換えるために使用されます。5つのパラメーターを受け入れ、そのうち3つが一般的に使用されます。
- パターン、パターンインスタンス
- 文字列、置き換えられる文字列
- replは、置き換える必要のある新しい文字列または実行する必要のある置換方法を表します
- カウント、置換の数、デフォルトは0で、すべてを置換します
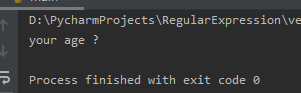
import re
def getMatch(match):return match.group(0).replace(r'年齢','age')if __name__ =='__main__':
message ="あなたの年齢?"
pattern=re.compile(r'\w+')print(re.sub(pattern,getMatch,message))
コード実行結果は次のとおりです。
3、要約####
Pythonの正規式は非常に便利です。上記のコードは直接コピーして、わずかな変更を加えてプロジェクトで使用できます。内容はあまり多くありませんが、主にコードの使い方を説明するために、常連式の書き方を十分に理解し、習得していただきたいと思います。
Recommended Posts