アニメのスクリーンショットを取得するためのPythonクローラーの例
前書き
以前は少し退屈だったので(家にいるのに本当にうんざりしていました)、基本的な理論的研究なしで、ステーションBに行ってパイソンクローラーのビデオをいくつか見ました。つまり、実際の戦闘を直接開始しました。クロールは式を覚えるのと同じだと感じました。さて、少なくとも私は何かを登ることができます、うーん。今日はクローラーコードを共有します。
テキスト
言うことはあまりありませんが、完全なコードに移動するだけです
ps:このコードにはいくつか問題があります。運命の写真に登るたびに、エラーが報告されます。スキップしてみてください。誰かがエラーを見つけて修正するのを手伝ってくれると、私は圧倒されます。ありがたい
import requests as r
import re
import os
import time
file_name ="アニメのスクリーンショット"if not os.path.exists(file_name):
os.mkdir(file_name)for p inrange(1,34):print("--------------------クロール{}ページコンテンツ------------------".format(p))
url ='https://www.acgimage.com/shot/recommend?page={}'.format(p)
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
resp = r.get(url, headers=headers)
html = resp.text
images = re.findall('data-original="(.*?)" ', html)
names =re.findall('title="(.*?)"', html)
# print(images)
# print(names)
dic =dict(zip(images, names))for image in images:
time.sleep(1)print(image, dic[image])
name = dic[image]
# name = image.split('/')[-1]
i = r.get(image, headers=headers).content
try:withopen(file_name +'/'+ name +'.jpg','wb')as f:
f.write(i)
except FileNotFoundError:continue
まず、使用するライブラリをインポートします
import requests as r
import re
import os
import time
次に、クロールするURLを分析します:https://www.acgimage.com/shot/recommend
次の図は、URLの内容です。
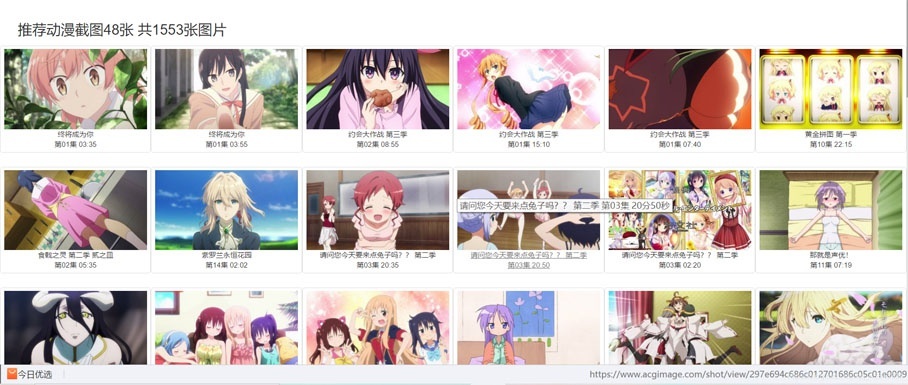
わかりました、URLは決定されました
ヘッダーを見つけましょう
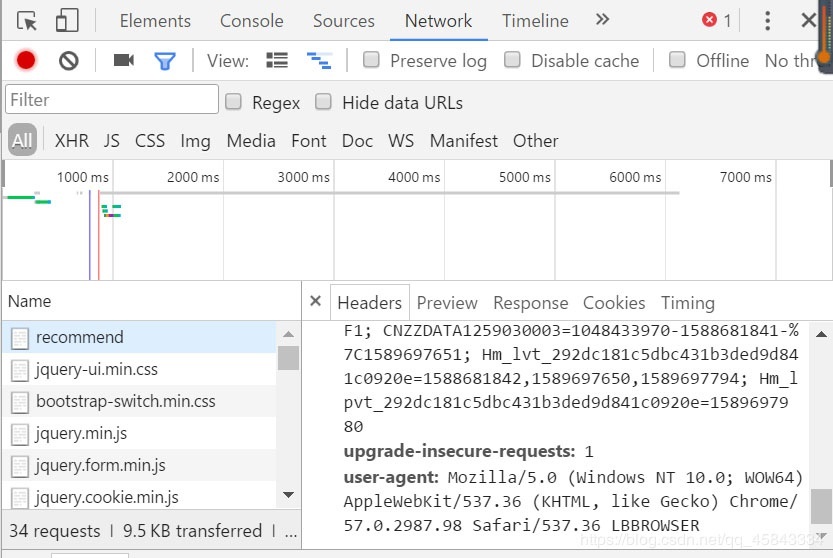
ユーザーエージェントを見つけて、そのコンテンツをヘッダーにコピーします
最初のステップが完了しました
以下はコード表示です
url ='https://www.acgimage.com/shot/recommend?page={}'.format(p)
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
次に、クロールする画像のコンテンツを取得します

あなたは上の写真から写真の場所を見つけることができます:data-origina = below
そして写真の名前:title =コンテンツの下
次に、正規式reを使用して取得します
images = re.findall('data-original="(.*?)" ', html)
names =re.findall('title="(.*?)"', html)
ついに保存するだけ
i = r.get(image, headers=headers).content
withopen(file_name +'/'+ name +'.jpg','wb')as f:
f.write(i)
いくつかの詳細があります
変更ページのように
最初のページのURL:
https://www.acgimage.com/shot/recommend
2ページ目のURL:https://www.acgimage.com/shot/recommend?page = 2
次に、ページの後ろの番号を変更して、対応するページにジャンプします
ページ変更の問題が解決されました
or p inrange(1,34):
url ='https://www.acgimage.com/shot/recommend?page={}'.format(p)
そして、クロールした写真を作成したファイルに入れます
使用したOsライブラリ
file_name ="アニメのスクリーンショット"if not os.path.exists(file_name):
os.mkdir(file_name)
そして、クロールされたウェブサイトに影響を与えないために、スリープ機能が使用されます
クロール速度は遅いですが
しかし、これは守られるべき道徳です
time.sleep(1)
上記は私のクロールプロセスです
上司が私の間違いを解決できることを願っています
どうもありがとう
総括する
これで、Pythonクローラーのアニメスクリーンショットの取得に関するこの記事は終わりです。アニメーションスクリーンショットを取得するための関連するPythonクローラーについては、ZaLou.Cnを検索してください。
Recommended Posts