Python crawler | Cognitive crawler request and response
The advantages and necessity of learning crawlers
Python crawler is to simulate the browser to open the webpage and obtain some data needed in the webpage.
Learning Python crawler is not only full of fun, but also provides basic knowledge of Python programming language. It can be said to be a shortcut to entry into the IT industry, to achieve the two-in-one entertainment and learning. Like reading novels and funny pictures? Looking for a job is still screening corporate needs one by one! There is no reference data for operations and data analysis! In my spare time, I want to make a small demand for a crawler to earn "pocket money", and the crawler will help you get it done quickly.
Python crawlers are recognized as easy to learn, easy to use, and full of fun. Among them, this series of articles will contain theoretical knowledge + diagram code, case + content summary, if you want to deepen your understanding of which knowledge points, you can leave a message in the comment area .
To learn Python crawlers, you must use Python software. Anaconda has its own python compiler, which integrates many Python libraries. Configuration and installation are very convenient. Very suitable for introductory learning.
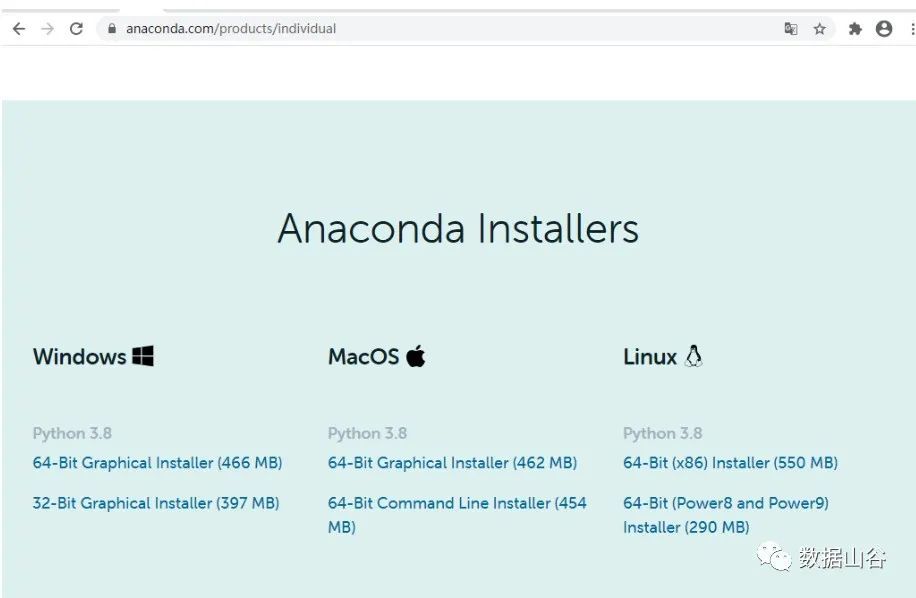
**01 **anaconda software download and installation##
Anaconda software installation official website address: https://www.anaconda.com/products/individual
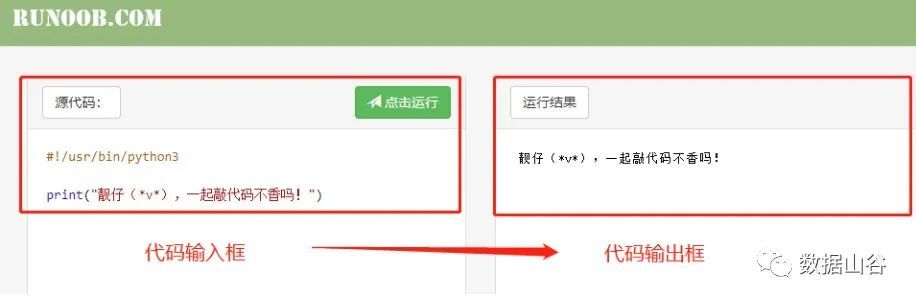
**02 **Python online compiler recommendation##
If you can use your spare time and office is inconvenient, we recommend two online code Python3.0 browser links.
- https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3
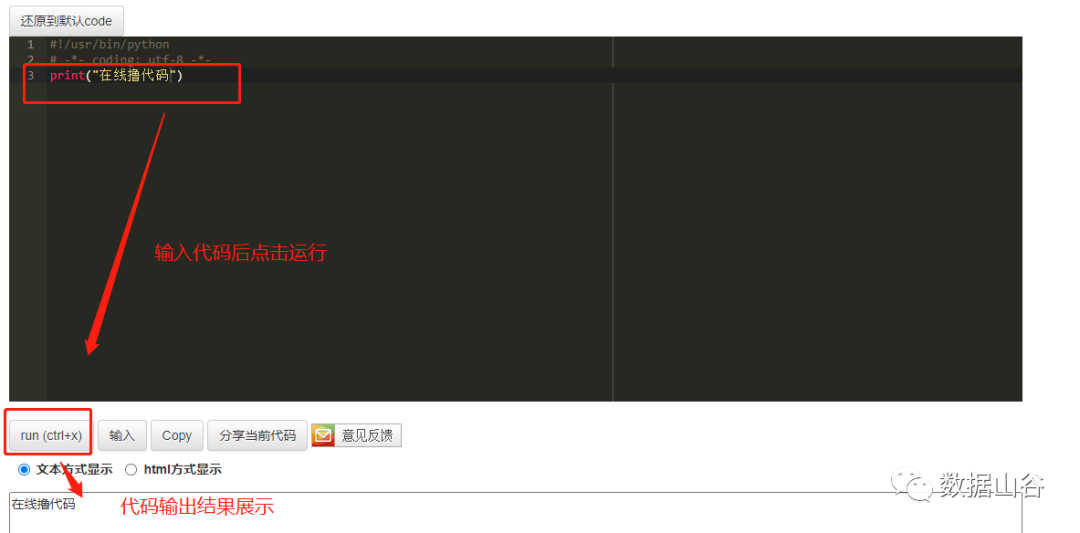
- http://www.dooccn.com/python3/
**03 **Basic Principles of Crawler##
We have prepared our "sharp weapon" tools, and now we are going to teach "gong method secrets". What is a crawler, and how does a crawler crawl data? What is the basic principle of crawlers?
A web spider is a program or script that requests a website according to certain rules and automatically grabs data and information.
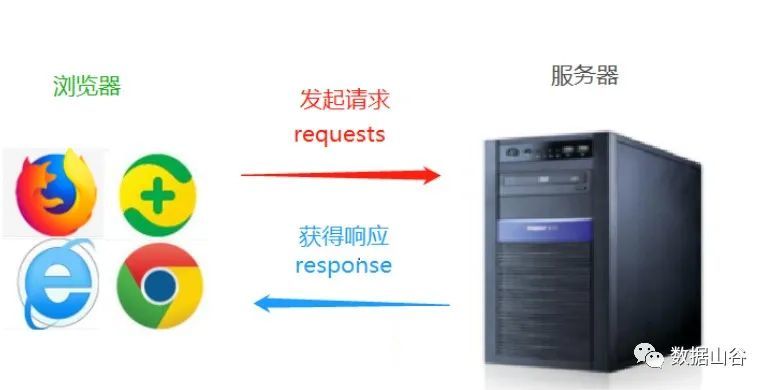
**04 **Basic principle--requests initiate a request##
Initiating a request through the HTTP library target site, that is, sending a request, the request can contain additional headers and other information, waiting for the server to respond.
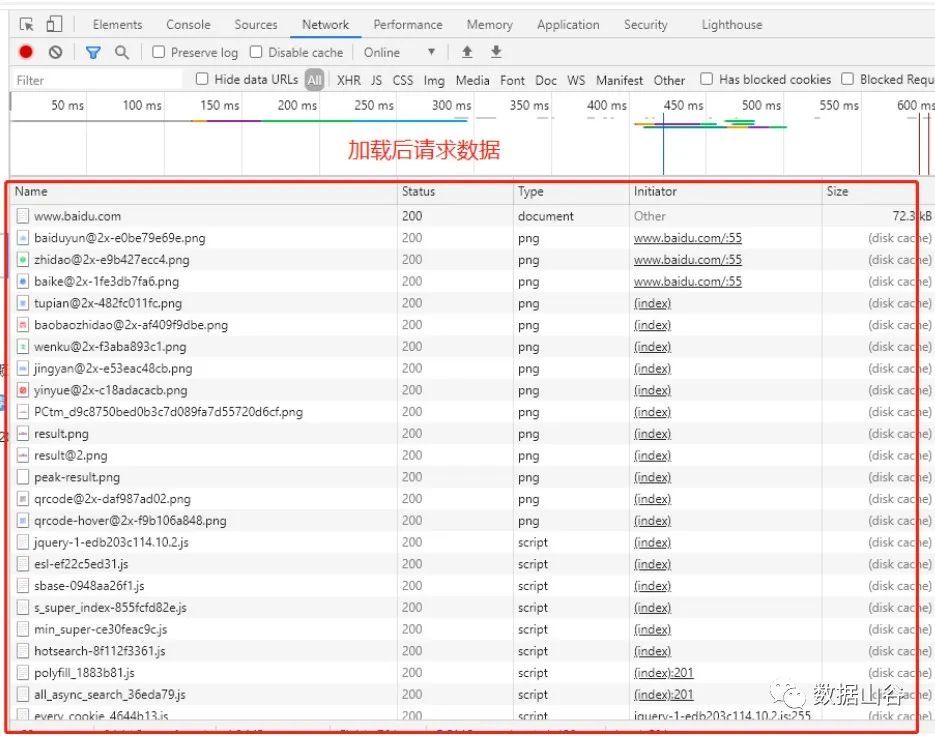
When we open a website link, the process is to send a request from the client (for example: Google, Firefox) to the server (for example: the server where you open the Baidu website), the server receives the request, processes it, and returns it to the client ( Browser), and then saw the displayed data on the browser.
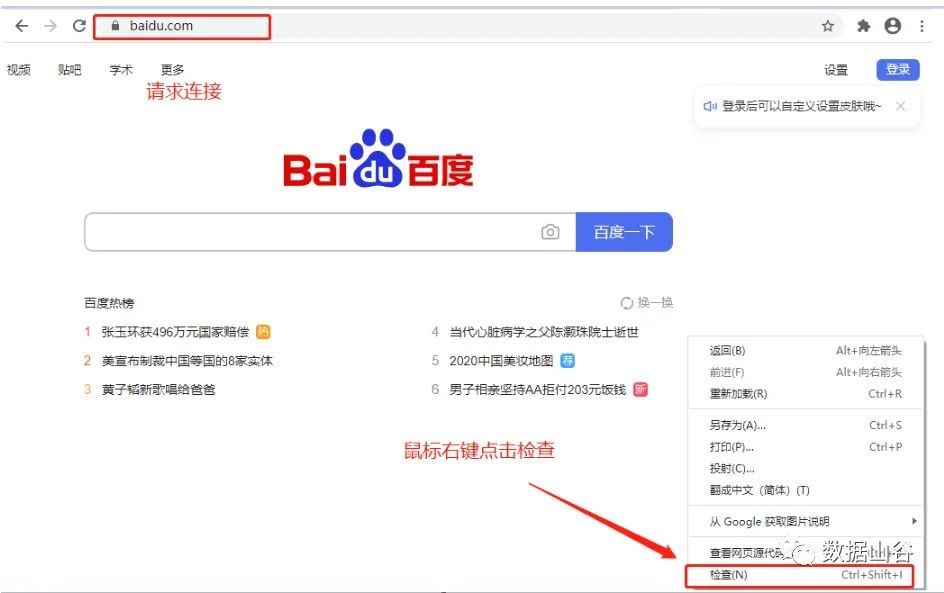
Among them, Elements is to find the source code of the webpage and edit the DOM node and CSS style in real time. After the request of the webpage is initiated, Network analyzes the information of each request resource obtained by the HTTP request. The parameter value in Network is the main content of our study.
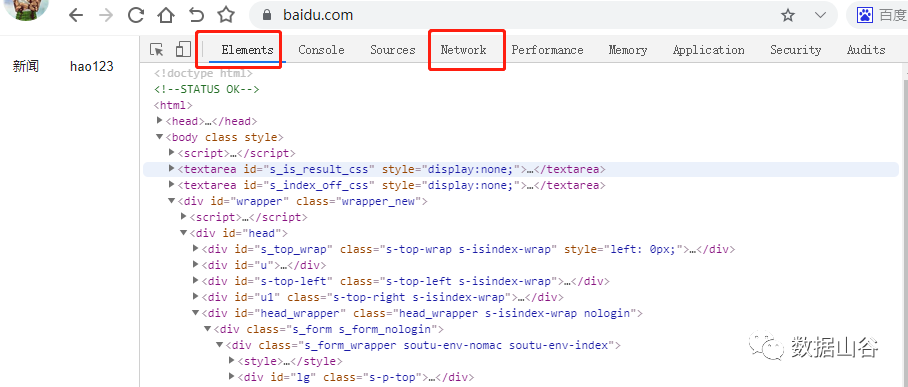
Network related parameters are as follows:
- Header: List HTTP header information, including request url, HTTP method, response status code [for example: 200, 404, etc.], request and response headers and their respective values, request parameters, etc.
- Preview: Preview panel, according to the resource type you selected [JSON, image, text] to display the corresponding preview.
- Response: Display HTTP Response response information, including the content of the resource that has not been formatted.
- Cookie: Display the cookies information in the HTTP Request and Response process of the resource.
- Timing: The detailed information of the resource request takes time.
**05 **Basic principle--requests request method##
Request refers to a request. Enter the link address in the browser and click the search [or press the enter key] to send a request.
There are mainly two types of request methods: Get and Post, as well as Head, Put, Delete, Options, etc. Because the most commonly used methods for crawlers are Post and Get, and other methods are hardly involved, so a brief introduction is given.
- Get is used to read data and request the specified page information. It is to send a request or a certain resource of the server, and return it to the client through a set of HTTP request headers and presentation data (for example: HTML text, pictures, videos, etc.);
- Post is to submit data to the server. At present, almost all data submission operations are completed by Post requests;
- Head only returns HTTP request header information to the client;
- Put and Post are very similar in that they both send data to the server. PUT usually specifies the storage location of the resource, and the data storage location of POST is determined by the server itself;
- Delete refers to deleting a certain resource;
- The Options request is for the client to view the performance of the server;
Examples of requests:
# The url address can be directly specified as the link address when requests are requested
requests.get(url='https://www.baidu.com/s?ie=utf-8&wd=Bald Girl 25')
**06 **Basic principle--standard format followed by URL##
The requested URL [uniform/universal resource identifier] is the full name of the uniform resource locator. The URL is mainly used for two purposes, naming resources and providing the path or location of the resource. In this case, it is called a uniform resource locator, such as a document or picture of a web page , Videos can be specified by URL.
The HTTP protocol: http:// or https://; the link address of the server, for example:
http//baidu.com
Searching for bald girl 25 in the browser, the URL link address has changed, s?ie=utf-8&wd=bald girl 25 in the link specifies the [utf-8] code, and [bald girl 25] specifies the search keyword for you.
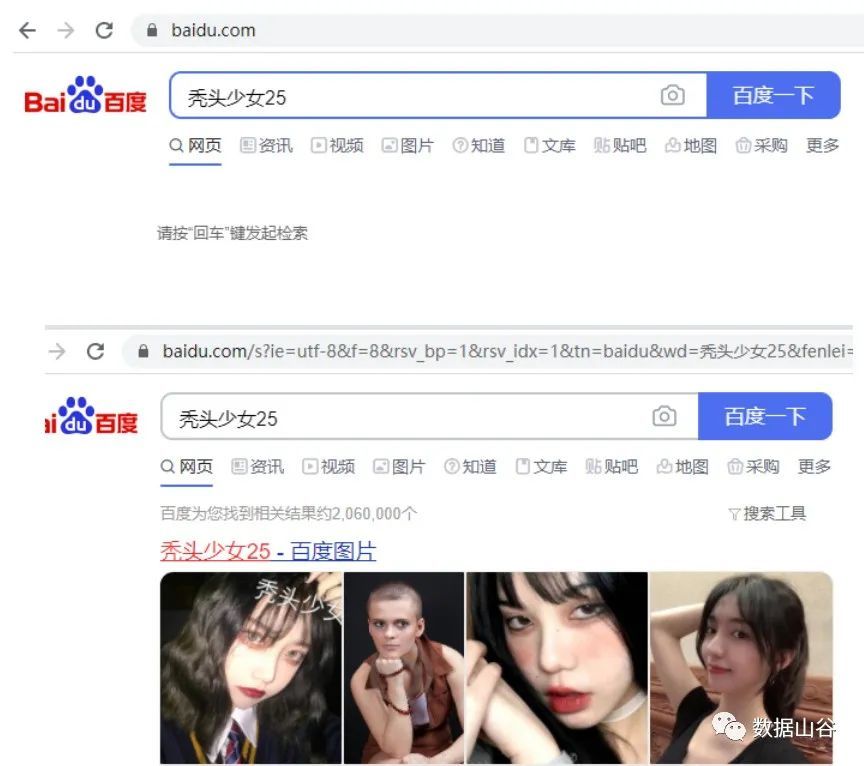
Specify the URL address as follows:
url ="https://www.baidu.com/s?ie=utf-8&wd=Bald Girl 25"
**07 **Basic principle--requests request header##
The request header refers to the header information when requesting, such as User-Agent, host, Cookies and other information. The request body refers to the additional data carried during the request, such as the form data when the form is submitted. Many websites cannot be accessed without a request header when applying for access, or return garbled codes. The simple solution is to pretend to be a browser for access, such as adding a request header to pretend the behavior of the browser.
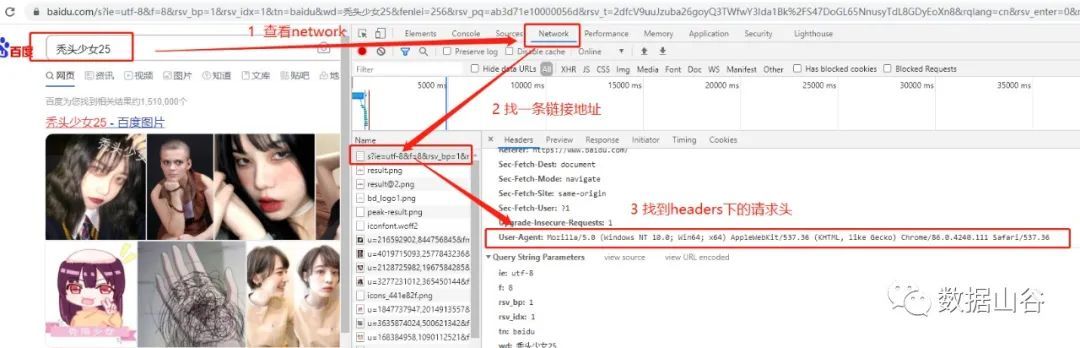
Examples of requests header:
# Define request headers as dictionary type
headers ={"User-Agent":"Mozilla/5.0(Windows NT 10.0; WOW64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
**08 **Basic principle--response get response content##
If the server can respond normally, it will get a Response. The content of the Response is the content of the page to be obtained. The types may be HTML, Json strings, binary data (such as pictures and videos), etc.
Next, let us combine the request, request header and return to complete a simple request response.
**09 **Basic Principles-Request Response Example##
First, you need to install the network request requests module imported into Python [this module needs to be installed in the terminal using pip install requests].
Find the request header in the access link and define it as a dictionary. Use the Get request method to pass in the link address and request header to get the response content. The result returned by response is the access status, such as:<Response [200]> , Response.text returns the entire text content.
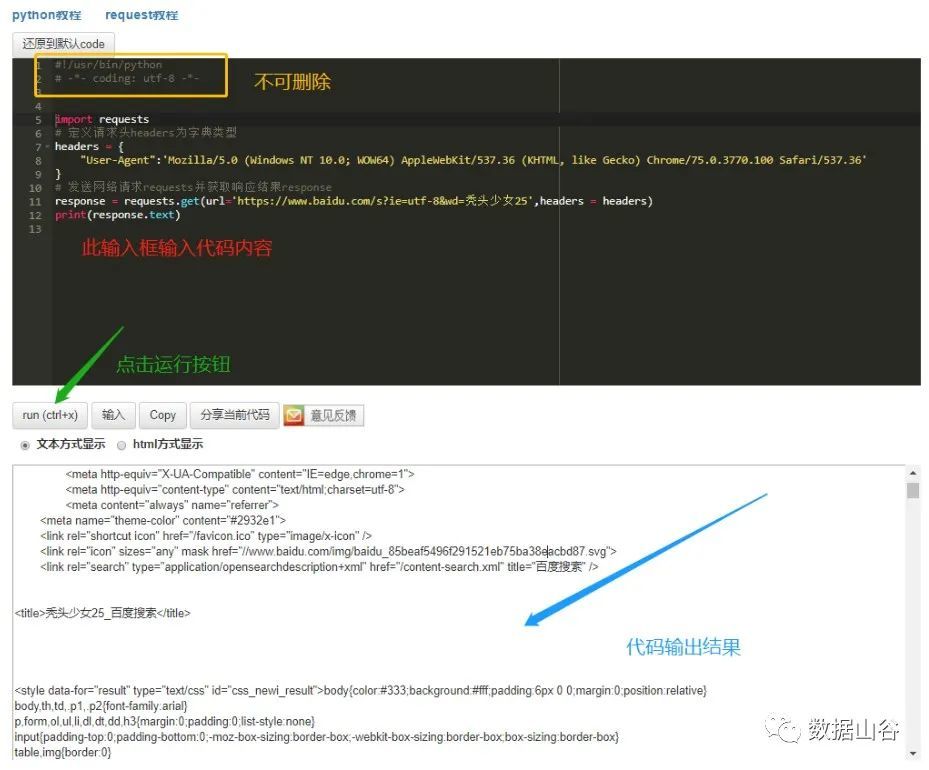
The code example is as follows:
import requests
# Define request headers as dictionary type
headers ={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
# Send network request requests and get the response result response
response = requests.get(url='https://www.baidu.com/s?ie=utf-8&wd=Bald Girl 25',headers = headers)
# Print response will output the return status, print response.text will output web page text
print(response.text)
The operation using the Python online editor is shown as follows:
**10 **Basic Principles-Summary of Knowledge Keywords##
requests (initiating a request), response (obtaining a response), get (reading data, requesting the specified page information), post (submitting data to the server), url (uniform resource locator, specifying the document, image, and video of the webpage) , Hearders (header information when requested).
Recommended Posts