Python3 crawler learning.md
[ TOC]
Directory Structure####
(1) urllib simply crawls the specified website
(2) Scrapy crawler framework
(3) BeautifulSoup crawler analysis
0 x00 urllib simple crawling####
1. Initial crawler
Case 1: urllib package formed by url+lib that comes with Python
#! /usr/bin/python
# Function: The first lesson of crawlers
import urllib.request #Import the specified module in the urllib package
import urllib.parse #Analytical use
# Case 1:
response = urllib.request.urlopen("http://www.weiyigeek.github.io"+urllib.parse.quote("cyber security")) #Url Chinese analysis
html = response.read() #To return a binary string
html = html.decode('utf-8') #Decoding operation
print("Writing to file.....")
f =open('weiyigeek.txt','w+',encoding='utf-8') #turn on
f.writelines(html)
f.close() #shut down
print("Results of the website request:\n",html)
# Case 2:
url ="http://placekitten.com/g/600/600"
response = urllib.request.urlopen(url) #Can be a url string or Request()Object,返回一个Object
img = response.read()
filename = url[-3:]+'.jpg'withopen(filename,'wb+')as f: #Note that binary is stored here
f.write(img)
2. Py crawler implementation/optimization
Case 1: Spider calls Youdao translation interface for Chinese-English translation
#! /usr/bin/python
# Function: Lesson 2 JSON of the crawler/proxy
import urllib.request
import urllib.parse
import json
import time
url ='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'while True:
i =input("Please enter the translated English(Type Q to exit):")if i =='Q' or i =='q':break
data ={}
data['i']= i
data['from']='AUTO'
data['to']='AUTO'
data['doctype']='json'
data['smartresult']='dict'
data['client']='fanyideskweb'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['salt']='15550362545153'
data['sign']='a28b8eb61693e30842ebbb4e0b36d406'
data['action']='FY_BY_CLICKBUTTION'
data['typoResult']='false'
data = urllib.parse.urlencode(data).encode('utf-8')
# Modify Header
# url object request and add request header information
req = urllib.request.Request(url, data) #You can also directly pass in the header object dictionary
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')
req.add_header('Cookie',' YOUDAO_MOBILE_ACCESS_TYPE=1; [email protected]; OUTFOX_SEARCH_USER_ID_NCOO=1911553850.7151666; YOUDAO_FANYI_SELECTOR=ON; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8N5HySla85aD-6kpOw; ___rl__test__cookies=1555036254514; UM_distinctid=16a0f2c1b0b146-0612adf0fe3fd6-4c312c7c-1fa400-16a0f2c1b0c659; SESSION_FROM_COOKIE=fanyiweb')
req.add_header('Referer','http://fanyi.youdao.com/')
# The object returned by the url request
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
jtarget = json.loads(html) #json parsing
print("Translated result:",jtarget['translateResult'][0][0]['tgt'])
time.sleep(1) #Delay 1s to prevent frequent requests
print("Request header information:",req.headers)print("Request URL:",res.geturl())print("status code:",res.getcode())print("Return header message:\n",res.info())
# Please enter the translated English(Type Q to exit):whoami
# Translated result:Show this user information
# Request header information:{'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0','Cookie':' YOUDAO_MOBILE_ACCESS_TYPE=1; [email protected]; OUTFOX_SEARCH_USER_ID_NCOO=1911553850.7151666; YOUDAO_FANYI_SELECTOR=ON; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8N5HySla85aD-6kpOw; ___rl__test__cookies=1555036254514; UM_distinctid=16a0f2c1b0b146-0612adf0fe3fd6-4c312c7c-1fa400-16a0f2c1b0c659; SESSION_FROM_COOKIE=fanyiweb','Referer':'http://fanyi.youdao.com/'}
# Request URL: http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule
# Status code: 200
# Return header message:
# Server: Tengine
# Date: Fri,12 Apr 201903:23:02 GMT
# Content-Type: application/json;charset=utf-8
# Transfer-Encoding: chunked
# Connection: close
# Vary: Accept-Encoding
# Vary: Accept-Encoding
# Content-Language: en-US
3. Crawler parameter settings
Case 3: Use a proxy to request a website
#! /usr/bin/python3
# The third lesson of crawler: proxy general urllib uses proxy ip steps as follows
# Set proxy address
# Create Proxyhandler
# Create Opener
# Install Opener
import urllib.request
import random
url1 ='http://myip.kkcha.com/'
url2 ='http://freeapi.ipip.net/'
proxylist =['116.209.52.49:9999','218.60.8.83:3129']
ualist =['Mozilla/5.0 (compatible; MSIE 12.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',\
' Mozilla/5.0 (Windows NT 6.7; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',\
' Mozilla/5.0 (Windows NT 6.7; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'\
]
proxyip = random.choice(proxylist)
# The proxy settings parameter is a dictionary{'Types of':'Proxy IP:port'}
proxy = urllib.request.ProxyHandler({'http':proxyip})
# Create a custom opener
pro_opener = urllib.request.build_opener(proxy)
pro_opener.addheaders =[('User-Agent',random.choice(ualist))] #Random request header
# Install opener
urllib.request.install_opener(pro_opener)
## Call opener.open(url)
## Use a proxy to make a request
url2 = url2+proxyip.split(":")[0]with urllib.request.urlopen(url1)as u:print(u.headers)
res = u.read().decode('utf-8')print(res)with urllib.request.urlopen(url2)as u:
res = u.read().decode('utf-8')print(res)
3. Exception handling of crawler urllib library
#! /usr/bin/python3
# Function: urllib exception handling
from urllib.request import Request,urlopen
from urllib.error import HTTPError,URLError
urlerror ='http://www.weiyigeek.com'
urlcode ='http://www.weiyigeek.github.io/demo.html'
def url_open(url):
req =Request(url)
req.add_header('APIKEY','This is a password!')try:
res =urlopen(req)except(HTTPError,URLError)as e:ifhasattr(e,'code'): #Need to be placed in front of the reason attribute
print('HTTP request error code:', e.code)print(e.read().decode('utf-8')) #[note]Here is e.read
elif hasattr(e,'reason'):print('Server link failed',e.reason)else:print("Suceeccful!")if __name__ =='__main__':url_open(urlerror)url_open(urlcode)
################## Results of the#####################
# Server link failed[Errno 11001] getaddrinfo failed
# HTTP request error code: 404
# < html>
# < head><title>404 Not Found</title></head>
# < body>
# < center><h1>404 Not Found</h1></center>
# < hr><center>nginx/1.15.9</center>
# < /body>
# < /html>
4. Reptile regular matching
Case 4: Regular and crawler utilization
#! /usr/bin/python3
# Function: regular and crawler
from urllib.request import Request,urlopen,urlretrieve
from urllib.error import HTTPError,URLError
import re
import os
def url_open(url):
req =Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')try:
res =urlopen(req)
html = res.read()
except HTTPError as e:print("Server request error:",e.code())return0
except URLError as e:print("Linked server Fail:",e.reason())return0else:return html
def save_img(url,dir):
i =0
os.mkdir(dir)
os.chdir(os.curdir+'/'+dir)for each in url:
# Will be discarded in the future is not recommended but it is really convenient
urlretrieve(each,str(i)+'.jpg',None)
i +=1else:print("Download completed!\a\a")
def get_img(url):
res =url_open(url).decode('utf-8')if res ==0:exit("Request error exit")
p = r'<img src="([^"]+\.jpg)"'
imglist= re.findall(p,res)save_img(imglist,'test')print(imglist)if __name__ =='__main__':
url ='http://tieba.baidu.com/f?kw=%E9%87%8D%E5%BA%86%E7%AC%AC%E4%BA%8C%E5%B8%88%E8%8C%83%E5%AD%A6%E9%99%A2&ie=utf-8&tab=album'get_img(url)

WeiyiGeek. Regular and crawler utilization
5. Advanced crawler regularization
Case 5: The crawler grabs the ip:port of the proxy website
#! /usr/bin/python3
# The last lesson of urllib crawler
import urllib.request
from urllib.error import HTTPError,URLError
import re
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')try:
res = urllib.request.urlopen(req)except(HTTPError,URLError)as e:print("An error occurred:",e.code,'Wrong page:',e.read())return0else:return res.read().decode('utf-8')
def main1(url,filename):
html =url_open(url)if html ==0:exit("Request error,Program exit!")
exp = r'<td>((?:(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){0,3}(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5]))</td>\n(?:\s*?)<td>(?P<port>\d{0,4})</td>' #This is a pit
regres = re.findall(exp,html,re.M)
iplist =[]for each in regres:
ipport = each[0]+':'+ each[1]
iplist.append(ipport)withopen(filename,'w+',encoding='utf-8')as f:for i inrange(len(iplist)):
f.write(iplist[i]+'\n')if __name__ =='__main__':
url ='https://www.xicidaili.com/nn/'main1(url,'proxyip.txt')
######### Fetch proxy results################
# 119.102.186.99:9999
# 111.177.175.234:9999
# 222.182.121.10:8118
# 110.52.235.219:9999
# 112.85.131.64:9999
0 x02 Scrapy crawler framework####
(1) Sccrapy installation configuration
1.1 Anaconda installation process
This method is a relatively simple way to install Scrapy (especially for Windows). You can use this method to install, or you can use the dedicated platform installation method below.
Anaconda is a Python distribution that contains commonly used data science libraries. If you don't have it installed, you can go to https://www.continuum.io/downloads to download and install the corresponding platform package.
If it is already installed, you can easily install Scrapy via the conda command.
The installation command is as follows:
conda install Scrapy
1.2 Windows installation process
The best way to install under WINDOS is to install through the wheel file; I am using pip3 for WIN10 environment.
# Current environment: win10+py3.7
pip3 install wheel
pip3 install lxml #Pay attention to find the corresponding version-Install lxml
pip3 install zope.interface #Install zope.interfacepip3 install Twisted
pip3 install pywin32
pip3 install Scrapy #Finally install Scrapy
# Install pyOpenSSL
# Download the wheel file from the official website, https://pypi.python.org/pypi/pyOpenSSL#downloads
pip3 install pyOpenSSL-16.2.0-py2.py3-none-any.whl
# Py3.7 One-click upgrade of all libraries
from subprocess import call
from pip._internal.utils.misc import get_installed_distributions
for dist inget_installed_distributions():call("pip install --upgrade "+ dist.project_name, shell=True)
1.3 CentOS、RedHat、Fedora
To ensure that some necessary libraries have been installed, run the following command:
sudo yum groupinstall development tools
sudo yum install python34-devel epel-release libxslt-devel libxml2-devel openssl-devel
pip3 install Scrapy
1.4 Ubuntu、Debian、Deepin
Dependent library installation First make sure that some necessary libraries have been installed, run the following command:
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
pip3 install Scrapy
1.5 Mac OS
Dependent library installation To build Scrapy's dependent library on Mac requires a C compiler and development header files, which are generally provided by Xcode. You can install it by running the following command:
xcode-select –install
pip3 install Scrapy
After verifying the installation, enter it on the command line. If a result similar to the following appears, it proves that Scrapy is installed successfully.
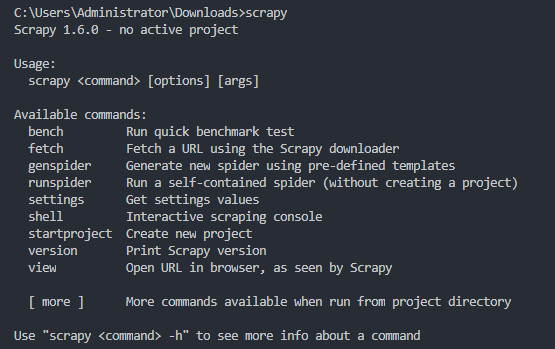
WeiyiGeek.scrapy
(2) Scrapy introduction and use
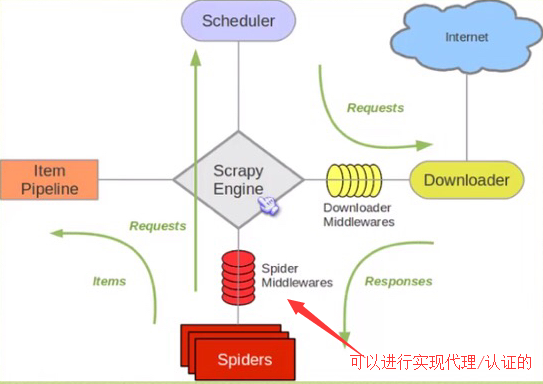
Scrapy is a Python-based crawler framework. It is an application framework written for crawling website data and extracting structural data. It can be used in data mining, information processing or storing historical data and other needs;
There are four steps to crawl a website with Scrapy:
- Create a Scrapy project
- Define Item container: a container for storing crawled data, similar to a dictionary, but with additional protection mechanisms to avoid spelling errors and undefined field errors;
- Writing a crawler
- Storage memory
Frame example picture:
WeiyiGeek.Scrapy
2.1 scrapy common commands
scrapy startproject douban #And initialize a project douban
scrapy genspider douban_spider movie.douban.com #After the establishment of a general crawler file is the crawling address
scrapy crawl douban_spider #Open the scrapy project for crawling,douban_spider project entry name
scrapy shell <url> #The code that executes the test to extract data in the interactive test crawler project
scrapy shell "http://scrapy.org"--nolog #Note that the print log is double quotes
scrapy crawl douban_spider -o movielist.json #Store crawled data in a specific format
scrapy crawl douban_spider -o movielist.cvs
2.2 scrapy project analysis
weiyigeek
│ items.py #Data model file,Container creation object(Serial number,name,description,Evaluation)
│ middlewares.py #Middleware settings(Crawler ip address camouflage)
│ pipelines.py #Write data through the pipeline/On disk
│ settings.py #Project settings(USER-AGENT,Crawl time)
│ __init__.py
├─spiders
│ │ douban_spider.py #Reptile project entrance
│ │ __init__.py
scrapy.cfg #Profile information
2.3 Introduction to scrapy selector
In Scrapy, selectors (selectors) based on an expression mechanism based on XPath and CSS are used. It has four basic methods:
- xpath(): Pass in xpath expression, return the selector list list of all nodes corresponding to the expression; #xml parsing method xpath syntax: response.xpath("//div[@class='article']// ol[@class='grid_view']/li") #Select all the li tags under the div where the class is article and the class is the ol under the grid_view
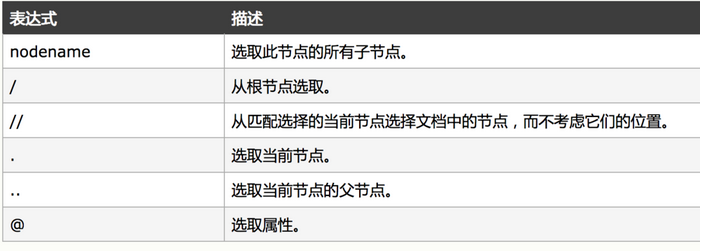
WeiyiGeek.xpath syntax attributes
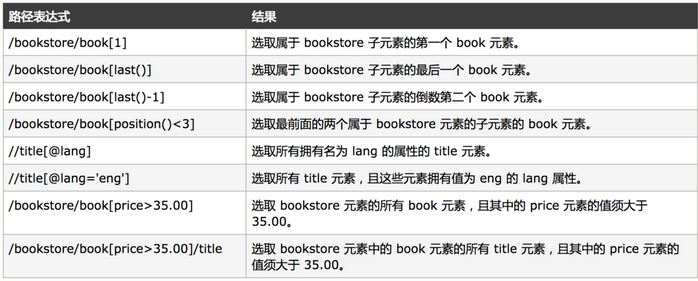
WeiyiGeek. Example
-
css(): Pass in a CSS expression and return the selector list of all nodes corresponding to the expression response.css('.Class name tag::method').extract() #Intercept string
-
extract(): serialize the node as a unicode string and return list
-
re(): Extract the data according to the regular expression passed in and return a list of unicode strings
2.4 scrapy interactive debugging
Description: Scrapy terminal is an interactive terminal for you to try and debug your crawling code without starting the spider;
- shelp()-Print the help list of available objects and shortcut commands
- fetch(request_or_url)-Get a new response according to the given request (Request) object or URL, and update related objects
- view(response)-Open the given response in the browser of this machine and save the downloaded html.
It will add a tag to the response body so that external links (such as pictures and css) can be displayed correctly. Note that this operation will create a temporary file locally, and the file will not be automatically deleted. - crawler-the current Crawler object.
- spider-The spider that processes the URL. If there is no Spider for the current URL, it is a Spider object.
- request-The Request object of the recently obtained page. You can use replace() to modify the request. Or use the fetch shortcut to get a new request.
- response-The Response object containing the most recently obtained page.
- sel-The Selector object constructed based on the recently obtained response.
- settings-current Scrapy settings
Case:
> scrapy shell "http://movie.douban.com/chart">>>help(command)>>> request
< GET http://www.weiyigeek.github.io>> response.url
' https://movie.douban.com/chart'>>> response
<200 https://movie.douban.com/chart>>>> response.headers #Request header
>>> response.body #Web page source code
>>> response.text
>>> response.xpath('//title') #Return an xpath selector
>>> response.xpath('//title').extract() #xpath expression extract content
['< title>\n Douban Movie Ranking\n</title>']
response.xpath('//title/text()').extract() #Extract text information
['\ n Douban Movie Ranking\n']>>> response.xpath("//div[@class='pl2']//a").extract_first().strip() # extract_first extract the first matching data
'< a href="https://movie.douban.com/subject/25986662/" class="">\n crazy alien\n / <span style="font-size:13px;">Crazy Alien</span>\n </a>'
# CSS for extraction
>>> sel.css('.pl2 a::text').extract_first().strip()'Crazy alien\n /'
# How to solve the problem of extracting the header information of the request from a website:
from scrapy import Request #Import module
>>> data =Request("https://www.taobao.com",headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"})>>>fetch(data) #Get the requested website
2017- 11- 3022:24:14[ scrapy.core.engine] DEBUG:Crawled(200)<GET https://www.taobao.com>(referer: None)>>> sel.xpath('/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]')[<Selector xpath='/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]' data='<a href="https://www.taobao.com/markets/'>]>>> data.headers #View the set header
{ b'User-Agent':[b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'], b'Accept-Encoding':[b'gzip,deflate']}
# Match multiple strings for iteration loop
>>> fetch('http://weiyigeek.github.io')>>> title = response.css('.article-header a::text').extract()>>>for each in title:...print(each)...
Summary of Security Device Policy Bypass Technology.md
Win platform security configuration.md
Python3 regular expression special symbols and usage.md
Python3 crawler learning.md
Disk high-availability solution(DBA).md
Nodejs introductory learning 1.md
Node.js introduction and installation.md
Domain Control Security Fundamentals.md
Win intranet penetration information search.md
Highly available service solutions(DBA).md
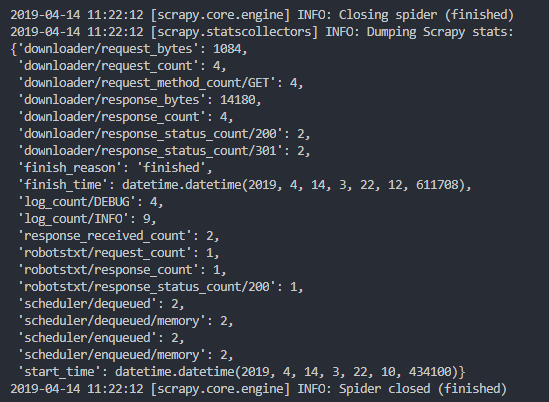
WeiyiGeek.scrapyshell
2.4 Simple example of scrapy
scrapy startproject weiyigeek
scrapy genspider blog_spider www.weiyigeek.github.io
'''
items.Edit the data model file of the object captured by py
'''
import scrapy
classWeiyigeekItem(scrapy.Item):
# items.py set the object to be grabbed edit the data model file,Create object(Serial number,name,description,Evaluation)
title = scrapy.Field() #title
href = scrapy.Field() #Title address
time = scrapy.Field() #Creation time
'''
blog_spider.py crawler processes the main file
'''
# - *- coding: utf-8-*-import scrapy
from weiyigeek.items import WeiyigeekItem #Import attributes in the class in the data container(Actually import the items in the project.py)classBlogSpiderSpider(scrapy.Spider):
name ='blog_spider' #Crawler name
allowed_domains =['www.weiyigeek.github.io'] #Domains allowed by the crawler
start_urls =['http://www.weiyigeek.github.io/','http://weiyigeek.github.io/page/2/'] #Crawler crawling data address,To the scheduler
# Parse the web page object returned by the request
def parse(self, response):
sel = scrapy.selector.Selector(response) #scrapy selector
sites = sel.css('.article-header') #Use css selector to select
items =[]for each in sites:
item =WeiyigeekItem() #Data container class
item['title']= each.xpath('a/text()').extract()
item['href']= each.xpath('a/@href').extract()
item['time']= each.xpath('div[@class="article-meta"]/time/text()').extract() #Note the use here
items.append(item)
# Output to the screen
print(">>>",item['title'],item['href'],item['time'])return items
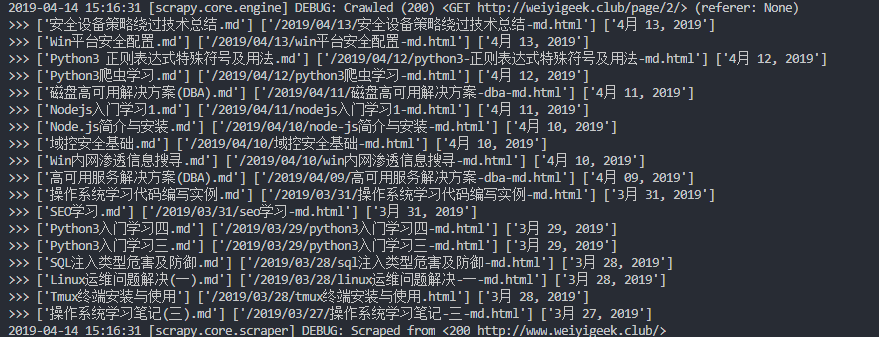
WeiyiGeek. Execution results
(3) Scrapy example project#####
Description: Crawl iQiyi’s TOPS250 project;
# Step1.Create spider project and initialize crawler name
scrapy startproject douban
scrapy genspider douban_spider movie.douban.com
'''
Step2.Modify the items template file
'''
classDoubanItem(scrapy.Item):
serial_number = scrapy.Field() #Serial number
movie_name = scrapy.Field() #Movie title
introduce = scrapy.Field() #Introduction
star = scrapy.Field() #Star rating
evaluate = scrapy.Field() #Evaluation
describle = scrapy.Field() #description
'''
Step3.Modify the crawler file
'''
# - *- coding: utf-8-*-import scrapy
from douban.items import DoubanItem #Import container douban\items.py
classDoubanSpiderSpider(scrapy.Spider):
name ='douban_spider' #The name of the crawler
allowed_domains =['movie.douban.com'] #Domains allowed by the crawler
start_urls =['https://movie.douban.com/top250'] #Crawler crawling data address,To the scheduler
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")for i_item in movie_list:
douban_item =DoubanItem() #Model initialization
# Take text()End means to get its information,extract_first()Filter the first value of the result
douban_item['serial_number']= i_item.xpath(".//div[@class='item']//em/text()").extract_first() #Rank
douban_item['movie_name']= i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first() #name
descs = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract_first() #
# Dealing with space issues
desc_str =''for i_desc in descs:
i_desc_str ="".join(i_desc.split())
desc_str += i_desc_str
douban_item['introduce']= desc_str #Introduction
douban_item['star']= i_item.xpath(".//span[@class='rating_num']/text()").extract_first() #star
douban_item['evaluate']= i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() #Number of evaluations
douban_item['describle']= i_item.xpath(".//p[@class='quote']/span/text()").extract_first() #description
yield douban_item #Press the returned result into item Pipline for processing (emphasis)
# Process next page function
next_link = response.xpath("//div[@class='article']//span[@class='next']/link/@href").extract()if next_link:
next_link = next_link[0]yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse) #(Emphasis)
# Explanation:
# 1 After each for loop ends,Need to get the next page link:next_link
# 2 If there is no next page when the last page is reached,Need to judge
# 3 Next address stitching:When you click on the second page, the page address is https://movie.douban.com/top250?start=25&filter=
# 4 callback=self.parse :Request callback
'''
Step4.Modify the configuration file
'''
$ grep -E -v "^#" settings.py
BOT_NAME ='douban' #project name
SPIDER_MODULES =['douban.spiders']
NEWSPIDER_MODULE ='douban.spiders'
USER_AGENT =' Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY =0.5
# Channel settings
ITEM_PIPELINES ={'douban.pipelines.DoubanPipeline':300,}
# Download middleware settings call
DOWNLOADER_MIDDLEWARES ={'douban.middlewares.my_proxy':543,'douban.middlewares.my_useragent':544,}
# Set up mongo_db database information
mongo_host ='172.16.0.0'
mongo_port =27017
mongo_db_name ='douban'
mongo_db_collection ='douban_movie''''
Step5.Modify pipelines.py
'''
# - *- coding: utf-8-*-import pymongo
from douban.settings import mongo_host ,mongo_port,mongo_db_name,mongo_db_collection
classDoubanPipeline(object):
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
def process_item(self, item, spider):
data =dict(item)
self.post.insert(data)return item
'''
Step6.Mid-price document:middlewares.py
'''
# ip proxy intermediate price compilation(Crawler ip address camouflage)/Header User-Agent disguise randomly
import base64
import random
# Adding method to the end of the file:classmy_proxy(object): #proxy
def process_request(self,request,spider):
request.meta['proxy']='http-cla.abuyun.com:9030'
proxy_name_pass = b'H622272STYB666BW:F78990HJSS7'
enconde_pass_name = base64.b64encode(proxy_name_pass)
request.headers['Proxy-Authorization']='Basic '+ enconde_pass_name.decode()
# Explanation:Purchase http tunnel list information according to Abu Cloud registration
# request.meta['proxy']:'server address:The port number'
# proxy_name_pass: b'Certificate No:Key',The beginning of b is the string base64 processing
# base64.b64encode():Variables do base64 processing
# ' Basic ':There must be a space after basic
classmy_useragent(object): # userAgent
def process_request(self, request, spider):
UserAgentList =["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5","Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5","Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre","Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",]
agent = random.choice(UserAgentList)
request.headers['User_Agent']= agent
## Run scrapy crawl and you will see the middle key method set above
You can also save the data to a json file or csv file
- scrapy crawl douban_spider -o movielist.csv
- scrapy crawl douban_spider -o movielist.json
Scrapy into the pit
- Q: There are dependency problems when installing twisted? *

WeiyiGeek. Question 1
Solution: [Official website download twisted whl package installation] (https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted)
Twisted‑19.2.0‑cp37‑cp37m‑win_amd64.whl
Work daily learning
- Function: realize the use of schools to find provinces*
#! /usr/bin/env python3
# - *- coding: utf-8-*-
# Function: School area analysis
import urllib.request
import urllib.parse
from lxml import etree
number =[]
name =[]
file1 =open('2.txt','r',encoding='utf-8')for i in file1:
keyvalue = i.split(" ")
number.append(str(keyvalue[0]))
name.append(str(keyvalue[1]))
file1.close()
def test1(html,parm=""):
dom_tree = etree.HTML(html)
links = dom_tree.xpath("//div[@class='basic-info cmn-clearfix']/dl/dd/text()")for i in links:for v inrange(0,len(number)):if(i.find(name[v][:2])!=-1):return number[v]+ name[v]+parm+"\n"return"Not found(Or overseas)"
file =open('1.txt','r+',encoding='utf-8')
file.seek(0,0)for eachline in file:
url ="https://baike.baidu.com/item/"+urllib.parse.quote(eachline[6:]);
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8') #Decoding operation
f =open('c:\\weiyigeek.txt','a+',encoding='utf-8') #turn on
res =test1(html,str(eachline[6:]))
f.writelines(res)
f.close() #shut down
file.close()
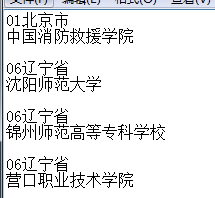
WeiyiGeek. Post-execution effect
Recommended Posts