python_ crawler basic learning
——Wang Yuyang—take notes based on the mooc course summary (Code_boy)
Requests library: automatically crawl to HTML pages, automatic network request submission
robots.txt: Web crawler exclusion criteria
Beautiful Soup library: parse HTML pages (install bs4 in pycharm)
re regular expression: the choice of HTML data analysis
requests.get(url[,params = None,**kwargs])
url: Get the URL link of the webpage
params: extra parameters in url, dictionary or byte stream format, optional
**kwargs: 12 parameters to control access
Properties of the Response object {0.0.py}
| Properties | Description |
|---|---|
| r.status_code | Return status of HTTP request, 200 means connection is successful, 404 means failure |
| r.text | The string form of the HTTP response content, (ie: the page content corresponding to the url) |
| r.encoding | The encoding method of the response content guessed from the HTTP header |
| r.apparent_encoding | The response content encoding method analyzed from the content (alternative encoding method) |
| r.content | Binary form of HTTP response content |
Examples:
1 r = requests.get("http://www.baidu.com")2print(r.status_code) #Return status code (content value is '200' indicating successful access)
3 # Result: 2004print(r.text) #Returns the string form of the response content
5 # Result: [ie-Source code content of baidu homepage (with garbled characters)]
6 print(r.encoding) #The encoding method of the response content guessed from the HTTP header
7 # Result: ISO-8859-1 The coding standard (method) of the baidu page
8 print(r.apparent_encoding) #Coding method of response content analyzed from content[Alternative encoding]9 #Result: utf-810print(r.content) #Binary form of content
11 # Result: I don’t understand anyway
1213 r.encoding ='utf-8' #(utf-8 is r.apparent_encoding result)14print(r.text)15 #As a result, the human-readable response content is mainly through r.the redefinition type of encoding, and r.text refers to the encoding method of encoding
General crawler code framework:
1 def getHTMLText(url):2try:3 r = requests.get(url,timeout =30)4 r.raise_for_status() #If the status is not 200, an exception is thrown: requests.HTTPError(r.status_code)5 r.encoding = r.apparent_encoding
6 return r.text
7 except:8return"Produces an exception"910if __name__ =="__main__":11 url ='http://www.baidu.com'12print(getHTMLText(url))
Requests library exception
| Exception | description |
|---|---|
| requests.ConnectionError | Network connection error exception, (such as DNS query failure, connection refused, etc.) |
| requests.HTTPError | HTTP Error Exception |
| requests.URLequired | URL missing exception |
| requests.TooManyRedirects | Exceeded the maximum number of redirects, a redirect exception occurred |
| requests.ConnectTimeout | Connection to remote server timed out exception |
| requests.Timeeout | Request URL timeout, timeout exception occurred |
| r.raise_for_status | If it is not 200, an exception occurs: requetst.HTTPError |
Examples of general code framework:
1 def getHTMLText(url):2try:3 r = requests.get(url,timeout =30)4 r.raise_for_status() #If the status is not 200, an exception is thrown: requests.HTTPError(r.status_code)5 r.encoding = r.apparent_encoding
6 return r.text
7 except:8return"Produces an exception"910if __name__ =="__main__":11 url ='http://www.baidu.com'12print(getHTMLText(url))
The 7 main methods of the Requests library
| Method | Description |
|---|---|
| requests.request() | Construct a request to support the basic method of the following methods |
| requests.get() | The only way to get HTML pages, corresponding to HTTP GET |
| requests.head() | Method to get HTML page header information, corresponding to HTTP HEAD |
| requests.post() | The method of submitting POST requests to HTML pages, corresponding to HTTP POST |
| requests.put() | The method of submitting PUT requests to HTML pages, which corresponds to HTTP PUT |
| requests.patch() | Submit a partial modification request to the HTML page, which corresponds to the PATCH of HTTP |
| requests.delete() | Submit a delete request to the HTML page, corresponding to HTTP DELETE |
HTTP protocol:
HTTP, Hypertext Transfer Protocol, Hypertext Transfer Protocol
HTTP is a stateless application layer protocol based on the "request and response" model.
HTTP uses URL to locate network resource identification
URL format: http://host[:port][path]
host: legal Internet host domain name or IP address
port: port number (default port is 80)
path: the path of the requested resource
HTTP protocol operations on resources:
| Method | Description |
|---|---|
| GET | Request to get the resource at URL location |
| HEAD | Request to get the response information report of the URL location resource, that is, get the header information of the resource |
| POST | Request to append new data to the resource at the URL location |
| PUT | Request to store a resource at the URL location, overwriting the resource at the original URL location |
| PATCH | Request a partial update of the resource at the URL location, that is, change part of the content of the resource |
| DELETE | Request to delete resources stored in URL location |
Understand the difference between PATCH and PUT
Suppose there is a set of data UserInfo in the URL location, including 20 fields such as UserID and UserName
Requirement: User modified UserName, others remain unchanged
-
Using PATCH, only submit partial update request of UserName to URL [Add]
-
With PUT, all 20 fields must be submitted to the URL together, and the unsubmitted fields are deleted [overwrite and append]
1 # the head of the requests library()Method (request to obtain the response information report of the URL location resource, that is, obtain the header information of the resource)2 r = requests.head('http://httpbin.org/get')3print(r.headers)4'''
5 result:
6{' Connection':'keep-alive','Server':'gunicorn/19.9.0',7'Date':'Thu, 22 Nov 2018 03:52:22 GMT','Content-Type':8'application/json','Content-Length':'268',9'Access-Control-Allow-Origin':'*',10'Access-Control-Allow-Credentials':'true','Via':'1.1 vegur'}11'''
12 # requests library post()Method (request to append new data to the resource at the URL location)
13 payload ={'key1':'value1','key2':'value2'}14 r = requests.post('http://httpbin.org/post',data = payload)15 #POST a dictionary to the URL, automatically encode the unform (form)
16 print(r.text)17'''
18 result:
19{20" args":{},21"data":"",22"files":{},23"form":{24"key1":"value1",25"key2":"value2"26},27"headers":{28"Accept":"*/*",29"Accept-Encoding":"gzip, deflate",30"Connection":"close",31"Content-Length":"23",32"Content-Type":"application/x-www-form-urlencoded",33"Host":"httpbin.org",34"User-Agent":"python-requests/2.20.1"35},36"json":null,37"origin":"106.111.147.213",38"url":"http://httpbin.org/post"39}40'''
41 r = requests.post('http://httpbin.org/post',data ='abc')42 #POST a string to the URL automatically encoded as data
43 print(r.text)44'''
45 result:
46{47" args":{},48"data":"abc",49"files":{},50"form":{},51"headers":{52"Accept":"*/*",53"Accept-Encoding":"gzip, deflate",54"Connection":"close",55"Content-Length":"3",56"Host":"httpbin.org",57"User-Agent":"python-requests/2.20.1"58},59"json":null,60"origin":"106.111.147.213",61"url":"http://httpbin.org/post"62}63'''
64 # put of the requests library()Method (request to store a resource to the URL location, overwriting the resource at the original URL location)
65 payload ={'key1':'value1','key2':'value2'}66 r = requests.put('http://httpbin.org/put',data = payload)67 #PUT a dictionary to the URL, automatically encode the unform (form)[The difference with post is that it will overwrite the original content]68print(r.text)69'''
70 result:71{72"args":{},73"data":"",74"files":{},75"form":{76"key1":"value1",77"key2":"value2"78},79"headers":{80"Accept":"*/*",81"Accept-Encoding":"gzip, deflate",82"Connection":"close",83"Content-Length":"23",84"Content-Type":"application/x-www-form-urlencoded",85"Host":"httpbin.org",86"User-Agent":"python-requests/2.20.1"87},88"json":null,89"origin":"106.111.147.213",90"url":"http://httpbin.org/put"91}92'''
Method function and use of requests library:
requests.request(method,url,**kwargs)
method: request method, corresponding to 7 methods such as get/put/post
r = requests.request(‘GET’,url,**kwargs)
r = requests.request(‘HEAD,’url,**kwargs)
r = requests.request(‘POST’,url,**kwargs)
r = requests.request(‘PUT’,url,**kwargs)
r = requests.request(‘PATCH’,url,**kwargs)
r = requests.request(‘delete’,url,**kwargs)
r = requests.request('OPTIONS',url,**kwargs)#Get relevant parameters from the service
url: The url link of the page to be obtained
**kwargs: parameters to control access, a total of 13 (optional)
params: dictionary or byte sequence, added as a parameter to the url ( link part system will add a'?')
data: dictionary, byte sequence or file object, as the content of Request
json: data in json format as the content of the request
headers: dictionary, HTTP custom headers
cookies: dictionary or CookieJar, cookie in Request *
auth: tuple, support HTTP authentication function*
files: dictionary type, transfer files
timeout: Set the timeout time, unit: seconds (if the time is returned, it returns an exception)
proxies: dictionary type, set access proxy server, can increase login authentication
pxs={'http':'http://user:[email protected]:1234'}
r = requests.request('GET','http://www.baidu.com',proxies = pxs)
allow_redirects: True/False, the default is True, redirect switch
stream: True/False, the default is True, the content is downloaded immediately
verify: True/False, the default is True, verify the SSL certificate switch
cert: local SSL certificate path
*requests.get(url,params=None,kwargs)
url: URL link of the page
params: additional parameters in url, dictionary or byte stream format, optional
**kwargs: 12 parameters that control access
**requests.head(url,kwargs)
url: URL link of the page
**kwargs: 13 parameters to control access
**requests.post(url,data=None,json=None,kwargs)
url: URL link of the page
data: dictionary, byte sequence or file, the content of Request
json: data in JSON format, the content of the request
**kwargs: 11 control access parameters (data and json have been used)
**requests.put(url,data=None,kwargs)
url: URL link of the page
data: dictionary, byte sequence or file, the content of Request
**kwargs: 12 parameters that control access
**requests.patch(url,data=None,kwargs)
url: URL link of the page
data: dictionary, byte sequence or file, the content of Request
**kwargs: 12 parameters that control access
**requests.delete(url,kwargs)
url: delete the url link of the page
**kwargs: 13 parameters to control access
The size of the web crawler:
| Style | Crawl web pages, fun web pages | Crawl websites, crawl series of websites | Crawl the whole network |
|---|---|---|---|
| Scale | Small scale, small amount of data, insensitive to crawling speed (>=90%) | Medium scale, large scale of data, sensitive to crawling speed | Large scale, search engine, crawling speed is critical |
| Common libraries | requests library | scrapy library | custom development |
Harassment by web crawlers:
Crawlers use fast functions to access web servers, it is difficult for the server to provide resources suitable for high-speed crawlers
Limited to the purpose of writing level, web crawlers will bring huge resource overhead to web servers
Legal risks of web crawlers:
The data on the server has property ownership
Profit after the data obtained by the web crawler will bring legal risks
Web crawler == "Crawl also has the right way"
Limit crawler conditions:
Source review: Judging User-Agent to restrict
·Check the User-Agent domain of the visiting HTTP protocol header, and only respond to the visit of the browser or friendly crawler
Announcement: Robots Agreement*****
Robots Exclusion Standard Web crawler exclusion standard
Role: Inform all crawlers of the crawling strategy of the website and require crawlers to comply
Format: robots.txt file in the root directory of the website
JD Robots Agreement: (https://www.jd.com/robots.txt)
| User-agent: * Disallow: /?* Disallow: /pop/.html Disallow: /pinpai/.html?* User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow : / User-agent: WochachaSpider Disallow: / | Should any crawler obey to not allow access? The path at the beginning is not allowed to access /pop/.html is not allowed to access /pinpai/.html?* EtaoSpider, HuihuiSpider, GwdangSpider, WochachaSpider are identified as malicious crawlers and are prohibited from crawling any content |
|---|
Basic syntax of Robots protocol:
| # | Notes |
|---|---|
| * | Represents all |
| / | Represents the root directory |
| User-agent: * | Specify crawlers (* means all crawlers) |
| Disallow:/ | Directory not allowed to crawler |
Crawler basic 1 example: (code + summary) {0.1.py}
1 # Example: crawling Jingdong goods
2 import requests
3 import os
4'''
5 r = requests.get('https://item.jd.com/36826348085.html?jd_pop=14982c1c-64d9-4bab-ac5c-e40af7ce62a2&abt=0')6print(r.status_code)7print(r.encoding)8print(r.text[:1000])9 #Example: crawling Amazon
1011 kv ={'User-Agent':'mozilla/5.0'} #Create access headers (pretend to be a browser)
12 r=requests.get('https://www.amazon.cn/dp/B073LJR2JF/ref=cngwdyfloorv2_recs_0/459-8865541-1481366?pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=desktop-2&pf_rd_r=AT12APC0BDJ216Y55VSR&pf_rd_r=AT12APC0BDJ216Y55VSR&pf_rd_t=36701&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_i=desktop',headers=kv)13print(r.status_code)14print(r.text[:1000])15print(r.request.headers)16'''
17 # Example: Baidu search
18 # Baidu search search url: http://www.baidu.com/s?wd:{Search content}19'''
20 keyword ='python'21try:22 kv ={'wd':keyword}23 r = requests.get('http://www.baidu.com/s',params = kv)24print(r.request.url)25 r.raise_for_status()26print(len(r.text))27 except:28print("Crawl failed")29'''
30 # Case: Web image crawling and storage
31'''
32 url ="http://img0.dili360.com/pic/2018/09/21/5ba4a6af2af103q29157813_t.jpg"33 rot ="E://"34 path = rot + url.split('/')[-1] #Specify the image save name as the suffix in the url address (url)
35 try:36if not os.path.exists(rot): #Check if there is a rot directory, create it if not
37 os.mkdir(rot) #Create rot directory
38 if not os.path.exists(path): #Check if there is a path file in the path directory
39 r = requests.get(url) #Link url address
40 # withopen(path,'wb')as f: #Another way to open and store files(???)41 f =open(path,'wb') #open a file
42 f.write(r.content) #r.content The binary content of the response URL
43 f.close()44print("Saved successfully")45else:46print("File already exists")47 except:48print("Crawl failed")49'''
50 # Crawl a single video
51'''
52 url ="http://video.pearvideo.com/mp4/adshort/20181121/cont-1480150-13269168_adpkg-ad_hd.mp4"53 rot ="E://"54 path = rot + url.split('/')[-1] #Specify the suffix name of the video save name (url) in the url address
55 try:56if not os.path.exists(rot): #Check if there is a rot directory, create it if not
57 os.mkdir(rot) #Create rot directory
58 if not os.path.exists(path): #Check if there is a path file in the path directory
59 r = requests.get(url) #Link url address
60 # withopen(path,'wb')as f: #Another way to open and store files(???)61 f =open(path,'wb') #open a file
62 f.write(r.content) #r.content The binary content of the response URL
63 f.close()64print("Saved successfully")65else:66print("File already exists")67 except:68print("Crawl failed")69'''
70 # Automatic query of IP address attribution
71 # IP168 query link url: http://ip138.com/ips138.asp?ip=123.125.6.1&action=272 #From the above: IP query url: http://ip138.com/ips138.asp?ip=ip address
7374 url ="http://ip138.com/ips138.asp"75 ip ={"ip":"106.111.147.213"}76try:77 r = requests.get(url,params=ip)78 r.raise_for_status()79print(r)80 #print(r.status_code)81 r.encoding = r.apparent_encoding
82 print(r.text)83 except:84print("Crawl failed")
Small summary:
It can be seen from the example that we need to master the url interface (will find and use it) to facilitate the search: the params() function is used in the middle to add new content after the url. When the function is called, the url will be in both Add a "?" symbol at the junction
In terms of web crawling, we have also seen the appearance of r.text[] format, which means that we need to crawl the number of characters in the source code of the web page;
In the example, I saw the crawling of pictures and videos and saved them in binary form!
Beautiful Soup library: (install bs4 in pycharm) {0.2 bs.py}
Use of the library:
1 form bs4 import BeautifulSoup
23 soup =BeautifulSoup( ‘ <p>data</p> ‘ , ‘ html.parser ‘ )
The understanding of the Beautiful Soup library: a functional library for parsing, traversing, and maintaining the "tag tree"
- Beautiful Soup library, also called Beautiful Soup4 or bs4
Currently commonly used citation methods: for bs4 impor tBeautiful Soup
Beautiful Soup class<<<equivalence>>> tag tree<<<equivalence>>> HTML<>
Because of the formation of equivalence, the tag tree forms a variable through the Beautiful Soup class;
Simple analogy: Beautiful Soup corresponds to the entire content of the HTML/XML document
Beautiful Soup library Parser:
| Parser | How to use | Condition |
|---|---|---|
| HTML parser for bs4 | Beautiful Soup (mk,'html.parser' ) | install bs4 library |
| HTML parser for lxml | Beautiful Soup (mk,'lxml' ) | pip install lxml |
| XML parser for lxml | Beautiful Soup (mk,'xml' ) | pip install lxml |
| html5lib's parser | Beautiful Soup (mk,'html5lib' ) | pip install html5lib |
Basic elements of Beautiful Soup library:
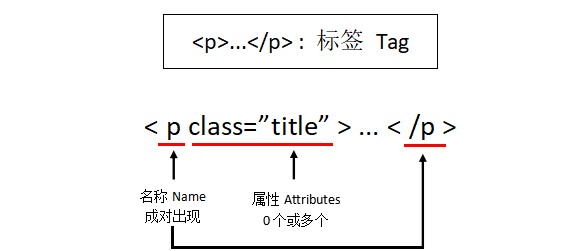
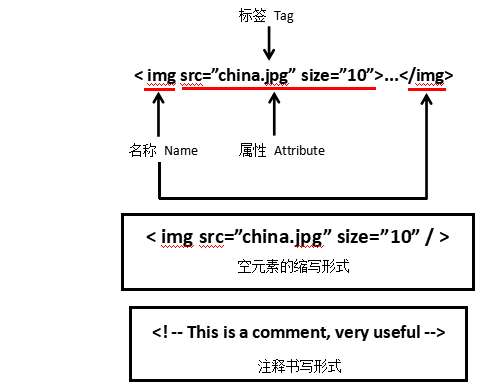
| Basic elements | Description |
|---|---|
| Tag | tag, the most basic information organization unit, use <> and</> Mark the beginning and end |
| Name | The name of the label, ... The name is'p', format: |
| Attributes | Tag attributes, organized in dictionary form, format: |
| NavigableString | Non-attribute string inside the tag, <>...</> Medium string, format: |
| Comment | The comment part of the string in the tag, a special Comment type |
Beautiful Soup library functions: (in the table
| Function | Description | Remarks |
|---|---|---|
| soup. |
Get the tags in the parsed webpage | t=soup. |
| [ soup. |
Get |
|
| [ soup. |
Get |
This can be inferred by analogy |
| [ soup. |
Get |
|
| [ soup. |
Get |
Code example (+description)
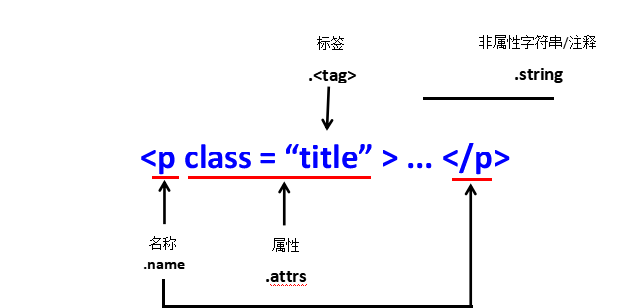
1 r = requests.get('http://python123.io/ws/demo.html')2print(r.text)3 demo = r.text #demo ==url webpage code
4 soup =BeautifulSoup(demo,'html.parser')5print(soup.prettify())6 r = requests.get('http://python123.io/ws/demo.html')7 demo = r.text
8 soup =BeautifulSoup(demo,"html.parser")9print(soup.title) #Find title tag
10 print(soup.a.string) #Print the string content of a tag
11 print(soup.a.name) #Print the name of a label
12 print(soup.a.parent.name) #Print the parent label of label a (the upper label)
13 print(soup.a.parent.parent.name) #Print the upper label of the parent label of label a
14 tag = soup.a #soup:Find label a
15 print(soup.a.attrs) #Print label attributes
16 print(tag.attrs['class']) #Print the content of'class' in label attributes
17 print(tag.attrs['href']) #Print the content of'href' in label properties
18 print(tag) #Print the content of a tag
HTML traversal:
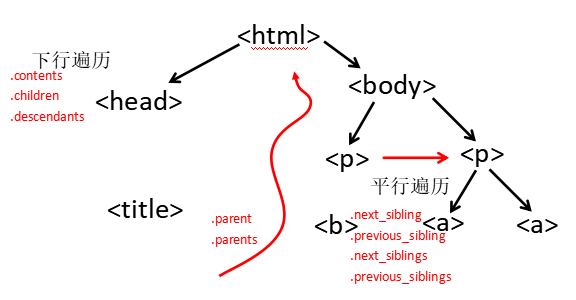
Downward traversal:
| Properties | Description |
|---|---|
| . contents | List of child nodes, will |
| . children | The iteration type of child nodes, similar to .contents, used to loop through the child nodes |
| . descendants | Iteration type of descendants, including all descendants, used for loop traversal |
| 1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text #demo == url web code 3 soup = BeautifulSoup(demo,'html.parser') 4 print (soup.head) #Get the head tag 5 print(soup.head.contents) #The return form is a list, and the list form retrieves head, 6 print(soup.body.contents) #Get the son node of the body tag (return form is list ) 7 print(len(soup.body.contents)) #Use len to test the total number of nodes of the body tag 8 print(soup.body.contents[1]) #list form return, use list to view one of the nodes 9 #traverse Son node 10 for child in soup.body.children:11 print(child)12 #Traverse the descendants node 13 for child in soup.body.descendants:14 print(child) |
Upward traversal:
| Properties | Description |
|---|---|
| . parent | The parent tag of the node |
| . parents | The iteration type of the node's ancestor label, used to loop through the ancestor node |
| 1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text #demo == url web code 3 soup = BeautifulSoup(demo,'html.parser') 4 print (soup.title.parent) #title tag node parent >>> Label 5 #Upstream traversal 6 for parent in soup.a.parents: # Traverse the parent up from the a label 7 if parent is None: 8 print(parent) #If the ancestor is None, execute 9 else:10 print(parent.name) # Print the label name of the ancestor |
Parallel traversal:
| Properties | Description |
|---|---|
| . next_sibling | Returns the next parallel node label in the order of HTML text |
| . previous_sibling | Return to the previous parallel node label in the order of HTML text |
| . next_siblings | Iteration type, returns all subsequent parallel node labels in HTML text order |
| . previous_siblings | Iteration type, returns all subsequent parallel node labels in HTML text order |
| 1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text #demo == url web code 3 soup = BeautifulSoup(demo,'html.parser') 4 print (soup.a.next_sibling) #a's next parallel node is the string >>>'and' 5 print(soup.a.next_sibling.next_sibling) #a's next parallel label is the next parallel label 6 print(soup .a.previous_sibling) #a's previous parallel label 7 print(soup.a.previous_sibling.previous_sibling) #>>> None (空信息) 8 #Traverse subsequent parallel nodes: 9 for sibling in soup.a.next_siblings:10 print(sibling)11 #Traverse the pre-order parallel nodes: 12 for sibling in soup.a.previous_siblings:13 print(sibling) |
HTML format output based on bs4 library:
prettify() function: print label (print in HTML format)
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup.a.prettify()) #Output a tag (HTML format)
5'''
6< a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">7 Basic Python
8< /a>9'''
10 soup =BeautifulSoup('<p>Chinese</p>','html.parser')11print(soup.p.string) #To[Obtain<tag>Non-attributed string/Comment]Output label
12'''
13 Chinese
14'''
15 print(soup.p.prettify()) #Output tags in HTML format
16'''
17< p>18 Chinese
19< /p>20'''
Information organization and extraction: {0.3.py}
Information mark:
The marked information can form the information organization structure, increasing the information dimension
The marked information can be used for communication
Store or display
The structure of the mark is as important as the information
The marked information is more conducive to the understanding and application of the program
HTML information mark:
HTML (Hyper Text Markup Language): Hypertext Markup Language; it is the information organization method of WWW (World Wide Web) to embed sound, image, and video into text by means of hypertext;
HTML passes predefined <>...</> Organize different types of information in tabs
Three forms of information mark: (XML\JSON\YAML)
XML (eXtensible Markup Language): Extensible Markup Language (based on HTML)
**JSON (JavsScript Object Notation): Typed key and value pairs (key: value) expression **
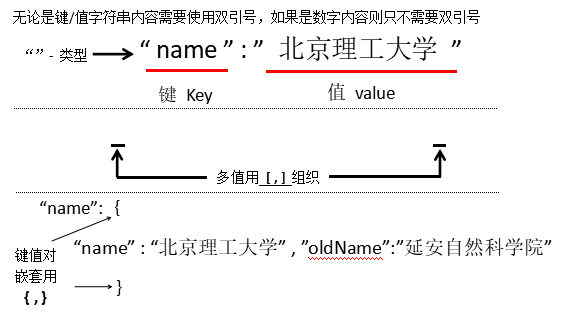
YAML (YAML Ain't Markup Language): Recursive definition; untyped key-value pair Key: Value

Comparison of three information marking methods: (example)
| XML example | |
|---|---|
| < person> |
It can be seen from the example that the proportion of effective information text is not high, and most of the information is occupied by tags |
| JSON example | |
|---|---|
| { "FirstName": "Tian", "lastName": "Song", "addresss": {"streetAddr": "Zhongguancun South Street 5", "city": "Beijing", "zipcode": "100081"} "Prof": ["Computer System", "Security" ]} | JSON defines related keys through key-value pairs |
| YAML examples (YAML is concise and clear) | |
| firstName: Tiam lastName: Song address: streetAddr: 5 Zhongguancun South Street city: Beijing zipcode: 100081 prof: -Computer System -security |
| Information Mark | Compare | Application |
|---|---|---|
| XML | The earliest general information markup language, extensible but cumbersome | Interaction and transmission of information on the Internet |
| JSON | Information has types, suitable for program processing (js), more concise than XML | Mobile application cloud and node information interaction, no comments |
| YAML | No type of information, the highest proportion of text information, good readability | Configuration files of various systems, easy to read with comments |
General method of information extraction:
Method 1: Completely analyze the marked form of the information, and then extract the key information.
XML JSON YAML_ requires a tag parser, for example: the tag tree traversal of the bs4 library
Advantages: accurate information analysis
Disadvantages: the extraction process is cumbersome and slow
Method 2: Ignore the markup form and directly search for key information.
Search the text search function for information
Advantages: the extraction process is simple and fast
Disadvantages: the accuracy of the extraction results is related to the information content (lack)
Fusion method: Combine form analysis and search methods to extract key information
XML JSON YAML + search >>> requires markup parser and text search function
Examples:
1 import requests
2 from bs4 import BeautifulSoup
3'''# Extract all URL links in HTML
41、 Search all<a>Tags (the content of the a tag is the url)
52、 Parsing<a>Tag format, link content after href is extracted
6'''
789 r = requests.get('http://python123.io/ws/demo.html')10 demo = r.text
11 soup =BeautifulSoup(demo,'html.parser')12for link in soup.find_all('a'): #Find in the demo<a>label
13 print(link.get('href')) #in<a>Find the "href" function in the tag
141516'''
17 result:18 http://www.icourse163.org/course/BIT-26800119 http://www.icourse163.org/course/BIT-100187000120'''
Beautiful Soup library method:
**bs4.element.Tag: tag type; **
| Method | <>.find_all (name,attrs,recursive,string,**kwargs) |
|---|---|
| Description | You can find the information in the variable of soup |
| Parameter | Returns a list type, storing the result of the search. Parameter description promotes the search string of name to the name of the label. If you search for multiple contents, you can use the list method attrs to search for the label attribute value. Whether the attribute index recursive can be marked Retrieve all descendants (default True) False only retrieve string<>...</> The search string in the string area string='....' |
| Parameters | Description |
| name | The search string for the name of the label |
| attrs | Retrieving string for label attribute value |
| recursive | Whether to search for all descendants (default True) |
| string | <>...</> The search string in the string area in the |
| Short search | |
| Extension method | Method description<>.find() searches and returns only one result, string (string) type, <>.find_parents() searches in the ancestor node, returns list type, <>.find_parent() in the ancestor node Return a node, string type, <>.find_next_siblings() searches in subsequent parallel nodes, returns list type, <>.find_next_sibling() returns a result in subsequent parallel nodes, string type <>.find_previous_siblings() first Search in order parallel nodes, return list type, <>.find_previous_sibling() returns a result in previous order parallel nodes, string type |
| Method | Description |
| <>. find() | Search and return only one result, string type, |
| <>. find_parents() | Search in ancestor nodes, return list type, |
| <>. find_parent() | Return a node in the ancestor node, string type, |
| <>. find_next_siblings() | Search in subsequent parallel nodes, return list type, |
| <>. find_next_sibling() | returns a result in subsequent parallel nodes, string type |
| <>. find_previous_siblings() | Search in the previous parallel nodes, return list type, |
| <>. find_previous_sibling() | returns a result in the previous parallel node, string type |
name instance:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,"html.parser")4print(soup.find_all('a')) #The list form returns the label string in soup (text) (retrieve a label)
5 print(soup.find_all(['a','b']))6for tag in soup.find_all(True): #Traverse all labels in soup
7 print(tag.name) #Print (get) the name of all labels! !
8'''
9[< a class="py1" href="http://www.icourse163.org/course/BIT-268001"10 id="link1">Basic Python</a>,<a class="py2" href="http://www.icourse163.org
11 /course/BIT-1001870001" id="link2">Advanced Python</a>]12[<b>The demo python introduces several python courses.</b>,<a class="py1"13 href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic
14 Python</a>,<a class="py2" href="http://www.icourse163.org/course/15 BIT-1001870001" id="link2">Advanced Python</a>]16 html
17 head
18 title
19 body
20 p
21 b
22 p
23 a
24 a
25'''# result
Examples of attrs:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup.find_all('p','course')) #Return the P tag with the course attribute
5 print(soup.find_all(id='link1')) #Return ID attribute==Content of link1
67 ‘’’
89[< p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:1011<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]1213[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]1415 ‘’’
Recursive instance:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup.find_all('a')) #Retrieve a tag
5 print(soup.find_all('a',recursive=False))#Return an empty list, indicating that the lower node of a does not have a label (only one layer (son layer) is retrieved under False)
string instance:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup) #Output the complete HTML code parsed by the parser
5 print(soup.find_all(string ='Basic Python')) #List returns the retrieved string information
A case of directional crawler for Chinese university ranking {0.4 bs.py}
1 import requests
2 import bs4
3 from bs4 import BeautifulSoup
4 # soup =BeautifulSoup(demo,'html.parser')5 def getHTML(url):#Standard framework
6 try:7 r = requests.get(url)8 r.raise_for_status()9 r.encoding = r.apparent_encoding
10 return(r.text)11 except:12print("Link crawling failed")1314 def uitHTML(ulist,demo):15 soup =BeautifulSoup(demo,'html.parser')16for tr in soup.find('tbody').children:1718 #.find(..)Search tag results returned.children traverse the son (lower layer) node at the same time
19 ifisinstance(tr,bs4.element.Tag):2021 #Detect the type of tr, if it is not a tag type, filter (to avoid traversing to the string content) isinstance to determine the variable type
22 tds =tr('td') #Equivalent to tr.find(...)>>>Find the td tag (the returned object is list)
23 # print(tds) #Test and use: view tds content
24 # tds now gets the HTML format of all td tags in tr in the HTML of the url (returned in list format)
25 ulist.append([tds[0].string, tds[1].string, tds[3].string])26 #The data needed in tds(Extract only.string>>String area)Save to the ulist list
2728 def uitUlist(ulist,num):29print("{:^16}\t{:^16}\t{:^16}".format("Rank","School Name","Total score"))30for i inrange(num):31 u = ulist[i]32print("{:^16}\t{:^16}\t{:^16}".format(u[0],u[1],u[2]))3334 def main():35 ulist =[]36 url ="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"37 demo =getHTML(url)38uitHTML(ulist,demo)39uitUlist(ulist,20)4041main()
Regular expression: re library: (https://www.cnblogs.com/wangyuyang1016/p/10034868.html)
Commonly used operators of regular expressions
| . | Represents any single character | |
|---|---|---|
| [ ] | Character set, given a range of values for a single character | [a,b,c] means a,b,c; [az] means a single character from a to z |
| [^] | Non-character set, the exclusion range is given for a single character | [^a,b,c] indicates a single character that is not a, b, or c |
| * | 0 or unlimited expansion of the previous character | abc* means ab, abc, abcc, abccc, etc. |
| + | The previous character is expanded once or unlimited times | abc+ means abc, abcc, abccc, etc. |
| ? | The previous character 0 or 1 expansion | abc? means ab,abc |
| Any one of left and right expressions | ||
| { m} | Expand the previous character m times | ab{2}c means abbc |
| { m,n} | Expand the previous character m to n times (including n) | ab{1,2}c means abc, abbc |
| ^ | Match the beginning of the string | ^abc means abc and is at the beginning of a string |
| $ | matches the end of the string | abc$ means abc and is at the end of a string |
| ( ) | Grouping mark, only the | operator |
| \ d | Number, equivalent to [0-9] | |
| \ w | word character, equivalent to [A-Za-z0-9] |
Main functions of the re library
| re.search() | Search for the first position of a matching regular expression in a string and return the match object |
|---|---|
| re.match() | Match the regular expression from the beginning of a string and return the match object |
| re.findall() | Search string, return all matching substrings in list type |
| re.split() | Split a string according to the regular expression matching result and return the list type |
| re.finditer() | Search for a string and return an iterable type of matching result, each iterable element is a match object |
| re.sub() | Replace all substrings matching regular expressions in a string, and return the replaced string |
Detailed function function:
| Syntax | re.search (pattern, string, flags=0 ) |
|---|---|
| Parameter description | pattern regular expression string or native string representation string The string to be matched (string) flags The control flag when regular expression is used |
| pattern | String or native string representation of regular expression |
| string | The string to be matched (string) |
| flags | Control flags when using regular expressions |
| The flags control flag | re.I ignores the case of regular expressions. The ^ operator of re.M (multi-line matching) can treat each line of the given string as the beginning of the match. The operator can match. All characters |
| re.I | Ignore the case of regular expressions |
| The ^ operator of re.M | (multi-line matching) can treat each line of the given string as the beginning of the match |
| re.S | Regular. Operator can match all characters |
| Syntax | re.match (pattern, string, flags=0 ) |
|---|---|
| Parameter description | pattern regular expression string or native string representation string The string to be matched (string) flags The control flag when regular expression is used |
| pattern | String or native string representation of regular expression |
| string | The string to be matched (string) |
| flags | Control flags when using regular expressions |
| The flags control flag | re.I ignores the case of regular expressions. The ^ operator of re.M (multi-line matching) can treat each line of the given string as the beginning of the match. The operator can match. All characters |
| re.I | Ignore the case of regular expressions |
| The ^ operator of re.M | (multi-line matching) can treat each line of the given string as the beginning of the match |
| re.S | Regular. Operator can match all characters |
| Syntax | re.findall (pattern, string, flags=0 ) |
|---|---|
| Parameter description | pattern regular expression string or native string representation string The string to be matched (string) flags The control flag when regular expression is used |
| pattern | String or native string representation of regular expression |
| string | The string to be matched (string) |
| flags | Control flags when using regular expressions |
| The flags control flag | re.I ignores the case of regular expressions. The ^ operator of re.M (multi-line matching) can treat each line of the given string as the beginning of the match. The operator can match. All characters |
| re.I | Ignore the case of regular expressions |
| The ^ operator of re.M | (multi-line matching) can treat each line of the given string as the beginning of the match |
| re.S | Regular. Operator can match all characters |
| Syntax | re.split (pattern, string, maxsplit=0, flags=0 ) |
|---|---|
| Parameter description | pattern regular expression string or native string represents the maximum split number of string to be matched (string) maxsplit, and the remaining part is used as the last element to output flags. The control flag when the regular expression is used |
| pattern | String or native string representation of regular expression |
| string | The string to be matched (string) |
| maxsplit | The maximum number of splits, the remaining part is output as the last element |
| flags | Control flags when using regular expressions |
| The flags control flag | re.I ignores the case of regular expressions. The ^ operator of re.M (multi-line matching) can treat each line of the given string as the beginning of the match. The operator can match. All characters |
| re.I | Ignore the case of regular expressions |
| The ^ operator of re.M | (multi-line matching) can treat each line of the given string as the beginning of the match |
| re.S | Regular. Operator can match all characters |
| Syntax | re.finditer (pattern, string, flags=0 ) |
|---|---|
| Parameter description | pattern regular expression string or native string representation string The string to be matched (string) flags The control flag when regular expression is used |
| pattern | String or native string representation of regular expression |
| string | The string to be matched (string) |
| flags | Control flags when using regular expressions |
| The flags control flag | re.I ignores the case of regular expressions. The ^ operator of re.M (multi-line matching) can treat each line of the given string as the beginning of the match. The operator can match. All characters |
| re.I | Ignore the case of regular expressions |
| The ^ operator of re.M | (multi-line matching) can treat each line of the given string as the beginning of the match |
| re.S | Regular. Operator can match all characters |
| Syntax | re.sub (pattern, repl, string, count=0, flags=0 ) |
|---|---|
| Parameter description | pattern The string of regular expression or the native string represents the repl replace the string of the matched string string the string to be matched (string) count replace the maximum matching flags The control flag when the regular expression is used |
| pattern | String or native string representation of regular expression |
| repl | Replace the string matching the string |
| string | The string to be matched (string) |
| count | The maximum number of replacement matches |
| flags | Control flags when using regular expressions |
| The flags control flag | re.I ignores the case of regular expressions. The ^ operator of re.M (multi-line matching) can treat each line of the given string as the beginning of the match. The operator can match. All characters |
| re.I | Ignore the case of regular expressions |
| The ^ operator of re.M | (multi-line matching) can treat each line of the given string as the beginning of the match |
| re.S | Regular. Operator can match all characters |
re.compile(): Object-oriented usage (operation):
| Syntax | regex = re.compile( pattern, flags = 0) |
|---|---|
| Description | ·Compile the string form of the regular expression into a regular expression object (object) pattern Regular expression string or native string representation (regular expression method) flags The control flag match = regex when the regular expression is used. search('string') #compile() The re function function after compile() is the same as before |
| pattern | String or native string representation of regular expressions (regular representation method) |
| flags | Control flags when using regular expressions |

Properties of the Match object
| Properties | Description |
|---|---|
| . string | Text to be matched |
| . re | pattern object (regular expression) used in matching |
| . pos | The starting position of the regular expression search text |
| . endpos | The end position of the regular expression search text |
Match object method
| Method | Description |
|---|---|
| . group(0) | Get the matched string |
| . start() | The matching string is at the beginning of the original string |
| . end() | The matching string is at the end of the original string |
| . span() | return (.start(), .end()) |
Examples:
1 import re
2 match = re.search(r'[1-9]\d{5}','BIT 100081')3 #Properties of the Match object
4 print(match.string) #Returns the string to be matched when matching
5 print(match.re) #Return the re expression when matching
6 print(match.pos) #Returns the starting position of the matched search text
7 print(match.endpos) #Returns the position where the matched search text ends
8 # Match object method
9 print(match.group(0)) #Return the matched string (the first match result)
10 print(match.start()) #Match the original string
11 print(match.end()) #Match the end of the original string
12 print(match.span()) #Return as a tuple.start()with.end()
Greedy matching and minimum matching of the re library
1 match = re.search(r'PY.*N','PYANBNCNDN') #Greedy matching (re library default greedy matching, that is, the longest substring matching output)
2 print(match.group(0))3 match = re.search(r'PY.*?N','PYANBNCNDN') #Minimum match
4 print(match.group(0))
Minimum matching operator
| Operator | Description |
|---|---|
| *? | The previous character is expanded 0 times or unlimited times, the smallest match |
| +? | The previous character is expanded 1 time or unlimited times, the smallest match |
| ?? | 0 or 1 expansion of the previous character, minimum match |
| { m,n}? | Expand the previous character m to n times (including n), the smallest match |
Recommended Posts