Python handles the 4 wheels of Chinese
Here is a record of Python-related content worth sharing, which will be released every Friday. Since WeChat does not allow external links, click to read the original text to access the links in the article.

Title picture: China's "Dead Sea"-Xinjiang Salt Lake, 2019
On a university campus, I always think I still have a lot of time, I can learn things slowly, I don’t worry about the future at all, so I can play for a while. After working, I realized that I had almost no time for myself. Although I can learn things that I don’t know, it takes time. After work, time becomes extremely precious. Therefore, I have to weigh the trade-offs: Which ones should I learn, and which ones, I don’t need to learn?
As you in the workplace, how did you choose? Do you use what you learn, or do you have a choice?
I personally prefer the latter because I think that professionals will be scarcer in the future, and people must have skills to gain a foothold. What you spend time learning should serve your own advantages, because the strong are always strong. Of course, if you think generalists are more valuable in the future, you can develop in a balanced way and learn what you use.
In software design, the best way to save time is not to reinvent the wheel, and to write the program yourself, write it as generic as possible, encapsulate it with classes, and use it directly next time you encounter a similar situation, or use it slightly Can be used by inheritance. If you haven't, please go to github and search first to see if someone has already built a wheel, just wait for you to use it.
Our Chinese is broad and profound, but we often encounter troubles in program processing, how to judge synonyms, how to segment words, how to do sentiment analysis, how to get the pinyin of Chinese characters, do not rush to write code, use wheels made by others, save your life The precious time is very wise. This article shares several wheels related to Python Chinese, please use them as needed.
**1、 Synonyms, a toolkit for synonyms. **
The best Chinese synonym toolkit https://github.com/huyingxi/Synonyms, which can be used for many tasks of natural language understanding: text alignment, recommendation algorithm, similarity calculation, semantic shift, keyword extraction, concept extraction, Automatic summarization, search engines, etc.
installation method:
pip install -U synonyms
Compatible with py2 and py3, the current stable version v3.x.
The effect is as follows:
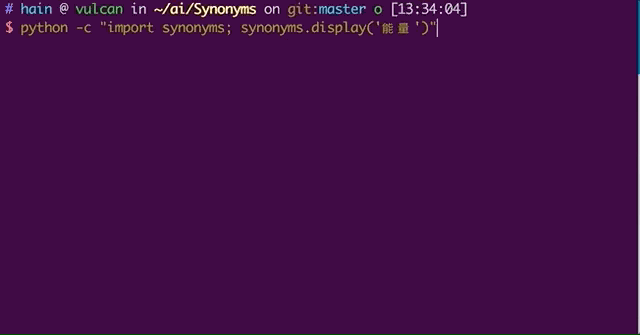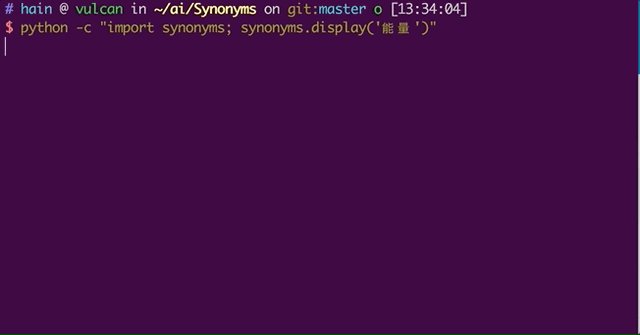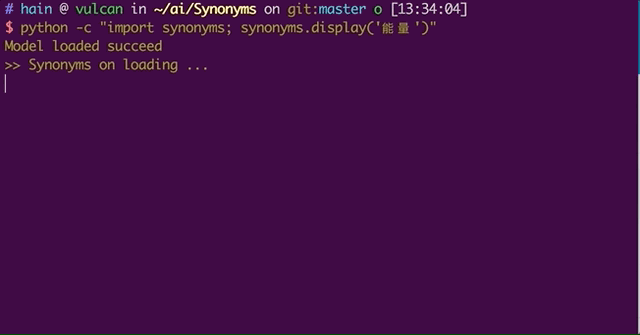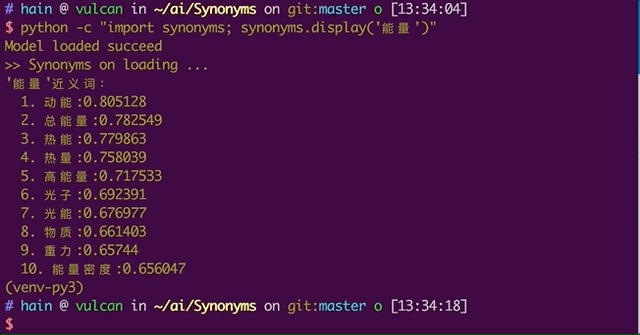
In addition, Node.js users can use node-synonyms.
**2、 Chinese word segmentation tool jieba. **
The best Chinese word segmentation toolkit: https://github.com/fxsjy/jieba
Installation method:
pip install jieba
Support three word segmentation modes:
- Precise mode, trying to cut the sentence most accurately, suitable for text analysis;
- The full mode scans out all the words in the sentence that can be formed into words, which is very fast, but cannot resolve ambiguities;
- Search engine mode, on the basis of precise mode, segment long words again, improve the recall rate, suitable for search engine word segmentation.
**Support traditional word segmentation, support custom dictionary **
Code example
# encoding=utf-8import jieba
seg_list = jieba.cut("I came to Beijing Tsinghua University", cut_all=True)print("Full Mode: "+"/ ".join(seg_list)) #Full mode
seg_list = jieba.cut("I came to Beijing Tsinghua University", cut_all=False)print("Default Mode: "+"/ ".join(seg_list)) #Precise mode
seg_list = jieba.cut("He came to NetEase Hangyan Building") #The default is precise mode
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("Xiao Ming graduated from the Institute of Computing Technology, Chinese Academy of Sciences, and then studied at Kyoto University, Japan") #Search engine mode
print(", ".join(seg_list))
Output:
【Full mode】:I/come/Beijing/Tsinghua/Tsinghua大学/Huada/the University
【Accurate Mode】:I/come/Beijing/Tsinghua University
[New word recognition]: He,come,Up,NetEase,Hang Yan,building(Here, "Hangyan" is not in the dictionary, but it is also recognized by the Viterbi algorithm)
[Search Engine Mode]: Xiao Ming,master's degree,graduation,in,China,science,College,science院,China科学院,Calculation,Calculation所,Rear,in,Japan,Kyoto,the University,day
**3、 Chinese processing tool SnowNLP. **
github link: https://github.com/isnowfy/snownlp
SnowNLP is a class library written in python, which can handle Chinese text content conveniently. It was inspired by TextBlob. Since most of the natural language processing libraries are basically for English, so I wrote a convenient processing Chinese Unlike TextBlob, NLTK is not used here, all algorithms are implemented by themselves, and some well-trained dictionaries are included. Note that this program handles unicode encoding, so please decode it into unicode when you use it.
characteristic
- Chinese word segmentation (Character-Based Generative Model)
- Part-of-speech tagging (TnT 3-gram hidden horse)
- Sentiment analysis (now the training data is mainly the evaluation when buying and selling things, so it may not be very effective for some other things, to be resolved)
- Text classification (Naive Bayes)
- Convert to Pinyin (the maximum match achieved by the Trie tree)
- Traditional to Simplified (Maximum matching achieved by Trie tree)
- Extract text keywords (TextRank algorithm)
- Extract text summaries (TextRank algorithm)
- tf,idf
- Tokenization (split into sentences)
- Text similar (BM25)
- Support python3
from snownlp import SnowNLP
s =SnowNLP(u'This thing is really awesome')
s.words # [u'This one', u'thing', u'sincere',
# u'very', u'awesome']
s.tags # [(u'This one', u'r'),(u'thing', u'n'),
# ( u'sincere', u'd'),(u'very', u'd'),
# ( u'awesome', u'Vg')]
s.sentiments # 0.9769663402895832 positive probability
s.pinyin # [u'zhe', u'ge', u'dong', u'xi',
# u'zhen', u'xin', u'hen', u'zan']
s =SnowNLP(u'"Traditional Chinese" and "Traditional Chinese" are also very common in Taiwan.')
s.han # u'"Traditional Chinese" and "Traditional Chinese"
# It is also very common in Taiwan.'
text = u'''
Natural language processing is an important direction in the field of computer science and artificial intelligence.
It studies various theories and methods that enable effective communication between humans and computers in natural language.
Natural language processing is a science that integrates linguistics, computer science, and mathematics.
Therefore, research in this field will involve natural language, that is, the language people use daily,
So it is closely related to the study of linguistics, but there are important differences.
Natural language processing is not a general study of natural language.
It is to develop a computer system that can effectively realize natural language communication.
Especially the software system. So it is part of computer science.
'''
s =SnowNLP(text)
s.keywords(3) # [u'Language', u'natural', u'computer']
s.summary(3) # [u'So it is part of computer science',
# u'Natural language processing is a subject that combines linguistics, computer science,
# Mathematics in one science',
# u'Natural language processing is the field of computer science and artificial intelligence
# An important direction in the field']
s.sentences
s =SnowNLP([[u'This', u'article'],[u'That article', u'paper'],[u'This one']])
s.tf
s.idf
s.sim([u'article'])# [0.3756070762985226,0,0]
**4、 Chinese pinyin conversion tool. **
installation
pip install pypinyin
characteristic
- Intelligently match the most correct pinyin according to the phrase.
- Support polyphonic characters.
- Simple traditional Chinese support, Zhuyin support.
- Support a variety of different pinyin/zhuyin styles.
>>> from pypinyin import pinyin, lazy_pinyin, Style
>>> pinyin('center')[['zhōng'],['xīn']]>>>pinyin('center', heteronym=True) #Enable polyphone mode
[[' zhōng','zhòng'],['xīn']]>>>pinyin('center', style=Style.FIRST_LETTER) #Set Pinyin style
[[' z'],['x']]>>>pinyin('center', style=Style.TONE2, heteronym=True)[['zho1ng','zho4ng'],['xi1n']]>>>pinyin('center', style=Style.BOPOMOFO) #Phonetic style
[[' ㄓㄨㄥ'],['ㄒㄧㄣ']]>>>pinyin('center', style=Style.CYRILLIC) #Russian alphabet style
[[' чжун1'],['синь1']]>>>lazy_pinyin('center') #Do not consider polyphonic characters
[' zhong','xin']
Precautions :
- The pinyin result will not indicate which vowel is soft, and the soft vowels have no tone or number identification.
- The result under the pinyin style without tone will use
vto representü.
Command line tools:
$pypinyin music
yīn yuè
$ pypinyin -h
For detailed documentation, please visit: http://pypinyin.rtfd.io/.
**5、 Other libraries commonly used by Python. **
There are so many powerful libraries here that you doubt your life: there are so many wheels that you can allocate on demand without spending money at all.
github link: https://github.com/jobbole/awesome-python-cn
This project is also my first pull request project on github, so I will share it to commemorate it.
(Finish)
Focus on Python technology sharing
Welcome to subscribe, watch, forward
Recommended Posts