python operation kafka
Kafka is an open source stream processing platform developed by the Apache Software Foundation, written in Scala and Java. Kafka is a high-throughput distributed publish-and-subscribe messaging system that can process all the action flow data of consumers in the website. Such actions (web browsing, search and other user actions) are a key factor in many social functions on the modern web. These data are usually resolved by processing logs and log aggregation due to throughput requirements. For log data and offline analysis systems like Hadoop, but with the limitations of real-time processing, this is a feasible solution.
Kafka's single-machine throughput is 100,000. When topics go from tens to hundreds, the throughput will drop significantly. Under the same machine, Kafka tries to ensure that the number of topics is not too much. If you want to support large-scale topics, you need to increase More machine resources.
One of the most basic understandings of Kafka's architecture: consists of multiple brokers, each broker is a node; you create a topic, this topic can be divided into multiple partitions, each partition can exist on a different broker, each partition Put part of the data. This is the natural distributed [message queue] (https://cloud.tencent.com/product/cmq?from=10680), which means that the data of a topic is scattered on multiple machines, and each machine puts a part of the data.
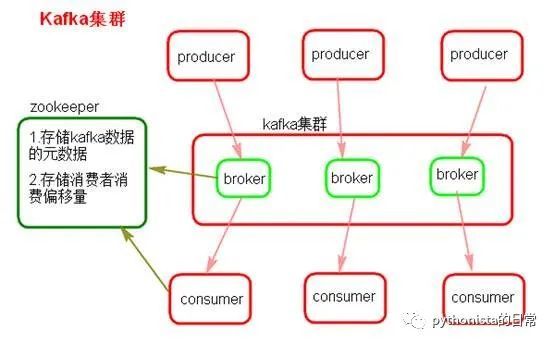
After Kafka 0.8, an HA mechanism is provided, which is the replica mechanism. The data of each partition will be synchronized to other machines to form its own multiple replica copies. All replicas will elect a leader, then production and consumption will deal with this leader, and then other replicas are followers. When writing, the leader will be responsible for synchronizing the data to all followers. When reading, just read the data on the leader directly. Can only read and write the leader? It's very simple. If you can read and write each follower at will, then you have to care about the data consistency problem. The system complexity is too high and problems are prone to occur. Kafka will evenly distribute all replicas of a partition on different machines, so as to improve fault tolerance.
In this way, there is the so-called high availability, because if a broker goes down, it's okay, the partition on that broker has a copy on other machines. If there is a leader of a certain partition on the down broker, then a new leader will be re-elected from the followers at this time, and everyone can continue to read and write that new leader. This is the so-called high availability.
When writing data, the producer writes to the leader, and then the leader writes the data to the local disk, and then other followers take the initiative to pull data from the leader. Once all the followers have synchronized their data, they will send an ack to the leader. After the leader receives the ack from all the followers, it will return a successful write message to the producer. (Of course, this is only one of the modes, and this behavior can be adjusted appropriately) When consuming, it will only be read from the leader, but only when a message has been successfully returned to ack by all the followers, the message will be Consumers read.
Use kafka-python to operate kafka in the project
- Create topic
from kafka.admin import KafkaAdminClient, NewTopic
# Kafka cluster information
bootstrap_servers ='127.0.0.1:9092'
# topic name
jrtt_topic_name ="T100117_jrtt_grade_advertiser_public_info"
admin_client =KafkaAdminClient(bootstrap_servers=bootstrap_servers, client_id='T100117_gdt_grade_advertiser_get')
topic_list =[]
# 6 Partitions, 2 copies
topic_list.append(NewTopic(name=jrtt_topic_name, num_partitions=6, replication_factor=2))
res = admin_client.create_topics(new_topics=topic_list, validate_only=False)
- View all topics of kafka
from kafka import KafkaProducer, KafkaConsumer
# Kafka cluster information
bootstrap_servers ='127.0.0.1:9092'
consumer =KafkaConsumer(bootstrap_servers=bootstrap_servers,)
all_topic = consumer.topics()print(all_topic)
- Kafka producer code
from kafka import KafkaClient, KafkaProducer
# Kafka cluster information
bootstrap_servers ='127.0.0.1:9092'
jrtt_value ={"dev_app_type":2,"date":"20201111","agent_id":"1648892709542919","tenant_alias":"T100117","data":{"first_industry_name":"\\u6559\\u80b2\\u57f9\\u8bad","second_industry_name":"\\u4e2d\\u5c0f\\u5b66\\u6559\\u80b2","company":"\\u7f51\\u6613\\u6709\\u9053\\u4fe1\\u606f\\u6280\\u672f\\uff08\\u5317\\u4eac\\uff09\\u6709\\u9650\\u516c\\u53f8\\u676d\\u5dde\\u5206\\u516c\\u53f8","id":1683030511810573,"name":"ZS-\\u7f51\\u6613\\u4e50\\u8bfb-001"},"timestamp": time.time()}
producer =KafkaProducer(bootstrap_servers=bootstrap_servers,value_serializer=lambda v: json.dumps(v).encode('utf-8'))
# Jrtt in json format_The value is sent to Kafka
producer.send(topic_name, value=jrtt_value)
- Kafka consumer
from kafka import KafkaProducer, KafkaConsumer
bootstrap_servers ='127.0.0.1:9092'
# Receive the message content generated by the producer of a topic
consumer =KafkaConsumer(topic_name, bootstrap_servers=bootstrap_servers,)for index, msg inenumerate(consumer):
#
print("%s:%d:%d: key=%s value=%s"%(msg.topic, msg.partition, msg.offset, msg.key, msg.value))
Recommended Posts