Python string
Python string str
str essence##
The essence of Python str can be viewed through the help command
>>> help(str)
can be seen
Help on classstrin module __builtin__:classstr(basestring)|str(object='')-> string
|| Return a nice string representation of the object.| If the argument is a string, the return value is the same object.|| Method resolution order:| str
| basestring
| object
|| Methods defined here:......
The essence of str is a class in the Python module __builtin__, which defines many methods.
str features##
Python strings cannot be changed, and the value of the string is fixed. Therefore, it will be wrong to assign values to the specific table positions of a string:
>>> word='Python'>>> word[0]='J'...
TypeError:'str' object does not support item assignment
>>> word[2:]='py'...
TypeError:'str' object does not support item assignment
If you want to get a different string, you have to create a new one:
>>>' J'+ word[1:]'Jython'>>> word[:2]+'py''Pypy'
You can use a built-in function len() in the module __builtin__ to get the length of the string:
>>> help(len)
Help on built-infunction len in module __builtin__:len(...)len(object)-> integer
Return the number of items of a sequence or collection.>>> s ='supercalifragilisticexpialidocious'>>>len(s)34
String is an iterable object
>>> s ='I love Python'>>>list(s)['I',' ','l','o','v','e',' ','P','y','t','h','o','n']>>>for c in s:...print(c)...
I
l
o
v
e
P
y
t
h
o
n
>>>
str method
The following functions are the results of the member functions in the str class according to the function classification
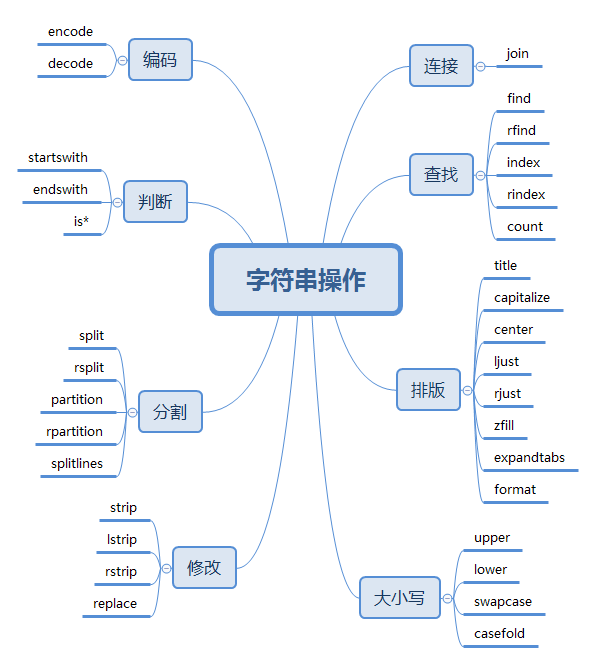
The xmind file can be downloaded from here
connection###
str.join(iterable)
S.join(iterable) -> string
Function function
Connect the elements in the sequence iterable with the specified character S to generate a new string.
Function example
>>> iter="apple">>> s="-">>> s.join(iter)'a-p-p-l-e'
Find
str.find(sub[, start[, end]])
S.find(sub [,start [,end]]) -> int
Function function
It has the same function as the find function of C++ string. Check whether there is substring sub in the string, if it exists, return the subscript of the first substring found, if not, return -1, and C++ returns string::nops .
Function example
>>> s="this is my dog, i love this dog and it's a good dog!">>> s.find("dog")11>>> s.find("dog",12,len(s)-1)28>>> s.find("dog",12,20)-1
str.rfind(sub[, start[, end]])
S.rfind(sub [,start [,end]]) -> int
Function function
It has the same function as the find function of C++ string. Check whether there is substring sub in the string, if it exists, return the subscript of the last substring found, if not, return -1, and C++ returns string::nops.
Function example
>>> s="this is my dog, i love this dog and it's a good dog!">>> s.rfind("dog")48>>> s.rfind("dog",0,len(s)-10)28
str.index(sub[, start[, end]])
S.index(sub [,start [,end]]) -> int
Function function
It has the same function as the python find() method, except that an exception (ValueError: substring not found) will be reported if the substring sub is not in S.
Function example
>>> s="this is my dog, i love this dog and it's a good dog!">>> s.index("dog")11>>> s.index("digw")Traceback(most recent call last):
File "<stdin>", line 1,in<module>
ValueError: substring not found
str.rindex(sub[, start[, end]])
S.rindex(sub [,start [,end]]) -> int
Function function
It has the same function as the python rfind() method, except that if the substring sub is not in S, an exception (ValueError: substring not found) will be reported.
Function example
>>> s="this is my dog, i love this dog and it's a good dog!">>> s.rindex("dog")48>>> s.rfind("dog")48>>> s.rindex("oihofa")Traceback(most recent call last):
File "<stdin>", line 1,in<module>
ValueError: substring not found
str.count(sub[, start[, end]])
S.count(sub[, start[, end]]) -> int
Function function
Find the number of occurrences of a certain substring in a string. start and end are two optional parameters, indicating the start and end subscript positions. Python default subscript position starts from 0.
Function example
>>> s="this is my dog, i love this dog and it's a good dog!">>> print s
this is my dog, i love this dog and it's a good dog!>>> s.count("dog")3>>> s.count(" ")12>>> s.count("dog",15)2>>> s.count("dog",15,32)1
typesetting###
str.capitalize()
S.capitalize() -> string
- Return a copy of the string S with only its first character capitalized.
Function function
The first character is a letter, return the first letter in uppercase, the others remain unchanged
Function example
>>> s='linux'>>> s.capitalize()'Linux'>>> s='790873linux'>>> s.capitalize()'790873linux'
str.center(width[, fillchar])
S.center(width[, fillchar]) -> string
Function function
The string S is the center, and a string of width length is returned, and the extra part is filled with fillchar. If width is less than or equal to len(S), then str itself is returned. If the parameter fillchar is not given, then spaces are filled by default
Function example
>>> s='linux'>>> a=s.center(len(s)+1,'m')>>> print a
linuxm
>>> a=s.center(len(s)+2,'m')>>> print a
mlinuxm
>>> a=s.center(len(s)+3,'m')>>> print a
mlinuxmm
>>> a=s.center(len(s)+4,'m')>>> print a
mmlinuxmm
>>> a=s.center(len(s)-1,'m')>>> print a
linux
str.ljust(width[, fillchar])
S.ljust(width[, fillchar]) -> string
Function function
Return a new string with the original string left-justified and filled to the specified length with the fillchar character.
width-specifies the length of the string
fillchar-fill character, default is space
Function example
>>> a="apple">>> a.ljust(10)'apple '>>> a.ljust(10,'.')'apple.....'>>> a.ljust(3,'2')'apple'
str.rjust(width[, fillchar])
S.rjust(width[, fillchar]) -> string
Function function
Return a new string with the original string right-aligned and filled with the character fillchar to the specified length width.
width-specifies the length of the string
fillchar-fill character, default is space
Function example
>>> a="apple">>> a.rjust(10)' apple'>>> a.rjust(10,'.')'.....apple'>>> a.rjust(3,'.')'apple'
str.expandtabs([tabsize])
S.expandtabs([tabsize]) -> string
Function function
Convert the tab symbol ('\t') in the string to a space, the default number of spaces for the tab symbol ('\t') is 8, tabsize-specify the tab symbol ('\t') in the converted string to The number of characters in the space.
Function example
>>> s ="today is a good d\tay">>> print s
today is a good d ay
>>> s.expandtabs()'today is a good d ay'>>> s.expandtabs(4)'today is a good d ay'>>> s.expandtabs(1)'today is a good d ay'>>> s.expandtabs(0)'today is a good day'
str.format(*args, **kwargs)
S.format(*args, **kwargs) -> string
Function function
Format string variables. The {} format is only supported after version 2.7 and version 3.1. Old version will report errors
ValueError: zero length field name in format
See: ValueError: zero length field name in format python
Function example
>>> name ='StivenWang'>>> fruit ='apple'>>> print 'my name is {},I like {}'.format(name,fruit)
my name is StivenWang,I like apple
>>> print 'my name is {1},I like {0}'.format(fruit,name)
my name is StivenWang,I like apple
>>> print 'my name is {mingzi},I like{shuiguo}'.format(shuiguo=fruit,mingzi=name)
my name is StivenWang,I like apple
Case###
str.lower()
S.lower() -> string
Convert all uppercase characters in a string to lowercase
>>> a="oiawh92dafawFAWF';;,">>> a.lower()"oiawh92dafawfawf';;,"
str.upper()
S.upper() -> string
Convert all lowercase characters in the string to uppercase
>>> a="oiawh92dafawFAWF';;,">>> a.upper()"OIAWH92DAFAWFAWF';;,"
str.swapcase()
S.swapcase() -> string
Function function
Convert the case of the string. Lowercase to uppercase, uppercase to lowercase
Function example
>>> s="ugdwAWDgu2323">>> s.swapcase()'UGDWawdGU2323'
segmentation###
str.split([sep[, maxsplit]])
S.split([sep [,maxsplit]]) -> list of strings
Function function
The string is sliced by specifying the separator sep. If the parameter maxsplit has a specified value, only maxsplit substrings are separated. If the separator sep is not given, it will be separated by spaces by default.
Function example
>>> s="sys❌3:3:Ownerofsystemfiles:/usr/sys:">>> s.split(":")['sys','x','3','3','Ownerofsystemfiles','/usr/sys','']>>> s.strip(":").split(":")['sys','x','3','3','Ownerofsystemfiles','/usr/sys']>>>len(s.strip(":").split(":"))6>>> s="sa aa aa as">>> s.split()['sa','aa','aa','as']
str.splitlines([keepends])
S.splitlines(keepends=False) -> list of strings
Function function
Separate by line, return a list containing each line as an element. If the parameter keepends=False and the latter is empty or 0, it does not contain "\n", otherwise it contains "\n"
Function example
>>> s="Line1-a b c d e f\nLine2- a b c\n\nLine4- a b c d">>> print s.splitlines()['Line1-a b c d e f','Line2- a b c','','Line4- a b c d']>>> print s.splitlines(0)['Line1-a b c d e f','Line2- a b c','','Line4- a b c d']>>> print s.splitlines(1)['Line1-a b c d e f\n','Line2- a b c\n','\n','Line4- a b c d']>>> print s.splitlines(2)['Line1-a b c d e f\n','Line2- a b c\n','\n','Line4- a b c d']>>> print s.splitlines(3)['Line1-a b c d e f\n','Line2- a b c\n','\n','Line4- a b c d']>>> print s.splitlines(4)['Line1-a b c d e f\n','Line2- a b c\n','\n','Line4- a b c d']
str.partition(sep)
S.partition(sep) -> (head, sep, tail)
Function function
Split the string according to the specified separator sep (returns a 3-element tuple, the first is the substring on the left of the separator, the second is the separator itself, and the third is the substring on the right of the separator) . And the separator cannot be empty or empty string, otherwise an error will be reported.
Function example
>>> s="are you know:lilin is lowser">>> s.partition("lilin")('are you know:','lilin',' is lowser')>>> s.partition("")Traceback(most recent call last):
File "<stdin>", line 1,in<module>
ValueError: empty separator
>>> s.partition()Traceback(most recent call last):
File "<stdin>", line 1,in<module>
TypeError:partition() takes exactly one argument(0 given)
modify###
str.strip([chars])
S.strip([chars]) -> string or unicode
Function function
Used to remove the specified characters at the beginning and end of the string (the default is a space). If the character is unicode, first convert the string to unicode and then perform the strip operation.
Function example
>>> s="egg is a apple">>> print s.strip("e")
gg is a appl
>>> s="\negg is a apple\n">>> print s
egg is a apple
>>> print s.strip("\n")
egg is a apple
str.lstrip([chars])
S.lstrip([chars]) ->string or unicode
Function function
It is used to cut off the spaces or specified characters on the left side of the string.
Function example
>>> s="egg is a apple">>> print s.lstrip("e")
gg is a apple
>>> s="\negg is a apple\n">>> print s.lstrip("\n")
egg is a apple
>>>
str.rstrip([chars])
S.rstrip([chars]) -> string or unicode
Function function
Used to cut off the spaces or specified characters on the right side of the string.
Function example
>>> s="egg is a apple">>> print s.rstrip("e")
egg is a appl
>>> s="\negg is a apple\n">>> print s.rstrip("\n")
egg is a apple
>>>
str.replace(old, new[, count])
S.replace(old, new[, count]) -> unicode
Function function
Replace old (old string) with new (new string) in the string. If the third parameter max is specified, the replacement will not exceed count times.
Function example
>>> s="saaas">>> s.replace("aaa","aa")'saas'>>> s="saaaas">>> s.replace("aaa","aa")'saaas'>>> s="saaaaas">>> s.replace("aaa","aa")'saaaas'>>> s="saaaaaas">>> s.replace("aaa","aa")'saaaas'
The above replacement does not replace it recursively. Every time it finds 3 a and replaces it with two a, and then continues to traverse from the position behind the 3 a instead of starting from the beginning.
coding###
There are two functions related to encoding str.decode([encoding[, errors]])hestr.encode([encoding[, errors]])
First understand several concepts related to coding
- str is a text sequence
- bytes is a sequence of bytes
- The text is encoded (utf-8, gbk, GB18030, etc.)
- Bytes are not encoded
- The encoding of text refers to how characters are represented by bytes
- Python3 strings use utf-8 encoding by default
>>> s ='Liu Yifei'>>>type(s)<class'str'>>>>help(s.encode)
Help on built-infunction encode:encode(...) method of builtins.str instance
S.encode(encoding='utf-8', errors='strict')-> bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore','replace' and
' xmlcharrefreplace'as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
# The default encoding is utf-8. The following is in accordance with the default encoding
>>> s.encode()
b'\xe5\x88\x98\xe4\xba\xa6\xe8\x8f\xb2'>>>'Liu'.encode()
b'\xe5\x88\x98'>>>'also'.encode()
b'\xe4\xba\xa6'>>>'Fei'.encode()
b'\xe8\x8f\xb2'>>>bin(0xe5)'0b11100101'>>>bin(0x88)'0b10001000'>>>bin(0x98)'0b10011000'>>> b = s.encode()>>> b
b'\xe5\x88\x98\xe4\xba\xa6\xe8\x8f\xb2'>>> b.decode()'Liu Yifei'
# The following is the designated code as GBK
>>> b = s.encode('GBK')>>> b
b'\xc1\xf5\xd2\xe0\xb7\xc6'>>> b.decode('GBK')'Liu Yifei'>>> b.decode()Traceback(most recent call last):
File "<stdin>", line 1,in<module>
UnicodeDecodeError:'utf-8' codec can't decode byte 0xc1in position 0: invalid start byte
The bytes type appears in the use of the encode and decode methods above. The following is a brief introduction to this type
- bytes are converted from str through the encode method
- Define bytes by prefix b
>>> b = b'\xe5\x88\x98'>>>type(b)<class'bytes'>>>> b
b'\xe5\x88\x98'>>> b.decode()'Liu'
In addition to encode, the str operation has a corresponding version of bytes, but the incoming parameter must also be bytes
Variable version of bytes bytearray
Bytearray is variable, and changing bytes are often used in image processing. Compared with bytes, bytearray has more operations such as insert, append, extend, pop, remove, and clear reverse, and can be indexed.
judgment###
str.startswith(prefix[, start[, end]])
Function function
It is used to judge whether the string starts with the specified prefix, if it ends with the specified suffix, it returns True, otherwise it returns False. The optional parameters "start" and "end" are the start and end positions of the search string. The prefix can be a tuple.
Function example
>>> s ="I am Mary,what's your name ?">>> s.startswith("I am")
True
>>> s.startswith("I are")
False
>>> s.startswith("I am",1,5)
False
str.endswith(suffix[, start[, end]])
S.endswith(suffix[, start[, end]]) -> bool
Function function
It is used to judge whether the string ends with the specified suffix, if it ends with the specified suffix, it returns True, otherwise it returns False. The optional parameters "start" and "end" are the start and end positions of the search string. Suffix can be tuple.
Function example
>>> s ="I am Mary,what's your name ?">>> print s
I am Mary,what's your name ?>>> s.endswith("name ?")
True
>>> s.endswith("mame ?")
False
>>> s.endswith("name ?",0,len(s)-2)
False
str.isalnum()
S.isalnum() -> bool
Function function
Check whether the string consists of letters or numbers. If it is, it returns True, if there are other characters, it returns False.
The string is not empty, if it is empty, it returns False.
Function example
>>> a="123">>> a.isalnum()
True
>>> a="daowihd">>> a.isalnum()
True
>>> a="ofaweo2131giu">>> a.isalnum()
True
>>> a="douha ioh~w80">>> a.isalnum()
False
>>> a="">>> a.isalnum()
False
str.isalpha()
S.isalpha() -> bool
Function function
Check whether the string consists of only letters. The string is not empty, if it is empty, it returns False.
Function example
>>> a="123">>> a.isalpha()
False
>>> a="uuagwifo">>> a.isalpha()
True
>>> a="oiwhdaw899hdw">>> a.isalpha()
False
>>> a="">>> a.isalpha()
False
str.isdigit()
S.isdigit() -> bool
Function function
Check whether the string consists only of numbers. The string is not empty, if it is empty, it returns False.
Function example
>>> a="123">>> a.isdigit()
True
>>> a="dowaoh90709">>> a.isdigit()
False
>>> a="">>> a.isdigit()
False
str.islower()
S.islower() -> bool
Function function
Check whether the string consists of lowercase letters.
Function example
>>> a="uigfa">>> a.islower()
True
>>> a="uiuiga123141a">>> a.islower()
True
>>> a="uiuiga12314WATA">>> a.islower()
False
>>> a="">>> a.islower()
False
>>> a="doiowhoid;'">>> a.islower()
True
str.isupper()
S.isupper() -> bool
Function function
Check whether the string consists of uppercase letters.
Function example
>>> a="SGS">>> a.isupper()
True
>>> a="SGSugdw">>> a.isupper()
False
>>> a="SGS123908;',">>> a.isupper()
True
str.isspace()
S.isspace() -> bool
Function function
Check if the string consists only of spaces
Function example
>>> a=" ">>> a.isspace()
True
>>> a=" 12 dw ">>> a.isspace()
False
References##
1、 Python 2.7.12 documentation
2、 Shaw Blog--Summary of Python str method
3、 hc-Python string manipulation
Recommended Posts