Python preliminary implementation of word2vec operation
I. Introduction
At first I saw that the installation of the word2vec environment was quite complicated, and Cygwin didn't understand it after installing it for a long time. Then I suddenly found out, why should I use the C language version? I should use the python version, and then I found gensim. You can use word2vec by installing a gensim package, but gensim only implements skip- in word2vec gram model. If you want to use other models, you need to study word2vec in other languages.
2. Corpus preparation
After having the gensim package, I read a lot of online tutorials that directly pass in a txt file, but what the txt file looks like and what kind of data format it is, many blogs do not explain, nor provide a txt file that can be downloaded as an example. After further understanding, I found that this txt is a well-divided file containing a lot of text. As shown in the figure below, it is a corpus that I trained myself. I selected 7000 news that I had previously crawled with a crawler as the corpus and performed word segmentation. Note that spaces must be used between words:
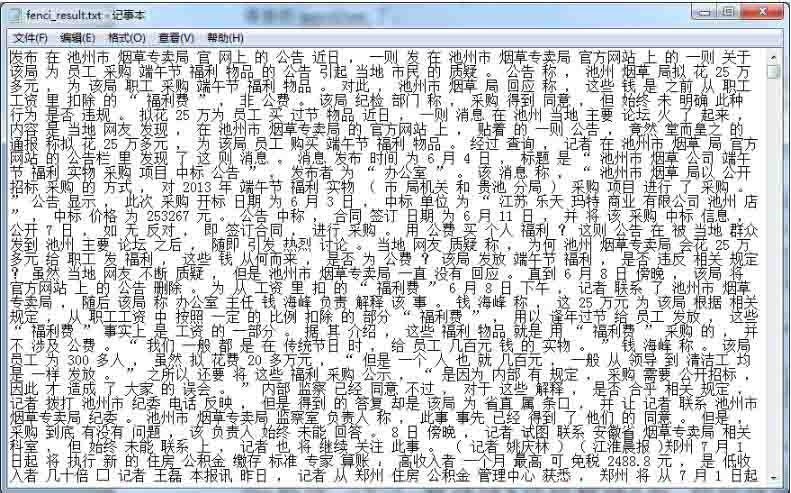
Here the participle uses the stammering participle.
This part of the code is as follows:
import jieba
f1 =open("fenci.txt")
f2 =open("fenci_result.txt",'a')
lines =f1.readlines() #Read all
for line in lines:
line.replace('\t','').replace('\n','').replace(' ','')
seg_list = jieba.cut(line, cut_all=False)
f2.write(" ".join(seg_list))
f1.close()
f2.close()
One thing to note is that there must be more texts in the corpus. Any corpus on the Internet has several Gs, and I used a piece of news as a corpus at the beginning. The result is very bad, and the output is all 0. Then I used 7000 news as a corpus, and the fenci_result.txt I got after word segmentation was 20M. Although it is not big, I can get preliminary results.
Three, use gensim's word2vec training model
The relevant code is as follows:
from gensim.modelsimport word2vec
import logging
# Main program
logging.basicConfig(format='%(asctime)s:%(levelname)s: %(message)s', level=logging.INFO)
sentences =word2vec.Text8Corpus(u"fenci_result.txt") #Load corpus
model =word2vec.Word2Vec(sentences, size=200) #Training skip-gram model, default window=5
print model
# Calculate the similarity of two words/Relevance
try:
y1 = model.similarity(u"country", u"State Council")
except KeyError:
y1 =0
print u"The similarity between [Country] and [State Council] is:", y1
print"-----\n"
#
# Calculate the related word list of a word
y2 = model.most_similar(u"Tobacco Control", topn=20) #20 most relevant
print u"The words most related to [tobacco control] are:\n"for item in y2:
print item[0], item[1]
print"-----\n"
# Find correspondence
print u"book-Good quality-"
y3 =model.most_similar([u'quality', u'Not bad'],[u'book'], topn=3)for item in y3:
print item[0], item[1]
print"----\n"
# Looking for out-of-group words
y4 =model.doesnt_match(u"Books, books, teaching materials".split())
print u"Incompatible words:", y4
print"-----\n"
# Save the model for reuse
model.save(u"book review.model")
# Corresponding loading method
# model_2 =word2vec.Word2Vec.load("text8.model")
# Store word vectors in a form that can be parsed by C language
# model.save_word2vec_format(u"book review.model.bin", binary=True)
# Corresponding loading method
# model_3 =word2vec.Word2Vec.load_word2vec_format("text8.model.bin",binary=True)
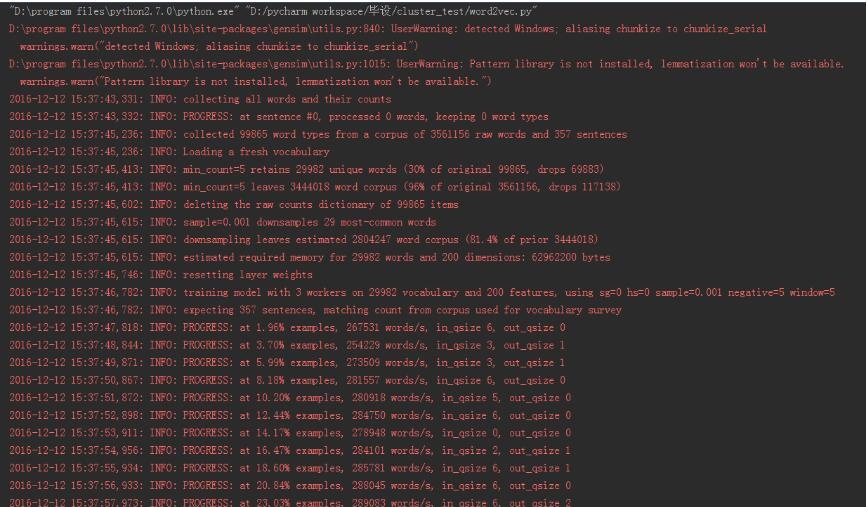
The output is as follows:
" D:\program files\python2.7.0\python.exe""D:/pycharm workspace/Set up/cluster_test/word2vec.py"
D:\program files\python2.7.0\lib\site-packages\gensim\utils.py:840: UserWarning: detected Windows; aliasing chunkize to chunkize_serial
warnings.warn("detected Windows; aliasing chunkize to chunkize_serial")
D:\program files\python2.7.0\lib\site-packages\gensim\utils.py:1015: UserWarning: Pattern library is not installed, lemmatization won't be available.
warnings.warn("Pattern library is not installed, lemmatization won't be available.")2016-12-1215:37:43,331: INFO: collecting all words and their counts
2016- 12- 1215:37:43,332: INFO: PROGRESS: at sentence #0, processed 0 words, keeping 0 word types
2016- 12- 1215:37:45,236: INFO: collected 99865 word types from a corpus of3561156 raw words and 357 sentences
2016- 12- 1215:37:45,236: INFO: Loading a fresh vocabulary
2016- 12- 1215:37:45,413: INFO: min_count=5 retains 29982 unique words(30%of original 99865, drops 69883)2016-12-1215:37:45,413: INFO: min_count=5 leaves 3444018 word corpus(96%of original 3561156, drops 117138)2016-12-1215:37:45,602: INFO: deleting the raw counts dictionary of99865 items
2016- 12- 1215:37:45,615: INFO: sample=0.001 downsamples 29 most-common words
2016- 12- 1215:37:45,615: INFO: downsampling leaves estimated 2804247 word corpus(81.4%of prior 3444018)2016-12-1215:37:45,615: INFO: estimated required memory for29982 words and 200 dimensions:62962200 bytes
2016- 12- 1215:37:45,746: INFO: resetting layer weights
2016- 12- 1215:37:46,782: INFO: training model with3 workers on 29982 vocabulary and 200 features, using sg=0 hs=0 sample=0.001 negative=5 window=52016-12-1215:37:46,782: INFO: expecting 357 sentences, matching count from corpus used for vocabulary survey
2016- 12- 1215:37:47,818: INFO: PROGRESS: at 1.96% examples,267531 words/s, in_qsize 6, out_qsize 02016-12-1215:37:48,844: INFO: PROGRESS: at 3.70% examples,254229 words/s, in_qsize 3, out_qsize 12016-12-1215:37:49,871: INFO: PROGRESS: at 5.99% examples,273509 words/s, in_qsize 3, out_qsize 12016-12-1215:37:50,867: INFO: PROGRESS: at 8.18% examples,281557 words/s, in_qsize 6, out_qsize 02016-12-1215:37:51,872: INFO: PROGRESS: at 10.20% examples,280918 words/s, in_qsize 5, out_qsize 02016-12-1215:37:52,898: INFO: PROGRESS: at 12.44% examples,284750 words/s, in_qsize 6, out_qsize 02016-12-1215:37:53,911: INFO: PROGRESS: at 14.17% examples,278948 words/s, in_qsize 0, out_qsize 02016-12-1215:37:54,956: INFO: PROGRESS: at 16.47% examples,284101 words/s, in_qsize 2, out_qsize 12016-12-1215:37:55,934: INFO: PROGRESS: at 18.60% examples,285781 words/s, in_qsize 6, out_qsize 12016-12-1215:37:56,933: INFO: PROGRESS: at 20.84% examples,288045 words/s, in_qsize 6, out_qsize 02016-12-1215:37:57,973: INFO: PROGRESS: at 23.03% examples,289083 words/s, in_qsize 6, out_qsize 22016-12-1215:37:58,993: INFO: PROGRESS: at 24.87% examples,285990 words/s, in_qsize 6, out_qsize 12016-12-1215:38:00,006: INFO: PROGRESS: at 27.17% examples,288266 words/s, in_qsize 4, out_qsize 12016-12-1215:38:01,081: INFO: PROGRESS: at 29.52% examples,290197 words/s, in_qsize 1, out_qsize 22016-12-1215:38:02,065: INFO: PROGRESS: at 31.88% examples,292344 words/s, in_qsize 6, out_qsize 02016-12-1215:38:03,188: INFO: PROGRESS: at 34.01% examples,291356 words/s, in_qsize 2, out_qsize 22016-12-1215:38:04,161: INFO: PROGRESS: at 36.02% examples,290805 words/s, in_qsize 6, out_qsize 02016-12-1215:38:05,174: INFO: PROGRESS: at 38.26% examples,292174 words/s, in_qsize 3, out_qsize 02016-12-1215:38:06,214: INFO: PROGRESS: at 40.56% examples,293297 words/s, in_qsize 4, out_qsize 12016-12-1215:38:07,201: INFO: PROGRESS: at 42.69% examples,293428 words/s, in_qsize 4, out_qsize 12016-12-1215:38:08,266: INFO: PROGRESS: at 44.65% examples,292108 words/s, in_qsize 1, out_qsize 12016-12-1215:38:09,295: INFO: PROGRESS: at 46.83% examples,292097 words/s, in_qsize 4, out_qsize 12016-12-1215:38:10,315: INFO: PROGRESS: at 49.13% examples,292968 words/s, in_qsize 2, out_qsize 22016-12-1215:38:11,326: INFO: PROGRESS: at 51.37% examples,293621 words/s, in_qsize 5, out_qsize 02016-12-1215:38:12,367: INFO: PROGRESS: at 53.39% examples,292777 words/s, in_qsize 2, out_qsize 22016-12-1215:38:13,348: INFO: PROGRESS: at 55.35% examples,292187 words/s, in_qsize 5, out_qsize 02016-12-1215:38:14,349: INFO: PROGRESS: at 57.31% examples,291656 words/s, in_qsize 6, out_qsize 02016-12-1215:38:15,374: INFO: PROGRESS: at 59.50% examples,292019 words/s, in_qsize 6, out_qsize 02016-12-1215:38:16,403: INFO: PROGRESS: at 61.68% examples,292318 words/s, in_qsize 4, out_qsize 22016-12-1215:38:17,401: INFO: PROGRESS: at 63.81% examples,292275 words/s, in_qsize 6, out_qsize 02016-12-1215:38:18,410: INFO: PROGRESS: at 65.71% examples,291495 words/s, in_qsize 4, out_qsize 12016-12-1215:38:19,433: INFO: PROGRESS: at 67.62% examples,290443 words/s, in_qsize 6, out_qsize 02016-12-1215:38:20,473: INFO: PROGRESS: at 69.58% examples,289655 words/s, in_qsize 6, out_qsize 22016-12-1215:38:21,589: INFO: PROGRESS: at 71.71% examples,289388 words/s, in_qsize 2, out_qsize 22016-12-1215:38:22,533: INFO: PROGRESS: at 73.78% examples,289366 words/s, in_qsize 0, out_qsize 12016-12-1215:38:23,611: INFO: PROGRESS: at 75.46% examples,287542 words/s, in_qsize 5, out_qsize 12016-12-1215:38:24,614: INFO: PROGRESS: at 77.25% examples,286609 words/s, in_qsize 3, out_qsize 02016-12-1215:38:25,609: INFO: PROGRESS: at 79.33% examples,286732 words/s, in_qsize 5, out_qsize 12016-12-1215:38:26,621: INFO: PROGRESS: at 81.40% examples,286595 words/s, in_qsize 2, out_qsize 02016-12-1215:38:27,625: INFO: PROGRESS: at 83.53% examples,286807 words/s, in_qsize 6, out_qsize 02016-12-1215:38:28,683: INFO: PROGRESS: at 85.32% examples,285651 words/s, in_qsize 5, out_qsize 32016-12-1215:38:29,729: INFO: PROGRESS: at 87.56% examples,286175 words/s, in_qsize 6, out_qsize 12016-12-1215:38:30,706: INFO: PROGRESS: at 89.86% examples,286920 words/s, in_qsize 5, out_qsize 02016-12-1215:38:31,714: INFO: PROGRESS: at 92.10% examples,287368 words/s, in_qsize 6, out_qsize 02016-12-1215:38:32,756: INFO: PROGRESS: at 94.40% examples,288070 words/s, in_qsize 4, out_qsize 22016-12-1215:38:33,755: INFO: PROGRESS: at 96.30% examples,287543 words/s, in_qsize 1, out_qsize 02016-12-1215:38:34,802: INFO: PROGRESS: at 98.71% examples,288375 words/s, in_qsize 4, out_qsize 02016-12-1215:38:35,286: INFO: worker thread finished; awaiting finish of2 more threads
2016- 12- 1215:38:35,286: INFO: worker thread finished; awaiting finish of1 more threads
Word2Vec(vocab=29982, size=200, alpha=0.025)
The similarity between [Country] and [State Council] is: 0.387535493256-----2016-12-1215:38:35,293: INFO: worker thread finished; awaiting finish of0 more threads
2016- 12- 1215:38:35,293: INFO: training on 17805780 raw words(14021191 effective words) took 48.5s,289037 effective words/s
2016- 12- 1215:38:35,293: INFO: precomputing L2-norms of word weight vectors
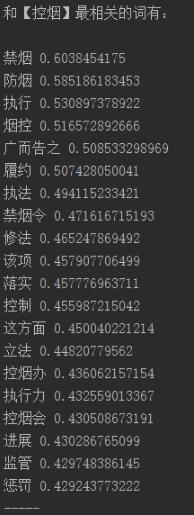
The words most related to [tobacco control] are:
No smoking 0.6038454175
Smoke prevention 0.585186183453
Execute 0.530897378922
Tobacco control 0.516572892666
Advertised 0.508533298969
Performance 0.507428050041
Enforcement 0.494115233421
No smoking ban 0.471616715193
Modification 0.465247869492
Item 0.457907706499
Implementation 0.457776963711
Control 0.455987215042
This aspect 0.450040221214
Legislation 0.44820779562
Tobacco Control Office 0.436062157154
Execution 0.432559013367
Tobacco Control Meeting 0.430508673191
Progress 0.430286765099
Supervision 0.429748386145
Penalty 0.429243773222-----
book-Good quality-
Survival 0.613928854465
Stable 0.595371186733
Overall 0.592055797577----
Incompatible words: very
- - - - - 2016- 12- 1215:38:35,515: INFO:saving Word2Vec object under book review.model, separately None
2016- 12- 1215:38:35,515: INFO: not storing attribute syn0norm
2016- 12- 1215:38:35,515: INFO: not storing attribute cum_table
2016- 12- 1215:38:36,490: INFO:saved book review.model
Process finished with exit code 0


The above python preliminary implementation of word2vec operation is all the content shared by the editor, I hope to give you a reference.
Recommended Posts