Python uses pandas to process Excel data
The computer system of the editor is Windows10 Home Edition, 64-bit. I found N methods on the Internet, but they are too complicated to write. The following is the feasible method I tried.
1 : Pandas depends on the xlrd module that handles Excel, so we need to install this in advance, the installation command is: pip install xlrd
2 : The installation of pandas module also requires a certain coding environment, so when we install ourselves, make sure that your computer has these environments: Net.4, VC-Compiler and winsdk_web.
3 : After steps 1 and 2 are ready, we can start to install pandas, update the latest version of pandas: pip install pandas==0.24.0
4 : Pip show pandas can check whether you have installed the latest version. If you do not install the latest version, some libraries will be missing in pandas, which will cause your Python code execution to fail.
ps: During this process, you may encounter unsatisfactory installation. The omnipotent Duniang has N solutions. You should learn to solve the problem by yourself.
import pandas as pd
df=pd.read_excel('test_data_xiejinjieguo_chongzhi.xlsx',sheet_name='recharge')
# print(df.values)Read all lines
# print(df.ix[:].values)Read all
# print(df.ix[1:1].values)It counts from 0
# print(df.ix[:])Read out in matrix form
# print(df.ix[:,['url']].values)Read the specified column of the specified row
# print(df.ix[:,['url','data']].values)Specify multiple lines
# print(df.ix[1,['url','data','title','case_id','http_method']].to_dict())Specify the column to be read
# print(df.ix[1].to_dict())All fields are read by default
# print(df.index.values)#01234 Removed the headers in Excel modules by default, such as url,test_method
test_data=[]#See all use cases and results
for i in df.index.values:
row_data=df.ix[i,['url','data','title','case_id','http_method']].to_dict()
test_data.append(row_data)print(test_data)
My code file structure is as follows:
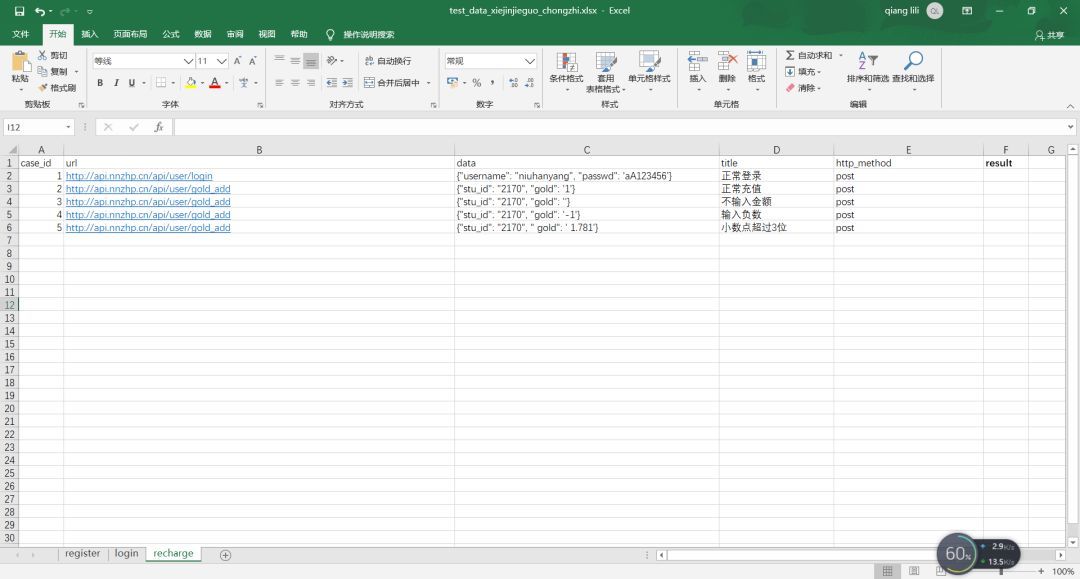
The contents of Excel are as follows:
Note: The absolute path and relative path in Pycharm must be clarified, otherwise it will cause an error when the code runs.
Recommended Posts