Python data analysis
Python data analysis
If you want to do good things, you must first sharpen your tools.” Python is by far the most commonly used programming language for data analysis. We can stand on the shoulders of giants and complete data analysis efficiently.
Let's first understand the development history of Python. Python language was born in the 1980s. It was developed by the Dutchman Guido van Rossum. We call Guido van Rossum the father of Python. It is worth mentioning the origin of the name Python. Python means python, but Guido's name has nothing to do with python. When Guido was implementing Python, he also read the script of Monty Python's Flying Circus, which is from a BBC comedy from the 1970s. Guido thought he needed a short, unique and slightly mysterious name, so he decided to call the language Python.
Python 1.0 version was released in January 1994. The main new features of this version are lambda, map, filter and reduce, but Guido doesn't like this version.
Six and a half years later, in October 2000, Python 2.0 was released. The main new features of this version are memory management and cycle detection garbage collector and support for Unicode. However, the most important change is the change in the development process, and Python now has a more transparent community.
2008 In December of the year, Python3.0 was released. Python3.x is not backward compatible with Python2.x, which means that Python3.x may not be able to run Python2.x code. Python3 represents the future of the Python language.
Today's Python has entered the 3,0 era, and the Python community is also booming. When you ask a Python problem, almost always someone has encountered the same problem and has already solved it.
Features of Python language:
Python is a completely object-oriented language. Functions, modules, numbers, and strings are all objects. In Python, everything is an object. Supports overloaded operators and also supports generic design.
Python has a powerful standard library. The core of the Python language only contains common types and functions such as numbers, strings, lists, dictionaries, and files. The Python standard library provides system management, network communication, text processing, database interfaces, and graphics. System, XML processing and other additional functions.
The Python community provides a large number of third-party modules, which are used in a similar way to the standard library. Their functions cover scientific computing, artificial intelligence, machine learning, Web development, database interfaces, and graphics systems.
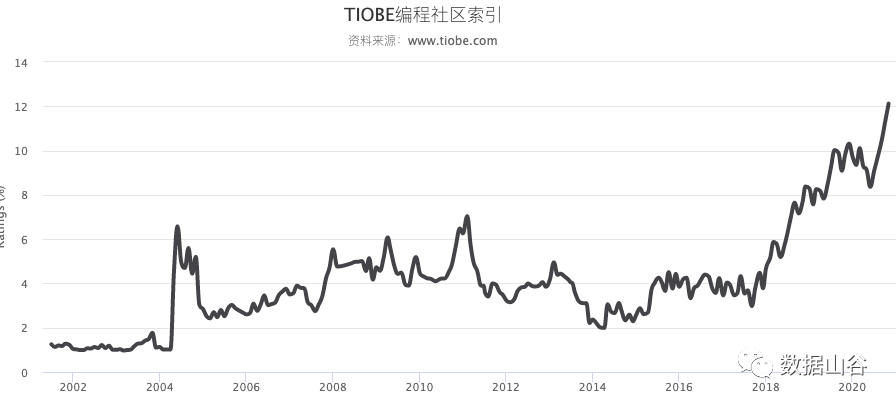
Because Python has powerful functions, it is easy to use and easy to get started. We often hear people say "Life is short, I use Python". Research organization Tiobe released an analysis report for October 2020 this week, and the Python language ranked third for two consecutive years. In the latest data for November 2020, Python surpassed Java to become the second place with an unstoppable trend.
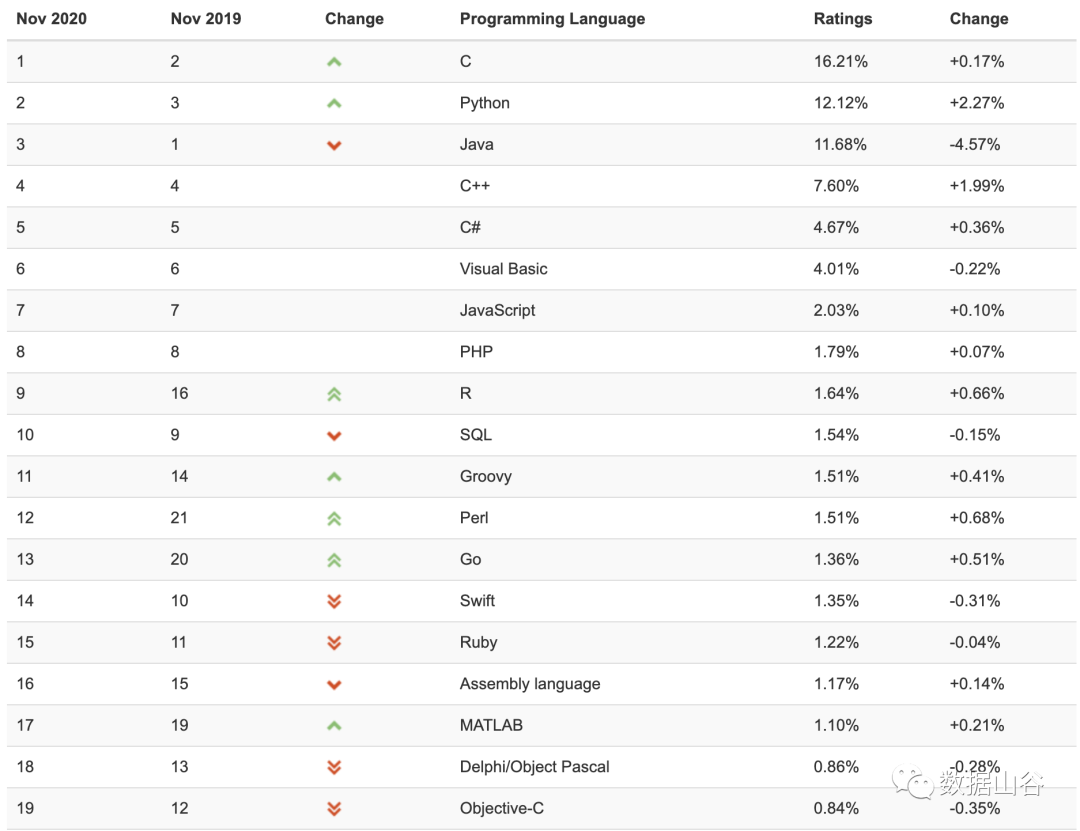
It is particularly important to choose a suitable programming language. The Python language is simple, easy to learn, fast, free and open source. It focuses on how to solve problems, a free and open community environment, and a wealth of third-party libraries. There is no need to waste time making wheels: various Web frameworks, crawler frameworks, data analysis frameworks, machine learning frameworks have everything, ready to use. From the perspective of Python’s popularity, it has been on the rise
We are now going to use Python to do data analysis, mainly from two aspects to consider the problem:
First: what development tool to choose.
Second: What knowledge to learn to solve the problem of data analysis.
I recommend Anaconda as a development tool. The specific software can be downloaded from the open source mirror website of Tsinghua University (https://mirror.tuna.tsinghua.edu.cn/help/anaconda/) and download the corresponding version of the installation package according to the software and hardware environment of the computer you are using. After the installation is complete, enter jupyter notebook in the console.
There is a detailed anaconda installation process in this official account. The article link is as follows:
Anaconda installation process
Brother Dabin, public account: Data Valley [Python Anaconda Installation] (http://mp.weixin.qq.com/s?__biz=MzUxMTAzOTkzMQ==&mid=2247484820&idx=2&sn=66db50025112ee7401a3fd8545ea2ca9&chksm=f9788540ce0f0c562938d717e4442f3890f9714273295723ed334a95ece8b9ade33fc7ea5d76#rd)
Knowledge points in Python and common scientific computing libraries used in data analysis also need to be listed for everyone:
Basic syntax: variables, data types, conditions, loops.
Data structure: collection, tuple, dictionary.
Input and output
Module
class
Scientific computing libraries: NumPy, Pandas, Matplotlib, Seaborn.
Python does data analysis mainly to solve the problems of data cleaning and data visualization. It is very important to master the basic grammatical rules of Python and call third-party modules to improve data analysis capabilities. NumPy and Pandas are the best tools for data cleaning, and Matplotlib and Seaborn are toolkits for data visualization. We can learn Python from a practical perspective to improve the ability and efficiency of data analysis.