Centos6.9でのRabbitMQクラスター展開レコード
[CentOSでのRabbltMQ環境の単一マシン展開の操作記録](https://cloud.tencent.com/developer/article/1027419?from=10680)を簡単に紹介しました。以下はRabbitMQクラスターの知識の詳細な説明です。RabbitMQはerlangで開発されています。erlangは分散言語として生まれているため、クラスターは非常に便利ですが、 [負荷分散](https://cloud.tencent.com/product/clb?from=10680)はサポートしていません。
ラビットクラスターモードは、シングルモード、ノーマルモード、ミラーモードの3種類に大別されます。
1 )シングルモード:最も単純なケースである非クラスターモードでは、何も言うことはありません。
2 )通常モード:デフォルトのクラスターモード。
-
キューの場合、メッセージエンティティはノードの1つにのみ存在し、2つのノードAとBは同じメタデータ、つまりキュー構造を持っています。
-
メッセージがノードAのキューに入り、消費者がノードBからプルすると、RabbitMQは一時的にAとBの間でメッセージを送信し、Aのメッセージエンティティを取り出してBを介して消費者に送信します。
-
したがって、コンシューマーは各ノードに接続して、そこからメッセージを取得する必要があります。つまり、同じ論理キューの場合、物理キューを複数のノードで確立する必要があります。そうしないと、消費者がAまたはBのどちらに接続しているかに関係なく、エクスポートは常にAで行われるため、ボトルネックが発生します。
-
このモードの問題の1つは、ノードAに障害が発生すると、ノードBがノードAで消費されていないメッセージエンティティを取得できないことです。
-
メッセージが永続化されている場合は、ノードAが回復するのを待ってから消費する必要があります。永続化がない場合は、それ以上はありません。
3 )ミラーモード:必要なキューをミラーキューにします。ミラーキューは複数のノードに存在し、RabbitMQのHAソリューションに属します。 -
このモードは上記の問題を解決します。通常モードとの本質的な違いは、メッセージエンティティが、コンシューマーがデータをフェッチするときに一時的にプルするのではなく、ミラーノード間でアクティブに同期することです。
-
このモードの副作用も明らかです。システムパフォーマンスの低下に加えて、ミラーキューが多すぎて大量のメッセージが入力されると、クラスター内のネットワーク帯域幅がこの同期通信によって大幅に消費されます。
-
したがって、このモードは、信頼性の要件が高い場合(次の図で説明するクラスターモードなど)に適しています。
RabbitMQクラスターの基本概念:
1 )RabbitMQのクラスターノードには、メモリノードとディスクノードが含まれます。名前が示すように、メモリノードはすべてのデータをメモリに配置し、ディスクノードはデータをディスクに配置します。ただし、前述のように、メッセージの配信時にメッセージの永続性をオンにすると、メモリノードであっても、データは安全にディスクに保存されます。
2 )rabbitmqクラスターは、ユーザー、vhost、キュー、交換などを共有でき、すべてのデータとステータスをすべてのノードに複製する必要があります。1つの例外は、それを作成したノードに現在属している[メッセージキュー](https://cloud.tencent.com/product/cmq?from=10680)です。 )、ただし、すべてのノードで表示および読み取り可能です。 rabbitmqノードは、クラスターに動的に追加できます。ノードをクラスターに追加することも、クラスターリングクラスターから基本的な負荷分散を実行することもできます。
RabbitMQクラスターには2つのタイプのノードがあります:
1 )Ramメモリノード:状態をメモリにのみ保存します(例外:永続キューの永続コンテンツはディスクに保存されます)
2 )ディスクディスクノード:状態をメモリとディスクに保存します。
メモリノードはディスクに書き込みませんが、ディスクノードよりもパフォーマンスが優れています。 RabbitMQクラスターでは、状態を保存するために必要なディスクノードは1つだけです。クラスター内にメモリノードしかない場合、それらを停止することはできません。そうしないと、すべての状態、メッセージなどが失われます。
RabbitMQクラスターのアイデア:
具体的には、RabbitMQの高可用性を実現する方法として、最初に共通クラスターモードを構築し、次にこのモデルに基づいて高可用性を実現するようにミラーモードを構成し、Rabbitクラスターの前にリバースプロキシを追加し、プロデューサーとコンシューマーがリバースプロキシを介してRabbitMQクラスターにアクセスします。 。
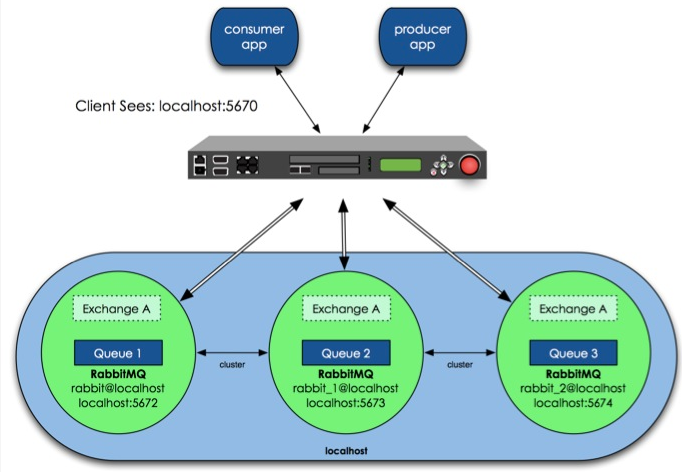
上の図では、3つのRabbitMQが同じホストで実行されており、異なるサービスポートを使用しています。もちろん、実稼働環境では、複数のRabbitMQを異なる物理サーバーで実行する必要があります。そうしないと、高可用性の意味が失われます。
RabbitMQクラスターモード構成
設計アーキテクチャは次のとおりです。クラスタには3つのマシンがあり、そのうちの1つはディスクモードを使用し、他の2つはメモリモードを使用します。 2つのメモリモードノードは間違いなく高速であるため、クライアント(消費者、プロデューサー)はそれらにアクセスするために接続します。ディスクモードノードは、ディスクIOが比較的遅いため、データバックアップにのみ使用され、もう1つはリバースプロキシとして使用されます。
RabbitMQクラスターの構成は非常に簡単で、次の例のように、いくつかのコマンドのみが必要です。構成手順について簡単に説明します。
最初のステップ: queue、kevintest1、kevintest2をRabbitMQクラスターノードとして、それぞれRabbitMq-Serverをインストールし、インストール後にRabbitMq-serverを起動します。
開始コマンド
# Rabbit-Server start
**ステップ2:**インストールされている3つのノードサーバーで、/ etc / hostsファイルをそれぞれ変更して、キュー、kevintest1、およびkevintest2のホストを指定します。
172.16.3.32 queue
172.16.3.107 kevintest1
172.16.3.108 kevintest2
3つのノードのホスト名は正しい必要があります。ホスト名はqueue、kevintest1、およびkevintest2です。ホスト名を変更する場合は、rabbitmqをインストールする前に変更することをお勧めします。 RabbitMQクラスターノードは同じネットワークセグメントに存在する必要があることに注意してください。
広域ネットワーク全体にある場合、効果は不十分です。
**ステップ3:**各ノードのCookieを設定する
Rabbitmqクラスターはerlangクラスターに依存して機能するため、最初にerlangクラスター環境を構築する必要があります。 Erlangクラスターの各ノードは、次の場所に保存されているマジックCookieを介して実装されます。
/var/lib/rabbitmq/.erlang.Cookieでは、ファイルには400の権限があります。したがって、各ノードのCookieが一貫していることを確認する必要があります。そうしないと、ノードは通信できません。
# ll /var/lib/rabbitmq/.erlang.cookie
- r--------1rabbitmqrabbitmq600年12月21日:40/var/lib/rabbitmq/.erlang.cookie
キューに入れます/var/lib/rabbitmq/.erlang.cookieファイルはkevintest1とkevintest2の同じ場所にコピーされます(逆も可能です)。このファイルは、クラスターノード間の通信の検証キーです。
ノードは一貫している必要があります。コピー後、RabbitMQを再起動します。コピー後に復元することを忘れないでください.erlang.Cookieのアクセス許可。そうしないと、エラーが発生する可能性があります
# chmod 400/var/lib/rabbitmq/.erlang.cookie
Cookieを設定した後、3つのノードのrabbitmqを再起動します
# rabbitmqctl stop
# rabbitmq-server start
**ステップ4:**すべてのノードでRabbitMqサービスを停止し、次に切り離されたパラメーターを使用して独立して実行します。このステップは非常に重要です。特に、ノードを停止した後にノードを再開できない場合は、このシーケンスを参照できます。
[ root@queue ~]# rabbitmqctl stop
[ root@kevintest1 ~]# rabbitmqctl stop
[ root@kevintest2 ~]# rabbitmqctl stop
[ root@queue ~]# rabbitmq-server -detached
[ root@kevintest1 ~]# rabbitmq-server -detached
[ root@kevintest2 ~]# rabbitmq-server -detached
各ノードを個別に表示
[ root@queue ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@queue ...[{nodes,[{disc,[rabbit@queue]}]},{running_nodes,[rabbit@queue]},{partitions,[]}]...done.[root@kevintest1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@kevintest1...[{nodes,[{disc,[rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest1]},{partitions,[]}]...done.[root@kevintest2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@kevintest2...[{nodes,[{disc,[rabbit@kevintest2]}]},{running_nodes,[rabbit@kevintest2]},{partitions,[]}]...done.
**手順5:**メモリノードとしてkevintest1とkevintest2をキューに接続します。kevintest1で、次のコマンドを実行します。
[ root@kevintest1 ~]# rabbitmqctl stop_app
[ root@kevintest1 ~]# rabbitmqctl join_cluster --ram rabbit@queue
[ root@kevintest1 ~]# rabbitmqctl start_app
[ root@kevintest2 ~]# rabbitmqctl stop_app
[ root@kevintest2 ~]# rabbitmqctl join_cluster --ram rabbit@queue #Kevintest1が上記のキューに接続されているか、kevintest2がkevintest1に直接接続されており、同じものがクラスターに追加されています
[ root@kevintest2 ~]# rabbitmqctl start_app
1 )上記のコマンドは、最初にrabbitmqアプリケーションを停止し、次にclusterコマンドを呼び出してkevintest1を接続し、2つをクラスターにし、最後にrabbitmqアプリケーションを再起動します。
2 )このclusterコマンドでは、kevintest1とkevintest2はメモリノードであり、queueはディスクノードです(RabbitMQが開始された後、デフォルトはディスクノードです)。
3 )キューがkevintest1またはkevintest2をクラスター内のディスクノードにもしたい場合は、参加します_clusterコマンドを削除します--ラムパラメータ
# rabbitmqctl join_cluster rabbit@queue
ノードリストに含まれている限り、ディスクノードになります。 RabbitMQクラスターには、少なくとも1つのディスクノードが存在する必要があります。
**手順6:**キューkevintest1、kevintest2で、cluster_statusコマンドを実行してクラスターのステータスを表示します。
# rabbitmqctl cluster_status
Cluster status of node rabbit@queue ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@kevintest2,rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest2,rabbit@kevintest1,rabbit@queue]},{partitions,[]}]...done.[root@kevintest1 rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@kevintest1 ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@kevintest2,rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest2,rabbit@queue,rabbit@kevintest1]},{partitions,[]}]...done.[root@kevintest2 rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@kevintest2 ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@kevintest2,rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest1,rabbit@queue,rabbit@kevintest2]},{partitions,[]}]...done.
このとき、各ノードのクラスタ情報を確認できます。2つのメモリノードと1つのディスクノードがあります。
**手順7:**メッセージキューを任意のクラスターノードに書き込むと、別のノードにコピーされます。2つのノードのメッセージキューの数が同じであることがわかります。
[ root@kevintest2 ~]# rabbitmqctl list_queues -p hrsystem
Listing queues …
test_queue 10000
…done.[root@kevintest1 ~]# rabbitmqctl list_queues -p hrsystem
Listing queues …
test_queue 10000
…done.[root@queue ~]# rabbitmqctl list_queues -p hrsystem
Listing queues …
test_queue 10000
…done.-pパラメータはvhost名です
このように、RabbitMQクラスターは正常に機能します。このモードは、非永続キューに適しています。キューが非永続である場合にのみ、クライアントはクラスター内の他のノードに再接続してキューを再作成できます。キューが永続的である場合、唯一の方法は障害が発生したノードを回復することです。RabbitMQがクラスター内のすべてのノードにキューを複製しないのはなぜですか。これは、クラスターの設計と矛盾します。クラスターの設計目的は、ノードが追加されたときにパフォーマンス(CPU、メモリ)と容量(メモリ、ディスク)を直線的に増加させることです。その理由は次のとおりです。もちろん、新しいバージョンのRabbitMQはキューレプリケーションもサポートしています(構成するオプションがあります)。たとえば、5つのノードがあるクラスターでは、パフォーマンスと高可用性のバランスをとるために、特定のキューのコンテンツを2つのノードに格納するように指定できます。
============= RabbitMQメッセージキュー内のすべてのデータをクリーンアップします============
以下の方法:
# rabbitmqctl list_queues //すべてのキューデータを表示
# rabbitmqctl stop_app //アプリケーションを最初に閉じる必要があります。そうしないと、クリアできません
# rabbitmqctl reset
# rabbitmqctl start_app
# rabbitmqctl list_queues //この時点で、リストとキューはすべて空です
=========================================================================================
RabbitMQクラスター:
1 )RabbitMQブローカークラスターは複数のerlangノードの論理グループであり、各ノードはrabbitmqアプリケーションを実行し、ユーザー、仮想ホスト、キュー、交換、バインディング、およびランタイムパラメーターを共有します。
2 )RabbitMQクラスター間で複製される情報:メッセージキュー(他のノードから見えるノードがあり、キューへのアクセス、キューの複製を実現するには、キューHAを実行する必要があります)に加えて、任意のrabbitmqブローカーでのすべての操作データと状態はすべてのノード間で複製されます。
3 )RabbitMQメッセージキューは非常に基本的なキーサービスです。このペーパーでは、3つのrabbitMQサーバーがブローカークラスター、1つのマスターと2つのスレーブを構築します。サービスに影響を与えずに2台のサーバーに障害が発生するのを許可します。
RabbitMQクラスターの目的
1 )RabbitMQノードがクラッシュした場合でも、コンシューマーとプロデューサーが実行を継続できるようにします
2 )ノードを追加してメッセージ通信のスループットを拡張します
RabbitMQクラスター操作の前提:
1 )クラスター内のすべてのノードは、同じerlangバージョンとrabbitmqバージョンを実行する必要があります
2 )ホスト名が解決され、ノードはドメイン名を介して相互に通信します。この記事は、ホストの構成形式を使用した3つのノードのクラスターです。
RabbitMQポートと使用法
1 )5672クライアント接続の目的
2 )15672Web管理インターフェイス
3 )25672クラスター通信の目的
RabbitMQクラスターを構築する方法:
1 )rabbitmqctlによる手動設定(この記事ではこの方法を使用します)
2 )構成ファイルを介して宣言
3 )rabbitmq-autoclusterプラグイン宣言を介して
4 )rabbitmq-clustererプラグインステートメントを介して
RabbitMQクラスターの障害処理メカニズム:
1 )rabbitmqブローカークラスターを使用すると、個々のノードをダウンさせることができます。
2 )クラスタのネットワークパーティション(ネットワークパーティション)に対応
RAbbitMQクラスターはWAN環境ではなくLAN環境に推奨されます。WANを介してブローカーに接続するには、ShovelまたはFederationプラグインが最適なソリューションです。ShovelまたはFederationはクラスターとは異なります。
RabbitMQクラスターのノード動作モード:
データの耐久性を確保するために、現在すべてのノードノードがディスクモードで実行されています。将来的に多くのプレッシャーがあり、パフォーマンスを改善する必要がある場合は、ramモードの使用を検討してください。
RabbitMQノードタイプ
1 )RAMノード:メモリノードは、すべてのキュー、スイッチ、バインディング、ユーザー、アクセス許可、およびvhostメタデータ定義をメモリに格納します。利点は、スイッチやキュー宣言などの操作を高速化できることです。
2 )ディスクノード:メタデータをディスクに保存します。シングルノードシステムでは、RabbitMQの再起動時に、ディスクタイプのノードのみがシステム構成情報の損失を防ぐことができます。
問題の説明:
RabbitMQには、クラスター内に少なくとも1つのディスクノードが必要であり、他のすべてのノードはメモリノードにすることができます。ノードがクラスターに参加またはクラスターから離脱する場合、変更を少なくとも1つのディスクノードに通知する必要があります。
クラスタ内の唯一のディスクノードがクラッシュした場合でも、クラスタは実行を継続できますが、ノードが復元されるまで、他の操作(追加、削除、変更、およびチェック)を実行できません。
解決策:2つのディスクノードをセットアップします。そのうちの少なくとも1つは使用可能であり、メタデータの変更を保存できます。
RabbitMQクラスターノードはどのように相互に認証しますか:
1 )Erlang Cookieを使用すると、共有秘密鍵の概念と同等になります。すべてのノードに一貫性がある限り、長さは任意です。
2 )rabbitmqサーバーが起動すると、erlangVMはランダムなCookieファイルを自動的に作成します。 cookieファイルの場所は/var/lib/rabbitmq/.erlang.cookieまたは/root/.erlang.cookieです。cookieが完全に一貫していることを確認するために、ノードからコピーする方法が採用されています。
**Erlang Cookie **は、さまざまなノードが相互に通信できるようにするための鍵です。クラスター内のさまざまなノードが相互に通信できるようにするには、同じErlangCookieを共有する必要があります。特定のディレクトリは/var/lib/rabbitmq/.erlang.cookieに保存されます。
**注:**これはrabbitmqctlコマンドの動作原理から始まります。RabbitMQの最下層はErlangアーキテクチャを介して実装されるため、rabbitmqctlはErlangノードを起動し、Erlangシステムを使用してErlangノードに基づいてRabbitMQノードに接続します。接続プロセス中に必要です。正しいErlangCookieとノード名を使用すると、ErlangノードはErlangCookieを交換することによって認証を取得します。
**======= 以下は、CentOS6.9 ======= **でのRabbitMQクラスターの展開プロセスを記録しています。
クラスターマシン情報:
rabbitmq01.kevin.cn 192.168.1.40
rabbitmq02.kevin.cn 192.168.1.41
rabbitmq03.kevin.cn 192.168.1.421)ホストのホスト解像度を設定する,rabbitmqクラスター通信の場合、すべてのノードの構成は同じです。
[ root@rabbitmq01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.40 rabbitmq01.kevin.cn
192.168.1.41 rabbitmq02.kevin.cn
192.168.1.42 rabbitmq03.kevin.cn
他の2つのノードのホスト構成は同じです。
2 )Rabbitmq環境は3つのノードサーバーにデプロイする必要があります。以下を参照できます:http://www.cnblogs.com/kevingrace/p/7693042.html
フォアグラウンドでrabbitmqサービスを実行します:
# /etc/init.d/rabbitmq-server start(ユーザーが接続を閉じた後,プロセスを自動的に終了します)
または
# rabbitmq-server start
起動を設定する
# chkconfig rabbitmq-server on
バックグラウンドでrabbitmqサービスを実行する:
# rabbitmq-server -detached
# lsof -i:5672
# lsof -i:15672
# lsof -i:25672
各ノードのステータスを表示します。
# rabbitmqctl status
または
# /etc/init.d/rabbitmq-server status
3 )ノード間の認証用にCookieを設定します。 scpを使用して、ノードの1つ(rabbitmq01など)から他の2つのノードにファイルをコピーできます。
[ root@rabbitmq01 ~]# cat /var/lib/rabbitmq/.erlang.cookie
FXQTFVXIUWEBZRLXFQOZ
[ root@rabbitmq02 ~]# cat /var/lib/rabbitmq/.erlang.cookie
FXQTFVXIUWEBZRLXFQOZ
[ root@rabbitmq03 ~]# cat /var/lib/rabbitmq/.erlang.cookie
FXQTFVXIUWEBZRLXFQOZ
Cookieを同期した後、rabbitmqを再起動します-server。
# /etc/init.d/rabbitmq-server restart
4 )クラスター内の3つのノードを接続するために、そのうちの2つを別のノードに追加できます。
例:rabbitmq01とrabbitmq03をそれぞれクラスターrabbitmq02に追加します。ここで、rabbitmq01ノードとrabbitmq02ノードはメモリノードです。 rabbitmq02はディスクノードです。
注:rabbitmqctl stop_app ---アプリケーションを閉じるだけで、ノードは閉じられません
[ root@rabbitmq01 ~]# rabbitmqctl stop_app
[ root@rabbitmq01 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq02
[ root@rabbitmq01 ~]# rabbitmqctl start_app
[ root@rabbitmq03 ~]# rabbitmqctl stop_app
[ root@rabbitmq03 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq02
[ root@rabbitmq03 ~]# rabbitmqctl start_app
RabbitMQクラスターを表示します(3つのノードの結果は同じです)
[ root@rabbitmq01 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq01 ...[{nodes,[{disc,[rabbit@rabbitmq02]},{ram,[rabbit@rabbitmq03,rabbit@rabbitmq01]}]},{running_nodes,[rabbit@rabbitmq03,rabbit@rabbitmq02,rabbit@rabbitmq01]},{cluster_name,<<"[email protected]">>},{partitions,[]},{alarms,[{rabbit@rabbitmq03,[]},{rabbit@rabbitmq02,[]},{rabbit@rabbitmq01,[]}]}]
RabbitMQクラスターの名前は、デフォルトでは最初のノードの名前です。たとえば、上記のクラスターの名前はrabbitmq01です。
RabbitMQクラスターkevinmqの名前を変更します
# rabbitmqctl set_cluster_name kevinmq
# rabbitmqctl cluster_status
クラスタを再起動します。
# rabbitmqctl stop
# rabbitmq-server -detached
# rabbitmqctl cluster_status //クラスタの実行ステータスの変化を観察します。5)重要な情報:
クラスタ全体がダウンしている場合、最後にダウンしたノードが最初にオンラインで開始する必要があります。そうでない場合、ノードは最後のディスクノードが回復するまで30秒間待機してから、障害が発生します。
最後のオフラインノードがオンラインになれない場合は、忘却を使用できます_cluster_クラスターをキックアウトするnodeコマンド。
電源障害など、すべてのノードが同時に制御不能になった場合、すべてのノードがすべてのノードに入り、他のノードが自分のノードよりも遅くダウンしている、つまり最初にダウンしていると見なします。この場合、次を使用できます。
force_ノードを起動するためのbootコマンド。
6 )クラスターを解除します。
ノードがこのクラスターに属していない場合、ローカルまたはリモートで時間内にキックアウトする必要があります
# rabbitmqctl stop_app
# rabbitmqctl reset
# rabbitmqctl start_app
このように、RabbitMQクラスターを再度表示すると、ノードは存在しなくなります。
# rabbitmqctl cluster_status
7 )クライアント接続クラスターテスト
Web管理ページから、キューの作成、メッセージの公開、ユーザーの作成、ポリシーの作成などを行います。
http://192.168.1.41:15672/
または、rabbitmqadminコマンドラインでテストします
[ root@rabbitmq02 ~]# wget https://192.168.1.41:15672/cli/rabbitmqadmin
[ root@rabbitmq02 ~]# chmod +x rabbitmqadmin
[ root@rabbitmq02 ~]# mv rabbitmqadmin /usr/sbin/
Declare an exchange
[ root@rabbitmq02 ~]# rabbitmqadmin declare exchange name=my-new-exchange type=fanout
exchange declared
Declare a queue,with optional parameters
[ root@rabbitmq02 ~]# rabbitmqadmin declare queue name=my-new-queue durable=false
queue declared
Publish a message
[ root@rabbitmq02 ~]# rabbitmqadmin publish exchange=my-new-exchange routing_key=test payload="hello, world"
Message published
And get it back
[ root@rabbitmq02 ~]# rabbitmqadmin get queue=test requeue=false+-------------+----------+---------------+--------------+------------------+-------------+| routing_key | exchange | message_count | payload | payload_encoding | redelivered |+-------------+----------+---------------+--------------+------------------+-------------+| test ||0| hello, world | string | False |+-------------+----------+---------------+--------------+------------------+-------------+
テスト後に見つかった問題:
[ root@rabbitmq01 ~]# rabbitmqctl stop_app
[ root@rabbitmq01 ~]# rabbitmqctl stop
stop_appまたはブローカーが停止すると、rabbitmq01ノードの上位キューは使用できなくなります。rabbitmq01アプリまたはブローカーを再起動すると、クラスターは正常に機能していますが、rabbitmq01キューのメッセージはクリアされます(キューはまだ存在します)。
実稼働環境では、これは絶対に受け入れられません。キューの高い可用性が保証されない場合、クラスタリングの重要性はそれほど大きくありません。幸い、rabbitmqはHighly Availableキューをサポートしています。次に、キューのHAについて説明します。
**================= キューHA構成=============== **
デフォルトでは、RabbitMQクラスターのキューは、キューの作成時に宣言されたノードに応じて、クラスター内の1つのノードに存在し、交換とバインディングは、クラスター内のすべてのノードにデフォルトで存在します。
キューをミラーリングして可用性を向上させることができます。HAはrabbitmqクラスターに依存しているため、キューミラーリングはWAN展開には適していません。ミラーリングされた各キューには、マスターと1つ以上のスレーブが含まれます。
何らかの理由で失敗すると、最も古いスレーブが新しいマスターに昇格します。キューに投稿されたメッセージはすべてのスレーブにコピーされ、コンシューマーは接続先のノードに関係なくマスターに接続します。マスターが確認した場合
メッセージを削除する場合、すべてのスレーブがキュー内のメッセージを削除します。キューミラーリングは、キューの高い可用性を提供できますが、参加しているすべてのノードがすべての作業を行うため、負荷を共有できません。
1. キューミラーリングを構成する
ポリシーを介してミラーリングを構成するには、ミラーリングされていないキューを最初に作成してからミラーリングする、またはその逆など、いつでもポリシーを作成できます。
ミラーリングされたキューとミラーリングされていないキューの違いは、ミラーリングされていないキューにはスレーブがなく、ミラーリングされたキューよりも高速に実行されることです。
戦略を設定してから、haモードの3つのモードを設定します。すべて、正確に、ノードです。
各キューには、キューマスターノードと呼ばれるホームノードがあります
1 )ポリシーを設定すると、ha。で始まるキューは、クラスター内の他のすべてのノードにミラーリングされます。ノードがハングアップして再起動した後、キューメッセージを手動で同期する必要があります。
# rabbitmqctl set_policy ha-all-queue "^ha\."'{"ha-mode":"all"}'
2 )ポリシーを設定すると、ha。で始まるキューは、クラスター内の他のすべてのノードにミラーリングされます。ノードがハングアップして再起動すると、キューメッセージが自動的に同期されます(この方法は実稼働環境で使用されます)
# rabbitmqctl set_policy ha-all-queue "^ha\."'{"ha-mode":"all","ha-sync-mode":"automatic"}'
2. 問題:
ミラーキューを構成した後、ノードの1つに障害が発生しても、キューの内容は失われません。クラスター全体が再起動しても、キュー内のメッセージの内容は失われます。キューのメッセージの内容の永続性を実現するにはどうすればよいですか。
クラスターノードはディスクモードで実行され、メッセージの作成時に永続性を宣言しますが、それでも機能しないのはなぜですか?
メッセージの作成時にメッセージを永続化するかどうかを指定する必要があるため、メッセージの永続化が有効になっている場合、作成されたキューが作成された永続的なキューでもある限り、クラスターの再起動後にメッセージが失われることはありません。
クライアントがrabbitMQクラスターサービスに接続する方法:
1 )クライアントはクラスター内の任意のノードに接続できます。ノードに障害が発生した場合、クライアントは他の使用可能なノードに再接続します;(非推奨、クライアントには不透明)
2 )動的DNSを介して、より短いttl
3 )HA + 4レイヤーロードバランサー(haproxy + keepalivedなど)を介して
========== Haproxy + keepalivedデプロイメント===============
同社の主要な基本サービスとして、メッセージキューはクライアントに安定した透過的なrabbitmqサービスを提供します。現在、Haproxy + keepalivedを使用して、可用性の高いrabbitmq統合ポータルと基本的な負荷分散サービスを構築しています。
インストールと構成を簡素化するために、haproxyとkeepalivedがyumによってインストールされるようになりました。keepalived+ nginxに基づく堅牢で可用性の高い7層の負荷分散ソリューションの展開を参照できます。
2つの2つのサーバーにhaproxyをデプロイします+Keepalived環境では、展開プロセスは同じです。
haroxy01.kevin.cn 192.168.1.43
haroxy02.kevin.cn 192.168.1.441)インストール
[ root@haproxy01 ~]# yum install haproxy keepalived -y
[ root@haproxy01 ~]# /etc/init.d/keepalived start
2 )自動的に開始するように主要なサービスを設定する
[ root@haproxy01 ~]# chkconfig --list|grep haproxy
[ root@haproxy01 ~]# chkconfig haproxy on
[ root@haproxy01 ~]# chkconfig --list|grep haproxy
3) haproxyログをに記録するように構成します/var/log/haproxy.log
[ root@haproxy01 ~]# more /etc/rsyslog.d/haproxy.conf
$ModLoad imudp
$UDPServerRun 514
local0.*/var/log/haproxy.log
[ root@haproxy01 ~]# /etc/init.d/rsyslog restart
4 )haproxyの構成、2台のマシンの構成はまったく同じです
[ root@haproxy01 ~]# more /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# https://haproxy.1wt.eu/download/1.4/doc/configuration.txt
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in/var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.*/var/log/haproxy.log
#
log 127.0.0.1 local2 notice
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode tcp
option tcplog
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
### haproxy statistics monitor by laijingli 20160222
listen statics 0.0.0.0:8888
mode http
log 127.0.0.1 local0 debug
transparent
stats refresh 60s
stats uri / haproxy-stats
stats realm Haproxy \ statistic
stats auth laijingli:xxxxx
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kevin_rabbitMQ_cluster_frontend
mode tcp
option tcpka
log 127.0.0.1 local0 debug
bind 0.0.0.0:5672
use_backend kevin_rabbitMQ_cluster_backend
frontend kevin_rabbitMQ_cluster_management_frontend
mode tcp
option tcpka
log 127.0.0.1 local0 debug
bind 0.0.0.0:15672
use_backend kevin_rabbitMQ_cluster_management_backend
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kevin_rabbitMQ_cluster_backend
balance roundrobin
server rabbitmq01.kevin.cn 192.168.1.40:5672 check inter 3s rise 1 fall 2
server rabbitmq02.kevin.cn 192.168.1.41:5672 check inter 3s rise 1 fall 2
server rabbitmq03.kevin.cn 192.168.1.42:5672 check inter 3s rise 1 fall 2
backend kevin_rabbitMQ_cluster_management_backend
balance roundrobin
server rabbitmq01.kevin.cn 192.168.1.40:15672 check inter 3s rise 1 fall 2
server rabbitmq02.kevin.cn 192.168.1.41:15672 check inter 3s rise 1 fall 2
server rabbitmq03.kevin.cn 192.168.1.42:15672チェックインター3s上昇1下降25)Keepalived構成、2つのサーバーのkeepalived構成の違いに特に注意してください。
======================= haroxy01を最初に見てください.kevin.cnマシンでの構成===========================[root@haproxy01 ~]# more /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
102533678@ qq.com
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id haproxy43 ## xxhaproxy101 on master , xxhaproxy102 on backup
}
### simple check with killall -0 which is less expensive than pidof to verify that nginx is running
vrrp_script chk_nginx {
script "killall -0 nginx"
interval 1
weight 2
fall 2
rise 1}
vrrp_instance KEVIN_GATEWAY {
state MASTER ## MASTER on master , BACKUP on backup
interfaceem1
virtual_router_id 101 ## KEVIN_GATEWAY virtual_router_id
priority 200 ## 200 on master ,199 on backup
advert_int 1
### 同じLAN内の複数のkeepalivedグループ間の相互影響を回避するためにユニキャスト通信を採用する
unicast_src_ip 192.168.1.43 ##ネイティブIP
unicast_peer {192.168.1.44 ##ピアIP
}
authentication {
auth_type PASS
auth_pass 123456}
virtual_ipaddress {192.168.1.45 ## VIP
}
### ネットワークカードが1つしかない場合は、ネットワークインターフェイスを監視する必要はありません。
# track_interface {
# em1
#}
track_script {
chk_nginx
}
### ステータススイッチは電子メール通知を送信することであり、マシンはログを記録し、SMS通知は後でトリガーされます
notify_master /usr/local/bin/keepalived_notify.sh notify_master
notify_backup /usr/local/bin/keepalived_notify.sh notify_backup
notify_fault /usr/local/bin/keepalived_notify.sh notify_fault
notify /usr/local/bin/keepalived_notify.sh notify
smtp_alert
}
### simple check with killall -0 which is less expensive than pidof to verify that haproxy is running
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight 2
fall 2
rise 1}
vrrp_instance kevin_rabbitMQ_GATEWAY {
state BACKUP ## MASTER on master , BACKUP on backup
interfaceem1
virtual_router_id 111 ## kevin_rabbitMQ_GATEWAY virtual_router_id
priority 199 ## 200 on master ,199 on backup
advert_int 1
### 同じLAN内の複数のkeepalivedグループ間の相互影響を回避するためにユニキャスト通信を採用する
unicast_src_ip 192.168.1.43 ##ネイティブIP
unicast_peer {192.168.1.44 ##ピアIP
}
authentication {
auth_type PASS
auth_pass 123456}
virtual_ipaddress {192.168.1.46 ## VIP
}
### ネットワークカードが1つしかない場合は、ネットワークインターフェイスを監視する必要はありません。
# track_interface {
# em1
#}
track_script {
chk_haproxy
}
### ステータススイッチは電子メール通知を送信することであり、マシンはログを記録し、SMS通知は後でトリガーされます
notify_master /usr/local/bin/keepalived_notify_for_haproxy.sh notify_master
notify_backup /usr/local/bin/keepalived_notify_for_haproxy.sh notify_backup
notify_fault /usr/local/bin/keepalived_notify_for_haproxy.sh notify_fault
notify /usr/local/bin/keepalived_notify_for_haproxy.sh notify
smtp_alert
}============================= haroxy02をもう一度見てください.kevin.cnマシンでの構成==========================[root@haproxy02 ~]# more /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
102533678@ qq.com
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id haproxy44 ## xxhaproxy101 on master , xxhaproxy102 on backup
}
### simple check with killall -0 which is less expensive than pidof to verify that nginx is running
vrrp_script chk_nginx {
script "killall -0 nginx"
interval 1
weight 2
fall 2
rise 1}
vrrp_instance KEVIN_GATEWAY {
state BACKUP ## MASTER on master , BACKUP on backup
interfaceem1
virtual_router_id 101 ## KEVIN_GATEWAY virtual_router_id
priority 199 ## 200 on master ,199 on backup
advert_int 1
### 同じLAN内の複数のkeepalivedグループ間の相互影響を回避するためにユニキャスト通信を採用する
unicast_src_ip 192.168.1.44 ##ネイティブIP
unicast_peer {192.168.1.43 ##ピアIP
}
authentication {
auth_type PASS
auth_pass YN_API_HA_PASS
}
virtual_ipaddress {192.168.1.45 ## VIP
}
### ネットワークカードが1つしかない場合は、ネットワークインターフェイスを監視する必要はありません。
# track_interface {
# em1
#}
track_script {
chk_nginx
}
### ステータススイッチは電子メール通知を送信することであり、マシンはログを記録し、SMS通知は後でトリガーされます
notify_master /usr/local/bin/keepalived_notify.sh notify_master
notify_backup /usr/local/bin/keepalived_notify.sh notify_backup
notify_fault /usr/local/bin/keepalived_notify.sh notify_fault
notify /usr/local/bin/keepalived_notify.sh notify
smtp_alert
}
### simple check with killall -0 which is less expensive than pidof to verify that haproxy is running
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight 2
fall 2
rise 1}
vrrp_instance kevin_rabbitMQ_GATEWAY {
state MASTER ## MASTER on master , BACKUP on backup
interfaceem1
virtual_router_id 111 ## kevin_rabbitMQ_GATEWAY virtual_router_id
priority 200 ## 200 on master ,199 on backup
advert_int 1
### 同じLAN内の複数のkeepalivedグループ間の相互影響を回避するためにユニキャスト通信を採用する
unicast_src_ip 192.168.1.44 ##ネイティブIP
unicast_peer {192.168.1.43 ##ピアIP
}
authentication {
auth_type PASS
auth_pass YN_MQ_HA_PASS
}
virtual_ipaddress {192.168.1.46 ## VIP
}
### ネットワークカードが1つしかない場合は、ネットワークインターフェイスを監視する必要はありません。
# track_interface {
# em1
#}
track_script {
chk_haproxy
}
### ステータススイッチは電子メール通知を送信することであり、マシンはログを記録し、SMS通知は後でトリガーされます
notify_master /usr/local/bin/keepalived_notify_for_haproxy.sh notify_master
notify_backup /usr/local/bin/keepalived_notify_for_haproxy.sh notify_backup
notify_fault /usr/local/bin/keepalived_notify_for_haproxy.sh notify_fault
notify /usr/local/bin/keepalived_notify_for_haproxy.sh notify
smtp_alert
}
構成で使用される通知スクリプトは、2つのhaproxyサーバーでまったく同じです。
[ root@haproxy01 ~]# more /usr/local/bin/keepalived_notify.sh
#! /bin/bash
### keepalived notify script for record ha state transtion to log files
### トラブルシューティングを容易にするために、状態遷移プロセスをログに記録します
logfile=/var/log/keepalived.notify.log
echo --------------->> $logfile
echo `date`[`hostname`] keepalived HA role state transition: $1 $2 $3 $4 $5 $6>> $logfile
### ステータス遷移をnginxファイルに記録して、Webを介してhaステータスを表示できるようにします(パブリックネットワークに開かないように注意してください)。
echo `date``hostname` $1 $2 $3 $4 $5 $6 "
" > /usr/share/nginx/html/index_for_nginx.html
### nginxapiとrabbitmqのhaログを同じファイルに記録します
cat /usr/share/nginx/html/index_for*>/usr/share/nginx/html/index.html
6 )Haproxy監視ページ。
アクセスアドレスhttp://192.168.1.43:88887)keepalived中高可用性サービスが実行されているサーバーを確認します
https://192.168.1.438)VIPを介してrabbitMQサービスにアクセスする
http://192.168.1.46:56729)その他の問題
Rabbitmqサービスクライアントの使用仕様
1 )vhostを使用して、さまざまなアプリケーション、さまざまなユーザー、さまざまなビジネスグループを分離します
2 )メッセージの永続性、交換の永続性、キュー、メッセージなどは、クライアント側で指定する必要があります
Recommended Posts