Centos7.4はスタンドアロンSparkをインストールします

序文###
個人的な学習ニーズがあるため、 Sparkのインストール方法を調べましょうが、個人的な財源のため、まだクラスターに参加していません。まず、スタンドアロンバージョンの Sparkを試してみましょう。後で拡張がある場合は、クラスターインストールチュートリアルを同期的に更新します。
以下のすべての操作は、
rootユーザーに基づいています。
0. Scala ###をインストールします
0.1 インストール前####
Sparkは Scalaに依存しているため、 Sparkをインストールする前に Scalaをインストールする必要があります。それでは、まず Scalaをインストールしましょう。まず、[Scala公式ウェブサイト](https://www.scala-lang.org/download/2.12.2.html)にアクセスして、 Scalaの圧縮パッケージをダウンロードします。
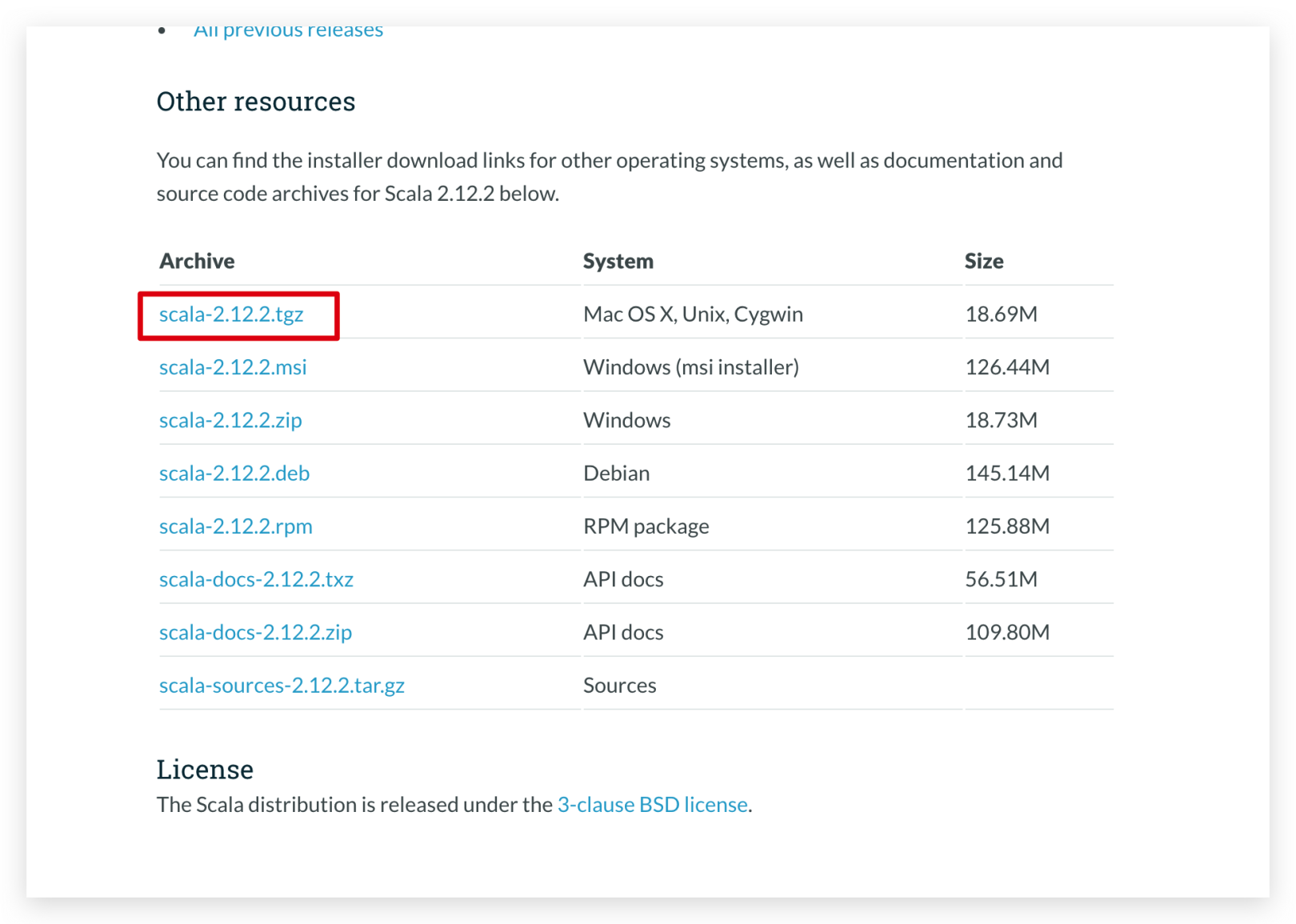
次に、圧縮されたパッケージをCentosサーバーにアップロードします。アップロード方法については、ここでは詳しく説明しません。
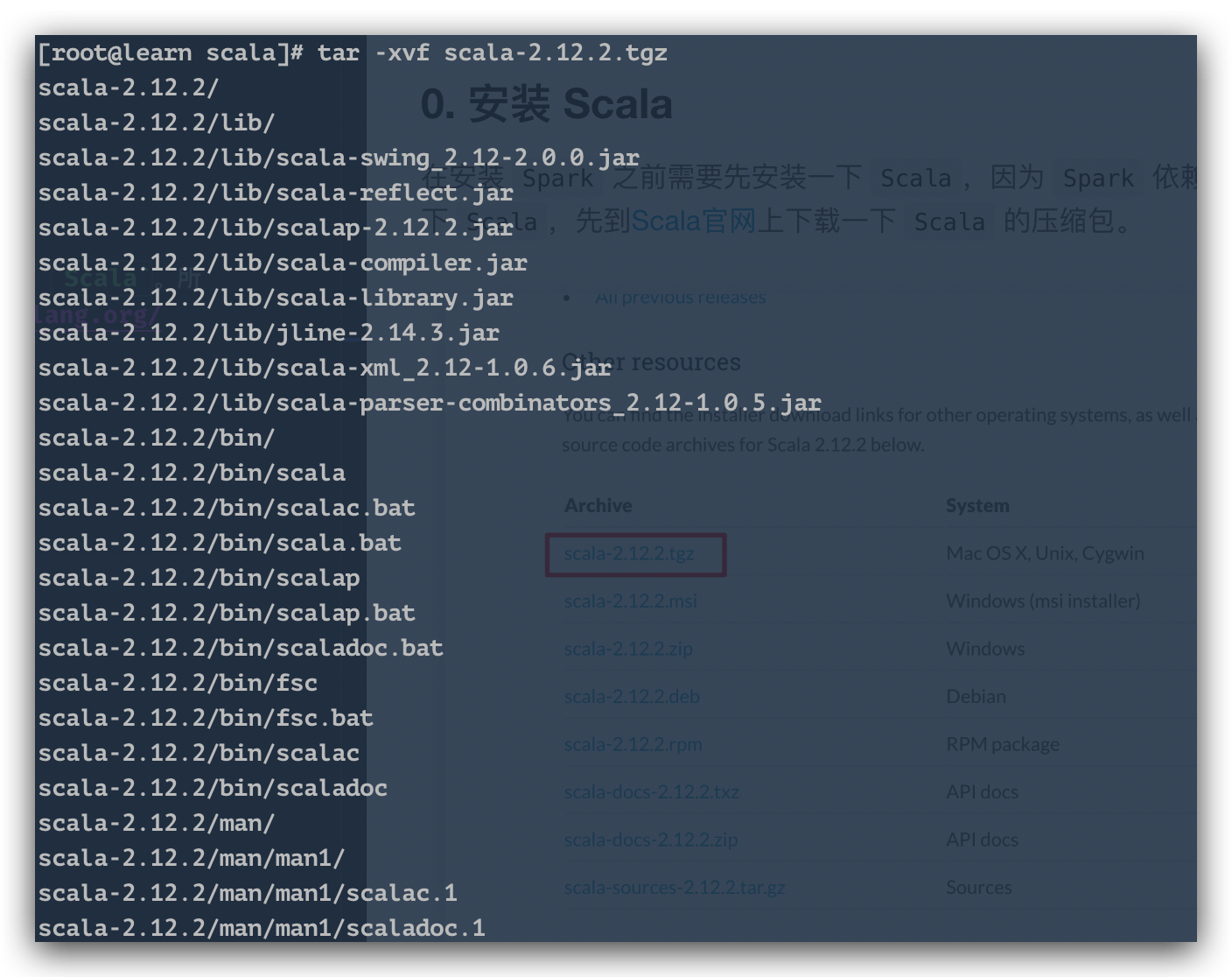
圧縮されたパッケージを / opt / scalaディレクトリに置き、解凍します。
解凍コマンド
tar -xvf scala-2.12.2.tgz
0.2 環境変数を構成する####
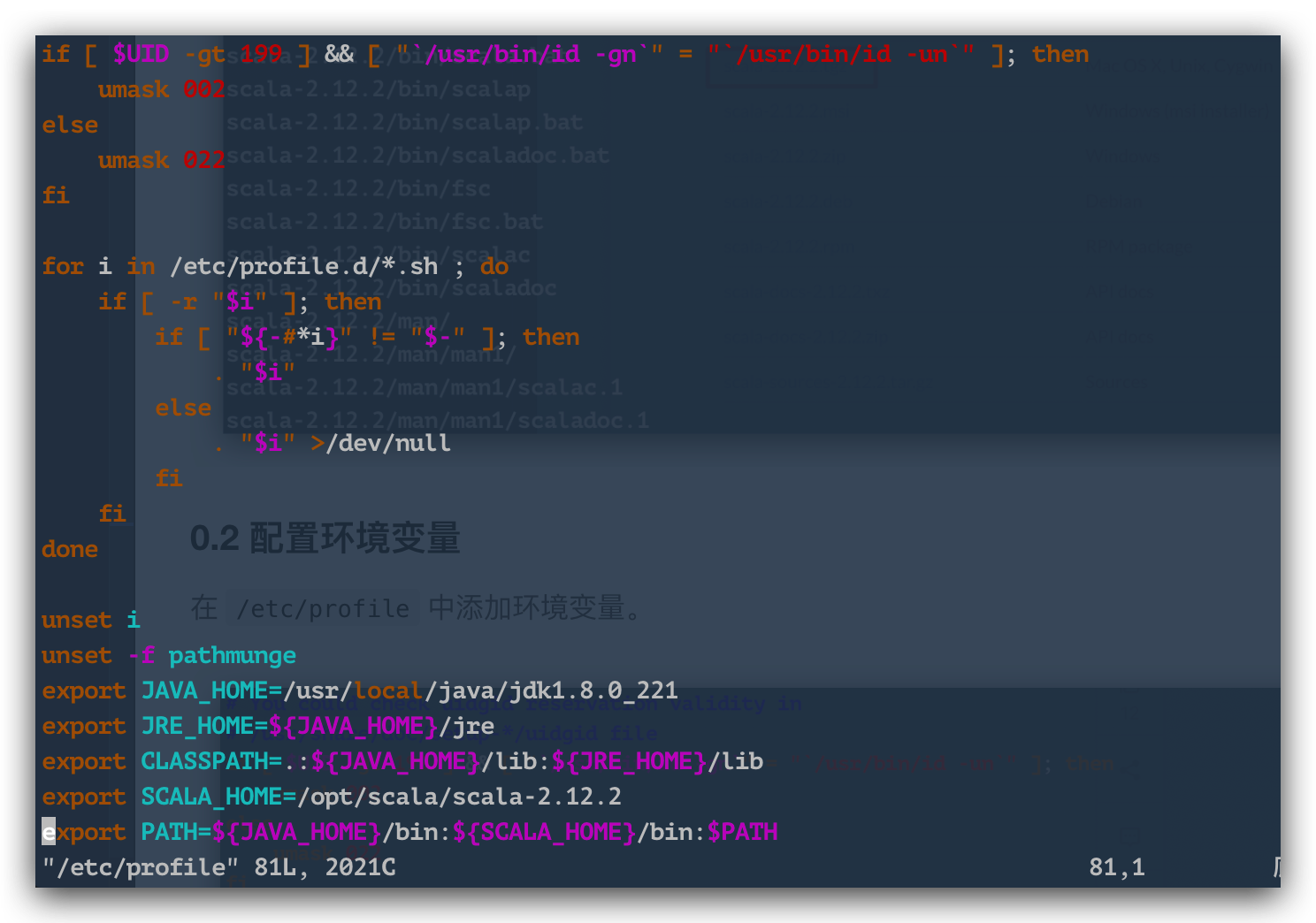
/ etc / profileに環境変数を追加し、 export SCALA_HOME = / opt / scala / scala-2.12.2を追加し、 pathに$ {SCALA_HOME} / bin:を追加します。
以下は私の環境変数です。
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export SCALA_HOME=/opt/scala/scala-2.12.2export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH
次に、 scalaを確認できます。

この時点で、 scalaのインストールが完了し、次のステップは Sparkのインストールです~~~
1. Spark ###をインストールします
1.1 ダウンロードして解凍####
Scalaと同じように、まず買い物に行ってパッケージをダウンロードしてから、サーバーにアップロードしましょう。
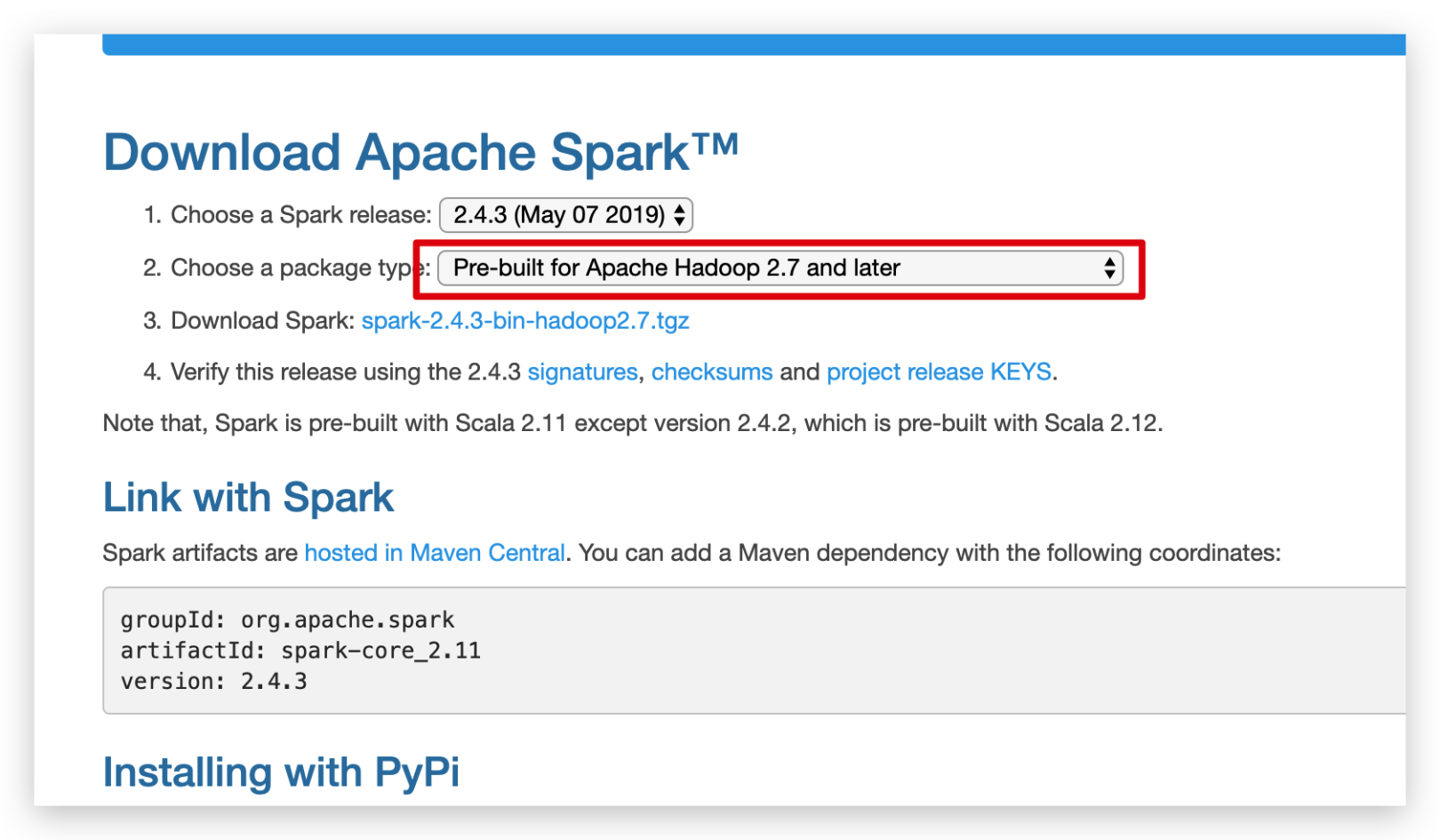
同様に、圧縮パッケージを / opt / sparkディレクトリに配置し、解凍します。
解凍コマンド
tar -xvf spark-2.4.3-bin-hadoop2.7.tgz
1.2 環境変数を構成する####
小さな違いと同様に、 / etc / profileに環境変数を追加し、 export SPARK_HOME = / opt / spark / spark-2.4.3-bin-hadoop2.7を追加し、 pathに$ {SPARK_HOME} / binを追加します。 :。
以下は私の環境変数です。
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export SCALA_HOME=/opt/scala/scala-2.12.2export SPARK_HOME=/opt/spark/spark-2.4.3-bin-hadoop2.7export PATH=${JAVA_HOME}/bin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
1.3 Spark ####を構成します
まず、解凍されたファイルの confディレクトリ(/ opt / spark / spark-2.4.3-bin-hadoop2.7 / conf /)に入ると、テンプレートファイルがあることがわかります。copy一食分。
cp spark-env.sh.template spark-env.sh
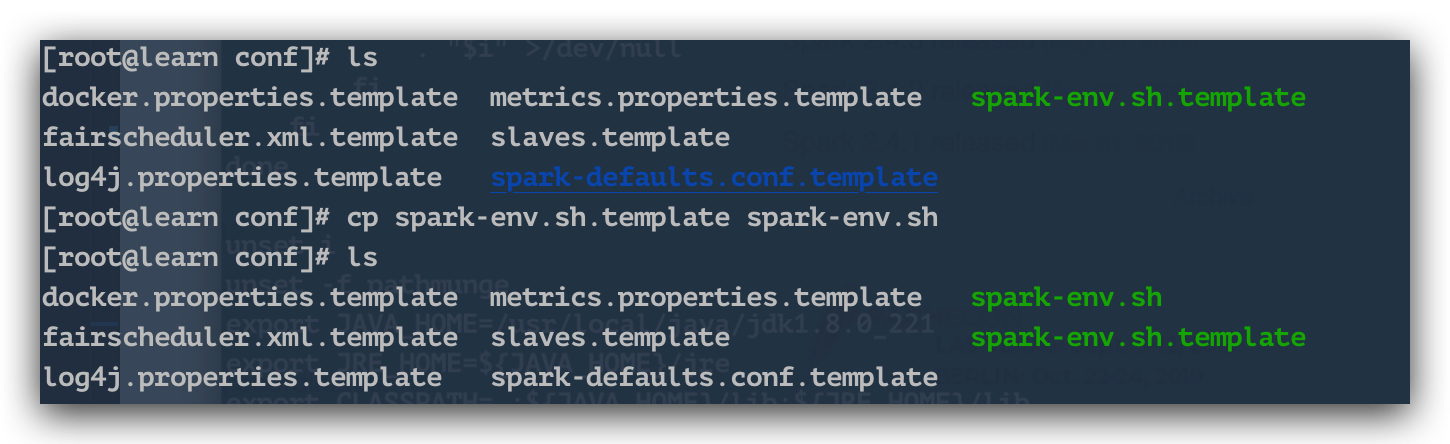
コピーしたファイルを編集し、次のコンテンツを追加します。
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export SCALA_HOME=/opt/scala/scala-2.12.2export SPARK_HOME=/opt/spark/spark-2.4.3-bin-hadoop2.7export SPARK_MASTER_IP=learn
export SPARK_EXECUTOR_MEMORY=1G
同様に、 slavesのコピーをコピーします
cp slaves.template slaves
slavesを編集します。内容は localhostです。
localhost
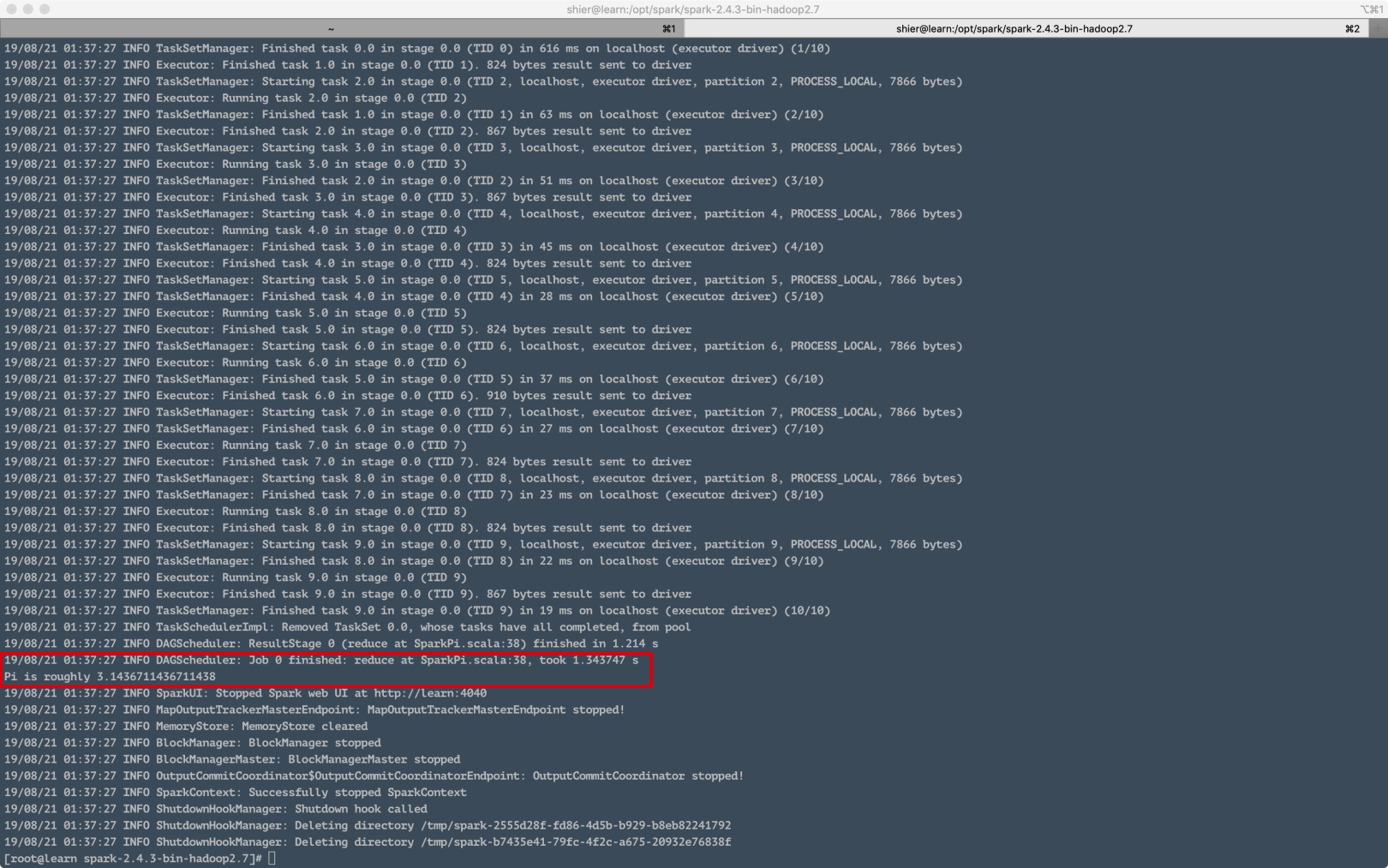
次に、次のディレクトリで / opt / spark / spark-2.4.3-bin-hadoop2.7を実行してテストできます。
. /bin/run-example SparkPi 10
ここで、実行が成功したことがわかります。
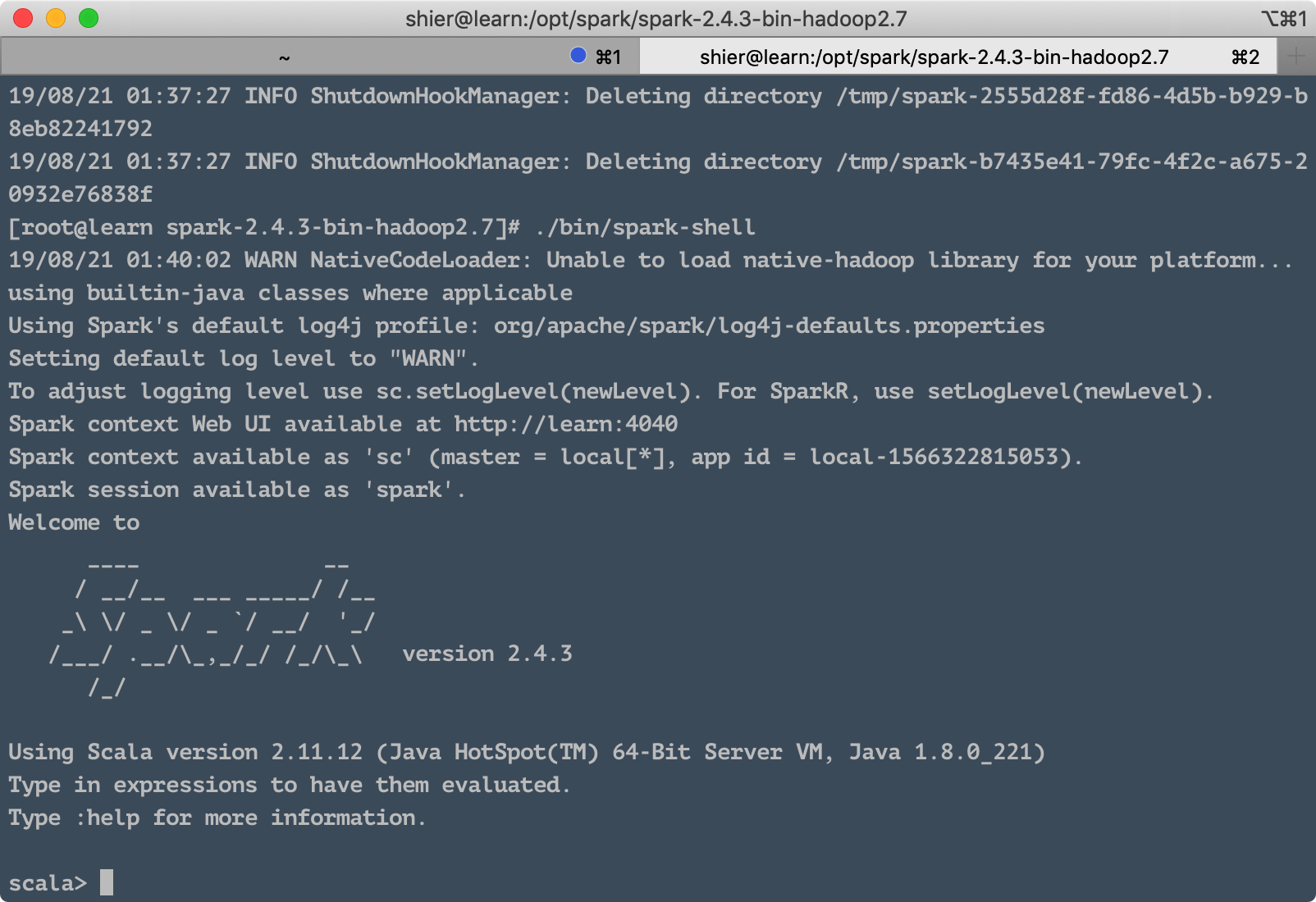
1.4 Spark Shell ####を起動します
上記と同じように、 / opt / spark / spark-2.4.3-bin-hadoop2.7ディレクトリにもあります。実行します。
. /bin/spark-shell
次の結果を確認できます。
これまでのところ、スタンドアロンバージョンの Sparkがインストールされています~~~
Recommended Posts