CentOS6.5はCDH5.13をインストールします
注意:高解像度のコード化されていない写真のセットを表示するには、携帯電話を使用して写真を開き、クリックして拡大してください。
1. 文書作成の目的
ClouderaはCDH5.13バージョンを少し前にリリースしました。5.13の新機能については、前の記事[CDH5.13およびCM5.13の新機能](https://cloud.tencent.com/developer/article/1078130?from=10680)を参照してください。この記事では、主にCentOS6.5にCDH5.13をインストールする方法について説明します。 、クラスターインストールの準備については、前の記事[CDHインストールの準備](https://cloud.tencent.com/developer/article/1078212?from=10680)を参照してください。インストール前によくお読みください [CDHインストールの準備](https://cloud.tencent.com/developer/article/1078212?from=10680)**、およびyum source、ntp構成など、関連する基本的な環境準備を含む、ドキュメントに従って準備されます。 ****
- コンテンツの概要
-
前提条件の準備
-
ClouderaManagerのインストール
-
CDHのインストール
-
Kuduのインストール
-
コンポーネントの検証
- テスト環境
-
CentOS6.5
-
ルートユーザー操作を使用する
- 前提条件
-
CMとCDHのバージョンは5.13です
-
CMおよびCDHインストールパッケージがダウンロードされました
2. ClouderaManagerサーバーをインストールします
- 次のコマンドを使用して、Cloudera ManagerServerサービスをCMノードにインストールします
root@ip-172-31-6-148~# yum -y install cloudera-manager-server

- CMデータベースを初期化します
[ root@ip-172-31-6-148~]#/usr/share/cmf/schema/scm_prepare_database.sh mysql cm cm password
JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera
Verifying that we can write to /etc/cloudera-scm-server
Creating SCM configuration file in/etc/cloudera-scm-server
Executing:/usr/java/jdk1.7.0_67-cloudera/bin/java-cp/usr/share/java/mysql-connector-java.jar:/usr/share/java/oracle-connector-java.jar:/usr/share/cmf/schema/../lib/*com.cloudera.enterprise.dbutil.DbCommandExecutor/etc/cloudera-scm-server/db.properties com.cloudera.cmf.db.
log4j:ERRORCould not find value for keylog4j.appender.A
log4j:ERRORCould not instantiate appender named "A".
[2017- 10- 1517:49:38,476] INFO 0[main] -com.cloudera.enterprise.dbutil.DbCommandExecutor.testDbConnection(DbCommandExecutor.java) - Successfullyconnected to database.
All done, your SCM database is configured correctly!
[ root@ip-172-31-6-148~]#

- ClouderaManagerサーバーを起動します
root@ip-172-31-6-148~# service cloudera-scm-server start
Starting cloudera-scm-server: [ OK ]
root@ip-172-31-6-148~#

- ポートがリッスンしているかどうかを確認します
root@ip-172-31-6-148~# netstat -apn |grep 7180
tcp 0 0 0.0.0.0:7180 0.0.0.0:* LISTEN 20963/java
root@ip-172-31-6-148~#

- http:// 172.31.2.159:7180 / cmf / loginからCMにアクセス

3. CDHのインストール
3.1 CDHクラスターインストールウィザード
-
Cloudera Managerにログインして、Webインストールウィザードのインターフェイスに入ります
-
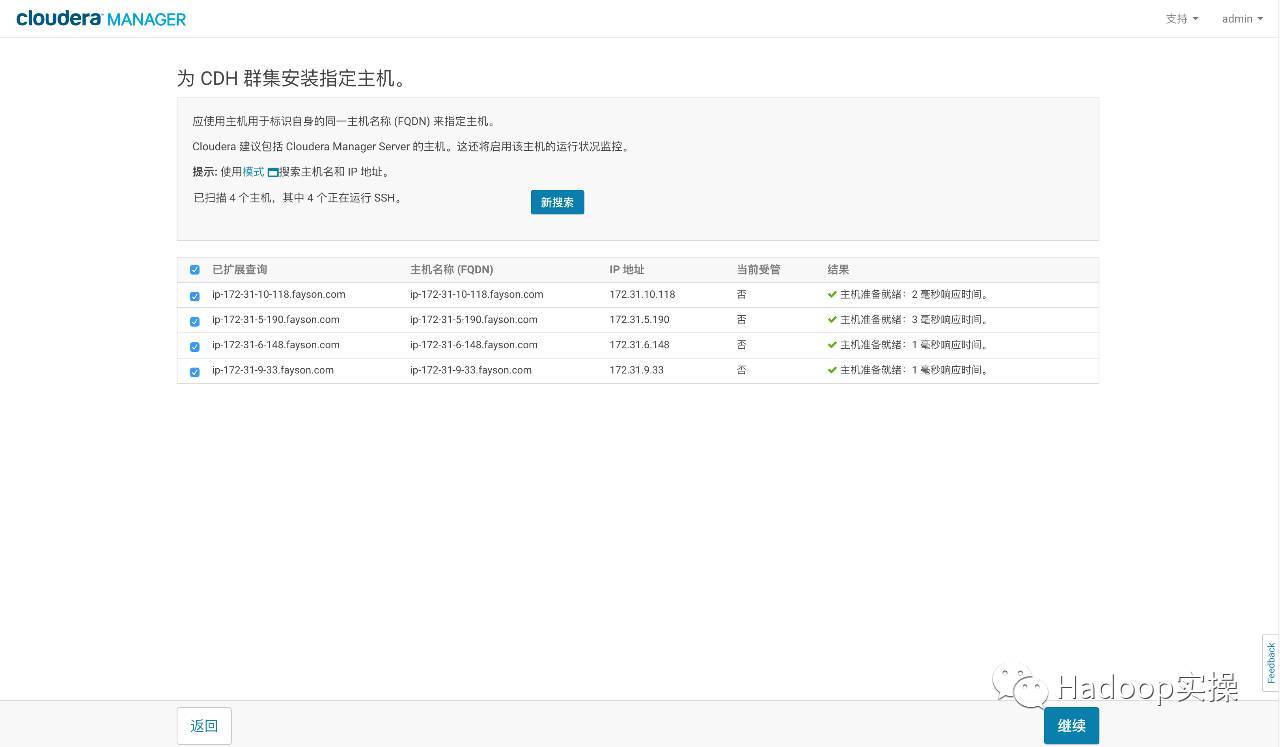
クラスターインストールホストを指定します
- CDHの区画アドレスを設定します

- CMリポジトリアドレスを設定する

- クラスターインストールJDKオプション

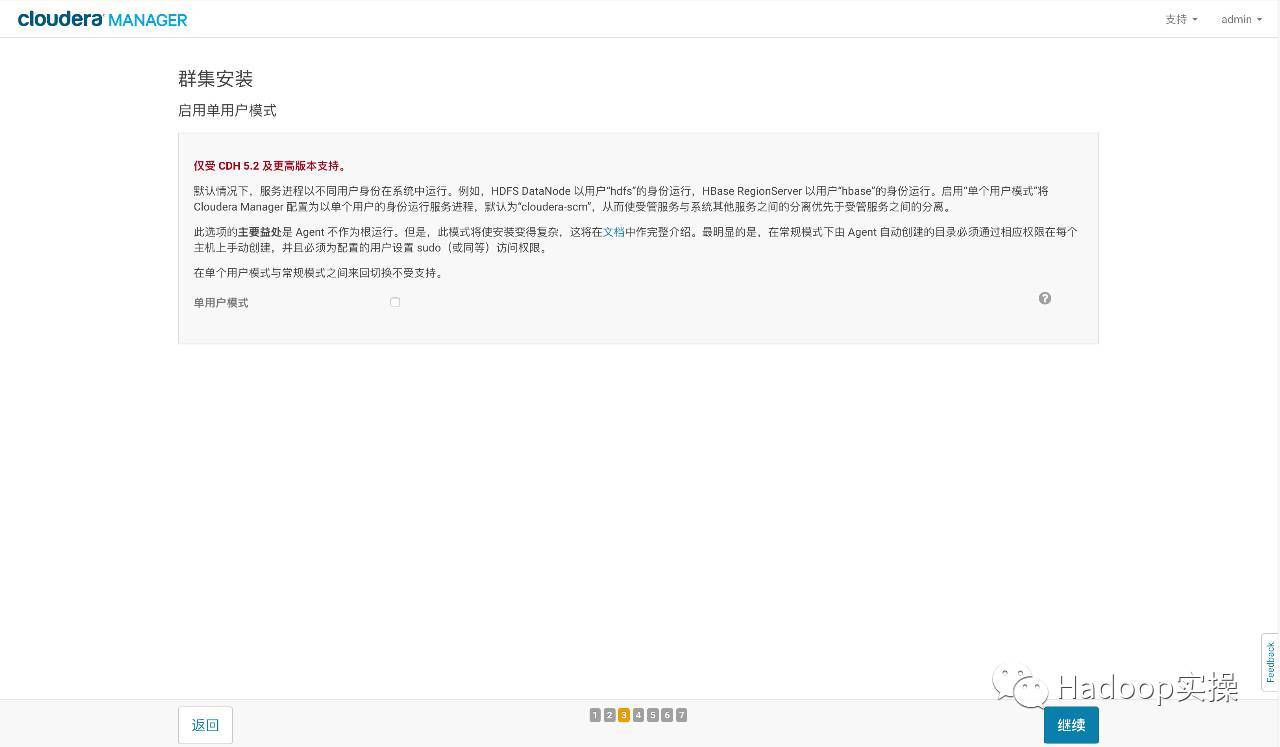
- クラスターインストールモード
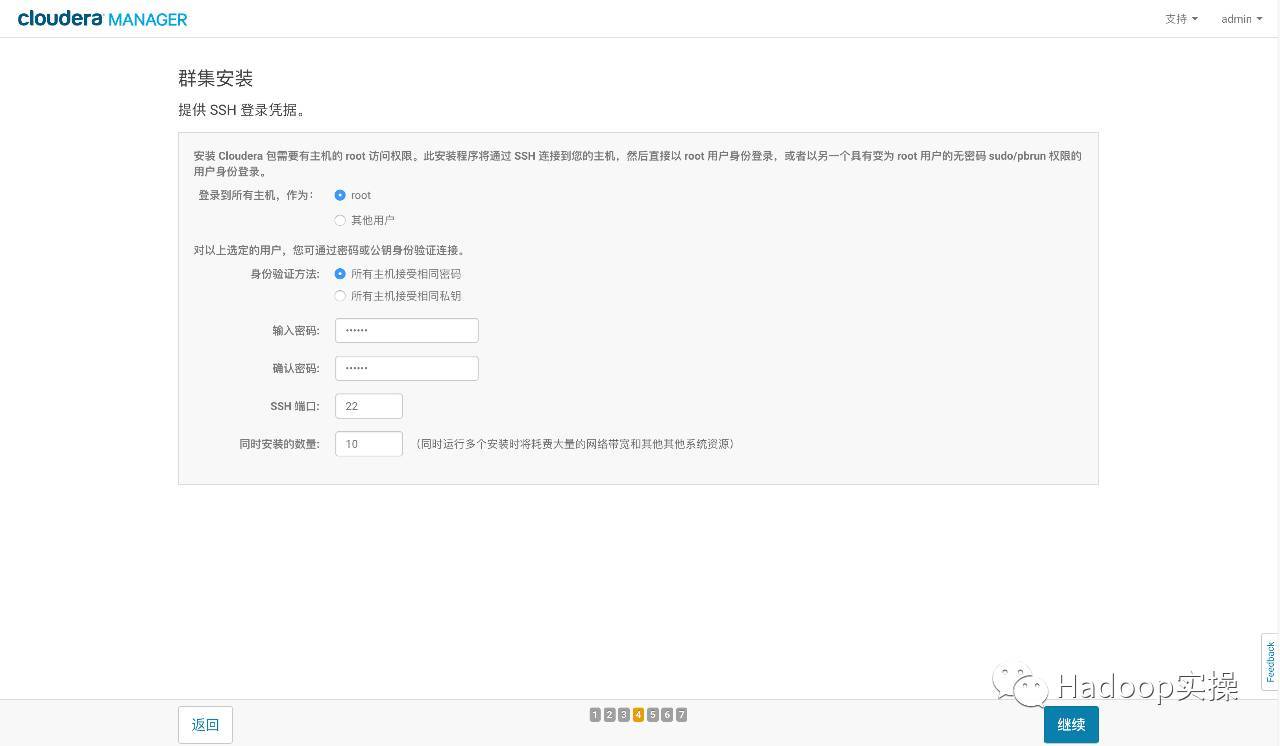
- クラスタSSHログイン情報を入力します
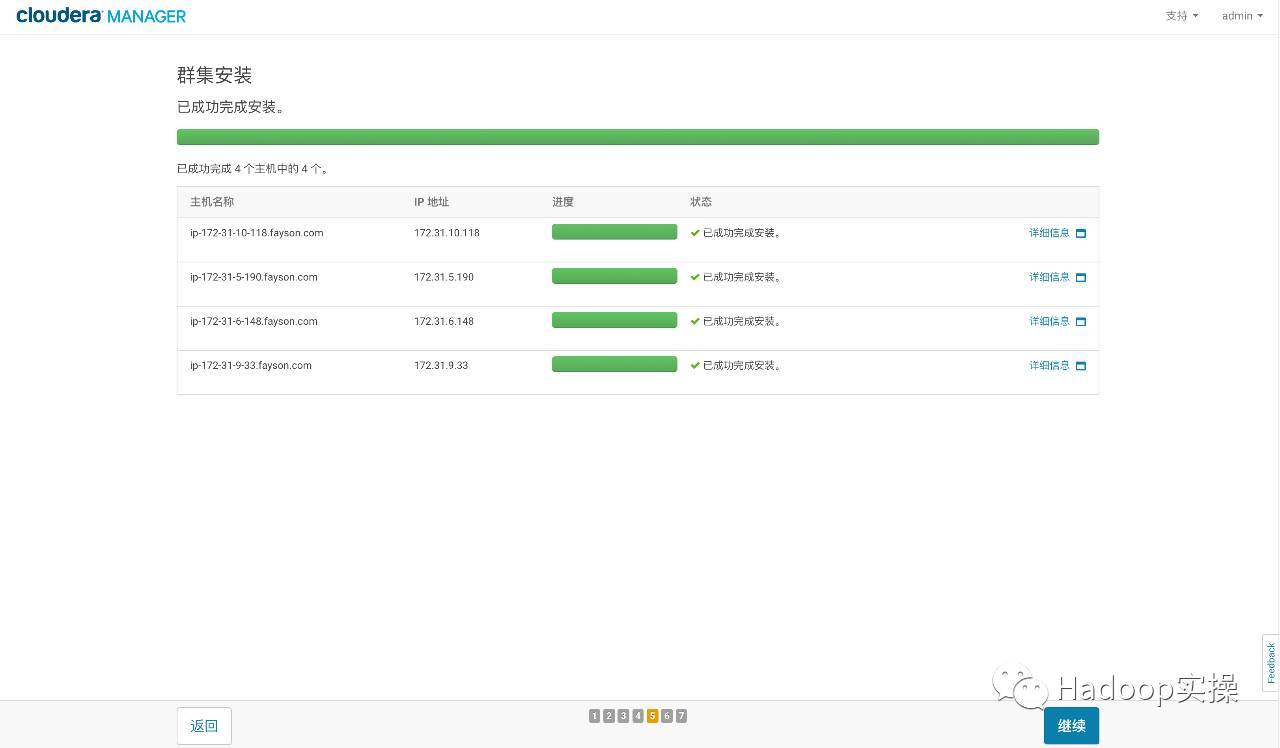
- JDKおよびClouderaManagerAagentサービスのクラスターインストール
- クラスター内のすべてのホストにParcelをインストールしてアクティブ化します
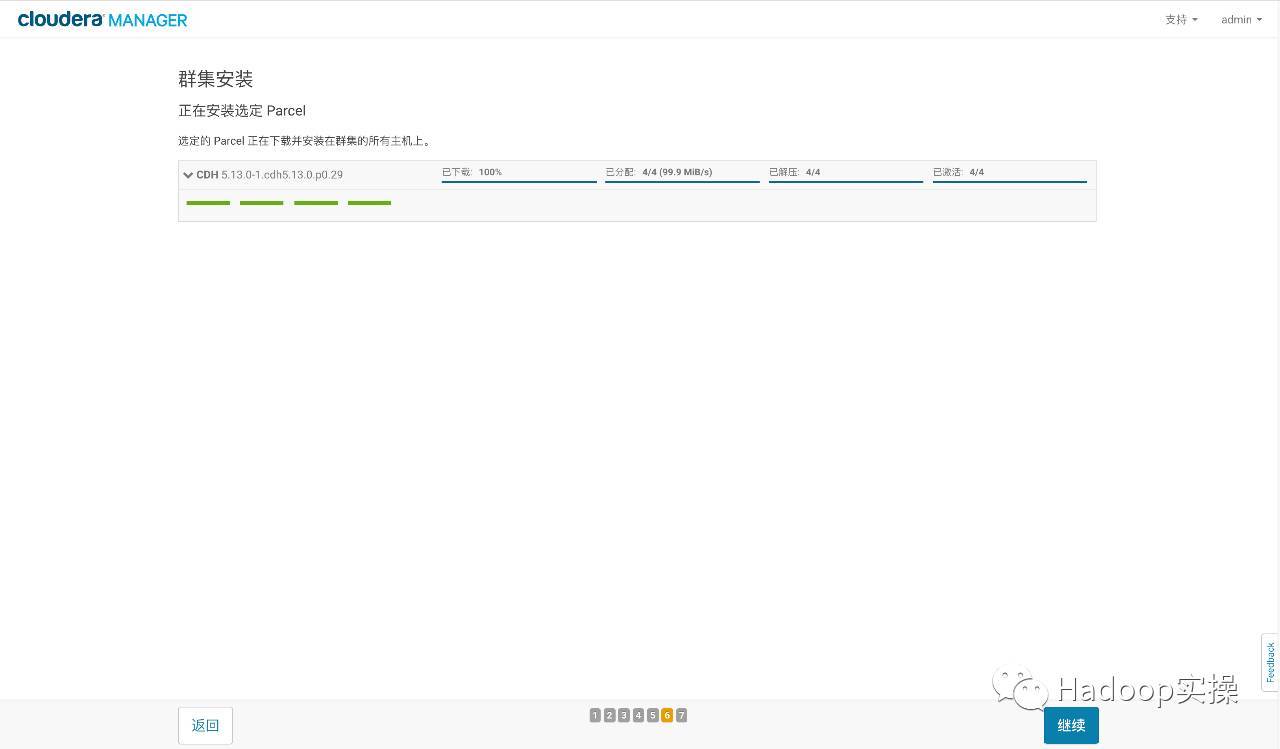
- ホストの正しさを確認してください

3.2 CDHクラスターセットアップウィザード
- クラスターインストールのサービスポートフォリオを設定する

- カスタムの役割の割り当て
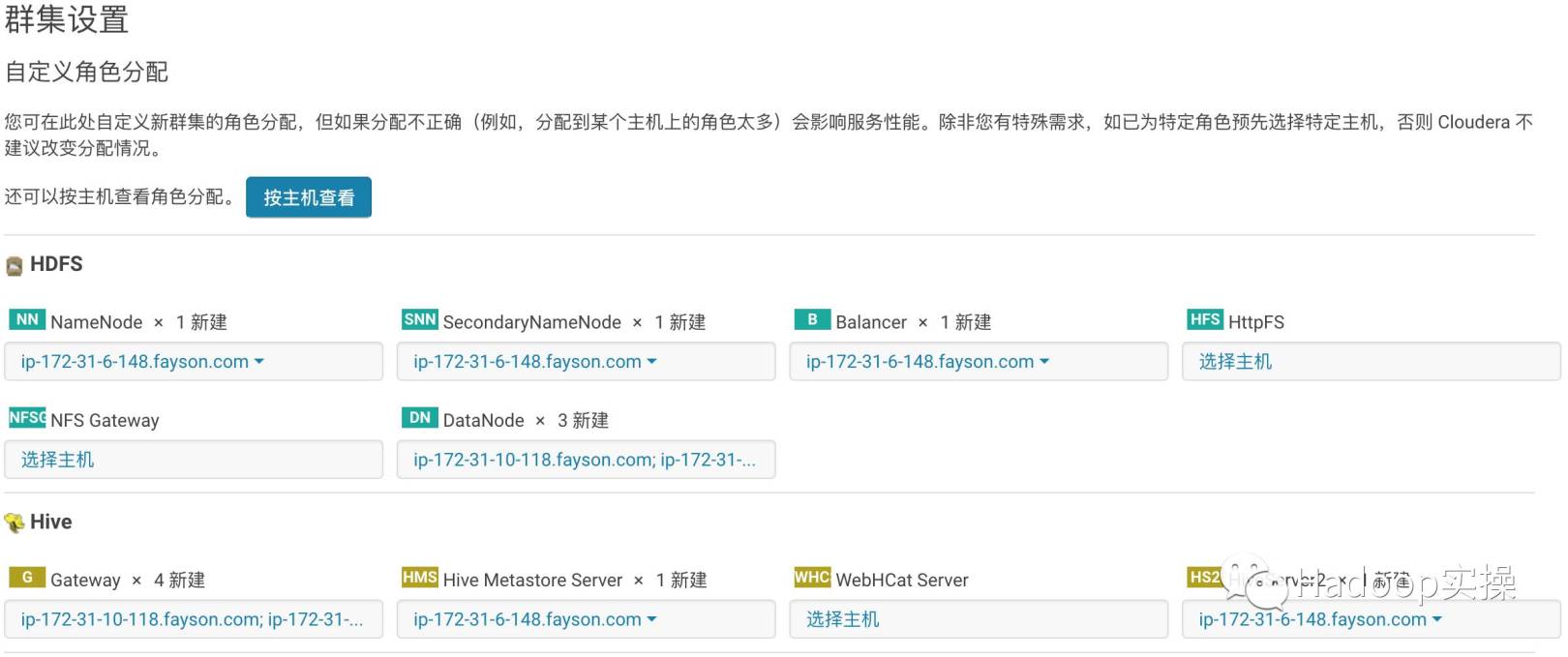
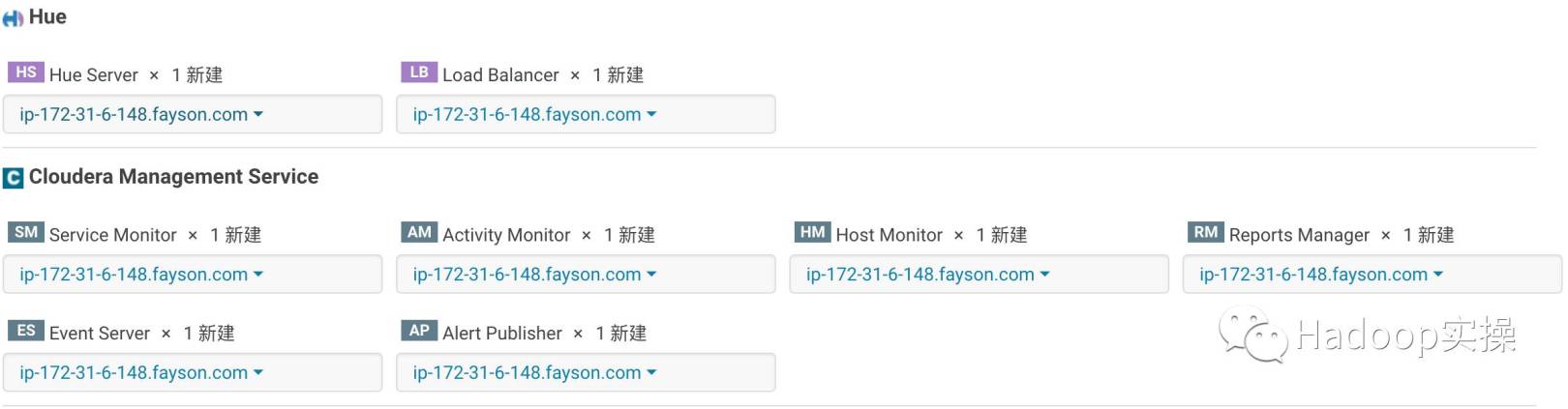
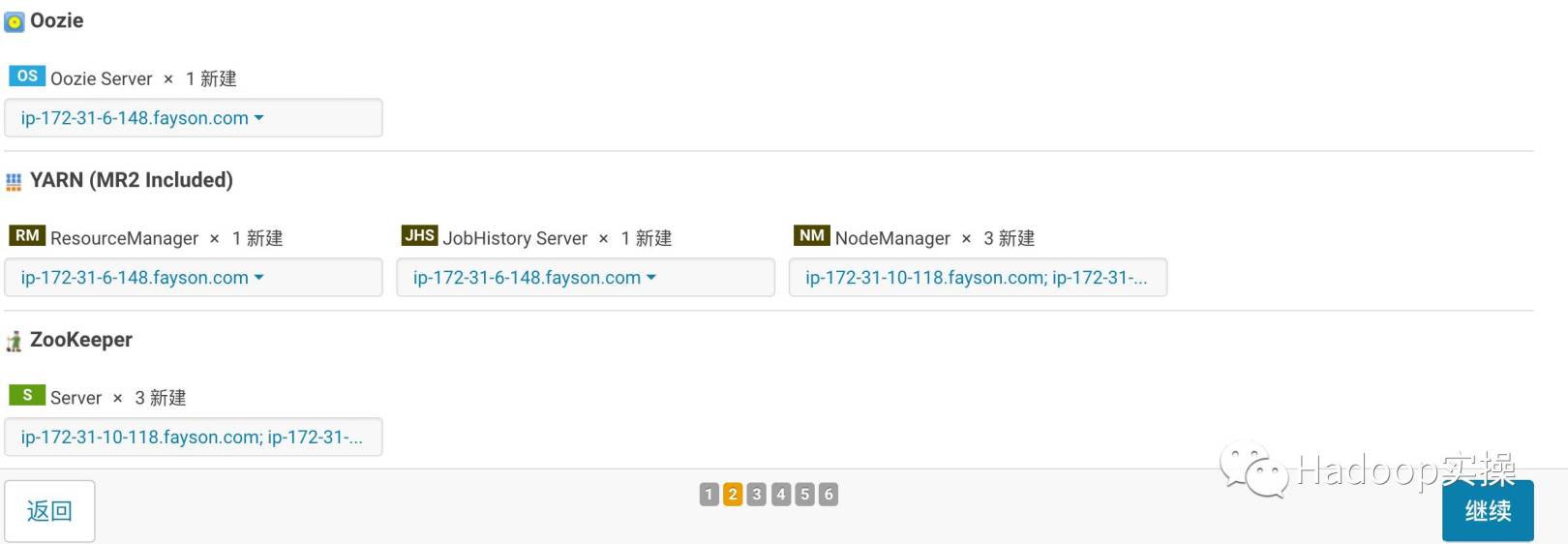
- データベース設定
- 構成レビューの変更
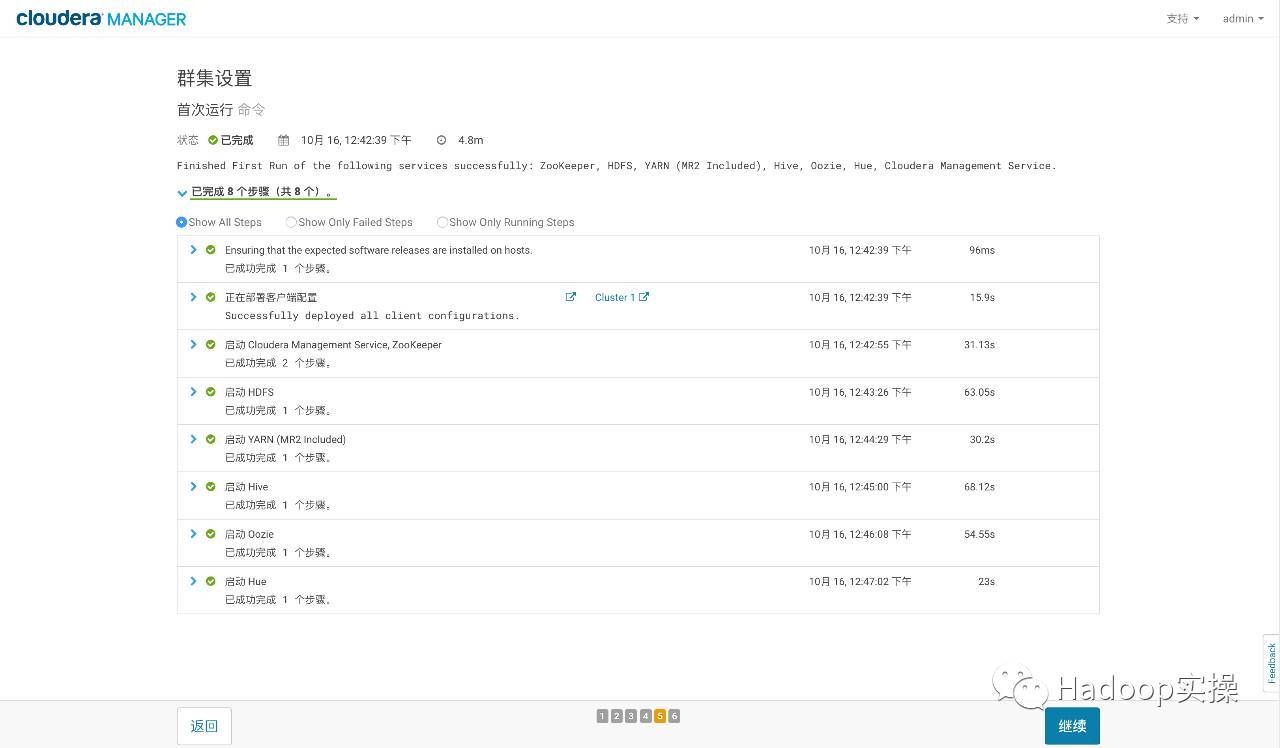
- クラスターの初回実行
- クラスターが正常にインストールされました
- CMおよびCDHバージョンを表示するには、CMホームページにアクセスしてください
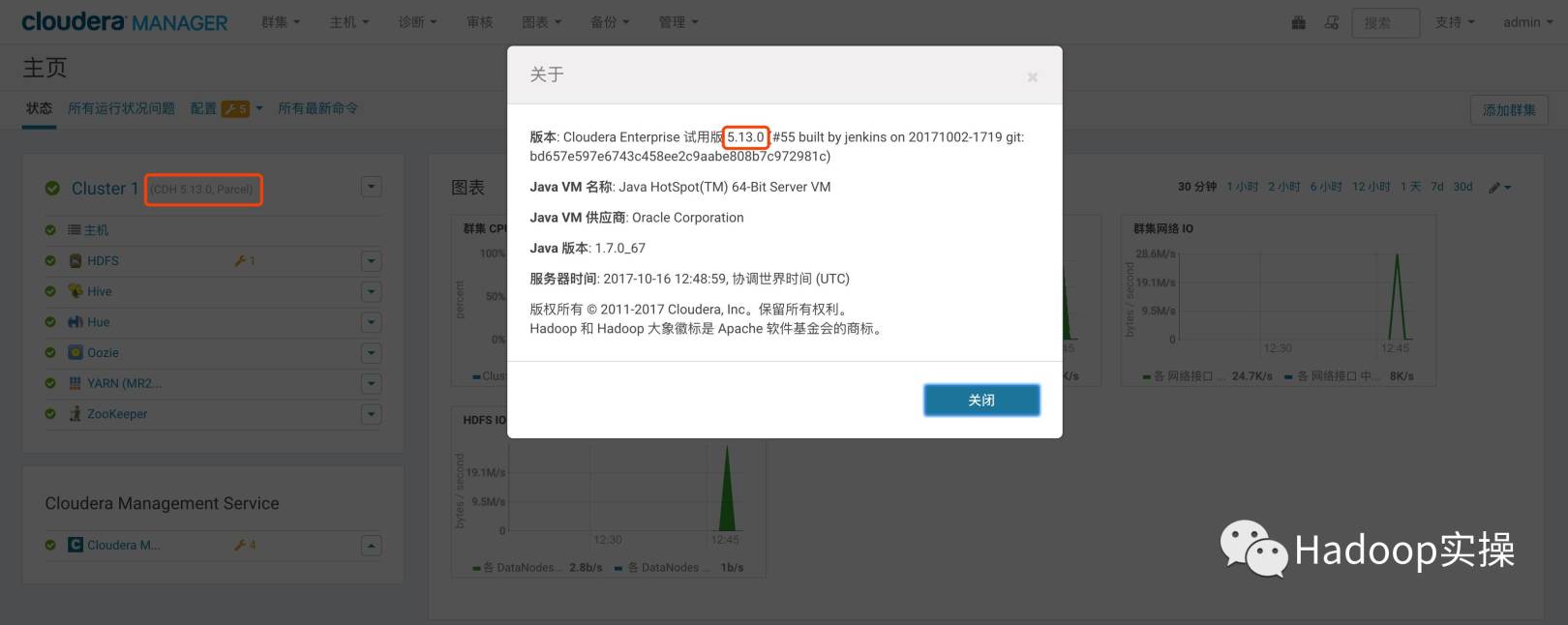
3.3 Kuduのインストール
CDH 5.13.0バージョン以降、KuduはCDHのParcelsパッケージに統合されています。したがって、インストールは以前よりも簡単で便利です。
- CMにログインしてホームページに入り、対応するクラスターの[サービスの追加]をクリックします

- サービス選択インターフェースに入り、「Kudu」を選択します
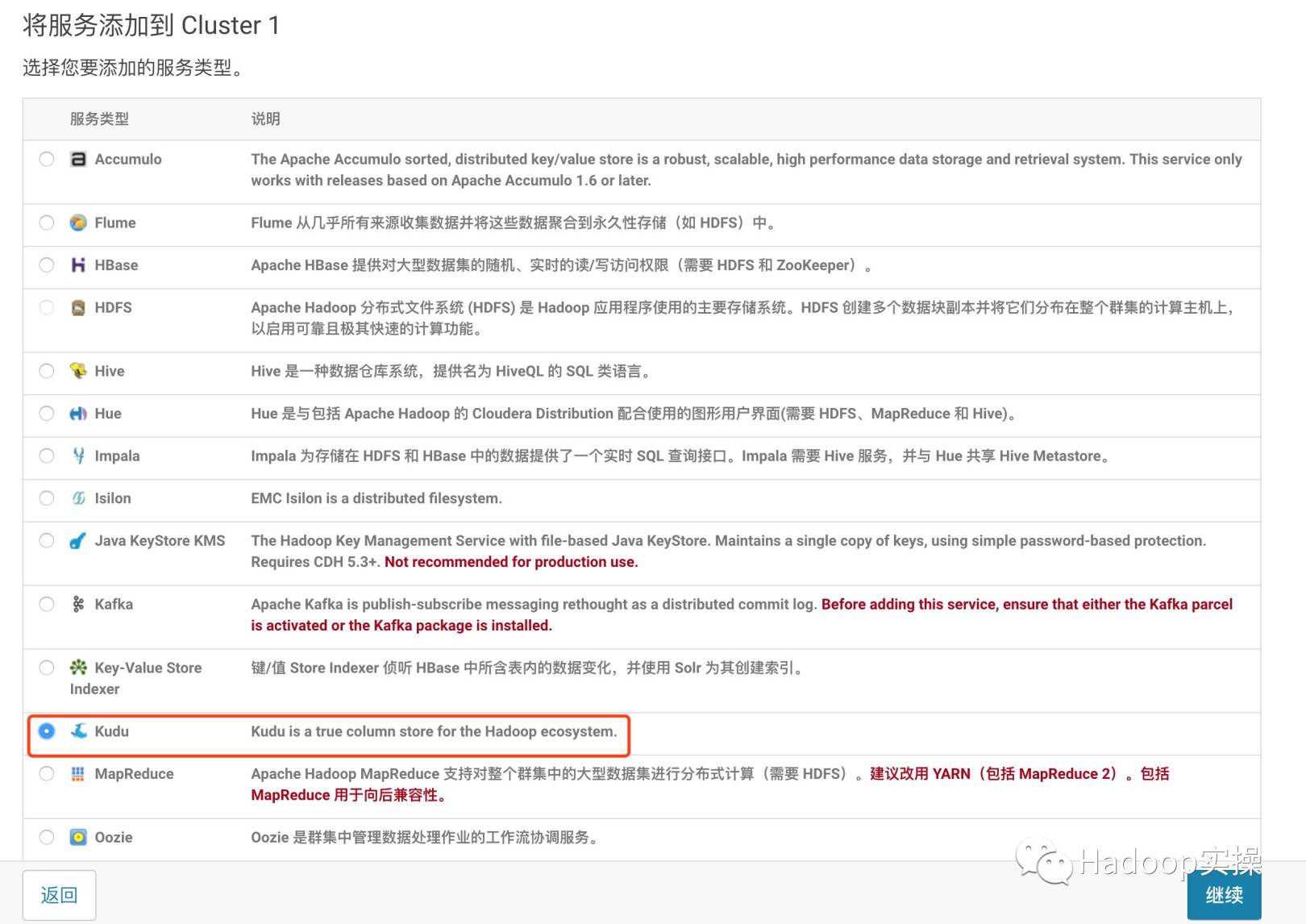
- [続行]をクリックして、Kuduの役割の割り当てを入力し、Kuduマスターとタブレットサーバーを割り当てます
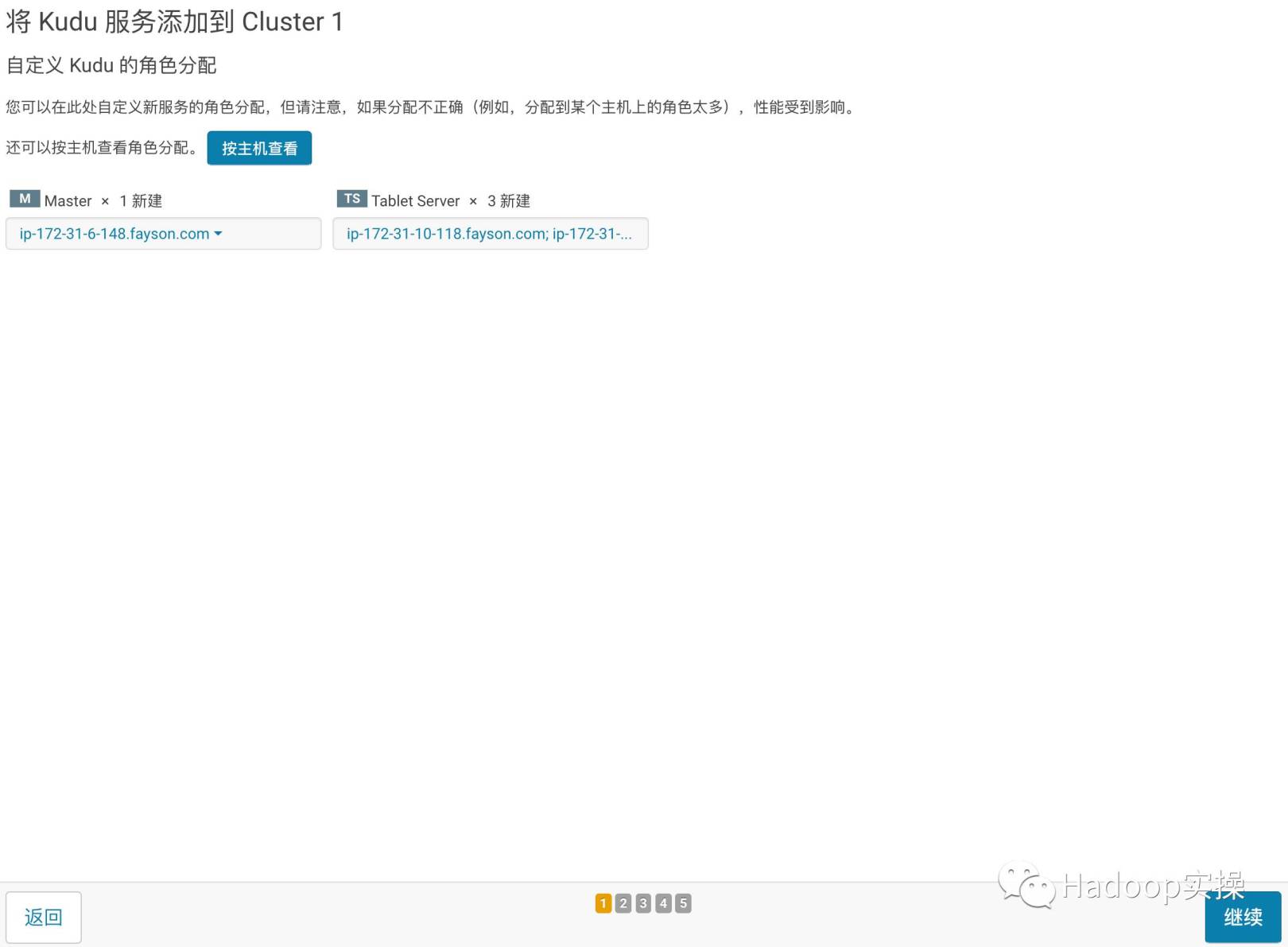
- [続行]をクリックして、KuduのWALおよびデータディレクトリを構成します
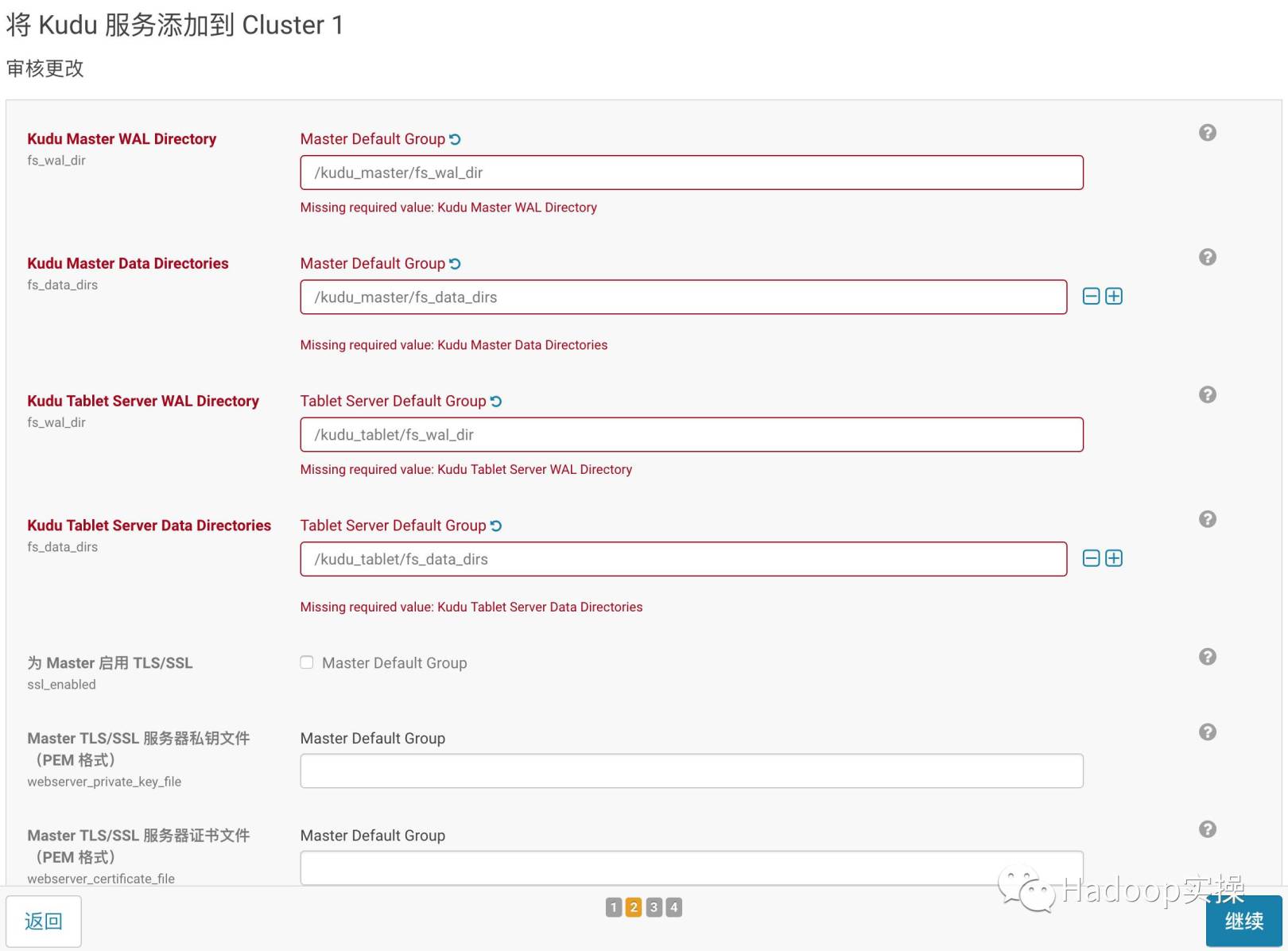
- [続行]をクリックして、Kuduサービスをクラスターに追加し、開始します

- [続行]をクリックして、Kuduサービスのインストールを完了します

- CMホームページを確認してください。Kuduサービスが正常にインストールされています。
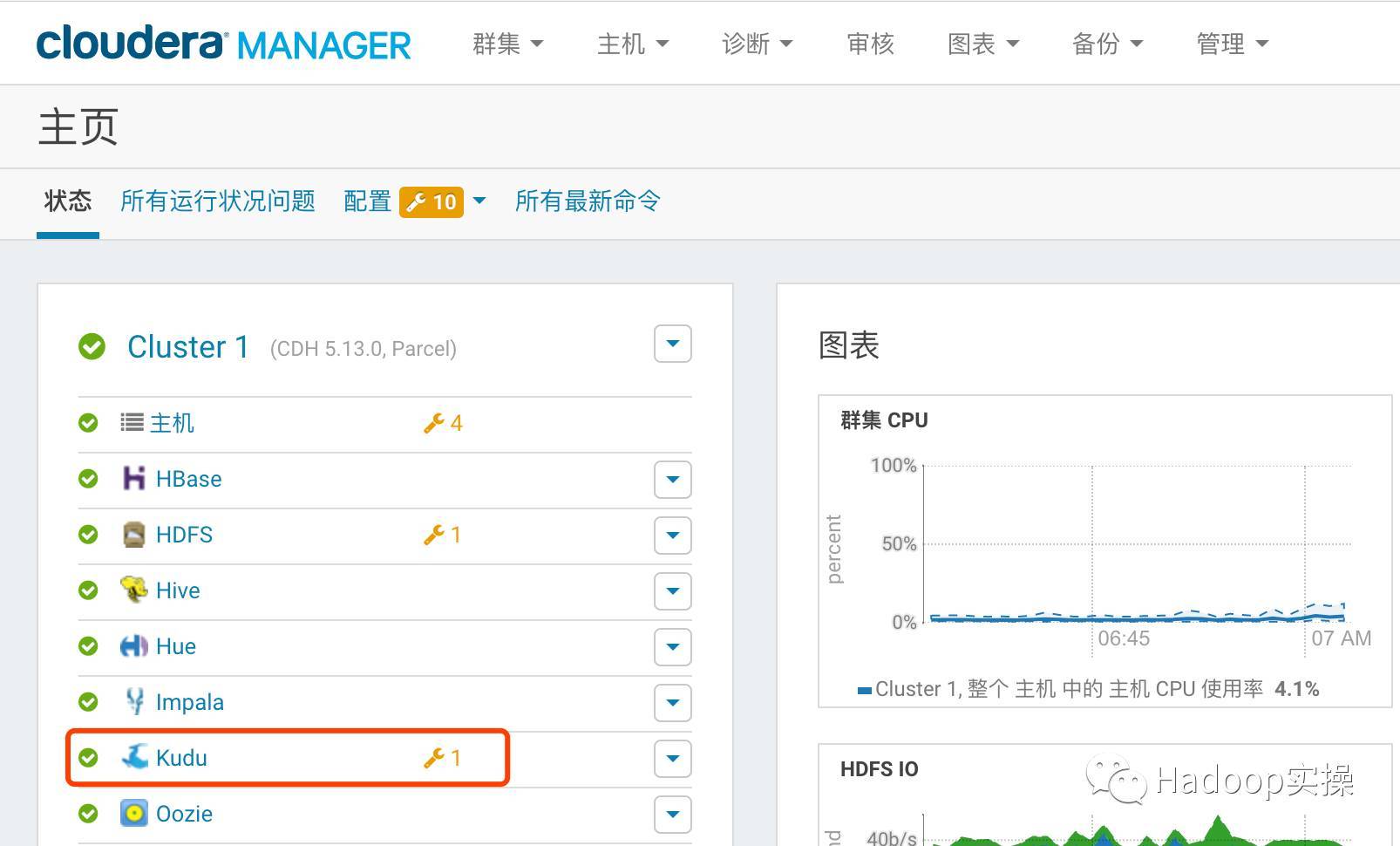
- Kuduと統合するようにImpalaを構成する
デフォルトでは、ImpalaはSQL操作のためにKuduを直接操作できますが、テーブルを作成するたびにTBLPROPERTIESにkudu_master_addresses属性を追加する必要をなくすために、Impalaの高度な構成でKuduMasterのアドレスを構成することをお勧めします。--kudu_master_hosts = ip-172-31-6- 148.fayson.com:7051

構成を保存し、CMホームページに戻り、プロンプトに従って対応するサービスを再起動します。
4. 高速コンポーネントサービス検証
4.1 HDFS検証(mkdir + put + cat + get)
[ root@ip-172-31-6-148~]# hadoop fs -mkdir -p /fayson/test_table
[ root@ip-172-31-6-148~]# cat a.txt
1, test
2, fayson
3, zhangsan
[ root@ip-172-31-6-148~]#hadoop fs -put a.txt /fayson/test_table
[ root@ip-172-31-6-148~]# hadoop fs -cat /fayson/test_table/a.txt
1, test
2, fayson
3, zhangsan
[ root@ip-172-31-6-148~]# rm -rf a.txt
[ root@ip-172-31-6-148~]# hadoop fs -get/fayson/test_table/a.txt .[root@ip-172-31-6-148~]# cat a.txt
1, test
2, fayson
3, zhangsan
[ root@ip-172-31-6-148~]#

4.2 ハイブの検証
[ root@ip-172-31-6-148~]# hive
hive>> create external table test_table(> s1 string,> s2 string
>)> row format delimited fields terminated by ','> stored as textfilelocation '/fayson/test_table';
OK
Time taken:2.117 seconds
hive> select *from test_table;
OK
1 test
2 fayson
3 zhangsan
Time taken:0.683 seconds, Fetched:3row(s)
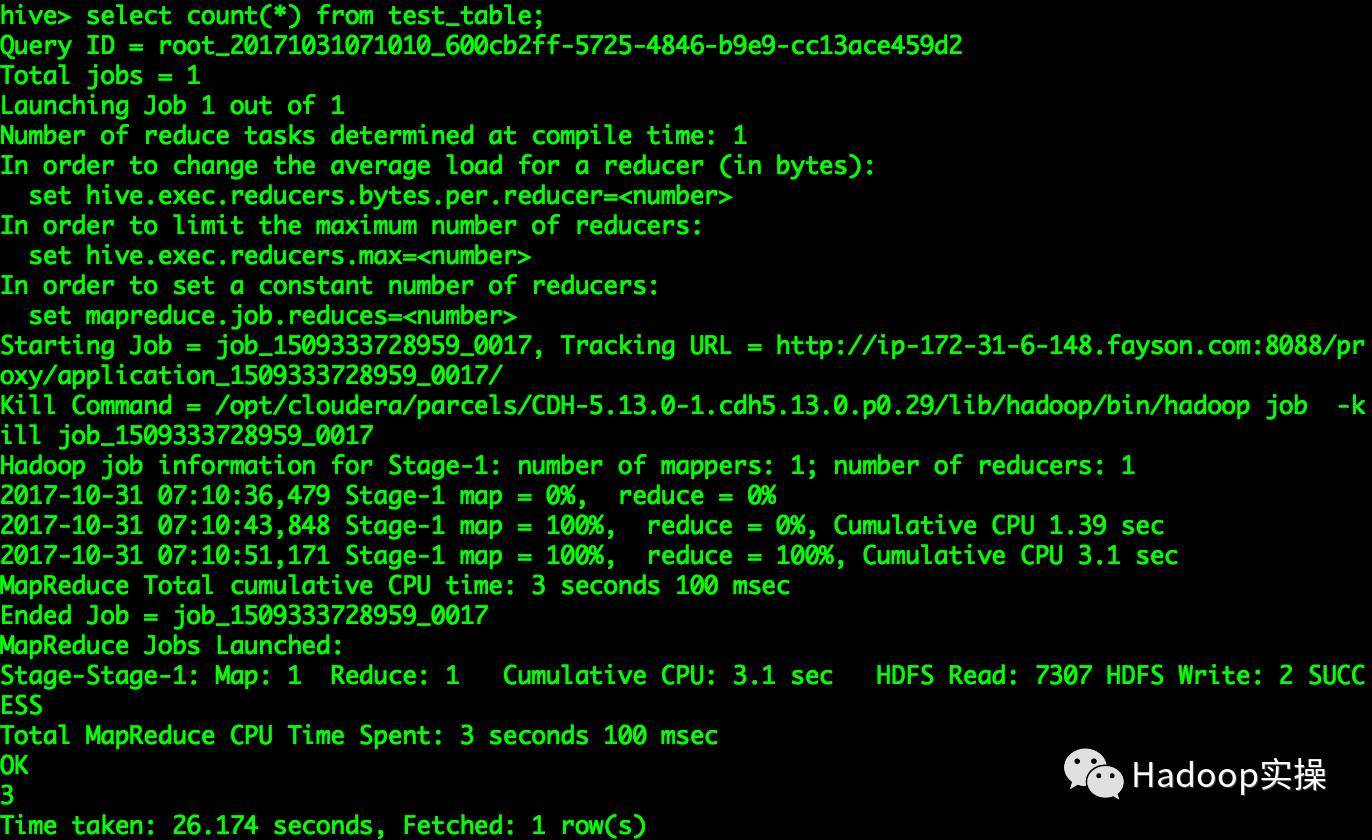
hive> select count(*)from test_table;...
OK
3
Time taken:26.174 seconds, Fetched:1row(s)
hive>

4.3 MapReduce検証
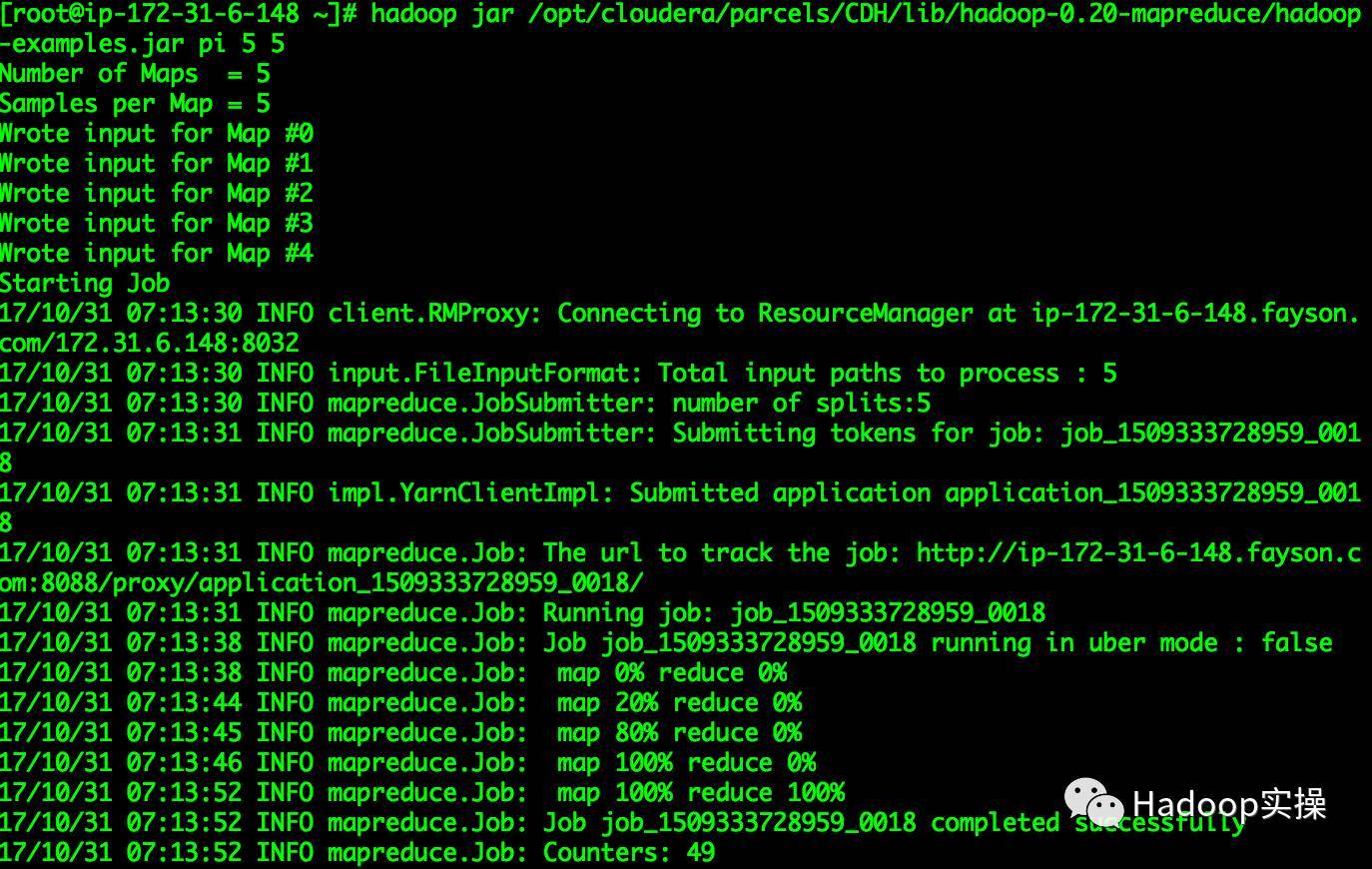
root@ip-172-31-6-148~]# hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-examples.jar pi 55...17/10/3107:13:52 INFO mapreduce.Job: map 100% reduce 100%17/10/3107:13:52 INFO mapreduce.Job: Job job_1509333728959_0018 completedsuccessfully
...
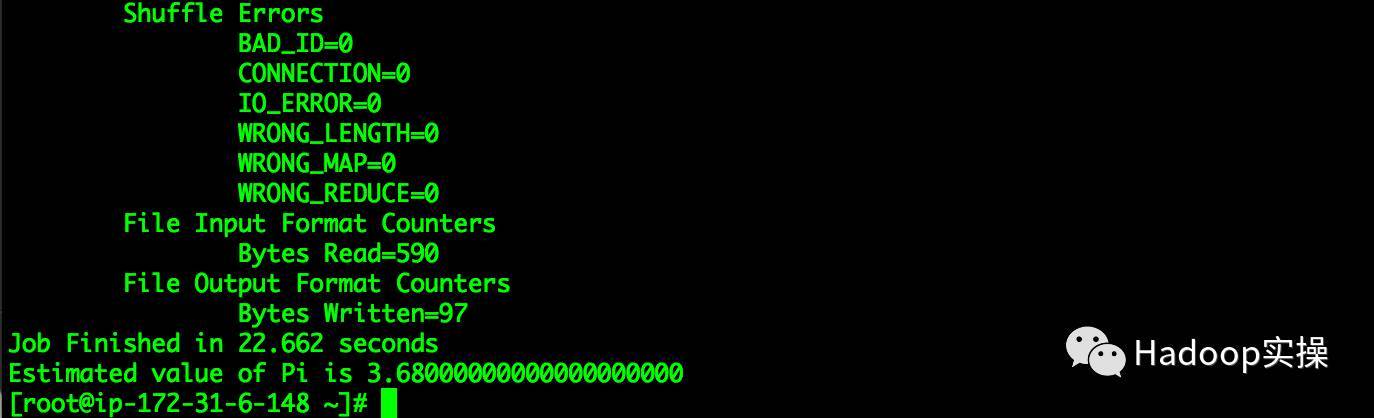
Job Finished in22.662 seconds
Estimated value of Pi is 3.68000000000000000000[root@ip-172-31-6-148~]#
4.4 インパラ検証
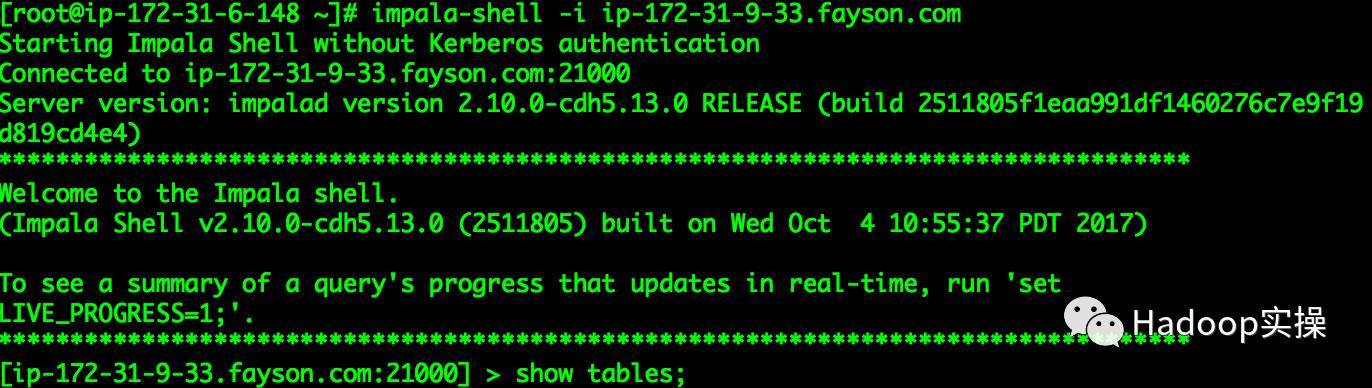
[ root@ip-172-31-6-148~]# impala-shell -i ip-172-31-9-33.fayson.com
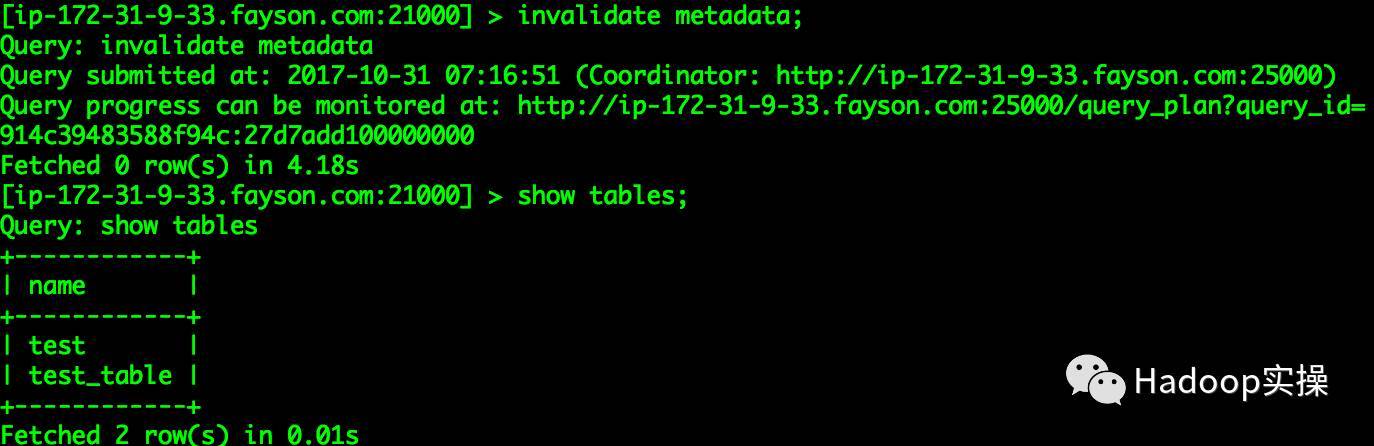
...[ ip-172-31-9-33.fayson.com:21000]> invalidate metadata;...
Fetched 0row(s)in4.18s
[ ip-172-31-9-33.fayson.com:21000]> show tables;
Query: show tables
+- - - - - - - - - - - - +| name |+------------+| test || test_table|+------------+
Fetched 2row(s)in0.01s
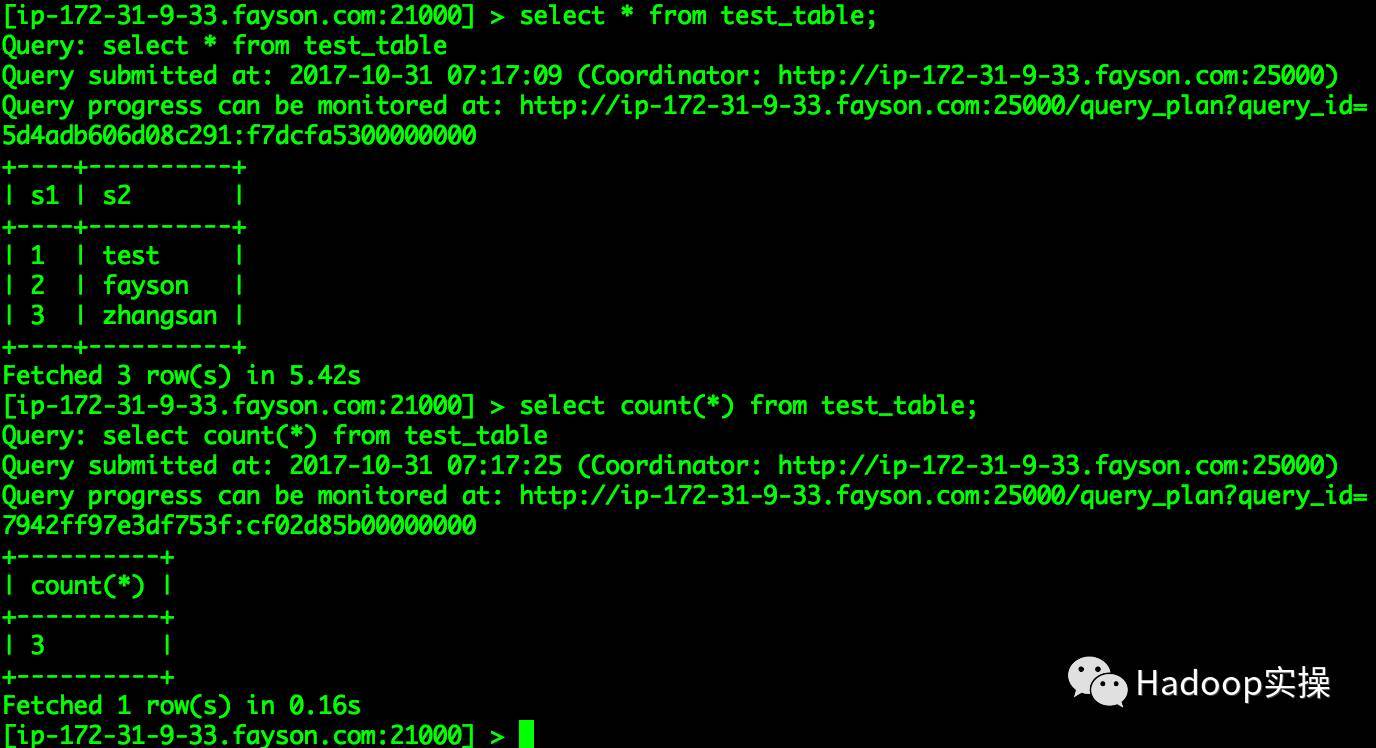
[ ip-172-31-9-33.fayson.com:21000]> select *from test_table;...+----+----------+| s1 | s2 |+----+----------+|1| test ||2| fayson ||3| zhangsan |+----+----------+
Fetched 3row(s)in5.42s
[ ip-172-31-9-33.fayson.com:21000]> select count(*)from test_table;...+----------+|count(*)|+----------+|3|+----------+
Fetched 1row(s)in0.16s
[ ip-172-31-9-33.fayson.com:21000]>
4.5 スパーク検証
[ root@ip-172-31-6-148~]# spark-shell
Welcome to
____ __
/ __/__ ___ _____//__
_\ \ / _ \/ _ `/__/ '_//___/.__/\_,_/_//_/\_\ version 1.6.0/_/
Using Scala version 2.10.5(Java HotSpot(TM)64-Bit ServerVM, Java 1.7.0_67)...
scala>var textFile=sc.textFile("/fayson/test_table/a.txt")
textFile: org.apache.spark.rdd.RDD[String]=/fayson/test_table/a.txt MapPartitionsRDD[1] at textFile at <console>:27
scala> textFile.count()
res0: Long =3
scala>

4.6 Kudu検証
[ root@ip-172-31-6-148~]# impala-shell -i ip-172-31-9-33.fayson.com
...[ ip-172-31-9-33.fayson.com:21000]> CREATE TABLE my_first_table(> id BIGINT,> name STRING,> PRIMARY KEY(id)>)> PARTITION BY HASH PARTITIONS 16> STORED AS KUDU;...
Fetched 0row(s)in2.40s
[ ip-172-31-9-33.fayson.com:21000]> INSERT INTO my_first_table VALUES(99,"sarah");...
Modified 1row(s),0 row error(s)in4.14s
[ ip-172-31-9-33.fayson.com:21000]> INSERT INTO my_first_table VALUES(1,"john"),(2,"jane"),(3,"jim");...
Modified 3row(s),0 row error(s)in0.11s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+-------+| id | name |+----+-------+|1| john ||99| sarah ||2| jane ||3| jim |+----+-------+
Fetched 4row(s)in1.12s
[ ip-172-31-9-33.fayson.com:21000]>deletefrom my_first_table where id =99;...
Modified 1row(s),0 row error(s)in0.17s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+------+| id | name |+----+------+|1| john ||2| jane ||3| jim |+----+------+
Fetched 3row(s)in0.14s
[ ip-172-31-9-33.fayson.com:21000]> update my_first_table set name='fayson' where id=1;...
Modified 1row(s),0 row error(s)in0.14s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+--------+| id | name |+----+--------+|2| jane ||3| jim ||1| fayson |+----+--------+
Fetched 3row(s)in0.04s
[ ip-172-31-9-33.fayson.com:21000]> upsert into my_first_table values(1,"john"),(2,"tom");...
Modified 2row(s),0 row error(s)in0.11s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+------+| id | name |+----+------+|2| tom ||3| jim ||1| john |+----+------+
Fetched 3row(s)in0.06s
[ ip-172-31-9-33.fayson.com:21000]> select count(*)from my_first_table;...+----------+|count(*)|+----------+|3|+----------+
Fetched 1row(s)in0.39s
[ ip-172-31-9-33.fayson.com:21000]>

天と地の心を築き、人々の生活を築き、神聖で最高の知識を受け継ぎ、すべての年齢の人々に平和を開いてください。
注意:高解像度のコード化されていない写真のセットを表示するには、携帯電話を使用して写真を開き、クリックして拡大してください。
Hadoopの実際の操作に注意を払い、最初はより多くのHadoop乾物を共有することをお勧めします。転送と共有へようこそ。
元の記事、再版を歓迎します、示してください:WeChatパブリックアカウントHadoopの実用的な操作から再版

Recommended Posts