Python3.mdの使用を開始する
[ TOC]
1. Python3 ###の簡単な紹介
3.0バージョンのPythonは、Python 3000、または略してPy3kと呼ばれることがよくあります。
Python言語の幅:
-
Webアプリケーション開発
DjangoやTurboGearsなどの豊富なWeb開発フレームワークを使用したサーバー側プログラミングにより、Webサイト開発とWebサービスを迅速に完了します。典型的な例は、国内のDouban、Guokangなど、海外のGoogle、Dropboxなどです。 -
システムネットワークの運用と保守
運用・保守作業では、繰り返し作業が多く、作業の自動化や作業効率の向上のために、管理システム、監視システム、公開システムなどを行う必要があります。Pythonはそのようなシナリオに最適な言語です。 -
科学とデジタルコンピューティング
Pythonは、バイオインフォマティクス、物理学、アーキテクチャ、地理情報システム、画像視覚化分析、ライフサイエンスなどの科学およびデジタルコンピューティングで広く使用されており、numpy、SciPy、Biopython、SunPyなどで一般的に使用されています。 -
3 Dゲーム開発
Pythonには優れた3Dレンダリングライブラリとゲーム開発フレームワークがあり、Disney CartoonCityやDarkBladeなど、Pythonを使用して開発されたゲームはたくさんあります。一般的に使用されるPyGame、PykyraなどとPyWeekゲーム。 -
グラフィカルインターフェイスの開発
Pythonは、デスクトップのグラフィカルユーザーインターフェイスを記述できます。また、Microsoft Windows、一般的に使用されるTk、GTK +、PyQt、win32などを拡張することもできます。 -
ネットワークプログラミング
ネットワークとインターネットのサポートに加えて、Pythonは、使いやすいSocketインターフェイスと非同期ネットワークプログラミングフレームワークTwisted Pythonを使用して、基盤となるネットワークのサポートも提供します。
2. Python3のインストール###
LinuxにPython3コマンドをインストールし、公式Webサイト[https://www.python.org/downloads/source/](https://www.python.org/downloads/source/)からダウンロードします。
tar -zxvf Python-3.6.1.tgz
cd Python-3.6.1./configure
make && make install
python3 -V
ipythonはpythonインタラクティブシェルです(iはinteractionの略です)。デフォルトのpythonシェルよりもはるかに使いやすく、自動変数補完、自動インデント、bashシェルコマンドをサポートしています。多くの便利な機能と組み込みがあります。関数。
Linux環境は、次のコマンドを使用してインストールすることもできます。
pip install ipython
sudo apt-get install ipython #Ubuntu
yum install ipython #c entos
環境変数の構成:
setenv PATH "$PATH:/usr/local/bin/python"//csh shellexport PATH="$PATH:/usr/local/bin/python"// bash shell (Linux)入る
PATH="$PATH:/usr/local/bin/python"//shまたはkshシェルを入力します:
path=%path%;C:\Python //Windowsで環境変数を設定する:
Python環境変数:

Python環境トラバーサル
Pythonを実行する3つのモード
- インタラクティブな通訳とスクリプトプログラミング
- Cloud StudioでPython3プログラムを実行します(推奨:[https://studio.dev.tencent.com/)](https://studio.dev.tencent.com/%EF%BC%89)
- インタラクティブなipythonでPythonを実行する
Pythonコマンドラインのパラメータは次のとおりです。
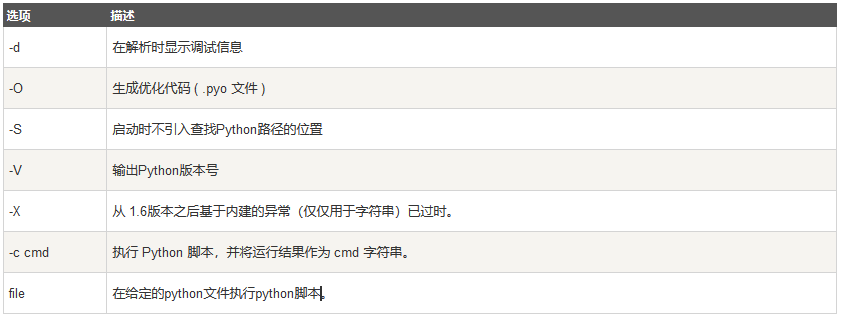
Pythonコマンドラインパラメータ
3. Python3とPython2.X ###の比較
- 違い0:印刷出力を使用する場合は形式が異なり、Py2は「」を使用しますが、python3は()関数形式を使用します*
# Py2
print a
# py3
print(a)
- 違い1: `バッククォートはPython2.xで使用できますが、Python3は廃止されています。理由の1つはシングルクォートと簡単に混同されます*
>>> a =1024>>> b ="weiyigeek">>>print( b + a) #3.x
>>> print b + a #2.x
# エラー、解決策を報告します
>>> print b +`a` #2.x
Weiyigeek1024 #実際にreprと``結果の文字列を正当なPython式に変換するのに十分な一貫性があります;>>>print( b +repr(a)) #3.x上記と同じ
>>> print( b +str(a)) #3.x
- 違い2:pthon2のraw_input()は、Python3 *の入力関数と同じ関数を持っています
説明:raw_input関数はpy3で削除され、input関数と1つにマージされました。
>>> name =raw_input("あなたの名前を入力してください:") #2.x
名前を入力してください:WeiyiGeek
>>> print(name)
WeiyiGeek
- 違い3:ptthon2にはcmp比較関数がありますが、Python3 *には存在しません
# cmp(ストリング,ストリング)またはcmp(int,int) 比较ストリング和整形
>>> cmp(1,2) #前者は後者よりも小さい-1-1>>>cmp("abc","abb") #前者は後者が11を返すよりも大きい>>>cmp("abc","abc") #前者は後者と同じで、00を返します
- 違い4:文字セットがpthhon2とPython3 *で異なります
Python2は中国語が文字化けする傾向があるため、次の3つの方法で解決できます。
# 方法1;ファイルの先頭にあるステートメント
# - *- coding:utf-8-*-
# 方法2:
unicode_str =unicode('中国語',encoding="utf-8");
print unicode_str.encode('utf-8');
# 方法3:コードを使用してファイルを開く.open関数の代わりにopen;
import codecs
codecs.open('filename',encoding='utf-8');
補足:
# コードセットが指定されていない場合、エラーを報告するのは簡単です
UnicodeDecodeError:'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)'
# これはasciiコーディングの問題であることがわかりました。問題を解決するには、プログラムコードの前に次の文を追加してください。
import sys
reload(sys)
sys.setdefaultencoding('gb18030')
- 違い5:python3.5とPython2.7は、ソケットの戻り値のデコードが異なります:*
strは、encode()メソッドを使用して、指定したバイトにエンコードできます。ネットワークまたはディスクからバイトストリームをバイトとして読み取る場合は、decode()メソッドを使用してバイトをstrに変換する必要があります。
# Python3 - encode
>>>" 私はサイバーセキュリティの専門家です".encode('utf-8')
b'\xe6\x88\x91\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe7\xbd\x91\xe7\xbb\x9c\xe5\xae\x89\xe5\x85\xa8\xe4\xbb\x8e\xe4\xb8\x9a\xe8\x80\x85'>>>"私はサイバーセキュリティの専門家です".encode('gbk')
b'\xce\xd2\xca\xc7\xd2\xbb\xb8\xf6\xcd\xf8\xc2\xe7\xb0\xb2\xc8\xab\xb4\xd3\xd2\xb5\xd5\xdf'
# Python3 - decode
se.decode('gbk')'私はサイバーセキュリティの専門家です'>>> b'\xe6\x88\x91\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe7\xbd\x91\xe7\xbb\x9c\xe5\xae\x89\xe5\x85\xa8\xe4\xbb\x8e\xe4\xb8\x9a\xe8\x80\x85'.decode('utf-8')'私はサイバーセキュリティの専門家です'
- 違い6:python3と2には違いがありますpipインストールソフトウェアの違い*
# mysqlパッケージの違い
py2:pip install mysql-python
py3:pip install mysqlclient
4. Python3の基本構文###
4.1 Python中国語コーディング####
Pythonのデフォルトのエンコード形式はASCII形式です。エンコード形式を変更しないと中国語の文字を正しく印刷できないため、中国語を読み取るとエラーが報告されます。すべてのコードに中国語が含まれているため、ヘッダーでエンコードを指定する必要があります。
ケース1:最初のPythonプログラムHello Wrold:
# 解決策:ファイルの先頭に追加するだけです# -*- coding: UTF-8-*-または#coding=utf-8が行います
#! /usr/bin/python3
# coding=utf-8
# - *- coding: UTF-8-*-
# - *- coding: cp936 -*-print("Hello World, Python 3.x!のみ")print("こんにちは世界");

Python中国語エンコーディング
予防:
Python3.Xソースコードファイルはデフォルトでutf-8エンコーディングを使用するため、中国語はUTF-8エンコーディングを指定しなくても通常どおり解析できますが、開発中にpy [ファイルストレージ](https://cloud.tencent.com/product/cfs?from=10680)の形式をUTF-8に設定する必要があります。そうしないと表示されます。次のエラーメッセージのように
4.2 Pythonの基本的な文法学習####
Pythonでは、すべての識別子に英語、数字、下線(_)を含めることができますが、数字で始めることはできず、識別子は大文字と小文字が区別されます。
単一の下線:単一の下線_fooの先頭で直接アクセスできないクラス属性には、クラスが提供するインターフェイスを介してアクセスする必要があります,xxxインポートからは使用できません*インポート。
二重下線:二重下線で始まる__fooはクラスのプライベートメンバーを表し、二重のアンダースコアで始まり、終わります。__foo__次のようなPythonの特別なメソッド専用の識別子を表します__init__()クラスのコンストラクターを表します。
Python変数の定義:
Pythonの変数を宣言する必要はありません。各変数には、使用する前に値を割り当てる必要があります。変数は、変数が割り当てられた後に作成されます。
Pythonは弱く型付けされた言語であるため、型はオブジェクトに属し、変数には型がありません。変数はオブジェクト(ポインター)への単なる参照であり、変数は割り当てによってさまざまな種類のオブジェクトを指すことができます。
等符号(=)演算子の左側は変数名であり、等符号(=)演算子の右側は変数に格納されている値です。Pythonでは、複数の変数に同時に値を割り当てることができます。値を指定すると、Numberオブジェクトは作成されたら、* delステートメント*を使用していくつかのオブジェクト参照を削除できます。
a=[1,2,3]
a="Runoob"
# 上記のコードでは、[1,2,3]タイプはリストで、"Runoob"文字列タイプであり、変数aにはタイプがなく、彼女はただ
# これは、オブジェクト(ポインタ)への参照であり、リストタイプのオブジェクトまたは文字列タイプのオブジェクトのいずれかを指すことができます。
pythonでは、文字列、タプル、および数値は変更不可能なオブジェクトですが、list、dict、およびsetは変更可能なオブジェクトです。
- 不変タイプ:変数割り当てa = 5、次に割り当てa = 10、これは実際には新しく生成されたint値オブジェクト10であり、それをポイントし、5は破棄されます。aの値を変更する代わりに、新しく生成されたものと同等です。 。
- 変数タイプ:変数割り当てla = [1,2,3,4]次に割り当てla [2] = 5は、リストlaの3番目の要素の値を変更します。la自体は変更されず、内部値の一部のみが変更されます。変更されました。
ケース:Python変数の割り当て:
#! /usr/bin/python3
# - *- coding:UTF-8-*-
# 機能:変数の定義と使用
int1 =23
float1 =100.0
string ="WeiyiGeek"print("名前:",string,"年齢:",int1,"割合:", float1,end="\n")
a = b = c =1 #値が1の整数オブジェクトを作成し、値を後ろから前に割り当て、3つの変数に同じ値を割り当てます
print(a,b,c,end="\n")
a,b,c =1,2,"WeiyiGeek" #2つの整数オブジェクト1と2が変数aとb、文字列オブジェクトに割り当てられます"runoob"変数cに割り当てられます。
print(a,b,c,end=" ")
del a,b
print(a,b,c,end=" ") #ここで言うでしょう,b未定義(未定義)

Python変数の割り当て
Pythonの予約文字と関数のヘルプ:
これらの予約済みワードは、定数や変数、またはその他の識別子名として使用することはできません。組み込みの関数ヘルプとPython3出力形式:
>>> import keyword
>>> keyword.kwlist
[' False','None','True','and','as','assert','async','await','break','class','continue','def','del','elif','else','except','finally','for','from','global','if','import','in','is','lambda','nonlocal','not','or','pass','raise','return','try','while','with','yield']
# BIF=built-in functions
>>> dir(__builtins__)>>>help(int)>>>print("string")
Pythonでのコメント:
# '' '"" "を使用してコードにコメントを付けます。ペアで使用される最初のコードを除いて、コメント出力は出力関数でも実行できることに注意してください。
# 次の例では、関数のコメントを出力できます。
def a():'''これはdocstringです'''
pass
print(a.__doc__) #出力は次のとおりです。これはdocstringです
Pythonの行とインデント:
Pythonコードブロックでは、{}は、他の言語のようにクラス、関数、およびその他の論理的判断を制御するために使用されなくなりましたが、インデントされた方法で使用されます。
したがって、Pythonコードブロックでは、行の先頭に同じ数のインデントスペースを使用する必要があります。各インデントレベルで単一タブまたは* 2スペースまたは 4スペース*を使用することをお勧めします。混用;
- 注:*インデントされたブランクの数は可変ですが、すべてのコードブロックステートメントには同じ量のインデントされたブランクが含まれている必要があります。これは厳密に適用する必要があります。
Pythonでの空白行の意味:
空白行を使用してクラスの関数またはメソッドを区切り、新しいコードの始まりを示します。クラスと関数のエントリも、関数のエントリの先頭を強調するために空白行で区切られています。
空白行はコードインデントとは異なります。空白行はPython構文の一部ではありません。書き込むときは、空白行を挿入しないでください。Pythonインタープリターはエラーなしで実行されます。ただし、空白行の機能は、機能や意味が異なる2つのコードセクションを分離することです。これは、将来のコードの保守や再構築に便利です。空白行はプログラムコードでもあります。部。
Pythonの複数行のステートメント:
通常、ステートメントは1行で記述されますが、ステートメントが非常に長い場合は、バックスラッシュ()を使用して複数行のステートメントを実装できます。ただし、[]、{}、または()の複数行のステートメントでは、「、」を直接使用して分割、バックスラッシュ()を使用する必要はありません。
同じ行で複数のステートメントを使用し、セミコロン(;)を使用してステートメントを区切ります。
ケース:複数行のステートメントを検証するには、入力ステートメントを1行に分割します
#! /usr/bin/python3
# - *- coding:UTF-8-*-
# 機能:Pythonの複数行ステートメントを確認する
one =1
two =2
three =3
add = one +\
two +\
three
print("add =",add);print(add); #1行で出力を使用する;セグメンテーション
Pythonモジュールのインポート:
importまたはfrom ... importを使用して、対応するモジュールをpythonにインポートします。
- モジュール全体をインポートします(somemodule)| import modulename |
- モジュールから関数をインポートする| modulenameから関数をインポートするimportfunction |
- モジュールから複数の関数をインポートします。形式は| from modulename import function1、function1 |
- モジュール内のすべての関数をインポートする| somemodule import * |
4.3 Pythonの基本的なデータタイプ####
Python3には6つの標準データタイプがあります。
番号(番号)文字列(文字列)リスト(リスト)タプル(タプル)セット(コレクション)辞書(辞書)
- 不変データ(3):数値(数値)、文字列(文字列)、タプル(タプル)
- 変数データ(3):リスト(リスト)、辞書(辞書)、セット(コレクション)
- データタイプエイリアス:*
- シーケンスタイプ:リスト/プリミティブ/文字列
- マッピングコンテナ:辞書(オブジェクトの保存)
4.3.1 整数(整数)#####

Python整数データ変数
複素数は実数部と虚数部で構成され、+ bjまたは複素数(a、b)で表すことができます。複素数の実数部aと虚数部bはどちらも浮動小数点型です。
E表記:15e10 => 15 * 10の10乗= 150000000000.0;インタラクティブモードでは、最後の出力式の結果が変数_に割り当てられます。
場合:
>>> price =113.0625>>> _ =0>>> price + _ #ここに、_変数は、ユーザーが読み取り専用変数として扱う必要があります。
113.0625>>> round(_,2)113.06
#! /usr/bin/python3
# - *- coding:UTF-8-*-
# 機能:基本データタイプ,入力および出力機能で使用
#- - - - integer----#
temp =input("番号を入力してください:")print("入力値: ",temp," |の種類:",type(temp))
temp ='5'
number =int(temp) #文字を整数型に変換する
print("文字変換整数: ",number," |の種類:",type(number))
temp = True
temp =4+3j #複数タイプ
print("複数:",temp," |の種類:",type(temp),end="\n\n")
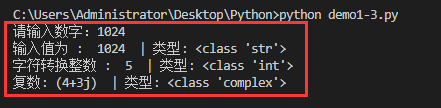
Python整数データ変数の場合
- 予防:*
- Python2にはブール型はありません。0はFalseを表し、1はTrueを表します。
- Python3では、TrueとFalseはキーワードとして定義されており、それらの値は1と0のままであり、数値に追加できます。
- Python3では、16進数と8進数を使用して整数を表します。number= 0xA0F#16進数0o37#8進数
- Jは、負の数では大文字と小文字を区別できません
4.3.2 文字列(文字列)#####
pythonの単一引用符と二重引用符はまったく同じであり、文字列は変更できません。三重引用符( "'または" "")を使用して、行間WYSIWYG(表示されるものが取得されるもの)形式の複数行文字列を指定します。
Pythonは単一文字タイプをサポートしていません。str= 'a'のように、単一文字はPythonの文字列としても使用されます。文字列には、新行文字、タブ、およびその他の特殊文字を含めることができます。
Python文字列は、+演算子で連結したり、*演算子で繰り返したり、文字通り文字列を連結したりできます。たとえば、「this」「is」「string」は自動的にthisis文字列に変換されます。
Pythonは、インデックス付けによって文字列内の文字をインターセプトします。構文形式は次のとおりです。変数[ヘッド添え字:テール添え字](左から右に0で始まり、右から左に-1で始まる2つのインデックス方法があります)
[:] 文字列の一部をインターセプトするには、左クローズと右オープンの原則に従います。str[0,2]には3番目の文字が含まれていません。
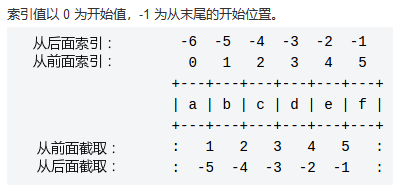
Python文字列インデックス
Pythonエスケープ文字:
バックスラッシュを使用してエスケープできます。バックスラッシュがエスケープされないようにするには、rを使用します。たとえば、r "this is a line with \ n"は、新しい行の代わりに\ nを表示します。
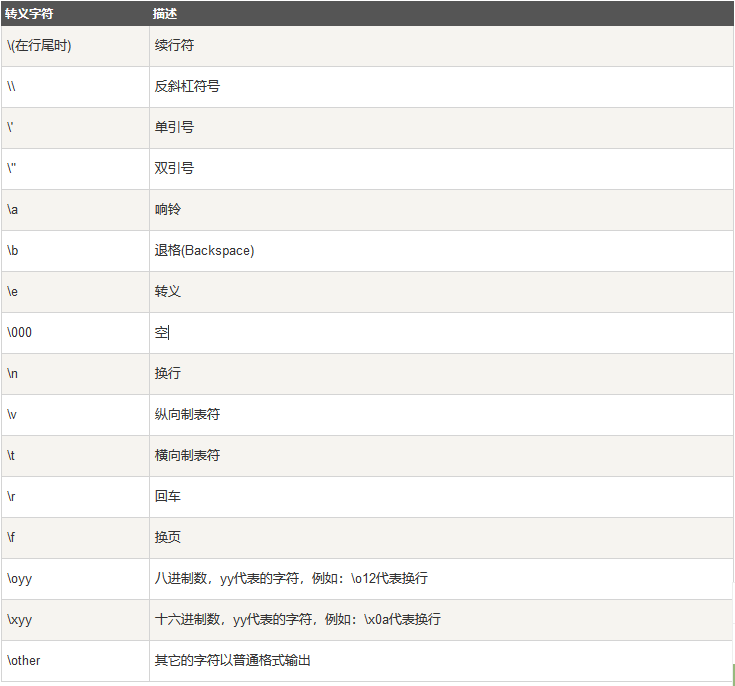
Python文字列のフォーマット
Python文字列のフォーマット:
基本的な使用法は、文字列形式の文字%sの文字列に値を挿入することです。これは、Cのsprintf関数と同じ構文です。

Python文字列のフォーマット

Pythonフォーマット演算子の補助命令
場合:
#! /usr/bin/python3
# coding:utf-8
# 機能:文字列タイプの詳細な説明
##- - - - String-----#
word ='ストリング'
sentence ="これは文です."
paragraph ="""
これは段落です、
複数の行で構成できます
"""
A =" THIS A"
B ="String !"
C = A + B #連結文字列
print(C,end="\n")print("段落:",paragraph)
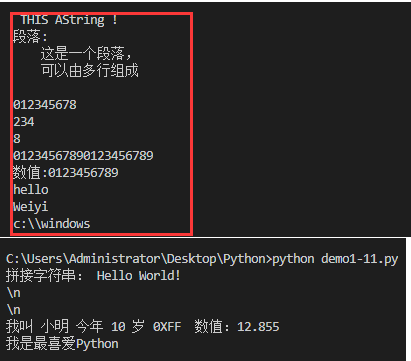
# 文字列インターセプトの文法形式は次のとおりです。[頭の添え字:テール添え字:ストライド]
str1 ='0123456789'print(str1[0:-1]) #最初から最後から2番目までのすべての文字を出力します
print(str1[2:5]) #3番目から5番目までの出力文字
print(str1[-2]) #2番目の番号
print(str1 *2) #文字列を2回出力(キーワード*繰り返す)print('値:'+ str1) #接続文字列(キーワード+スプライシング)
##- - - - キャラクターエスケープ-----#
print('hello\nWeiyi') #バックスラッシュを使用する(\)+n特殊文字をエスケープする
print(r'c:\\windows') #文字列の前にrを追加して、元の文字列を示し、エスケープされないようにします
var="Hello"print("文字列の連結:\a",var[:5]+" World!")
# 元の文字列の構文は通常の文字列とほぼ同じですが、文字列の最初の引用符の前に文字rが追加されている点が異なります(大文字と小文字)。
print(r'\n')print(R'\n')print("私の名前は%今年は%d歳%#X値:%5.3f"%('シャオミン',10,255,12.85455)) #フォーマット文字列
print("\u6211\u662f\u6700\u559c\u7231\u0050\u0079\u0074\u0068\u006f\u006e") #ユニコード出力
# ベース変換
" %o"%10 #'12'||"%#o"%10 #'0o12'"%X"%10 #'A'||"%#X"%10 #'0XA'"%x"%10 #'a'||"%#x"%10 #'0xa'
# フローティングポイントフォーマット
" %5.2f"%27.658 #'27.66'"%5.2f"%27 #'27.00'"%f"%27 #フロートタイプ,小数点以下6桁を保持'27.000000'"%e"%10000000 #'1.000000e+07'"%.2e"%27.658 #'2.77e+01"%g"%28.444455 #賢い選択'28.4445'"%g"%28261465 #'2.82615e+07'"%5d"%5 #' 5'"%-5d"%5 #'5 '-左揃えに使用
" %+d"%5 #'+5'+正と負の数値を取るために使用されます
" %+d"%-5 #'-5'"%010d"%5 #'0000000005'"%-010d"%5 #左のペアに負の符号を追加します,現時点では、0は入力されません'5print('%s'%"I love you") #フォーマット文字列'I love you'(従来の方法)
# %f形式の固定小数点番号,M.N(Mは最小の長さです,Nは小数点以下の桁数を表します?)推奨される方法
'{0:1 f}{1}'.format(27.586,"Gb") # '27.586000Gb''{0:.1f}{1}'.format(27.586,"Gb") # '27.6Gb'小数点以下1桁
" %c %c %c"%(97,98,99) #フォーマット文字Ascllコード変換'a b c''%d + %d = %d'%(4,5,4+5) #フォーマット整数'4 + 5 = 9'>>>"{:+.2f} {:+.2f}".format(3.1415926,-1) #小数点以下2桁を維持するために署名
'+3.14 - 1.00'>>>"{:.0 f}".format(3.1415926,-1) #10進抽出なし
'3'>>>"{:0>2 d}".format(3) #左をゼロサプリメントで補う
'03'>>>"{:0<2 d}".format(3) #右側をゼロサプリメントで補う
'30'>>>"{:,}". format(30000000) #コンマ区切り番号形式
'30,000,000'>>>"{:.2 %}".format(0.2657) #パーセンテージ形式
'26.57 %'>>>"{:.2e}".format(10000000000000) #インデックスレコード
'1.00 e+13'>>>"{:10d}".format(100) #右揃えの幅10ユニット
' 100'>>>"{:<10 d}".format(100) #左揃え
'100 '>>>"{:^10 d}".format(100) #中央揃え
' 100
Python文字列の例
- 予防:*
- Python2では、通常の文字列は8ビットのASCIIコードで格納されますが、Python3では、すべての文字列は16ビットのUnicode文字列で表されます。使用される構文は、文字列の前にuを付けることです。
- C文字列とは異なり、Python文字列は変更できません。word[0] = 'm'などのインデックス位置に値を割り当てると、エラーが発生します。
4.3.3 リスト(リスト)#####
リストするシーケンスは、Pythonの最も基本的なデータ構造であり、最も頻繁に使用されるデータタイプです。実行できる操作には、インデックス作成(0から開始)、スライス(スライスの組み合わせ[start:stop、step])、加算、乗算、および検査が含まれます。メンバー;リスト内の要素のタイプは異なる可能性があります(重要なのは、それらがリストになることもできるということです); Pythonリストのデータ項目は変更または更新できます。
形式:リストは、角括弧[]で囲まれ、変数[head subscript:tail subscript]のようにコンマで区切られた要素のリストです。リストは、文字列のようにインデックスを付けてインターセプトすることもできます。リストがインターセプトされた後必要な要素を含む新しいリストを返します。
Pythonリスト
焦点:リストの理解(分析)
リスト内包表記は、リスト内包表記とも呼ばれ、機能プログラミング言語Haskellに触発されており、リストを動的に作成するために使用できる非常に便利で柔軟なツールです。
文法:
[ BのAの場合]
例:list1=list(x**2for x inrange(10)) #[0,1,4,9,16,25,36,49,64,81])
ケース1:
#! /usr/bin/python3
# coding:utf-8
# 特徴:検証リスト(LIST)
#-4,-3,-2,-1,0
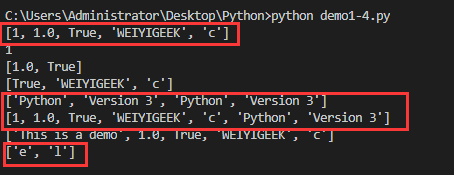
createlist =[1,1.0,True,"WEIYIGEEK",'c']
pjlist =['Python','Version 3']print(createlist) #全リスト
print(createlist[0]) #出力リストの最初の要素
print(createlist[1:3]) #2番目から3番目の要素への出力
print(createlist[-3:]) #3番目から最後の要素まで(3番目から最後の要素までのすべての要素の出力に特に注意を払う価値があります)print(pjlist *2) #リストを2回出力
print(createlist + pjlist) #リストスプライシング
createlist[0]='This is a demo' #Python文字列とは異なり、リスト内の要素は変更できます
print(createlist[:]) #全リスト
letters =['h','e','l','l','o']print(letters[1:4:2]) #ステップ実験1-e 3-l
Pythonリストケース1
ケース2:
#! /usr/bin/python3
# coding:utf-8
# 機能:詳細リストタイプ
# 更新リスト
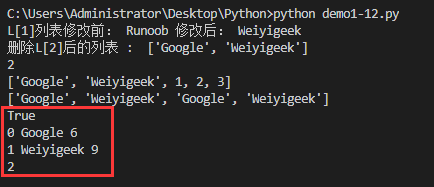
L=['Google','Runoob','Taobao']print("L[1]リスト変更前:",L[1],end=" ")
L[1]='Weiyigeek'print("変更後:",L[1],end="\n")
# リスト要素を削除する
del L[2]print("Lを削除[2]リストの後: ", L)
# リストの長さ
print(len(L))
# リストの組み合わせ
print(L+[1,2,3])
# 重複リスト
print(L *2)
# リストにあるかどうかを確認します
print('Weiyigeek'in L)
# 反復
for x inrange(len(L)):print(x,L[x],len(L[x]))
# ネストされたリストは2次元配列に似ています
x =[[1,2,3],['a','b','c']]print(x[0][1]) #出力2プリント(x[1][1]) #出力b#!/usr/bin/python3
# coding:utf-8
# 機能:詳細リストタイプ
# V1.通常のリストを作成する
L=['Google','Runoob','Taobao']
# V2.混合リストを作成する(ネストされたリスト)
mix =[1,'list0',2.3,[1,2,3]]
# V3.空のリストを作成する
empty =[]
# リストを更新します(アレイを交換することもできます)
print("L[1]リスト変更前:",L[1],end=" ")
L[1]='Weiyigeek'print("変更後:",L[1],end="\n")
# リスト要素を削除する
del L[2]print("Lを削除[2]リストの後: ", L)
# リストの長さ
print(len(L))
# リストの組み合わせ
print(L+[1,2,3])
# 重複リスト
print(L *2)
# リストにあるかどうかを確認します
print('Weiyigeek'in L)
# 反復
for x inrange(len(L)):print(x,L[x],len(L[x]))
# ネストされたリストは2次元配列に似ています
print(mix[3][1]) #出力2
# 補足リストの理解
list1 =[(x,y)for x inrange(10)for y inrange(10)if x %2==0if y %2!=0] #xは2で割り切れ、yは表示用に2で割り切れません(x.y)
print(list1)
#[(0,1),(0,3),(0,5),(0,7),(0,9),(2,1),(2,3),(2,5),(2,7),(2,9),(4,1),(4,3),(4,5),(4,7),(4,9),(6,1),(6,3),(6,5),(6,7),(6,9),(8,1),(8,3),(8,5),(8,7),(8,9)]
# 以下と同等です
list2 =[]for x inrange(10):for y inrange(10):if(x %2==0)&(y %2!=0):
list2.append((x,y))print(list2)
# 高度なリスト内包表記
list1 =['1.Jost do it','2.すべてが可能です','3.プログラミングで世界を変えましょう']
list2 =['2.粘膜','3.フィッシュCスタジオ','1.Nick']
list3 =[name+':'+title[2:]for title in list1 for name in list2 if name[0]== title[0]] #リスト分析を使用して、forループの最初の文字バリアントが一貫している場合に出力します
print(list3) #['1.Nick:Jost do it','2.粘膜:すべてが可能です','3.フィッシュCスタジオ:プログラミングで世界を変えましょう']
Pythonリストケース2
- 予防:*
- リスト内の要素の値は、list [0] = 'これはデモです'のように変更できます。
- Pythonリストインターセプトは3番目のパラメーターを受け取ることができます。このパラメーターはステップサイズをインターセプトするために使用されます。次の例は、インデックス1からインデックス4の位置に設定され、ステップサイズを2(1桁離れた)に設定して文字列をインターセプトします。
- 割り当てによって取得されたリストは、親リストの順序によって変更されます、
4.3.4 タプル#####
タプルタプルはシャックルされたリストです(数値/文字列タイプと同じで、その要素は自由に変更できません)。リストの強力な機能のため、特定の制限が必要です。
形式:タプルは括弧()で記述され、要素はコンマで区切られます(直接タプル= 1,2,3,4にすることもできます)。
主に、タプルの作成とアクセス、タプルの更新と削除、およびタプル関連の演算子から学びます。
連結演算子(両側のデータタイプは同じである必要があります)
演算子を繰り返します(8 *(8、))
リレーショナル演算子(より大きい、より小さいなど)
メンバー演算子([in] [not in])
論理演算子(>および>または)
場合:
#! /usr/bin/python3
# coding:utf-8
# 特徴:タプルタプルを検証する,チェーン上のタプルのリスト
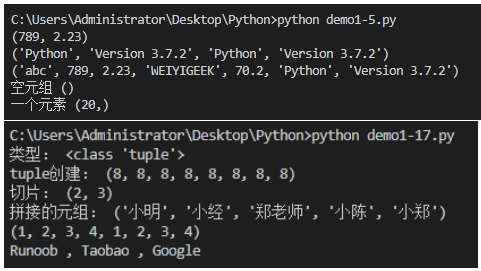
tuple1 =('abc',789,2.23,'WEIYIGEEK',70.2)
pjtuple =('Python','Version 3.7.2')print(tuple1[1:3]) #添え字インデックス1から添え字インデックス2までの要素を出力します(要素の数に注意してください3-1=2)print(pjtuple *2) #繰り返す
print(tuple1 + pjtuple) #スプライシング
# 0個または1個の要素を含むタプルの作成は特別です
tup1 =() #空のタプル
tup2 =(20,) #要素、要素の後にコンマを追加する必要があります
print("空のタプル",tup1)print("要素",tup2)
# 機能:チェーン上のタプルのリスト
tup =(1,2,3,4) #タプルを定義する
temp =1,2,3,4 #別の方法でもタプルを定義できます(学ぶ価値がある)print("の種類:",type(temp)) #の種類: <class'tuple'>print("タプルの作成:",8*(8,)) #(両方の方法でコンマが必要です)タプルの作成:(8,8,8,8,8,8,8,8)print("スライス:",temp[1:3]) #スライス(これを使用してタプルをコピーすることもできます)スライス:(2,3)
temp =('シャオミン','Xiaojing','シャオ・チェン','シャオ・チェン')
temp = temp[:2]+('鄭先生',)+temp[2:] #スライス方法を使用して2つのセグメントに分割し、新しい要素を追加してからスプライスします,カンマとタイプに注意してください. #連結されたタプル:('シャオミン','Xiaojing','鄭先生','シャオ・チェン','シャオ・チェン')print("連結されたタプル:",temp)
del temp #オブジェクト指向のプログラミング言語にはリサイクルメカニズムがあります
print(tup *2) #(1,2,3,4,1,2,3,4)
L =('Google','Taobao','Runoob')print("{0} , {1} , {2}".format(L[-1],L[1],L[0])) #出力タプルRunoobをフォーマットします, Taobao , Google
# 補足:発電機控除(genexpr)
e =(i for i inrange(10))next(e) # 1next(e) # 2next(e) # 3next(e) # 4next(e) # 5for each in e:print(each, end =" ")
# 補足:実装1+2+3.。。 +100=5050
Sum =sum( i for i inrange(101))print("Sum =",Sum) #5050
##### の結果#####
# 56789
# Sum =5050
Pythonタプルケース
- 予防:*
- タプルの要素は変更できませんが、リストなどの変更可能なオブジェクトを含めることができます。
- 0または1の要素を含むタプル、および空のタプルを作成するための特別な文法規則に注意してください。
- タプル/リスト/文字列はすべてシーケンス(シーケンス)に属し、共通点があります。インデックスごとに要素を取得し(負のインデックスがサポートされています)、範囲内の要素のコレクションはシャーディングによって取得できます。多くの一般的な演算子があります。 リピート演算子、スプライシング演算子、メンバーシップ演算子など
- タプルはリスト内包表記には存在しませんが、ジェネレーター控除genexprには存在します。
4.3.5 セットする #####
セットは、繰り返されない要素の順序付けられていないシーケンスです。サイズの異なる1つまたは複数の全体で構成されます。セットを構成するものまたはオブジェクトは、要素またはメンバーと呼ばれます。基本的な機能は、メンバーシップテストを実行することです。重複する要素を削除します。
形式:中括弧{}またはset()を使用してセットを作成します。たとえば、parame = {value01、value02、…}、set(value);
フォーマット:set1={1,2,3,4,5,6}
set2 =set(1,2,3,4,5,6)
場合:
#! /usr/bin/python3
# coding:utf-8
# 特徴:検証セットコレクション(大文字と小文字を区別)
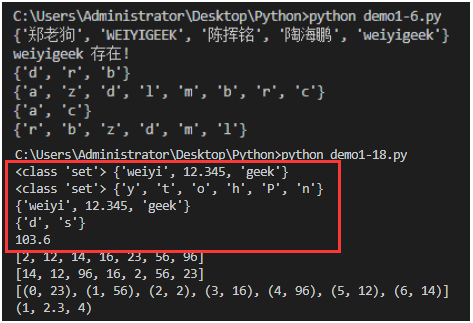
student ={"weiyigeek","WEIYIGEEK","タオハイペン","Zheng Laogou","Chen Huiming",'WEIYIGEEK'}print(student) #出力コレクション(順不同)、繰り返される要素は自動的に削除されます
# 会員テスト
if'weiyigeek'in student:print("weiyigeekが存在します!")else:print("存在しません!")
# setはset操作を実行できます
a =set('abracadabra')
b =set('alacazam')
# 次の操作は、差し引くことができる学習セットの価値があります
print(a - b) #aとbの違い
print(a | b) #aとbの結合
print(a & b) #aとbの交点
print(a ^ b) #同時に存在しないaとbの要素
# 機能:設定
set1 ={'weiyi','geek',12.345}
set2 =set("Python")print(type(set1),set1) #故障中
print(type(set2),set2) #故障中
print(set1 - set2) #リスト内包表記と同様に、同じコレクションがコレクション内包表記をサポートします(Set comprehension) #{'geek','weiyi',12.345}
a ={x for x in'abcasdsadsa'if x not in'abc'} #表示{'d','s'}キャラクター,print(a)コレクションはコレクションの理解をサポートします(Set comprehension)
tuple1 =(1.1,2.2,3.3,ord('a')) #同じタイプである必要があります
print(sum(tuple1)) # 6.6print(sorted([23,56,2,16,96,12,14]))
temp =[23,56,2,16,96,12,14]print(list(reversed(temp)))print(list(enumerate([23,56,2,16,96,12,14])))print((1,2.3,4))
Pythonコレクションの場合
- 予防:*
- リスト内包表記と同様に、同じセットがセット内包表記をサポートします(セット内包表記)
- 空のセットを作成するには、{}を使用して空の辞書を作成するため、{}の代わりにset()を使用する必要があります。
4.3.6 辞書データ(dict)#####
ディクショナリは別の可変コンテナモデルであり、任意のタイプのオブジェクトを格納でき、コレクションのいとこです。ディクショナリとコレクションの違いは次のとおりです。ディクショナリ内の要素は、キーを介してではなく、キーを介してアクセスされます。オフセットアクセス。
ディクショナリはマッピングタイプです。空のディクショナリは{}で識別されます。これは順序付けられていないキーです(キー-一意である必要があり、繰り返すことはできません):値(値-不変タイプを使用)。
コンストラクターdict()を使用して、キーと値のペアのシーケンスから直接辞書を作成します。形式は次のとおりです。
dict(([key,value],[key,value])) #辞書を作成する
dict1 ={'name':"weiyigeek",[key,value]}
場合:
#! /usr/bin/python3
# coding:utf-8
# 特徴:辞書辞書タイプはキーと値です,セットコレクションで使用{}特定する
d ={key1 : value1, key2 : value2 }
d['key1']/**辞書へのアクセス方法*/
d['key1]= value /**辞書の割り当て*/
del d['key1']/**指定した辞書のキー値を削除します*/
del d /**辞書を削除する**/
createdict ={}
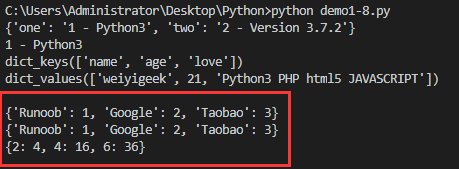
createdict['one']="1 - Python3"
createdict['two']="2 - Version 3.7.2"
tinydict ={'name':"weiyigeek",'age':21,'love':"Python3 PHP html5 JAVASCRIPT"}print(createdict) #出力辞書値/value
print(createdict['one']) #出力キーは'one'の値
print(tinydict.keys()) #すべてのキーを出力
print(tinydict.values(),end="\n\n") #すべての値を出力
# コンストラクタディクト()キーと値のペアのシーケンスから直接辞書を作成できます
cdict1 =dict([('Runoob',1),('Google',2),('Taobao',3)]) #方法1辞書を作成するための反復可能なオブジェクトメソッド
cdict2 =dict(Runoob=1, Google=2, Taobao=3) #方法2着信キーワード
cdict3 =dict((['a',2],['b',3])) #方法3埋め込みリストを渡す
cdict4 =dict(zip(['one','two','three'],[1,2,3])) #方法4マッピング関数による辞書の作成方法
jiecheng ={x: x**2for x in(2,4,6)} ##方法5辞書の理解
print(cdict1)print(cdict2)print(jiecheng)
# 辞書からの派生
>>> x ={i: i %2for i inrange(10)} #これが計算式です
{0:0,1:1,2:0,3:1,4:0,5:1,6:0,7:1,8:0,9:1}>>> y ={i: i %2==0for i inrange(10)} #これが条件式です
{0: True,1: False,2: True,3: False,4: True,5: False,6: True,7: False,8: True,9: False}
Python辞書の場合
- 予防:*
- リストはオブジェクトの順序付けられたコレクションであり、辞書はオブジェクトの順序付けられていないコレクションです(JSONと同様)。
- キーは一意である必要がありますが、値は必須ではありません。値は任意のデータタイプを取ることができますが、キーは不変(文字列、数値、またはタプル)である必要があります。
- 同じキーを2回表示することはできません。作成中に同じキーが2回割り当てられると、後者の値が前の値を上書きします。
- 辞書にも独自の派生物があります
Recommended Posts