Pythonの正規表現学習の小さな例
正規式は、文字列を処理するための強力なツールです。概念として、正規表現はPythonに固有のものではありません。ただし、Pythonの正規式には、実際の使用方法に微妙な違いがあります。
**(1) 1〜100 **の数値に一致します
import re
s ='100' # 1-100以内の任意の数
ret = re.match(r'(100|[1-9]\d{0,1})$',s)print(ret.group())
(100|[1- 9]\ d{0,1})$
100 100 |に一致するか、[1-9]の番号に一致する可能性があり、\ dは番号であり、次の{0,1}は最大で1つの番号に一致するか、番号なしに一致します
[1- 9]\ dは、主に0を除いて、前面に1〜9の任意の番号のみを指定できることを意味します。それ以外の場合、01は許可されず、0は背面に含まれます。
(2) 陸線番号と一致
010- 67132692 、その構築ルールは[3桁] [-] [8桁]です
または
0516- 8978981 、その構築ルールは[4桁] [-] [7桁]です
import re
s ="010-67132692"
ret = re.search(r'^\d{3,4}-\d{7,8}$', s)print(ret.group())
注:print(ret.group(0))も同じ効果があり、pythonはデフォルトで0になり、()なしで取得できます。通常、phpとjsは\ 1で始まります。
(3) 入力したqq番号に一致します(qq一致ルール:長さは5〜10桁で、純粋な番号で構成され、0から始めることはできません。)
import re
s ="1101111123"
ret = re.match(r'[1-9]\d{4,9}$', s)if ret != None:print(ret.group())else:print('一致しませんでした!')
(4) 文字列内のafの数を見つける
import re
s ="asdfjvjadsffvaadfkfasaffdsasdffadsafafsafdadsfaafd"
ret = re.findall(r'(af)', s)print(len(ret))
(5) ルールはスペースに応じて1回以上カットすることです
import re
s ="zhangsan lisi wangwu"
res = re.compile(r'\s+')
ret = res.split(s)print(ret)
効果画像:

**(6) 通常の\ cut **を使用します
import re
s ="c:\abc\a.txt"
res = re.compile(r'\')
ret = res.split(s)print(ret)
効果画像:
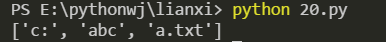
**(7) 5つ以上の連続した番号を#**に置き換えます
import re
s ="wer8934605juo123wa89320571f"
res = re.compile(r'\d{5,}')
ret = res.sub('#', s)print(ret)
効果画像:

(8) 文字列内のすべての文字を取り出します
import re
s ="abDEe23dJfd343dPOddfe4CdD5ccv!23rr"
res = re.compile(r'[a-zA-Z]+')
ret = res.findall(s)print(ret)
効果画像:

(9) 大文字と小文字を区別せずに、文字eで終わる単語を検索します
import re
s ='THREE people at HERE do some THING'
res = re.compile(r'\w+e\b', re.I) #\bは境界です
ret = res.findall(s)print(ret)
効果画像:
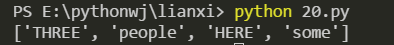
**(10) 複数の繰り返し文字を&**に置き換えます
import re
s ="cudddbhuuujdddcaa"
res = re.compile(r'([a-zA-Z])+')
ret = res.sub('&', s)print(ret)
効果画像:
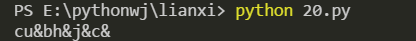
(11) 複数の繰り返される文字を1つの文字に置き換えます(たとえば、dddをdに置き換えます)
import re
s ="cudddbhuuujddd"
res = re.compile(r'([a-zA-Z])+')
ret = res.sub(r'',s)print(ret)
効果画像:

(12) 3文字の長さの単語を取得する
import re
s ="min tian jiu yao fang jia le ,da jia"
ret = re.findall(r'\b\w{3}\b', s)print(ret)
効果画像:
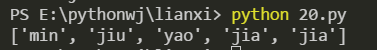
(13) 文字列を「プログラミングを学びたい」に変える
import re
s ="私...私...する必要がある..をしたい...をしたい...学ぶことを学びます...調査...編集..プログラミング..チェン.チェン...チェン...チェン"
res = re.sub(r'\W+','', s)
ret = re.sub(r'(.)+',r'',res)print(ret)
効果画像:
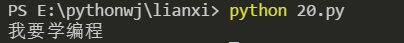
(14) divタグとbタグを削除します
結果:通常import re
s ="<div class='a'レギュラー<スパン式</span <b style='color:red'運動</b </div "
ret = re.sub(r'(</?div.*? |</?b.*? )','',s)print(ret)
効果画像:
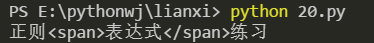
(15) 各行に3つの数字しかない文字列を検索
import re
s ='''121fefe
3 qsqse2
ded6d32
aaaaa1a
1234 adc
'''
ret = re.findall(r'^\D*\d\D*\d\D*\d\D*$', s ,re.M)print(ret)
効果画像:

以下は補足です
一般的に使用されるPythonの定期的な演習をいくつか収集する
# マッチアウト0-99の間の数
print("---マッチアウト0-99の間の数---")
ret = re.match(r"^[1-9]?[0-9]$","77")print(ret.group())
# 8 20桁までのパスワード。小文字、数字、下線を使用できます。
print("---、8〜20桁のパスワード、大小の英字、数字、下線を使用できます---")
ret = re.match("[\w_]{8,20}","1123dasf1")print(ret.group())
# 163の電子メールアドレスと一致し、@helloなどのシンボルの前に4〜20ビットがあります@163.com
print("---163の電子メールアドレスと一致し、@helloなどのシンボルの前に4〜20ビットがあります@163.com---")
ret = re.match("[\w_]{4,20}@163\.com","[email protected]")print(ret.group())print("---b---")
ret = re.match(r".*\b163\b","[email protected]")print(ret.group())
# マッチ1-100の間の数
print("---マッチ1-100の間の数---")
ret = re.match("[1-9]?\d$|100","100")print(ret.group())
# 163、126、qqメールボックスに一致
print("---163、126、qqメールボックスに一致---")
ret = re.match("[\w_]{4,20}@(163|126|qq)\.com","[email protected]")print(ret.group())
# 一致<html hello world</html
print("---一致<html hello world</html ---")
ret = re.match(r"<([a-zA-Z]*) .*</\1 ","<html hello world</html ")print(ret.group())
# 最初:マッチアウト<html <h1 www.itcast.cn</h1 </html
print("---最初:マッチアウト<html <h1 www.qblank.cn</h1 </html ---")
ret = re.match(r"<(\w*) <(\w*) .*</\2 </\1 ","<html <h1 www.itcast.cn</h1 </html ")print(ret.group())
# 二番目:マッチアウト<html <h1 www.qblank.cn</h1 </html
print("---二番目:マッチアウト<html <h1 www.qblank.cn</h1 </html ")
ret = re.match("<(?P<name1 \w*) <(?P<name2 \w*) .*</(?P=name2) </(?P=name1) ","<html <h1 www.qblank.cn</h1 </html ")print(ret.group())
# ******reモジュールの高度な使用法*****
# 検索を使用して、記事の読みの数を一致させます
print("---一致する記事の読み取り数---")
ret = re.search(r"\d+","読み取り数は9999です")print(ret.group())
# python、c、cの統計++対応する章が読み取られた回数
print("---python、c、cの統計++対応する章が読み取られた回数---")
ret = re.findall(r"\d+","python = 2342,c = 7980,java = 9999")print(ret)
# 一致した読み取り値の数に1printを追加します("---一致した読み取り値の数に1を追加します---")
ret = re.sub(r"\d+","999","python = 997")print(ret)
# < div
# < p仕事の責任:</p
# < p推奨アルゴリズム、データ統計、接続、バックグラウンドなどのサーバー側関連タスクを完了します</p
# < p <br </p <p必要な要件:</p <p優れた自己主導型でプロフェッショナルな品質、プロアクティブで結果重視</p
# < p <br </p <p技術要件:</p
# < p 1. 1年以上のPython開発経験、顔指向のオブジェクト分析と設計の習得、および設計パターンの理解</p
# < p 2. MVC、MVVM、および関連するWEB開発フレームワークなどの概念に精通したマスターHTTPプロトコル</p
# < p 3.リレーショナルデータベースの開発と設計をマスターし、SQLをマスターし、MySQLを上手に使用する/PostgreSQLの1つ<br </p
# < p 4. NoSQLとMQを習得し、対応するテクノロジーを使用してソリューションを解決することに習熟している</p
# < p 5.Javascriptに精通している/CSS/HTML5,JQuery、React、Vue.js</p
# < p <br </p <pボーナスアイテム:</p
# < p大規模なデータ、数学的統計、機械学習、sklearn、高性能、高い同時実行性。</p
# < /div
data ="""
< div
< p仕事の責任:</p
< p推奨アルゴリズム、データ統計、接続、バックグラウンドなどのサーバー側関連タスクを完了します</p
< p <br </p <p必要な要件:</p <p優れた自己主導型でプロフェッショナルな品質、プロアクティブで結果重視</p <p <br </p <p技術要件:</p
< p 1. 1年以上のPython開発経験、顔指向のオブジェクト分析と設計の習得、および設計パターンの理解</p
< p 2. MVC、MVVM、および関連するWEB開発フレームワークなどの概念に精通したマスターHTTPプロトコル</p
< p 3.リレーショナルデータベースの開発と設計をマスターし、SQLをマスターし、MySQLを上手に使用する/PostgreSQLの1つ<br </p
< p 4. NoSQLとMQを習得し、対応するテクノロジーを使用してソリューションを解決することに習熟している</p
< p 5.Javascriptに精通している/CSS/HTML5,JQuery、React、Vue.js</p
< p <br </p <pボーナスアイテム:</p
< p大規模なデータ、数学的統計、機械学習、sklearn、高性能、高い同時実行性。</p
< /div
"""
print("---クロール雇用情報URL---")
# 方法1:貪欲モードをオフにする
print("---方法1---")
ret = re.sub(r"<.+? ","",data)print(ret)
# 方法2:print("---方法2---")
ret = re.sub(r"</?\w+ ","",data)print(ret)
# 文字列を切る "情報:xiaoZhang 33 shandong”
print("---文字列を切る "情報:xiaoZhang 33 shandong”---")
ret = re.split(r":|","ストリング情報の切断:xiaoZhang 33 shandong")print(ret)
# This is a number 234-235-22-423
data ="This is a number 234-235-22-423"print("---貪欲で貪欲でない---")
# 貪欲
ret = re.match(".+(\d+-\d+-\d+-\d+)",data)print(ret.group(1))
# 貪欲でない
ret = re.match(".+?(\d+-\d+-\d+-\d+)",data)print(ret.group(1))
# 画像のURLを抽出します
data ="""
< img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
src="https://rpic.douyuc dn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
style="display:inline;""""
print("---画像のURLを抽出します")
ret = re.search(r"https.+?\.jpg",data)print(ret.group())
data ="""
http://www.interoem.com/messageinfo.asp?id=35
http://3995503.com/class/class09/news_show.asp?id=14
http://lib.wzmc.edu.cn/news/onews.asp?id=769
http://www.zy-ls.com/alfx.asp?newsid=377&id=6
http://www.fincm.com/newslist.asp?id=415"""
# 接尾辞を削除します
print("---接尾辞を削除します---")
ret = re.sub(r"(http://.+?/).*", lambda x: x.group(1),data)print(ret)
# すべての単語を検索
data ="hello world ha ha"print("---すべての単語を検索---")print("--方法1--")
ret = re.split(r" +",data)print(ret)print("--方法2--")
ret = re.findall(r"\b[a-zA-Z]+\b",data)print(ret)
これまで、Pythonの正規式学習の小さな例に関するこの記事を紹介しました。より関連性の高いPythonの正規式学習の例については、ZaLou.Cnの以前の記事を検索するか、以下の関連記事を引き続き参照してください。 Cn!
Recommended Posts