python_クローラーの基本的な学習
-王玉陽—moocコースの概要に基づいてメモを取ります(Code_boy)
リクエストライブラリ:HTMLページへの自動クロール、ネットワークリクエストの自動送信
robots.txt:Webクローラーの除外基準
美しいスープライブラリ:HTMLページを解析します(pycharmにbs4をインストールします)
再正規表現:HTMLデータ分析の選択
requests.get(url[,params = None,**kwargs])
url:ウェブページのURLリンクを取得します
params:url、辞書、またはバイトストリーム形式の追加パラメーター、オプション
**kwargs:アクセスを制御する12のパラメーター
Responseオブジェクトのプロパティ{0.0.py}
| プロパティ | 説明 |
|---|---|
| r.status_code | HTTPリクエストのステータスを返します。200は接続が成功したことを意味し、404は失敗を意味します |
| r.text | HTTP応答コンテンツの文字列形式(つまり、URLに対応するページコンテンツ) |
| r.encoding | HTTPヘッダーから推測される応答コンテンツのエンコード方法 |
| r.apparent_encoding | コンテンツから分析された応答コンテンツのエンコード方法(代替エンコード方法) |
| r.content | HTTP応答コンテンツのバイナリ形式 |
例:
1 r = requests.get("http://www.baidu.com")2print(r.status_code) #ステータスコードを返します(コンテンツ値は「200」で、アクセスが成功したことを示します)
3 # 結果:2004print(r.text) #応答コンテンツの文字列形式を返します
5 # 結果:[すなわち-baiduホームページのソースコードコンテンツ(文字化け)]
6 print(r.encoding) #HTTPヘッダーから推測される応答コンテンツのエンコード方法
7 # 結果:ISO-8859-1 baiduページのコーディング基準(方法)
8 print(r.apparent_encoding) #コンテンツから分析された応答コンテンツのコーディング方法[代替エンコーディング]9 #結果:utf-810print(r.content) #コンテンツのバイナリ形式
11 # 結果:とにかくわかりません
1213 r.encoding ='utf-8' #(utf-8はrです.apparent_エンコード結果)14print(r.text)15 #結果として、人間が読める応答コンテンツは主にrを介して行われます.エンコーディングの再定義タイプ、およびr.テキストは、エンコードのエンコード方法を指します
一般的なクローラーコードフレームワーク:
1 def getHTMLText(url):2try:3 r = requests.get(url,timeout =30)4 r.raise_for_status() #ステータスが200でない場合、例外がスローされます:リクエスト.HTTPError(r.status_code)5 r.encoding = r.apparent_encoding
6 return r.text
7 except:8return"例外を生成します"910if __name__ =="__main__":11 url ='http://www.baidu.com'12print(getHTMLText(url))
ライブラリの例外を要求します
| 例外 | 説明 |
|---|---|
| requests.ConnectionError | ネットワーク接続エラーの例外(DNSクエリの失敗、接続の拒否など) |
| requests.HTTPError | HTTPエラー例外 |
| requests.URLequired | URLに例外がありません |
| requests.TooManyRedirects | リダイレクトの最大数を超えたため、リダイレクト例外が発生しました |
| requests.ConnectTimeout | リモートサーバーへの接続がタイムアウトした例外 |
| requests.Timeeout | リクエストURLタイムアウト、タイムアウト例外が発生しました |
| r.raise_for_status | 200でない場合、例外が発生します:requetst.HTTPError |
一般的なコードフレームワークの例:
1 def getHTMLText(url):2try:3 r = requests.get(url,timeout =30)4 r.raise_for_status() #ステータスが200でない場合、例外がスローされます:リクエスト.HTTPError(r.status_code)5 r.encoding = r.apparent_encoding
6 return r.text
7 except:8return"例外を生成します"910if __name__ =="__main__":11 url ='http://www.baidu.com'12print(getHTMLText(url))
Requestsライブラリの7つの主なメソッド
| 方法 | 説明 |
|---|---|
| requests.request() | 次のメソッドの基本メソッドをサポートするリクエストを作成します |
| requests.get() | HTTPGETに対応するHTMLWebページを取得する唯一の方法 |
| requests.head() | HTTPHEADに対応するHTMLページヘッダー情報を取得するメソッド |
| requests.post() | HTTPPOSTに対応するPOSTリクエストをHTMLページに送信するメソッド |
| requests.put() | HTTPPUTに対応するHTMLページにPUTリクエストを送信するメソッド |
| requests.patch() | HTTPのPATCHに対応するHTMLページに部分的な変更要求を送信します |
| requests.delete() | HTTPDELETEに対応する削除リクエストをHTMLページに送信します |
HTTPプロトコル:
HTTP、ハイパーテキスト転送プロトコル、ハイパーテキスト転送プロトコル
HTTPは、「要求と応答」モデルに基づくステートレスアプリケーション層プロトコルです。
HTTPはURLを使用してネットワークリソースIDを検索します
URL形式:http:// host [:port] [path]
ホスト:正当なインターネットホストドメイン名またはIPアドレス
ポート:ポート番号(デフォルトのポートは80)
パス:要求されたリソースのパス
リソースに対するHTTPプロトコル操作:
| 方法 | 説明 |
|---|---|
| GET | URLの場所でリソースを取得するためのリクエスト |
| HEAD | URLロケーションリソースの応答情報レポートを取得するように要求します。つまり、リソースのヘッダー情報を取得します |
| POST | URLの場所にあるリソースに新しいデータを追加するように要求する |
| PUT | 元のURLの場所にあるリソースを上書きして、URLの場所にリソースを保存するように要求します |
| PATCH | URLの場所でリソースの部分的な更新を要求します。つまり、リソースのコンテンツの一部を変更します |
| DELETE | URLの場所に保存されているリソースの削除要求 |
PATCHとPUTの違いを理解する
URLの場所に、UserIDやUserNameなどの20個のフィールドを含む一連のデータUserInfoがあるとします。
要件:ユーザーが変更したユーザー名、その他は変更されません
-
PATCHを使用して、UserNameの部分的な更新要求のみをURLに送信します[追加]
-
PUTでは、20個のフィールドすべてを一緒にURLに送信する必要があり、送信されていないフィールドは削除されます[上書きおよび追加]
1 # リクエストライブラリの責任者()メソッド(URLロケーションリソースの応答情報レポートを取得する要求、つまり、リソースのヘッダー情報を取得する要求)2 r = requests.head('http://httpbin.org/get')3print(r.headers)4'''
5 結果:
6{' Connection':'keep-alive','Server':'gunicorn/19.9.0',7'Date':'Thu, 22 Nov 2018 03:52:22 GMT','Content-Type':8'application/json','Content-Length':'268',9'Access-Control-Allow-Origin':'*',10'Access-Control-Allow-Credentials':'true','Via':'1.1 vegur'}11'''
12 # ライブラリの投稿をリクエスト()メソッド(URLの場所にあるリソースに新しいデータを追加する要求)
13 payload ={'key1':'value1','key2':'value2'}14 r = requests.post('http://httpbin.org/post',data = payload)15 #辞書をURLにPOSTし、unform(フォーム)を自動的にエンコードします
16 print(r.text)17'''
18 結果:
19{20" args":{},21"data":"",22"files":{},23"form":{24"key1":"value1",25"key2":"value2"26},27"headers":{28"Accept":"*/*",29"Accept-Encoding":"gzip, deflate",30"Connection":"close",31"Content-Length":"23",32"Content-Type":"application/x-www-form-urlencoded",33"Host":"httpbin.org",34"User-Agent":"python-requests/2.20.1"35},36"json":null,37"origin":"106.111.147.213",38"url":"http://httpbin.org/post"39}40'''
41 r = requests.post('http://httpbin.org/post',data ='abc')42 #データとして自動的にエンコードされたURLに文字列をPOSTします
43 print(r.text)44'''
45 結果:
46{47" args":{},48"data":"abc",49"files":{},50"form":{},51"headers":{52"Accept":"*/*",53"Accept-Encoding":"gzip, deflate",54"Connection":"close",55"Content-Length":"3",56"Host":"httpbin.org",57"User-Agent":"python-requests/2.20.1"58},59"json":null,60"origin":"106.111.147.213",61"url":"http://httpbin.org/post"62}63'''
64 # リクエストライブラリのプット()メソッド(リソースをURLの場所に保存し、元のURLの場所でリソースを上書きするように要求する)
65 payload ={'key1':'value1','key2':'value2'}66 r = requests.put('http://httpbin.org/put',data = payload)67 #辞書をURLに入れて、unform(フォーム)を自動的にエンコードします[投稿との違いは、元のコンテンツが上書きされることです]68print(r.text)69'''
70 結果:71{72"args":{},73"data":"",74"files":{},75"form":{76"key1":"value1",77"key2":"value2"78},79"headers":{80"Accept":"*/*",81"Accept-Encoding":"gzip, deflate",82"Connection":"close",83"Content-Length":"23",84"Content-Type":"application/x-www-form-urlencoded",85"Host":"httpbin.org",86"User-Agent":"python-requests/2.20.1"87},88"json":null,89"origin":"106.111.147.213",90"url":"http://httpbin.org/put"91}92'''
メソッド関数とリクエストライブラリの使用:
requests.request(method,url,**kwargs)
メソッド:リクエストメソッド、get / put / postなどの7つのメソッドに対応
r = requests.request(‘GET’,url,**kwargs)
r = requests.request(‘HEAD,’url,**kwargs)
r = requests.request(‘POST’,url,**kwargs)
r = requests.request(‘PUT’,url,**kwargs)
r = requests.request(‘PATCH’,url,**kwargs)
r = requests.request(‘delete’,url,**kwargs)
r = requests.request( 'OPTIONS'、url、** kwargs)#サービスから関連するパラメーターを取得する
url:取得するページのurlリンク
**kwargs:アクセスを制御するためのパラメーター、合計13(オプション)
params:辞書またはバイトシーケンス。パラメータとしてURLに追加されます(リンクパーツシステムは '?' を追加します)
データ:リクエストの内容としての辞書、バイトシーケンス、またはファイルオブジェクト
json:リクエストのコンテンツとしてのjson形式のデータ
ヘッダー:辞書、HTTPカスタムヘッダー
クッキー:辞書またはCookieJar、リクエスト内のクッキー*
auth:tuple、HTTP認証機能をサポート*
ファイル:辞書タイプ、転送ファイル
タイムアウト:タイムアウト時間を設定します。単位:秒(時間が返されると、例外が返されます)
プロキシ:辞書タイプ、アクセスプロキシサーバーの設定、ログイン認証を増やすことができます
pxs={'http':'http://user:[email protected]:1234'}
r = requests.request('GET','http://www.baidu.com',proxies = pxs)
allow_redirects:True / False、デフォルトはTrue、リダイレクトスイッチ
ストリーム:True / False、デフォルトはTrue、コンテンツはすぐにダウンロードされます
検証:SSL証明書スイッチを検証するためのTrue / False、デフォルトはTrue
cert:ローカルSSL証明書パス
*requests.get(url,params=None,kwargs)
url:ページのURLリンク
params:url、辞書、またはバイトストリーム形式の追加パラメーター、オプション
**kwargs:アクセスを制御する12のパラメーター
**requests.head(url,kwargs)
url:ページのURLリンク
**kwargs:アクセスを制御するための13のパラメーター
**requests.post(url,data=None,json=None,kwargs)
url:ページのURLリンク
データ:辞書、バイトシーケンスまたはファイル、リクエストの内容
json:JSON形式のデータ、リクエストの内容
**kwargs:11の制御アクセスパラメータ(dataとjsonが使用されています)
**requests.put(url,data=None,kwargs)
url:ページのURLリンク
データ:辞書、バイトシーケンスまたはファイル、リクエストの内容
**kwargs:アクセスを制御する12のパラメーター
**requests.patch(url,data=None,kwargs)
url:ページのURLリンク
データ:辞書、バイトシーケンスまたはファイル、リクエストの内容
**kwargs:アクセスを制御する12のパラメーター
**requests.delete(url,kwargs)
url:ページのurlリンクを削除します
**kwargs:アクセスを制御するための13のパラメーター
Webクローラーのサイズ:
| スタイル | ウェブページをクロール、楽しいウェブページ | ウェブサイトをクロール、一連のウェブサイトをクロール | ネットワーク全体をクロール |
|---|---|---|---|
| スケール | 小規模、データ量が少ない、クロール速度に影響されない(> = 90%) | 中規模、データスケールが大きい、クロール速度に影響される | 大規模、検索エンジン、クロール速度が重要 |
| 共通ライブラリ | リクエストライブラリ | スクレイピーライブラリ | カスタム開発 |
Webクローラーによる嫌がらせ:
クローラーは高速機能を使用してWebサーバーにアクセスし、サーバーが高速クローラーに適したリソースを提供することは困難です。
レベルを書く目的に限定して、WebクローラーはWebサーバーに莫大なリソースオーバーヘッドをもたらします
Webクローラーの法的リスク:
サーバー上のデータにはプロパティの所有権があります
Webクローラーによって取得されたデータが法的リスクをもたらす後の利益
Webクローラー== "クロールにも正しい方法があります"
クローラーの条件を制限します。
ソースレビュー:制限するユーザーエージェントの判断
・訪問しているHTTPプロトコルヘッダーのUser-Agentドメインを確認し、ブラウザーまたはフレンドリクローラーの訪問にのみ応答します。
発表:ロボット協定*****
ロボット除外基準Webクローラー除外基準
役割:すべてのクローラーにWebサイトのクロール戦略を通知し、クローラーに準拠するように要求します
形式:Webサイトのルートディレクトリにあるrobots.txtファイル
JDロボット契約:(https://www.jd.com/robots.txt)
| User-agent:* Disallow:/?* Disallow:/ pop / *。html Disallow:/ pinpai / 。html? User-agent:EtaoSpider Disallow:/ User-agent:HuihuiSpider Disallow:/ User-agent:GwdangSpider Disallow :/ユーザーエージェント:WochachaSpider不許可:/ | クローラーはアクセスを許可しないように従う必要がありますか?最初のパスは/pop/.htmlへのアクセスを許可されていません/pinpai/.htmlへのアクセスは許可されていませんか?* EtaoSpider、HuihuiSpider、GwdangSpider、WochachaSpiderは悪意のあるクローラーとして識別され、コンテンツのクロールは禁止されています |
|---|
Robotsプロトコルの基本構文:
| # | 注意事項 |
|---|---|
| * | すべてを表します |
| / | ルートディレクトリを表します |
| ユーザーエージェント:* | クローラーを指定します(*はすべてのクローラーを意味します) |
| 許可しない:/ | ディレクトリはクローラーに許可されていません |
クローラーの基本的な1つの例:(コード+要約){0.1.py}
1 # 例:Jingdong商品のクロール
2 import requests
3 import os
4'''
5 r = requests.get('https://item.jd.com/36826348085.html?jd_pop=14982c1c-64d9-4bab-ac5c-e40af7ce62a2&abt=0')6print(r.status_code)7print(r.encoding)8print(r.text[:1000])9 #例:Amazonのクロール
1011 kv ={'User-Agent':'mozilla/5.0'} #アクセスヘッダーを作成します(ブラウザーのふりをします)
12 r=requests.get('https://www.amazon.cn/dp/B073LJR2JF/ref=cngwdyfloorv2_recs_0/459-8865541-1481366?pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=desktop-2&pf_rd_r=AT12APC0BDJ216Y55VSR&pf_rd_r=AT12APC0BDJ216Y55VSR&pf_rd_t=36701&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_i=desktop',headers=kv)13print(r.status_code)14print(r.text[:1000])15print(r.request.headers)16'''
17 # 例:Baidu検索
18 # Baidu検索検索URL:http://www.baidu.com/s?wd:{コンテンツを検索}19'''
20 keyword ='python'21try:22 kv ={'wd':keyword}23 r = requests.get('http://www.baidu.com/s',params = kv)24print(r.request.url)25 r.raise_for_status()26print(len(r.text))27 except:28print("クロールに失敗しました")29'''
30 # ケース:Webイメージのクロールとストレージ
31'''
32 url ="http://img0.dili360.com/pic/2018/09/21/5ba4a6af2af103q29157813_t.jpg"33 rot ="E://"34 path = rot + url.split('/')[-1] #urlアドレス(url)のサフィックスとして画像保存名を指定します
35 try:36if not os.path.exists(rot): #rotディレクトリがあるかどうかを確認し、ない場合は作成します
37 os.mkdir(rot) #腐敗ディレクトリを作成します
38 if not os.path.exists(path): #パスディレクトリにパスファイルがあるかどうかを確認します
39 r = requests.get(url) #リンクURLアドレス
40 # withopen(path,'wb')as f: #ファイルを開いて保存する別の方法(???)41 f =open(path,'wb') #ファイルを開く
42 f.write(r.content) #r.content応答URLのバイナリコンテンツ
43 f.close()44print("正常に保存")45else:46print("ファイルが既に存在します")47 except:48print("クロールに失敗しました")49'''
50 # 1つのビデオをクロールする
51'''
52 url ="http://video.pearvideo.com/mp4/adshort/20181121/cont-1480150-13269168_adpkg-ad_hd.mp4"53 rot ="E://"54 path = rot + url.split('/')[-1] #urlアドレスにビデオ保存名(url)のサフィックス名を指定します
55 try:56if not os.path.exists(rot): #rotディレクトリがあるかどうかを確認し、ない場合は作成します
57 os.mkdir(rot) #腐敗ディレクトリを作成します
58 if not os.path.exists(path): #パスディレクトリにパスファイルがあるかどうかを確認します
59 r = requests.get(url) #リンクURLアドレス
60 # withopen(path,'wb')as f: #ファイルを開いて保存する別の方法(???)61 f =open(path,'wb') #ファイルを開く
62 f.write(r.content) #r.content応答URLのバイナリコンテンツ
63 f.close()64print("正常に保存")65else:66print("ファイルが既に存在します")67 except:68print("クロールに失敗しました")69'''
70 # IPアドレス属性の自動クエリ
71 # IP168クエリリンクURL:http://ip138.com/ips138.asp?ip=123.125.6.1&action=272 #上記から:IPクエリURL:http://ip138.com/ips138.asp?ip=IPアドレス
7374 url ="http://ip138.com/ips138.asp"75 ip ={"ip":"106.111.147.213"}76try:77 r = requests.get(url,params=ip)78 r.raise_for_status()79print(r)80 #print(r.status_code)81 r.encoding = r.apparent_encoding
82 print(r.text)83 except:84print("クロールに失敗しました")
簡単な要約:
例から、検索を容易にするためにurlインターフェイスをマスターする必要があることがわかります(検索して使用します):params()関数は、URLの後に新しいコンテンツを追加するために中央で使用されます。関数が呼び出されると、urlは両方になりますジャンクションに「?」記号を追加します
Webクロールに関しては、r.text []形式の外観も確認されています。これは、Webページのソースコードの文字数をクロールする必要があることを意味します。
この例では、写真やビデオのクロールを見て、バイナリ形式で保存しました。
美しいスープライブラリ :( pycharmにbs4をインストール){0.2 bs.py}
ライブラリの使用:
1 form bs4 import BeautifulSoup
23 soup =BeautifulSoup( ‘ <p>data</p> ‘ , ‘ html.parser ‘ )
Beautiful Soupライブラリの理解:「タグツリー」を解析、トラバース、および維持するための機能ライブラリ
- BeautifulSoup4またはbs4とも呼ばれるBeautifulSoupライブラリ
現在一般的に使用されている引用方法:bs4重要なtBeautifulスープ用
美しいスープクラス<<<同等>>>タグツリー<<<同等>>> HTML <>
同等性が形成されるため、タグツリーはBeautifulSoupクラスを通じて変数を形成します。
簡単な例え:BeautifulSoupはHTML / XMLドキュメントのコンテンツ全体に対応します
美しいスープライブラリパーサー:
| パーサー | 使用方法 | 条件 |
|---|---|---|
| bs4 HTMLパーサー | BeautifulSoup(mk、 'html.parser') | bs4ライブラリをインストール |
| lxmlのHTMLパーサー | BeautifulSoup(mk、 'lxml') | pip install lxml |
| lxmlのXMLパーサー | BeautifulSoup(mk、 'xml') | pip install lxml |
| html5libのパーサー | BeautifulSoup(mk、 'html5lib') | pip install html5lib |
美しいスープライブラリの基本要素:
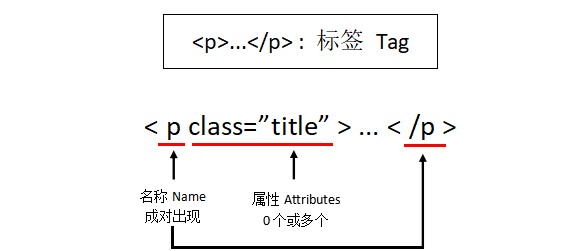
| 基本要素 | 説明 |
|---|---|
| 最も基本的な情報編成単位であるTag | tagは、<>と</>始まりと終わりをマークする |
| 名前 | ラベルの名前、 ..。 名前は「p」、形式: |
| 属性 | タグ属性、辞書形式、形式で編成: |
| NavigableString | タグ内の属性以外の文字列、<> .. ..</>中程度の文字列、形式: |
| コメント | タグ内の文字列のコメント部分、特別なコメントタイプ |
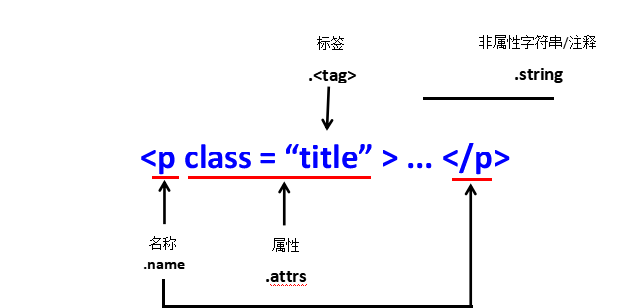
美しいスープライブラリ関数:(表内
| 機能 | 説明 | 備考 |
|---|---|---|
| スープ。 |
解析されたWebページでタグを取得します | t = soup。 |
| [ スープ。 |
Get |
|
| [ スープ。 |
Get |
これは上向きに推測できます |
| [ スープ。 |
Get |
|
| [ スープ。 |
取得 |
コード例(+説明)
1 r = requests.get('http://python123.io/ws/demo.html')2print(r.text)3 demo = r.text #demo ==urlウェブページコード
4 soup =BeautifulSoup(demo,'html.parser')5print(soup.prettify())6 r = requests.get('http://python123.io/ws/demo.html')7 demo = r.text
8 soup =BeautifulSoup(demo,"html.parser")9print(soup.title) #タイトルタグを探す
10 print(soup.a.string) #タグの文字列の内容を印刷します
11 print(soup.a.name) #ラベルの名前を印刷する
12 print(soup.a.parent.name) #ラベルaの親ラベル(上部ラベル)を印刷します
13 print(soup.a.parent.parent.name) #ラベルaの親ラベルの上部ラベルを印刷します
14 tag = soup.a #soup:ラベルを見つける
15 print(soup.a.attrs) #ラベル属性を印刷する
16 print(tag.attrs['class']) #ラベル属性に「クラス」の内容を出力します
17 print(tag.attrs['href']) #ラベルプロパティの「href」の内容を出力します
18 print(tag) #タグの内容を印刷する
HTMLトラバーサル:
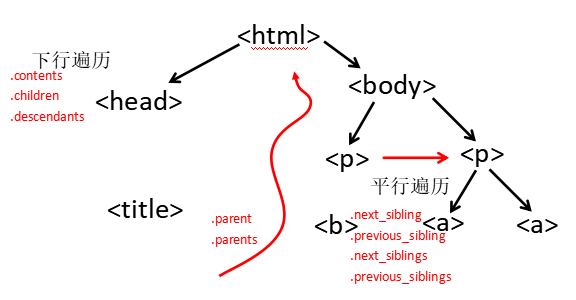
下向きのトラバーサル:
| プロパティ | 説明 |
|---|---|
| . 内容 | 子ノードのリスト、 |
| . children | .contentsと同様に、子ノードをループするために使用される子ノードの反復タイプ |
| . 子孫 | ループトラバーサルに使用される、すべての子孫を含む子孫の反復タイプ |
| 1 r = requests.get( 'http://python123.io/ws/demo.html')2 demo = r.text #demo == url web code 3 soup = BeautifulSoup(demo、 'html.parser')4 print (soup.head)#ヘッドタグを取得します5 print(soup.head.contents)#戻りフォームはリストであり、リストフォームはヘッドを取得します6 print(soup.body.contents)#ボディタグの息子ノードを取得します(戻りフォームはリストです) )7 print(len(soup.body.contents))#lenを使用してbodyタグのノードの総数をテストします8 print(soup.body.contents [1])#list form return、listを使用してノードの1つを表示します9 #traverse soup.body.children:11の子の息子ノード10 print(child)12#soup.body.descendants:14の子の子孫ノード13をトラバースしますprint(child) |
上向きのトラバーサル:
| プロパティ | 説明 |
|---|---|
| . 親 | ノードの親タグ |
| . 親 | 祖先ノードをループするために使用される、ノードの祖先ラベルの反復タイプ |
| 1 r = requests.get( 'http://python123.io/ws/demo.html')2 demo = r.text #demo == url web code 3 soup = BeautifulSoup(demo、 'html.parser')4 print (soup.title.parent)#titleタグノードの親>>>ラベル5#soup.a.parents内の親のアップストリームトラバーサル6:#親がNoneの場合はラベル7から親を上にトラバースします:8 print(parent)#祖先がNoneの場合は、9を実行しますelse:10 print(parent.name)#祖先のラベル名を印刷する |
並列トラバーサル:
| プロパティ | 説明 |
|---|---|
| . next_sibling | HTMLテキストの順序で次の並列ノードラベルを返します |
| . previous_sibling | HTMLテキストの順序で前の並列ノードラベルに戻ります |
| . next_siblings | 反復タイプ、後続のすべての並列ノードラベルをHTMLテキスト順に返します |
| . previous_siblings | 反復タイプ、後続のすべての並列ノードラベルをHTMLテキスト順に返します |
| 1 r = requests.get( 'http://python123.io/ws/demo.html')2 demo = r.text #demo == url web code 3 soup = BeautifulSoup(demo、 'html.parser')4 print (soup.a.next_sibling)#aの次の並列ノードは文字列>>> 'および' 5 print(soup.a.next_sibling.next_sibling)#aの次の並列ラベルは次の並列ラベル6 print(soup .a.previous_sibling)#aの以前の並列ラベル7 print(soup.a.previous_sibling.previous_sibling)#>>>なし(空信息)8#後続の並列ノードをトラバースします:9スープの兄弟用.a.next_siblings:10 print(sibling)11 #Traverse pre-order parallel node:12 for sibling in soup.a.previous_siblings:13 print(sibling) |
bs4ライブラリに基づくHTML形式の出力:
prettify()関数:ラベルの印刷(HTML形式での印刷)
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup.a.prettify()) #タグを出力する(HTML形式)
5'''
6< a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">7 Basic Python
8< /a>9'''
10 soup =BeautifulSoup('<p>中国語</p>','html.parser')11print(soup.p.string) #に[入手します<tag>属性のない文字列/コメント]出力ラベル
12'''
13 中国語
14'''
15 print(soup.p.prettify()) #タグをHTML形式で出力する
16'''
17< p>18中国語
19< /p>20'''
情報の整理と抽出:{0.3.py}
情報マーク:
マークされた情報は、情報組織構造を形成し、情報の次元を増やすことができます
マークされた情報は通信に使用できます
保存または表示
マークの構造は情報と同じくらい重要です
マークされた情報は、プログラムの理解と適用をより助長します
HTML情報マーク:
HTML(Hyper Text Markup Language):Hypertext Markup Language;これは、ハイパーテキストを使用して音声、画像、およびビデオをテキストに埋め込むためのWWW(World Wide Web)の情報編成方法です。
HTMLは事前定義された<> ..を渡します</>さまざまな種類の情報をタブで整理する
情報マークの3つの形式:(XML \ JSON \ YAML)
XML(eXtensible Markup Language):Extensible Markup Language(HTMLに基づく)
JSON(JavsScript Object Notation):型付きキーと値のペア(キー:値)式
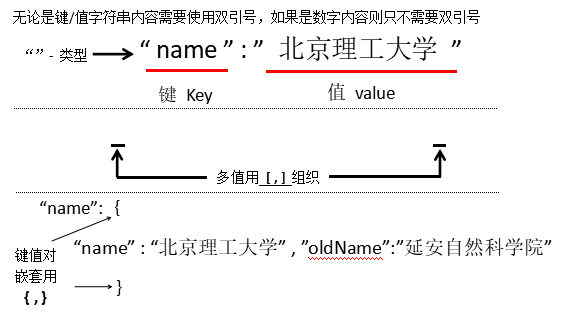
YAML(YAMLはマークアップ言語ではありません):再帰的な定義;型指定されていないキーと値のペアキー:値

3つの情報マーキング方法の比較:(例)
| XMLの例 | |
|---|---|
| < 人> |
例から、有効な情報テキストの割合が高くなく、ほとんどの情報がタグで占められていることがわかります |
| JSONの例 | |
|---|---|
| { "FirstName": "Tian"、 "lastName": "Song"、 "addresses":{"streetAddr": "Zhongguancun South Street 5"、 "city": "Beijing"、 "zipcode": "100081"} "Prof":["Computer System"、 "Security"]} | JSONは、キーと値のペアを介して関連するキーを定義します |
| YAMLの例(YAMLは簡潔で明確です) | |
| firstName:Tiam lastName:Song address:streetAddr:5 Zhongguancun South Street city:Beijing zipcode:100081 prof:-Computer System -security |
| インフォメーションマーク | 比較 | アプリケーション |
|---|---|---|
| XML | 最も初期の一般情報マークアップ言語、拡張可能ですが面倒です | インターネット上での情報の相互作用と送信 |
| JSON | 情報には、プログラム処理(js)に適したタイプがあり、XMLよりも簡潔です | モバイルアプリケーションクラウドとノード情報の相互作用、コメントなし |
| YAML | 情報の種類がなく、テキスト情報の割合が最も高く、読みやすさ | さまざまなシステムの構成ファイル、コメントで読みやすい |
情報抽出の一般的な方法:
方法1:マークされた形式の情報を完全に分析してから、重要な情報を抽出します。
XML JSON YAML_には、タグパーサーが必要です。例:bs4ライブラリのタグツリートラバーサル
利点:正確な情報分析
短所:抽出プロセスは面倒で時間がかかります
方法2:マークアップフォームを無視して、重要な情報を直接検索します。
テキスト検索機能で情報を検索する
利点:抽出プロセスはシンプルで高速です
短所:抽出結果の精度は情報の内容に関連しています(不足)
融合方法:フォーム分析と検索方法を組み合わせて重要な情報を抽出します
XML JSON YAML +検索>>>マークアップパーサーとテキスト検索機能が必要
例:
1 import requests
2 from bs4 import BeautifulSoup
3'''# HTMLですべてのURLリンクを抽出します
41、 すべて検索<a>タグ(タグの内容はURLです)
52、 解析<a>タグ形式、hrefが抽出された後のリンクコンテンツ
6'''
789 r = requests.get('http://python123.io/ws/demo.html')10 demo = r.text
11 soup =BeautifulSoup(demo,'html.parser')12for link in soup.find_all('a'): #デモで見つける<a>ラベル
13 print(link.get('href')) #に<a>タグで「href」関数を見つけます
141516'''
17 結果:18 http://www.icourse163.org/course/BIT-26800119 http://www.icourse163.org/course/BIT-100187000120'''
美しいスープライブラリメソッド:
**bs4.element.Tag:タグタイプ; **
| メソッド | <>。find_all(name、attrs、recursive、string、** kwargs) |
|---|---|
| 説明 | スープの変数で情報を見つけることができます |
| パラメータ | 検索結果を格納するリストタイプを返します。パラメータの説明は、名前の検索文字列をラベルの名前にプロモートします。複数のコンテンツを検索する場合は、listメソッドattrsを使用してラベル属性値を検索できます。属性インデックスを再帰的にマークできるかどうかすべての子孫を取得します(デフォルトはTrue)Falseは文字列<> ..のみを取得します。</>文字列領域内の検索文字列string = '....' |
| パラメータ | 説明 |
| name | ラベル名の検索文字列 |
| attrs | ラベル属性値の文字列の取得 |
| recursive | すべての子孫を検索するかどうか(デフォルトはTrue) |
| 文字列 | <>..。</> |
| 短い検索 | |
| 拡張メソッド | メソッドの説明<>。find()は1つの結果のみを検索して返します、文字列(文字列)タイプ、<>。find_parents()は祖先ノードで検索し、リストタイプを返します<>。find_parent()は祖先ノードでノードを返す、文字列タイプ、<>。find_next_siblings()は後続の並列ノードで検索、リストタイプを返す、<>。find_next_sibling()は後続の並列ノードで結果を返す、文字列タイプ<>。find_previous_siblings()最初並列ノードの順序で検索し、リストタイプを返します。<>。find_previous_sibling()は、前の順序の並列ノードで結果を返します。文字列タイプ |
| 方法 | 説明 |
| <>. find() | 検索して1つの結果、文字列タイプのみを返します |
| <>. find_parents() | 祖先ノードを検索し、リストタイプを返します |
| <>. find_parent() | 祖先ノードのノードを文字列タイプで返します |
| <>. find_next_siblings() | 後続の並列ノードで検索し、リストタイプを返します |
| <>. find_next_sibling() | 後続の並列ノードに結果を返します。文字列タイプ |
| <>. find_previous_siblings() | 前の並列ノードを検索し、リストタイプを返します |
| <>. find_previous_sibling() | 前の並列ノードの結果を返します。文字列タイプ |
名前インスタンス:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,"html.parser")4print(soup.find_all('a')) #リストフォームは、スープ(テキスト)でラベル文字列を返します(ラベルを取得します)
5 print(soup.find_all(['a','b']))6for tag in soup.find_all(True): #スープのすべてのラベルをトラバースします
7 print(tag.name) #すべてのラベルの名前を印刷(取得)してください! !
8'''
9[< a class="py1" href="http://www.icourse163.org/course/BIT-268001"10 id="link1">Basic Python</a>,<a class="py2" href="http://www.icourse163.org
11 /course/BIT-1001870001" id="link2">Advanced Python</a>]12[<b>The demo python introduces several python courses.</b>,<a class="py1"13 href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic
14 Python</a>,<a class="py2" href="http://www.icourse163.org/course/15 BIT-1001870001" id="link2">Advanced Python</a>]16 html
17 head
18 title
19 body
20 p
21 b
22 p
23 a
24 a
25'''# 結果
属性の例:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup.find_all('p','course')) #コース属性を持つPタグを返します
5 print(soup.find_all(id='link1')) #ID属性を返す==link1の内容
67 ‘’’
89[< p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:1011<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]1213[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]1415 ‘’’
再帰インスタンス:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup.find_all('a')) #タグを取得する
5 print(soup.find_all('a',recursive=False))#空のリストを返します。これは、aの下位ノードにラベルがないことを示します(Falseでは1つのレイヤー(sonレイヤー)のみが取得されます)
文字列インスタンス:
1 r = requests.get('http://python123.io/ws/demo.html')2 demo = r.text
3 soup =BeautifulSoup(demo,'html.parser')4print(soup) #パーサーによって解析された完全なHTMLコードを出力します
5 print(soup.find_all(string ='Basic Python')) #リストは取得した文字列情報を返します
中国の大学ランキング{0.4bs.py}の方向性クローラーの事例
1 import requests
2 import bs4
3 from bs4 import BeautifulSoup
4 # soup =BeautifulSoup(demo,'html.parser')5 def getHTML(url):#標準フレームワーク
6 try:7 r = requests.get(url)8 r.raise_for_status()9 r.encoding = r.apparent_encoding
10 return(r.text)11 except:12print("リンクのクロールに失敗しました")1314 def uitHTML(ulist,demo):15 soup =BeautifulSoup(demo,'html.parser')16for tr in soup.find('tbody').children:1718 #.find(..)検索タグの結果が返されました.子供たちは同時に息子(下層)ノードを横断します
19 ifisinstance(tr,bs4.element.Tag):2021 #trのタイプを検出します。タグタイプでない場合は、フィルター(文字列コンテンツへのトラバースを回避するため)がインスタンスであり、変数タイプを判別します。
22 tds =tr('td') #trに相当.find(...)>>>tdタグを見つけます(返されるオブジェクトはリストです)
23 # print(tds) #テストと使用:tdsコンテンツの表示
24 # tdsは、urlのHTML内のtr内のすべてのtdタグのHTML形式を取得するようになりました(リスト形式で返されます)
25 ulist.append([tds[0].string, tds[1].string, tds[3].string])26 #tdsで必要なデータ(抽出のみ.string>>文字列領域)ulistリストに保存
2728 def uitUlist(ulist,num):29print("{:^16}\t{:^16}\t{:^16}".format("ランク","学校名","総得点"))30for i inrange(num):31 u = ulist[i]32print("{:^16}\t{:^16}\t{:^16}".format(u[0],u[1],u[2]))3334 def main():35 ulist =[]36 url ="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"37 demo =getHTML(url)38uitHTML(ulist,demo)39uitUlist(ulist,20)4041main()
[ 通常の表現:ライブラリについて:(https://www.cnblogs.com/wangyuyang1016/p/10034868.html)](https://www.cnblogs.com/wangyuyang1016/p/10034868.html)
一般的に使用される正規式の演算子
| . | 任意の1文字を表します | |
|---|---|---|
| [ ] | 単一の文字の値の範囲が与えられた場合の文字セット | [a、b、c]はa、b、cを意味し、[az]はaからzまでの単一の文字を意味します |
| [^] | 文字セット以外の場合、除外範囲は1文字に指定されます | [^ a、b、c]は、a、b、またはc |
| * | 前の文字の0または無制限の展開 | abc *は、ab、abc、abcc、abcccなどを意味します。 |
| + | 前の文字は1回または無制限に展開されます | abc +はabc、abcc、abcccなどを意味します |
| ? | 前の文字0または1の展開 | abc?はab、abc |
| 左右の式のいずれか | ||
| { m} | 前の文字をm回展開する | ab {2} cはabbcを意味する |
| { m、n} | 前の文字をmからn倍に拡張します(nを含む) | ab {1,2} cはabc、abbcを意味します |
| ^ | 文字列の先頭に一致 | ^ abcはabcを意味し、文字列の先頭にあります |
| $ | 文字列の末尾に一致 | abc $はabcを意味し、文字列の末尾にあります |
| ( ) | グループ化マーク、 | 演算子 |
| \ d | 数値、[0-9] | |
| \ w | 単語文字、[A-Za-z0-9] |
reライブラリの主な機能
| re.search() | 文字列内の一致する正規式の最初の位置を検索し、一致するオブジェクトを返します |
|---|---|
| re.match() | 文字列の先頭から正規式を照合し、一致オブジェクトを返します |
| re.findall() | 文字列を検索し、リストタイプで一致するすべてのサブ文字列を返します |
| re.split() | 正規式のマッチング結果に従って文字列を分割し、リストタイプを返します |
| re.finditer() | 文字列を検索し、反復可能なタイプの一致結果を返します。各反復可能な要素は一致オブジェクトです |
| re.sub() | 文字列内の正規表現に一致するすべてのサブ文字列を置き換え、置き換えられた文字列を返します |
詳細な機能機能:
| 構文 | re.search(pattern、string、flags = 0) |
|---|---|
| パラメータの説明 | パターン正規式文字列またはネイティブ文字列表現文字列照合する文字列(文字列)フラグ正規式を使用する場合の制御フラグ |
| パターン | 正規表現の文字列またはネイティブ文字列表現 |
| string | 照合する文字列(string) |
| フラグ | 正規式を使用する場合の制御フラグ |
| フラグ制御フラグ | re.Iは正規式の場合を無視します。re.M(複数行照合)の^演算子は、指定された文字列の各行を一致re.S正規式の開始として扱うことができます。演算子は一致できます。すべての文字 |
| re.I | 正規表現の場合を無視する |
| re.M | (複数行の一致)の^演算子は、指定された文字列の各行を一致の開始として扱うことができます |
| re.S | 通常。演算子はすべての文字に一致できます |
| 構文 | re.match(pattern、string、flags = 0) |
|---|---|
| パラメータの説明 | パターン正規式文字列またはネイティブ文字列表現文字列照合する文字列(文字列)フラグ正規式を使用する場合の制御フラグ |
| パターン | 正規表現の文字列またはネイティブ文字列表現 |
| string | 照合する文字列(string) |
| フラグ | 正規式を使用する場合の制御フラグ |
| フラグ制御フラグ | re.Iは正規式の場合を無視します。re.M(複数行照合)の^演算子は、指定された文字列の各行を一致re.S正規式の開始として扱うことができます。演算子は一致できます。すべての文字 |
| re.I | 正規表現の場合を無視する |
| re.M | (複数行の一致)の^演算子は、指定された文字列の各行を一致の開始として扱うことができます |
| re.S | 通常。演算子はすべての文字に一致できます |
| 構文 | re.findall(pattern、string、flags = 0) |
|---|---|
| パラメータの説明 | パターン正規式文字列またはネイティブ文字列表現文字列照合する文字列(文字列)フラグ正規式を使用する場合の制御フラグ |
| パターン | 正規表現の文字列またはネイティブ文字列表現 |
| string | 照合する文字列(string) |
| フラグ | 正規式を使用する場合の制御フラグ |
| フラグ制御フラグ | re.Iは正規式の場合を無視します。re.M(複数行照合)の^演算子は、指定された文字列の各行を一致re.S正規式の開始として扱うことができます。演算子は一致できます。すべての文字 |
| re.I | 正規表現の場合を無視する |
| re.M | (複数行の一致)の^演算子は、指定された文字列の各行を一致の開始として扱うことができます |
| re.S | 通常。演算子はすべての文字に一致できます |
| 構文 | re.split(pattern、string、maxsplit = 0、flags = 0) |
|---|---|
| パラメータの説明 | パターン正規式文字列またはネイティブ文字列は、一致する文字列の最大分割数(文字列)maxsplitを表し、残りの部分はフラグを出力する最後の要素として使用されます。正規式を使用する場合の制御フラグ |
| パターン | 正規表現の文字列またはネイティブ文字列表現 |
| string | 照合する文字列(string) |
| maxsplit | 分割の最大数、残りの部分は最後の要素として出力されます |
| フラグ | 正規式を使用する場合の制御フラグ |
| フラグ制御フラグ | re.Iは正規式の場合を無視します。re.M(複数行照合)の^演算子は、指定された文字列の各行を一致re.S正規式の開始として扱うことができます。演算子は一致できます。すべての文字 |
| re.I | 正規表現の場合を無視する |
| re.M | (複数行の一致)の^演算子は、指定された文字列の各行を一致の開始として扱うことができます |
| re.S | 通常。演算子はすべての文字に一致できます |
| 構文 | re.finditer(pattern、string、flags = 0) |
|---|---|
| パラメータの説明 | パターン正規式文字列またはネイティブ文字列表現文字列照合する文字列(文字列)フラグ正規式を使用する場合の制御フラグ |
| パターン | 正規表現の文字列またはネイティブ文字列表現 |
| string | 照合する文字列(string) |
| フラグ | 正規式を使用する場合の制御フラグ |
| フラグ制御フラグ | re.Iは正規式の場合を無視します。re.M(複数行照合)の^演算子は、指定された文字列の各行を一致re.S正規式の開始として扱うことができます。演算子は一致できます。すべての文字 |
| re.I | 正規表現の場合を無視する |
| re.M | (複数行の一致)の^演算子は、指定された文字列の各行を一致の開始として扱うことができます |
| re.S | 通常。演算子はすべての文字に一致できます |
| 構文 | re.sub(pattern、repl、string、count = 0、flags = 0) |
|---|---|
| パラメータの説明 | pattern通常の式の文字列またはネイティブ文字列はreplを表します一致した文字列の文字列を置き換えます一致する文字列(文字列)count最大の一致フラグを置き換えます通常の式を使用する場合の制御フラグ |
| パターン | 正規表現の文字列またはネイティブ文字列表現 |
| repl | 文字列に一致する文字列を置き換えます |
| string | 照合する文字列(string) |
| count | 置換一致の最大数 |
| フラグ | 正規式を使用する場合の制御フラグ |
| フラグ制御フラグ | re.Iは正規式の場合を無視します。re.M(複数行照合)の^演算子は、指定された文字列の各行を一致re.S正規式の開始として扱うことができます。演算子は一致できます。すべての文字 |
| re.I | 正規表現の場合を無視する |
| re.M | (複数行の一致)の^演算子は、指定された文字列の各行を一致の開始として扱うことができます |
| re.S | 通常。演算子はすべての文字に一致できます |
re.compile():オブジェクト指向の使用法(操作):
| 構文 | regex = re.compile(pattern、flags = 0) |
|---|---|
| 説明 | ・正規式の文字列形式を正規式オブジェクト(オブジェクト)パターンにコンパイルします。正規式文字列またはネイティブ文字列表現(正規式メソッド)フラグ正規式を使用する場合、制御フラグはmatch = regexです。 search( 'string')#compile()は元のre関数と同じ関数を使用します |
| pattern | 通常の式の文字列またはネイティブ文字列表現(通常の表現方法) |
| フラグ | 正規式を使用する場合の制御フラグ |

Matchオブジェクトのプロパティ
| プロパティ | 説明 |
|---|---|
| . 文字列 | 照合するテキスト |
| . re | マッチングで使用されるパターンオブジェクト(正規表現) |
| . pos | 正規表現検索テキストの開始位置 |
| . endpos | 正規表現検索テキストの終了位置 |
マッチオブジェクトメソッド
| 方法 | 説明 |
|---|---|
| . group(0) | 一致した文字列を取得 |
| . start() | 一致する文字列は元の文字列の先頭にあります |
| . end() | 元の文字列内の一致した文字列の終了位置 |
| . span() | return(.start()、. end()) |
例:
1 import re
2 match = re.search(r'[1-9]\d{5}','BIT 100081')3 #Matchオブジェクトのプロパティ
4 print(match.string) #照合時に照合する文字列を返します
5 print(match.re) #マッチング時に再式を返す
6 print(match.pos) #一致した検索テキストの開始位置を返します
7 print(match.endpos) #一致した検索テキストが終了する位置を返します
8 # マッチオブジェクトメソッド
9 print(match.group(0)) #一致した文字列を返します(最初の一致結果)
10 print(match.start()) #元の文字列と一致する
11 print(match.end()) #元の文字列の終わりに一致する
12 print(match.span()) #タプルとして戻る.start()と.end()
reライブラリの貪欲なマッチングと最小のマッチング
1 match = re.search(r'PY.*N','PYANBNCNDN') #貪欲なマッチング(ライブラリのデフォルトの貪欲なマッチング、つまり、最長の出力サブストリングマッチング)
2 print(match.group(0))3 match = re.search(r'PY.*?N','PYANBNCNDN') #最小一致
4 print(match.group(0))
最小マッチング演算子
| オペレーター | 説明 |
|---|---|
| *? | 前の文字は0回または無制限に展開され、最小の一致 |
| +? | 前の文字は1回または無制限に展開され、最小の一致 |
| ?? | 前の文字の0または1の展開、最小一致 |
| { m、n}? | 前の文字をmからn倍(nを含む)に展開します。これは最小の一致です |
Recommended Posts