Pythonはパンダを使用してExcelデータを処理します
エディターのコンピューターシステムは、Windows10 Home Edition、64ビットです。インターネットでN個のメソッドを見つけましたが、複雑すぎて記述できません。以下は、私が試した実行可能なメソッドです。
1 :PandasはExcelを処理するxlrdモジュールに依存しているため、事前にこれをインストールする必要があります。インストールコマンドは次のとおりです。pipinstallxlrd
2 :pandasモジュールのインストールには、特定のコーディング環境も必要です。そのため、自分でインストールするときは、コンピューターにNet.4、VC-Compiler、winsdk_webの環境があることを確認してください。
3 :手順1と2の準備ができたら、パンダのインストールを開始し、パンダの最新バージョンを更新できます。pipinstall pandas == 0.24.0
4 :Pip show pandasは、最新バージョンがインストールされているかどうかを確認できます。最新バージョンをインストールしないと、一部のライブラリがpandasにないため、Pythonコードの実行が失敗します。
ps:このプロセス中に、インストールが不十分になる可能性があります。全能のDuniangにはN個のソリューションがあります。自分で問題を解決する方法を学ぶ必要があります。
import pandas as pd
df=pd.read_excel('test_data_xiejinjieguo_chongzhi.xlsx',sheet_name='recharge')
# print(df.values)すべての行を読む
# print(df.ix[:].values)すべて読む
# print(df.ix[1:1].values)0から数えます
# print(df.ix[:])マトリックス形式で読み上げる
# print(df.ix[:,['url']].values)指定された行の指定された列を読み取ります
# print(df.ix[:,['url','data']].values)複数行を指定する
# print(df.ix[1,['url','data','title','case_id','http_method']].to_dict())読み取る列を指定します
# print(df.ix[1].to_dict())すべてのフィールドはデフォルトで読み取られます
# print(df.index.values)#01234デフォルトで、urlなどのExcelモジュールのヘッダーを削除しました,test_method
test_data=[]#すべての使用例と結果を見る
for i in df.index.values:
row_data=df.ix[i,['url','data','title','case_id','http_method']].to_dict()
test_data.append(row_data)print(test_data)
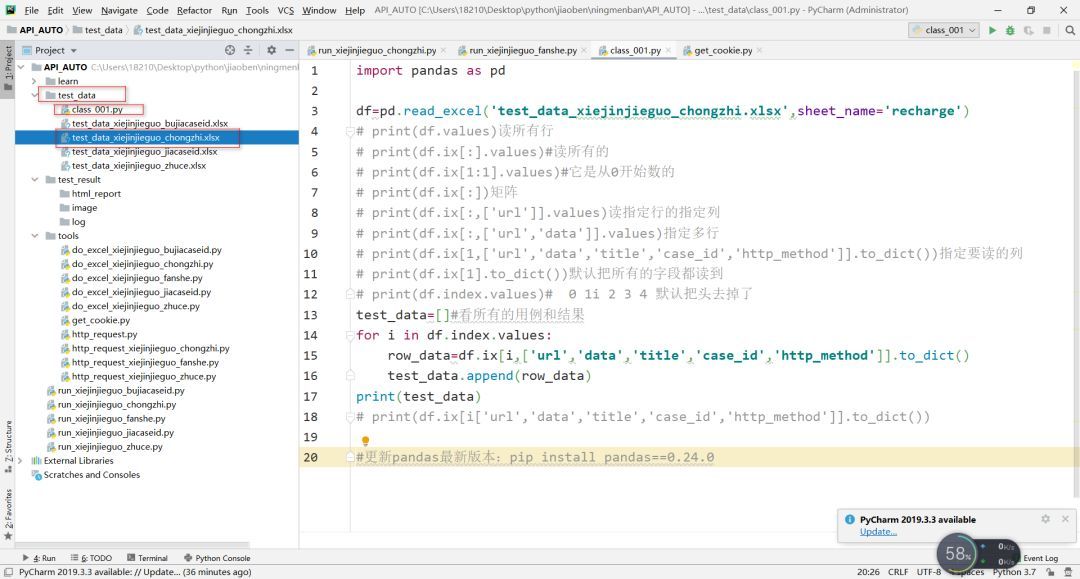
私のコードファイルの構造は次のとおりです。
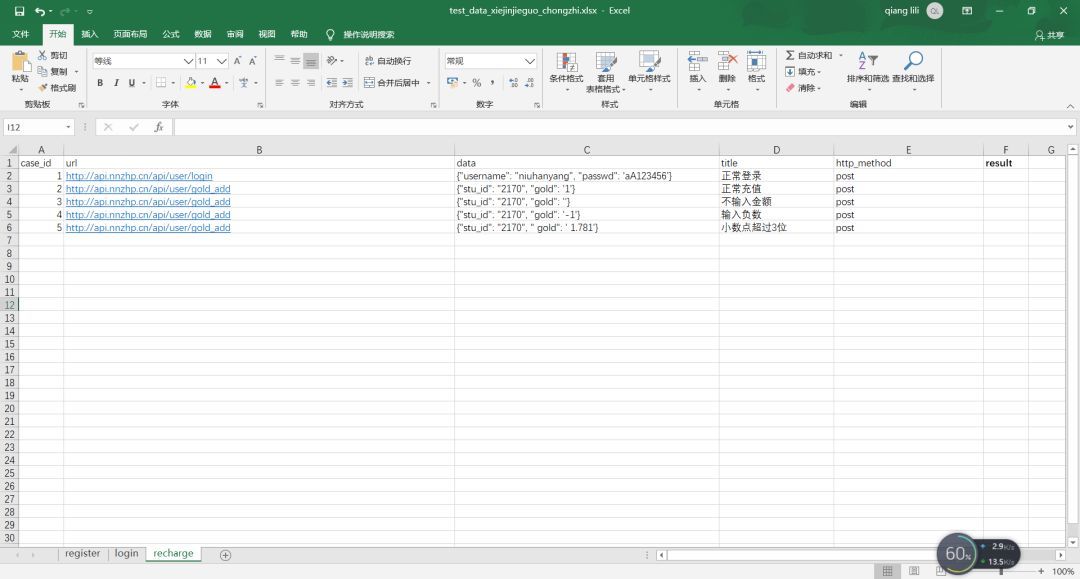
Excelの内容は次のとおりです。
注:Pycharmの絶対パスと相対パスを明確にする必要があります。そうしないと、コードの実行時にエラーが発生します。
Recommended Posts