Pythonデータ分析-データ選択
インターネットの急速な発展により、ますます多くのデータと情報がインターネットに保存されています。これらのデータを分析することで、大手企業は意思決定に役立つ情報を得ることができます。
たとえば、一部のユーザーのタオバオ閲覧記録データを分析することで、これらの顧客の潜在的な消費ポイントを発見し、分類によって指定されたポイントに広告を掲載して、商品の売上を増やすことができます。
もう1つの例はクレジットフィールドです。申請者のクレジットデータを分析し、申請者が延滞する可能性をモデル化して計算することにより、貸与するかどうかを決定し、それによって会社の資金の使用価値を高めます。
今日、データ分析がますます普及しているとき、データを分析することを学ぶことはあなたの昇進と給料の増加のための重要な重みです。
この記事は、データ分析の2番目のレッスンであり、Pythonでデータを選択する方法を説明します。
この記事の内容
-
データフレームの列を選択します
-
データフレームで複数の列を選択します
-
データフレームの行を選択します
-
データフレーム内の複数の行を選択します
-
サブデータフレームを選択
-
条件付きデータフレームを選択
注:この記事では、データ分析の最初のレッスンでデータフレームdate_frameを使用します[[Pythonデータ分析-データ作成](http://mp.weixin.qq.com/s?__biz=MzIxMjA1NzQzMQ==&mid=2247485128&idx=1&sn=64a6f87a16fa3cd41dadfcfea2f76787&chksm=974aaaf0a03d23e69179350c6fd900a2ba12d34c0a82426654fb76b5315e0936251d307375f1&scene=21#wechat_redirect)]:
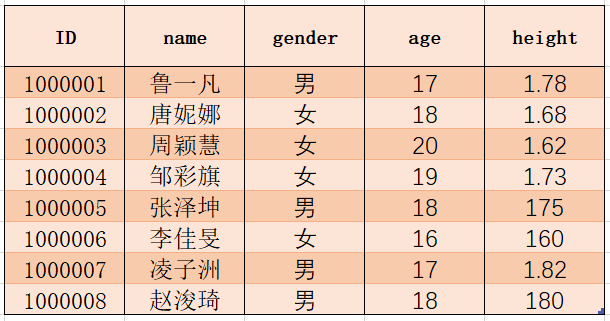
** 1 データフレームの列を選択**
データフレームの列を選択する方法は4つあります。
最初の方法:データフレームの名前。列名。
2番目の方法:データフレームの名前['列名']。
3番目の方法:データframe.iloc [:、column subscript]の名前。3番目の列を選択する場合、対応する添え字は2で、2つはマイナス1です。
4番目の方法:データフレームの名前。loc[:、['列名']]
date_frameデータフレームの名前列(2番目の列)を選択する必要がある場合は、jupyterで次のステートメントを実行できます。
date_frame.name #方法1
date_frame['name'] #方法2
date_frame.iloc[:,1] #方法3
date_frame.loc[:,['name']] #方法4
最初の3つの方法の結果は次のとおりです。

4番目の方法の結果は次のとおりです。

注:最初の3つの方法で取得されるデータタイプはSeriesであり、4番目の方法で取得されるデータタイプはDataFrameです。
** 2 データフレーム内のいくつかの列を選択します**
データフレームで複数の列を選択する必要がある場合は、次の3つの方法を使用できます。
最初の方法:データフレームの名前[['列名1'、 '列名2'、...、 '列名n']]。
2番目のメソッド:データフレームの名前。loc[:、['列名1'、 '列名2'、...、 '列名n']]。
3番目の方法:データフレームの名前。iloc[:、列の添え字の開始:列の添え字の終了と1]。
date_frameデータフレームでname列とheight列を選択する必要がある場合は、jupyterで次のステートメントを実行できます。
date_frame[['height','name']] #方法1
date_frame.loc[:,['height','name']] #方法2
date_frame.iloc[:,[1,4]] #方法3
最初の2つの方法で得られた結果は次のとおりです。
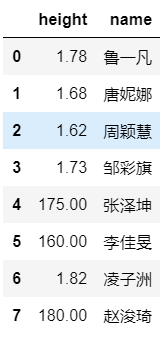
最初の2つの方法で特定の列を選択し、元のデータフレームの順序からフィルターで除外し、順序をカスタマイズできることがわかります。
3番目の方法の結果は次のとおりです。
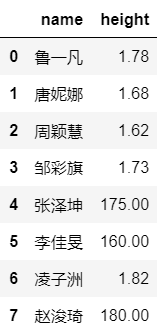
注:Pythonでは、対応する添え字と現在の位置はマイナス1であり、date_frame.iloc [:、1:3]の1:3は、頭を含み尾を含まない添え字3を取得できません。
** 3 データフレームの行を選択**
データフレームの行を選択する必要がある場合は、次の3つの方法を使用できます。
最初の方法:データフレームの名前[行の添え字:行の添え字に1を加えたもの]。
2番目の方法:データフレームの名前。loc[行添え字、:]。
3番目の方法:データframe.iloc [row subscript 、:]の名前。
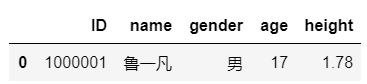
date_frameデータフレームの最初の行を選択する必要がある場合(対応する行の添え字は0です)、pythonで次のコードを入力できます。
date_frame[0:1] #最初の方法
date_frame.loc[1,:] #2番目の方法
date_frame.iloc[1,:] #3番目の方法
最初のメソッドはデータフレームを取得します。
最後の2つの方法はシリーズを取得し、具体的な結果は次のとおりです。

** 4 データフレーム内のいくつかの行を選択します**
データフレーム内の特定の行を選択する必要がある場合は、次の3つの方法を使用できます。
最初の方法:データフレームの名前[開始行の添え字:終了行の添え字に1を加えたもの]。
2番目の方法:データフレームの名前。iloc[開始行の添え字:終了行の添え字に1を加えたもの:]。
3番目の方法:データフレームの名前。loc[開始行の添え字:終了行の添え字、:]。
date_frameデータフレームの最初の行から2番目の行までのデータを選択する必要がある場合(対応する行の添え字は0:1です)、pythonで次のコードを入力できます。
date_frame[0:2] #最初の方法
date_frame.iloc[0:2,:] #2番目の方法
date_frame.loc[0:1,:] #3番目の方法
3つの方法で得られた結果は次のとおりです。

3番目の方法では、行選択の添え字に頭と尾が含まれていることに注意してください。コンピューターでコードを実行して、これを体験できます。
** 5 サブデータフレームを選択**
以前、特定の行と特定の列を別々に選択しましたが、行の添え字1と2、および列の添え字1と2(図の緑色の部分)を持つサブデータフレームを選択する場合は、どうすればよいですか?
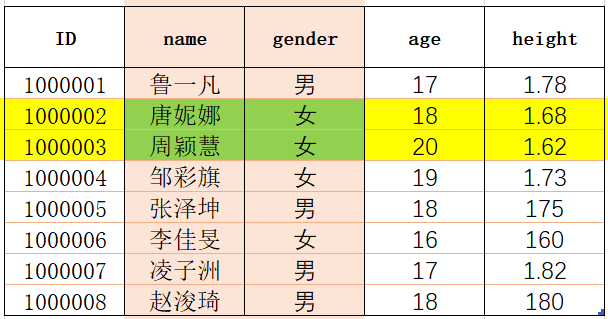
選択する行データフレームと列データフレーム(順不同)を選択するためのコードを重ね合わせることができます。
たとえば、次のコードを使用します。
date_frame[1:3][['name','gender']]
結果は次のとおりです。

** 6 条件付きデータフレームを選択**
date_frameで性別が男性のサブデータフレームを選択するとします。jupyterに次のコードを入力できます。
date_frame[date_frame.gender=='男性']
結果は次のとおりです。
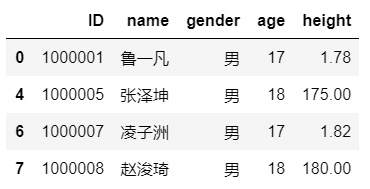
年齢が17歳を超え、身長が170を超える、date_frame内の学生情報を選択するとします。jupyterに次のコードを入力できます。
date_frame[(date_frame.height>1.7)&(date_frame.age>17)]
結果は次のとおりです。

この時点で、pythonでのデータ選択の基本的な操作は完了しています。これを練習して、データを選択するためのより良い方法があるかどうかを考えることができます。
Recommended Posts