Pythonデータ形式-CSV
CSVファイル:コンマ区切り値、中国語名、コンマ区切り値、または文字区切り値、そのファイルテーブルデータをプレーンテキスト形式で保存。ファイルは文字のシーケンスであり、ある種の新行文字で区切られた任意の数のレコードで構成できます。各レコードはフィールドで構成され、フィールド間の区切り文字は他の文字または文字列です。すべてのレコードには、まったく同じフィールドシーケンスがあります。これは、構造化テーブルのプレーンテキスト形式に相当します。
CSVファイルは、テキストファイル、Excelなどのテキストファイルで開くことができます。
CSVへの書き込み#
- PythonでCSVファイルにデータを書き込みます。例は次のとおりです。
import csv #ライブラリをインポートする必要があります
withopen('data.csv','w')as fp:
writer = csv.writer(fp)#最初にファイルハンドルを渡します
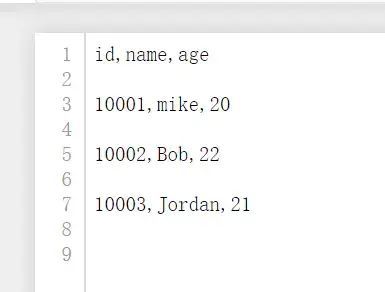
writer.writerow(['id','name','age'])#次に、
writer.writerow(['10001','mike','20'])#行で書く
writer.writerow(['10002','Bob','22'])
writer.writerow(['10003','Jordan','21'])
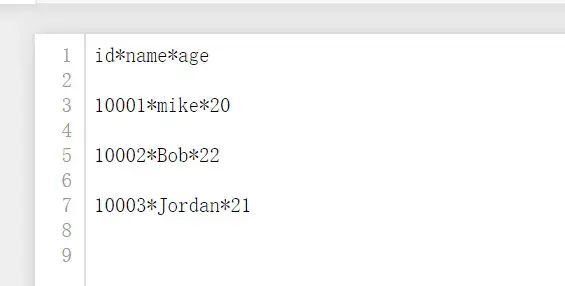
- 列間の区切り文字を変更し、区切り文字パラメーターを渡します。
import csv #ライブラリをインポートする必要があります
withopen('data.csv','w')as fp:
writer = csv.writer(fp,delimiter ='*')#区切り文字は1バイト文字のみにすることができます
writer.writerow(['id','name','age'])#次に、
writer.writerow(['10001','mike','20'])#行で書く
writer.writerow(['10002','Bob','22'])
writer.writerow(['10003','Jordan','21'])
- 最初にタイトルを書き込み、データを書き込みます。
注:データはリストであり、writerows()メソッドを使用します

- 辞書としてcsvに書き込む
import csv
withopen('data.csv','w')as fp:
fieldnames =['id','name','age'] #最初に辞書でキーを定義します
# DictWriter()メソッドを使用してフィールド名を追加します
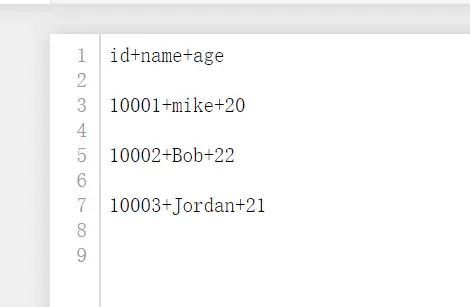
writer = csv.DictWriter(fp,fieldnames = fieldnames,delimiter ='+')
writer.writeheader()#最初にキーを書き込む
# 辞書に書く
writer.writerow({'id':'10001','name':'mike','age':'20'})
writer.writerow({'id':'10002','name':'Bob','age':'22'})
writer.writerow({'id':'10003','name':'Jordan','age':'21'})
CSVを読む#
- CSVファイルを読み取る方法は2つあります。
- 最初
import csv
withopen('data.csv','r',encoding ='utf8')as fp:
reader = csv.reader(fp)for row in reader:print(row)
- 二番目
import pandas as pd #パンダライブラリをインポートする必要があります
df = pd.read_csv('data.csv')print(df)
Recommended Posts