02.Pythonデータタイプ
Pythonエントリデータタイプ##
**メモリに保存されている変数の値。これは、変数が作成されると、メモリ内にスペースが作成されることを意味します。インタプリタは、変数のデータタイプに基づいて、指定されたメモリを割り当て、メモリに保存できるデータを決定します。 **したがって、変数はさまざまなデータタイプを指定でき、これらの変数は整数、小数、または文字を格納できます。
1つ、変数##
1.1 変数の割り当て###
# Pythonでの変数の割り当てには、型宣言は必要ありません。
# 各変数は、変数のID、名前、データを含めて、メモリ内に作成されます。
# 各変数には、使用する前に値を割り当てる必要があります。変数は、変数が割り当てられた後に作成されます。
# 等号(=)変数に値を割り当てるために使用されます。
# 等号(=)演算子の左側は変数名です,等号(=)演算子の右側は、変数に格納されている値です。例えば:
conuter =100
miles =1000.0
name ="Json"print(conuter)print(miles)print(name)
1.2 複数の変数の割り当て###
Pythonでは、たとえば、複数の変数に値を割り当てることができます。
a = b = c =1print(a,b,c)
# 複数のオブジェクトに複数の変数を指定することもできます,例えば:
a, b , c =1,2,"json"print(a,b,c)
しかし、pythonでは、pythonはすでにメモリ管理の実装を支援しているため、プログラマはメモリオーバーフローやその他の問題を気にする必要はありません。 **** 1。参照カウンター** 2。ゴミ収集メカニズム****各オブジェクトは独自の参照カウンターを維持し、参照されるたびに、カウンターは1ずつ増加します。オブジェクトのカウンターがゼロ時間になると、ガベージコレクションメカニズムは彼をメモリからクリアし、以前に占有していたメモリスペースを解放します。 ****
2、標準データタイプ##
メモリには多くの種類のデータが保存されている可能性があります。
たとえば、人の年齢は数字で保存でき、名前は文字で保存できます。
Pythonは、さまざまなタイプのデータを格納するためのいくつかの標準タイプを定義しています。
Pythonには5つの標準データタイプがあります。
* 数字
* ストリング
* リスト
* タプル(タプル)
* 辞書
3、Python番号(番号)##
Pythonの数値型は、数値を格納するために使用されます。数値型は変更できません。つまり、数値型の値が変更されると、メモリスペースが再割り当てされます。
var1 =10
var2 =20
delステートメントを使用して、一部のデジタルオブジェクトへの参照を削除することもできます。** delステートメントの構文は次のとおりです。**
del var1[,var2[,var3[....,varN]]]
# たとえば、delステートメントを使用して単一または複数のオブジェクトへの参照を削除することもできます。:
del var
del var_a,var_b
Pythonは3つの異なる数値タイプをサポートしています
整数(int):通常、整数または整数と呼ばれ、小数点のない正または負の整数です。 Python3整数型にはサイズ制限がなく、Long型として使用できるため、Python3にはPython2Long型がありません。
浮動小数点型(浮動小数点):浮動小数点型は整数部と小数部で構成されます。浮動小数点型は科学表記(2.5e2 = 2.5 x 102 = 250)でも表現できます。
複素数(複素数):複素数は、実数部と虚数部で構成され、+ bjまたは複素数(a、b)で表すことができます。複素数の実数部aと虚数部bは、どちらも浮動小数点型です。
整数を表すために16進数と8進数を使用することもできます:
>>> number =0xA0F #ヘキサデシマル
>>> number
2575>>> number=0o37 #オクタル
>>> number
31
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14 j |
| 100 | 15.20 | 45. j |
| - 786 | - 21.9 | 9.322 e-36j |
| 080 | 32.3 e+18 | .876j |
| - 0490 | - 90. | - .6545+0 J |
| - 0 x260 | -32.54e100 | 3e+26J |
| 0 x69 | 70.2E-12 | 4.53e-7j |
3.1 Python番号タイプの変換
場合によっては、組み込みタイプのデータを変換する必要があります。データタイプの変換では、関数名としてデータタイプを使用するだけで済みます。
* int(x)xを整数に変換します。
* float(x)xを浮動小数点数に変換します。
* complex(x)xを複素数に変換します。実数部はxで、虚数部は0です。
* complex(x, y)xとyを複素数に変換します。実数部はx、虚数部はyです。 xとyは数値式です。
# 次の例では、浮動小数点変数aを整数に変換します:
a =1.0print(int(a))1
3.2 Python番号操作
Pythonインタープリターは、単純な計算機として使用できます。インタープリターに式を入力すると、式の値が出力されます。式の構文は非常に単純です:+、-、*、/、他の言語(PascalやCなど)と同じです。例えば:
>>>2+24>>>50- 5*620>>>(50- 5*6) /45.0>>>8/5 #常に浮動小数点数を返します
1.6
**注:異なるマシンでの浮動小数点演算の結果は異なる場合があります。**整数除算では、除算/は常に浮動小数点数を返します。整数の結果のみを取得する場合は、可能な部分部分を破棄し、算術を使用できます。記号//:
>>>17 /3 #整数除算は浮動小数点を返します
5.666666666666667>>>>>>17 // 3 #整数除算は、5を切り捨てた結果を返します>>>17%3 #%演算子は、除算の残りを返します
2>>>5*3+217
# 注意://得られる数値は必ずしも整数型ではなく、分母分子のデータ型に関連しています。. >>>7//2 3>>>7.0//2 3.0>>>7//2.0 3.0>>>
等しい符号=は、変数に値を割り当てるために使用されます。割り当て後、インタプリタは次のプロンプトを除いて結果を表示しません。
>>> width =20>>> height =5*9>>> width * height
900
Pythonは指数化のための操作**を使用できます
>>>5**2 # 5 二乗
25>>>2**7 # 2 7乗
128
変数を使用する前に、変数を「定義」する(つまり、変数に値を割り当てる)必要があります。そうしないと、エラーが発生します。
>>> n #未定義の変数にアクセスしてみてください
Traceback(most recent call last):
File "<stdin>", line 1,in<module>
NameError: name 'n' is not defined
異なる種類の数値を混合する場合、整数は浮動小数点数に変換されます
>>>3*3.75 /1.57.5>>>7.0/23.5
インタラクティブモードでは、最後の出力式の結果が変数_に割り当てられます。例えば
>>> tax =12.5/100>>> price =100.50>>> price * tax
12.5625>>> price + _
113.0625>>> round(_,2)113.06
# ここに、_変数は、ユーザーが読み取り専用変数として扱う必要があります
3.3 ランダム番号関数
ランダム番号は、数学、ゲーム、セキュリティ、およびその他の分野で使用でき、アルゴリズムの効率を向上させ、プログラムのセキュリティを向上させるために、アルゴリズムに組み込まれることがよくあります。 **** Pythonには、次の一般的に使用されるランダム番号関数が含まれています
| 機能 | 説明 |
|---|---|
| [ choice(seq)] | random.choice(range(10))など、シーケンスの要素からランダムに要素を選択し、0から9までの整数をランダムに選択します。 |
| [ randrange([start、] stop [、step])] | 指定された範囲内で指定されたベースだけ増加するランダムな数値をセットから取得します。ベースのデフォルト値は1です |
| [ random()] | [0,1)の範囲にある次の実数をランダムに生成します。 |
| [ seed([x])] | ランダム数ジェネレーターのシードを変更します。原理を理解していない場合は、シードを具体的に設定する必要はありません。Pythonがシードの選択を支援します。 |
| [ shuffle(lst)] | シーケンスのすべての要素をランダムに並べ替えます |
| [ Uniform(x、y)] | [x、y]の範囲内にある次の実数をランダムに生成します。 |
5、Python文字列##
**文字列はPythonで最も一般的に使用されるデータ型です。引用符( 'または ``)を使用して文字列を作成できます。**文字列の作成は非常に簡単で、変数に値を割り当てるだけです。例:
var1 ='Hello World!' var2 ="Runoob"
5.1 Pythonは文字列の値にアクセスします
文字列または文字列(String)は、数字、文字、および下線で構成される文字の文字列です。
一般的にマーク
s="a1a2···an"(n>=0)
# プログラミング言語でテキストを表すデータタイプです
# Python文字列には2つの値の順序があります:
# 左から右へのインデックスはデフォルトで0から始まり、最大範囲は文字列の長さ1です。.
# 右から左へのインデックスのデフォルト-1から始まり、最大範囲は文字列の先頭です
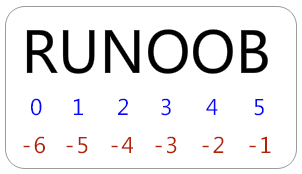
文字列から部分文字列を取得する場合は、[head subscript:tail subscript]を使用して、対応する文字列をインターセプトできます。この文字列は0から始まり、正または負になります。ラベルは、開始または終了を示すために空にすることができます。
[ ヘッドサブスクリプト:テールサブスクリプト]取得されたサブストリングには、ヘッドサブスクリプトの文字が含まれますが、テールサブスクリプトの文字は含まれません。
といった:
s ='youmen'print(s[1:5])
コロンで区切られた文字列を使用する場合、pythonは新しいオブジェクトを返し、結果にはオフセットのペアで識別される連続コンテンツが含まれ、左側の先頭には下限が含まれます。
上記の結果にはs [1]の値bが含まれており、取得される最大範囲には、s [5]の値fであるテール添え字は含まれていません。

str ='Hello Wrold'print(str)print(str[0])print(str[2:5])print(str[2:])print(str *2)print(str +"TEST")
Hello Wrold
H
llo
llo Wrold
Hello WroldHello Wrold
Hello WroldTEST
5.2 Python文字列の更新
次の例のように、文字列の一部をインターセプトして、他のフィールドとつなぎ合わせることができます。
var1 ='hello world'print(var1[:6]+'Runnob!')
# 上記の例の出力は次のとおりです。
hello Runnob!
5.3 Pythonエスケープ文字###
文字に特殊な文字を使用する必要がある場合、Pythonはバックスラッシュ()を使用して文字をエスケープします。次の表:
| エスケープ文字 | 説明 |
|---|---|
| ( 行末) | 行継続文字 |
| | バックスラッシュ記号 | |
| ' | 一重引用 |
| " | 二重引用符 |
| \ a | ベル |
| \ b | バックスペース |
| \000 | 空 |
| \ n | newline |
| \ v | 垂直タブ |
| \ t | 水平タブ文字 |
| \ r | 入力 |
| \ f | ページ変更 |
| \ oyy | オクタル番号。yyで表される文字。例:\ o12は改行を表します。ここで、oは文字であり、番号0ではありません。 |
| \ xyy | 16進数、yyで表される文字。例:\ x0aはnewlineを表します |
| \ その他 | その他の文字は通常の形式で出力されます |
5.4 Python文字列演算子###
**次の表では、変数aの値は「hello」であり、変数bは「Python **」です。
| 演算子 | 説明 | 例 |
|---|---|---|
| + | 文字列の連結 | a + b出力結果:HelloPython |
| * | 繰り返し出力文字列 | a * 2出力結果:HelloHello |
| [] | 文字列内の文字をインデックスで取得 | a [1]出力結果e |
| [ : ] | 文字列の一部をインターセプトするには、左クローズと右オープンの原則に従います。str[0,2]には3番目の文字が含まれていません。 | a [1:4]出力結果ell |
| in | メンバー演算子-文字列に指定された文字が含まれている場合、aにTrue | 'H'を返し、結果True |
| not in | member演算子-文字列に指定された文字が含まれていない場合、aにないTrue | 'M'を返し、結果True |
| % | フォーマット文字列 | 以下を参照 |
5.5 Python文字列のフォーマット
**Pythonは、フォーマットされた文字列の出力をサポートしています。この方法では非常に複雑な式を使用できますが、最も基本的な使用法は、文字列形式の文字%sを使用して文字列に値を挿入することです。 ****
**Pythonでは、文字列の書式設定はCのsprintf関数と同じ構文を使用します。
Example
print('私の名前は%今年は%d歳!'%('シャオミン',10))
私の名前はXiaoming、10歳です!
Python文字列フォーマット記号
| 記号 | 説明 |
|---|---|
| %c | 文字とそのASCIIコードのフォーマット |
| %s | フォーマット文字列 |
| %d | フォーマットされた整数 |
| %u | 符号なし整数をフォーマット |
| %o | 符号なしオクタル数をフォーマットする |
| %x | 符号なし16進数をフォーマットする |
| %X | 符号なし16進数をフォーマットします(大文字) |
| %f | 浮動小数点数をフォーマットします。小数点以下の精度を指定できます |
| %e | 浮動小数点数を科学表記でフォーマットする |
| %E | %eと同じ機能で、浮動小数点数を科学表記でフォーマットします |
| %g | %fおよび%e |
| %G | %fおよび%E |
| %p | 変数のアドレスを16進数でフォーマットします |
Pythonトリプルクォート
**Pythonの三重引用符を使用すると、文字列を複数行にまたがることができます。文字列には、次のように改行、タブ、およびその他の記号が含まれます。
para_str ="""これは複数行の文字列の例です
複数行の文字列はタブを使用できます
TAB(\t).
改行を使用することもできます[\n]."""
print(para_str)
# 上記の例の出力は次のとおりです。
これは複数行の文字列の例です
複数行の文字列はタブを使用できます
TAB().
改行を使用することもできます[].
# トリプルクォーテーションマークは、プログラマーをクォーテーションマークと特殊文字の泥沼から解放します,小さな文字列のフォーマットを最初から最後まで維持することは、いわゆるWYSIWYGフォーマットです。.
# 典型的な使用例は,HTMLまたはSQLが必要な場合は、この時点で文字列の組み合わせを使用します。特別な文字列エスケープは非常に面倒です。.
5.6 f-string
f-stringはpython3.6の後に追加されました。これはリテラル形式の文字列と呼ばれ、新しい形式の文字列構文です。以前はパーセント記号(%)を使用していました:
>>> name ='Runoob'>>>'Hello %s'% name
' Hello Runoob'
# f-文字列の形式と文字列はfで始まり、その後に文字列が続き、文字列内の式は中括弧を使用します{}要約、
# 彼は変数または式の計算値を置き換えます,例は次のとおりです.
name ='Runoob'print(f'Hello {name}')
age =20print(f'{age+1}')
w ={'name':'Runoob','url':'www.runoob.com'}print(f'{w["name"]}:{w["url"]}')
Hello Runoob
21
Runoob:www.runoob.com
Python2では、通常の文字列は8ビットのASCIIコードとして保存されますが、Unicode文字列は16ビットのユニコード文字列として保存され、より多くの文字セットを表すことができます。使用される構文は、文字列の前にuを付けることです。 **** Python3では、すべての文字列はUnicode文字列です
5.7 Pythonの文字列組み込み関数###
一般的に使用されるPythonの文字列組み込み関数は次のとおりです。
| シリアル番号 | 方法と説明 |
|---|---|
| 1 | Capitalize()は文字列の最初の文字を大文字に変換します |
| 2 | center(width、fillchar)は、中央に指定された幅の文字列を返します。fillcharは塗りつぶされた文字であり、デフォルトはスペースです。 |
| 3 | count(str、beg = 0、end = len(string))は、文字列内のstrの出現回数を返します。begまたはendが指定されている場合、指定された範囲内のstrの出現回数を返します |
| 4 | bytes.decode(encoding = "utf-8"、errors = "strict")Python3にはdecodeメソッドはありませんが、bytesオブジェクトのdecode()メソッドを使用して、特定のbytesオブジェクトをデコードできます。このbytesオブジェクトはstrによって生成できます。リターンをエンコードするencode()。 |
| 5 | encode(encoding = 'UTF-8'、errors = 'strict')は、encodingで指定されたエンコード形式で文字列をエンコードします。エラーが発生した場合、エラーで 'ignore'または 'replace'を指定しない限り、ValueError例外がデフォルトで報告されます |
| 6 | extendswith(suffix、beg = 0、end = len(string))文字列がobjで終わるかどうかを確認し、begまたはendが指定されている場合は、指定された範囲がobjで終わるかどうかを確認します。はいの場合はTrueを返し、そうでない場合はFalseを返します |
| 7 | expandtabs(tabsize = 8)は、文字列内のタブシンボルをスペースに変換します。タブシンボルのデフォルトのスペース数は8です。 |
| 8 | find(str、beg = 0、end = len(string))は、strが文字列に含まれているかどうかを検出し、範囲begとendが指定されている場合は、指定された範囲に含まれているかどうかを確認します。含まれている場合は、開始インデックス値を返します。それ以外の場合は、 -1 |
| 9 | index(str、beg = 0、end = len(string))はfind()と同じですが、strが文字列にない場合、例外が報告される点が異なります。 |
| 10 | isalnum()は、文字列に少なくとも1つの文字があり、すべての文字が文字または数字の場合はTrueを返し、それ以外の場合はFalseを返します |
| 11 | isalpha()は、文字列に少なくとも1つの文字があり、すべての文字が文字である場合はTrueを返し、それ以外の場合はFalseを返します |
| 12 | isdigit()は、文字列に数字のみが含まれている場合はTrueを返し、それ以外の場合はFalseを返します。 |
| 13 | islower()文字列に大文字と小文字が区別される文字が少なくとも1つ含まれていて、これらの(大文字と小文字が区別される)文字がすべて小文字の場合はTrueを返し、そうでない場合はFalseを返します |
| 14 | isnumeric()文字列に数字のみが含まれている場合はTrueを返し、そうでない場合はFalseを返します |
| 15 | isspace()文字列に空白のみが含まれている場合はTrueを返し、そうでない場合はFalseを返します。 |
| 16 | istitle()は、文字列にタイトルが付いている場合はTrueを返し(title()を参照)、そうでない場合はFalseを返します |
| 17 | isupper()文字列に大文字と小文字が区別される文字が少なくとも1つ含まれていて、これらの(大文字と小文字が区別される)文字がすべて大文字の場合はTrueを返し、そうでない場合はFalseを返します |
| 18 | join(seq)は、指定された文字列を区切り文字として使用して、seq内のすべての要素(文字列表現)を新しい文字列に結合します |
| 19 | len(string)は文字列の長さを返します |
| 20 | ljust(width [、fillchar])は、元の文字列が左寄せされ、fillcharで長さ幅に入力された新しい文字列を返します。fillcharのデフォルトはスペースです。 |
| 21 | lower()は、文字列内のすべての大文字を小文字に変換します。 |
| 22 | lstrip()は、文字列の左側のスペースまたは指定された文字を切り取ります。 |
| 23 | maketrans()は、文字マッピングの変換テーブルを作成します。2つのパラメーターを受け入れる最も単純な呼び出しメソッドの場合、最初のパラメーターは変換される文字を示す文字列であり、2番目のパラメーターも変換のターゲットを示す文字列です。 |
| 24 | max(str)は、文字列strの最大の文字を返します。 |
| 25 | min(str)は、文字列strの最小の文字を返します。 |
| 26 | replace(old、new [、max])は、文字列内のstr1をstr2に置き換えます。maxが指定されている場合、置き換えは最大回数を超えません。 |
| 27 | rfind(str、beg = 0、end = len(string))はfind()関数に似ていますが、右から検索します。 |
| 28 | rindex(str、beg = 0、end = len(string))はindex()に似ていますが、右から始まります。 |
| 29 | rjust(width、[、fillchar])は、元の文字列が右寄せされ、fillchar(デフォルトのスペース)で長さ幅に入力された新しい文字列を返します |
| 30 | rstrip()は、文字列の最後のスペースを削除します。 |
| 31 | split(str = ""、num = string.count(str))num = string.count(str))文字列をインターセプトするための区切り文字としてstrを使用します。numに指定された値がある場合、num +1個のサブストリングのみがインターセプトされます |
| 32 | splitlines([keepends])は行( '\ r'、 '\ r \ n'、\ n ')で区切られ、各行を要素として含むリストを返します。パラメーターkeependsがFalseの場合、改行は含まれません。Trueの場合、newline文字は保持されます。 |
| 33 | startupwith(substr、beg = 0、end = len(string))は、文字列が指定されたサブ文字列substrで始まるかどうかをチェックし、そうである場合はTrueを返し、そうでない場合はFalseを返します。 begとendで値を指定する場合は、指定した範囲内で確認してください。 |
| 34 | strip([chars])は、文字列に対してlstrip()とrstrip()を実行します |
| 35 | swapcase()は、文字列内で大文字を小文字に、小文字を大文字に変換します |
| 36 | title()は「titled」文字列を返します。これは、すべての単語が大文字で始まり、残りの文字が小文字であることを意味します(istitle()を参照) |
| 37 | translate(table、deletechars = "")は、str(256文字を含む)で指定されたテーブルに従って文字列の文字を変換し、フィルターで除外される文字はdeletecharsパラメーターに配置されます |
| 38 | upper()は、文字列内の小文字を大文字に変換します |
| 39 | zfill(width)は長さwidthの文字列を返し、元の文字列は右揃えになり、前面は0で埋められます |
| 40 | isdecimal()は、文字列に10進文字のみが含まれているかどうかを確認し、含まれている場合はtrueを返し、含まれていない場合はfalseを返します。 |
6、Pythonリスト##
リスト(リスト)は、Pythonで最も頻繁に使用されるデータタイプです。
このリストは、ほとんどのコレクションのデータ構造の実現を完了することができます。文字、数字、文字列、さらにはリスト(つまりネスト)もサポートします。
リストは[]でマークされています。これは、pythonで最も一般的な複合データタイプです。リスト内の値の切り取りでは、変数[head subscript:tail subscript]を使用して、対応するリストをインターセプトすることもできます。左から右へのインデックスはデフォルトで0から始まり、右から左へのインデックスはデフォルトで-1から始まります。空とは、最初または最後に到達することを意味します。

さらに、Pythonには、シーケンスの長さを決定し、最大要素と最小要素を決定するための組み込みメソッドがあります。
このリストは、最も一般的に使用されるPythonデータタイプであり、角括弧内にコンマ区切りの値として表示できます。
リストのデータ項目は同じタイプである必要はありません
リストを作成するには、さまざまなデータ項目をコンマで区切って角括弧で囲みます。次のように:
list1 =['Google','Runoob',1997,2000]
list2 =[1,2,3,4,5]
list3 =["a","b","c","d"]
# 注意:次の例はすべて、ここで変数をテンプレートとして使用しています
文字列のインデックスと同様に、リストのインデックスは0から始まり、リストを傍受したり、組み合わせたりすることができます。
6.1 リストの値にアクセスします###
以下に示すように、添え字インデックスを使用してリスト内の値にアクセスします。また、角括弧を使用して文字をインターセプトすることもできます。
print("list1[0]", list1[0])print("list2[1:3]",list2[1:3])
# 上記の例の出力は次のとおりです。:
list1[0] Google
list2[1:3][2,3]
6.2 リストの更新###
print('list1の最初の要素は:',list1[1])
list1[1]='youmen'print('list1の要素は次のとおりです。:',list1[1])
# 上記の例の出力は次のとおりです。:
list1の最初の要素は: Runoob
list1の要素は次のとおりです。: youmen
# 追加も使用できます()方法
6.3 リスト要素を削除する###
次の例に示すように、delステートメントを使用してリストの要素を削除できます
list3 =["a","b","c","d"]print("元のリストリスト3",list3)
del list3[0]print("0番目の要素を削除します",list3)
# 上記の例の出力は次のとおりです。
元のリストリスト3['a','b','c','d']
0番目の要素を削除します['b','c','d']
# もちろん、removeを使用することもできます()メソッド削除
6.4 Pythonリストスクリプト演算子###
**リストペア+と*の演算子は文字列に似ています。 +記号は結合リストに使用され、*記号は繰り返しリストに使用されます。 ****
| Python式 | 結果 | 説明 |
|---|---|---|
| len([1、2、3]) | 3 | 長さ |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 組み合わせ |
| [' こんにちは! '] * 4 | ['こんにちは! '、'こんにちは! '、'こんにちは! '、'こんにちは! '] | 繰り返し |
| 3 in [1、2、3] | True | 要素はリストに存在しますか |
| [1、2、3]のxの場合:print(x、end = "") | 1 2 3 | 反復 |
6.5 Pythonリストとネストされたリストのインターセプトとスプライシング###
Pythonのリストインターセプトと文字列操作のタイプは次のとおりです
L =['Google','Runoob','Taobao']print(L[2])print(L[-2])print(L[1:])
str1 =[1,4,9,13]
str1 +=[15,18,20,22]print(str1)
# 上記の例の出力は次のとおりです。
Taobao
Runoob
[' Runoob','Taobao'][1,4,9,13,15,18,20,22]
ネストされたリスト
stra =['a','b','c']
strb =['d','e','f']
strc =[stra,strb]print(strc)print(strc[0])print(strc[0][1])
# 上記の例の出力は次のとおりです。:[['a','b','c'],['d','e','f']]['a','b','c']
b
6.6 Pythonリストの関数とメソッド###
Pythonには次の関数が含まれています:
| シリアル番号 | 機能 |
|---|---|
| 1 | len(list)リスト要素の数 |
| 2 | max(list)はリスト要素の最大値を返します |
| 3 | min(list)はリスト要素の最小値を返します |
| 4 | list(seq)タプルをリストに変換する |
Pythonには次のメソッドが含まれています
| シリアル番号 | 方法 |
|---|---|
| 1 | list.append(obj)は、リストの最後に新しいオブジェクトを追加します |
| 2 | list.count(obj)は、要素がリストに表示される回数をカウントします |
| 3 | list.extend(seq)は、リストの最後に別の順序で複数の値を追加します(元のリストを新しいリストで拡張します) |
| 4 | list.index(obj)リストから値の最初の一致のインデックス位置を検索します |
| 5 | list.insert(index、obj)オブジェクトをリストに挿入 |
| 6 | list.pop([index = -1])リストから要素(デフォルトでは最後の要素)を削除し、要素の値を返します |
| 7 | list.remove(obj)は、リスト内の値の最初の一致を削除します |
| 8 | list.reverse()リスト内の要素を反転します |
| 9 | list.sort(key = None、reverse = False)元のリストを並べ替える |
| 10 | list.clear()リストをクリアする |
| 11 | list.copy()リストをコピー |
次の例に示すように、プラス記号+はリスト連結演算子であり、アスタリスク*は繰り返される操作です。
list =['runoob',788,3.14,'youmen',77]
youmen =['flying']print(list)print(list[0])print(list[2:4])print(list[2:])print(list *2)print(list + youmen)
# 上記の例の出力:['runoob',788,3.14,'youmen',77]
runoob
[3.14,' youmen'][3.14,'youmen',77]['runoob',788,3.14,'youmen',77,'runoob',788,3.14,'youmen',77]['runoob',788,3.14,'youmen',77,'flying']
6.7 リストをスタックとして使用する###
listメソッドを使用すると、リストをスタックとして簡単に使用できます。スタックは特定のデータ構造として使用され、最初に入力された要素が最後に解放されます(最後に入力、最初に出力)。 append()メソッドを使用して、スタックの一番上に要素を追加します。インデックスを指定せずにpop()メソッドを使用すると、スタックの最上位から要素を解放できます。例えば:
Example
>>> stack =[3,4,5]>>> stack.append(6)>>> stack.append(7)>>> stack
[3,4,5,6,7]>>> stack.pop()7>>> stack
[3,4,5,6]>>> stack.pop()6>>> stack.pop()5>>> stack
[3,4]
6.8 リストをキューとして使用する###
リストをキューとして使用することもできますが、キューに追加された最初の要素が最初に取り出されます。ただし、この目的でリストを使用するのは効率的ではありません。リストの最後に要素を追加またはポップするのは高速ですが、リストの先頭から挿入またはポップするのは高速ではありません(他のすべての要素を1つずつ移動する必要があるため)。
Example3from collections import deque >> queue = deque(["Eric", "John", "Michael"]) >> queue.append("Terry") # Terry arrives >> queue.append("Graham") # Graham arrives >> queue.popleft() # The first to arrive now leaves 'Eric' >> queue.popleft() # The second to arrive now leaves 'John' >> queue # Remaining queue in order of arrival deque(['Michael', 'Terry', 'Graham'])
6.9 リストの理解###
リスト内包表記は、シーケンスからリストを作成する簡単な方法を提供します。一般に、アプリケーションプログラムは、特定のシーケンスの各要素にいくつかの操作を適用し、要素として取得した結果を使用して新しいリストを生成するか、特定の判断条件に従ってサブシーケンスを作成します。
各リスト内包表記の後にはforの式が続き、その後にforまたはif句が0個以上あります。返される結果は、式に基づいて後続のforおよびifコンテキストから生成されたリストです。式でタプルを推定する場合は、括弧を使用する必要があります。
ここでは、リスト内の各値に3を掛けて、新しいリストを取得します。
Example
>>> vec =[2,4,6]>>>[3*x for x in vec][6,12,18]
# 彼のパワー計算も実行できます:>>>[[x, x**2]for x in vec][[2,4],[4,16],[6,36]]
# 前に同じシーケンスの各要素に対して1つずつメソッドを呼び出すことができます:>>> freshfruit =[' banana',' loganberry ','passion fruit ']>>>[weapon.strip()for weapon in freshfruit]['banana','loganberry','passion fruit']
# if句をフィルターとして使用することもできます:>>>[3*x for x in vec if x >3][12,18]>>>[3*x for x in vec if x <2][]
# ループやその他のトリックに関するいくつかのデモがあります:>>> vec1 =[2,4,6]>>> vec2 =[4,3,-9]>>>[x*y for x in vec1 for y in vec2][8,6,-18,16,12,-36,24,18,-54]>>>[x+y for x in vec1 for y in vec2][6,5,-7,8,7,-5,10,9,-3]>>>[vec1[i]*vec2[i]for i inrange(len(vec1))][8,12,-54]
# リスト内包表記では、複雑な式またはネストされた関数を使用できます:>>>[str(round(355/113, i))for i inrange(1,6)]['3.1','3.14','3.142','3.1416','3.14159']
6.10 ネストされたリストの理解###
Pythonリストはネストすることもできます
次の例は、3X4マトリックスリストを示しています
Example5
>>> matrix =[...[1,2,3,4],...[5,6,7,8],...[9,10,11,12],...]
# 次の例では、3X4マトリックスリストを4X3リストに変換します
>>>[[ row[i]for row in matrix]for i inrange(4)][[1,5,9],[2,6,10],[3,7,11],[4,8,12]]
# 次の例は、次の方法を使用して実装することもできます:>>> transposed =[]>>>for i inrange(4):... transposed.append([row[i]for row in matrix])...>>> transposed
[[1,5,9],[2,6,10],[3,7,11],[4,8,12]]
セブン、Python3タプル##
タプルは、リスト(リスト)と同様の別のデータタイプです。
タプルは()で識別され、内部要素はコンマで区切られますが、タプルを2回割り当てることはできません。これは、読み取り専用リストに相当します。
タプルは更新できませんが、リストは更新できます。タプルの作成は非常に簡単です。括弧内に要素を追加し、コンマで区切ってください。
tup1 =(50)print(type(tup1))
tup2 =(50,)print(type(tup2))<class'int'><class'tuple'>
# タプルは文字列に似ています。添え字インデックスは0から始まり、インターセプト、結合などが可能です。.
7.1 tuple ###にアクセスします
次の例のように、タプルは添え字インデックスを使用してタプルの値にアクセスできます
tuple =('runoob',788,3.14,'youmen',77)
youmen =(123,'flying')print(tuple)print(tuple[0])print(tuple[2:4])print(tuple[2:])print(tuple *2)print(tuple + youmen)
# 上記の例の出力('runoob',788,3.14,'youmen',77)runoob(3.14,'youmen')(3.14,'youmen',77)('runoob',788,3.14,'youmen',77,'runoob',788,3.14,'youmen',77)('runoob',788,3.14,'youmen',77,123,'flying')
7.2 タプルを変更する###
タプルの要素値を変更することはできませんが、次の例に示すように、タプルを接続して組み合わせることができます
tup1 =(1,2,3)
tup2 =('flying','youmen')
tup3 = tup1 + tup2
print(tup3)(1,2,3,'flying','youmen')
7.3 タプルを削除する###
タプル内の要素を削除することはできませんが、次の例に示すように、delステートメントを使用してタプル全体を削除できます。
tup =('Google','Runoob',1999,2000)print(tup)
del tup
print("削除されたタプルタップ:")print(tup)('Google','Runoob',1999,2000)
削除されたタプルタップ:Traceback(most recent call last):
File "c:\Users\You-Men\.vscode\extensions\ms-python.python-2019.11.50794\pythonFiles\ptvsd_launcher.py",
# 上記のインスタンスタプルが削除された後、出力変数には異常な情報が含まれます。出力は次のとおりです。:
削除されたタプルタップ:Traceback(most recent call last):
File "test.py", line 8,in<module>print(tup)
NameError: name 'tup' is not defined
7.4 タプルオペレーター###
文字列と同様に、+と*を使用してタプル間の操作を実行できます。これは、それらを組み合わせてコピーすることができ、操作後に新しいタプルが生成されることを意味します
| Python式 | 結果 | 説明 |
|---|---|---|
| len((1、2、3)) | 3 | 要素数を計算する |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 接続 |
| (' こんにちは! '、)* 4 | ('こんにちは! '、'こんにちは! '、'こんにちは! '、'こんにちは! ') | コピー |
| 3 in(1、2、3) | True | 要素は存在しますか |
| (1、2、3)のxの場合:print(x、) | 1 2 3 | 反復 |
7.5 タプルインデックス、インターセプト###
タプルもシーケンスであるため、以下に示すように、タプル内の指定された位置にある要素にアクセスでき、インデックス内の要素のセグメントをインターセプトすることもできます。タプル:
tup =('Google','Runoob',1999,2000)print(tup[2])print(tup[-2])print(tup[1:])
# 上記の例の出力
19991999(' Runoob',1999,2000)
| Python式 | 結果 | 説明 |
|---|---|---|
| L [2] | 'Runoob' | 3番目の要素を読む |
| L [-2] | 'Taobao' | 逆読み;最後から2番目の要素を読む |
| L [1:] | ( 'Taobao'、 'Runoob') | インターセプト要素、2番目以降のすべての要素。 |
7.6 タプル組み込み関数###
Python3タプルには、次の組み込み関数が含まれています
| シリアル番号 | 方法と説明 | 例 |
|---|---|---|
| 1 | len(tuple)は、タプル要素の数を計算します | tuple1 =( 'Google'、 'Runoob'); len(tuple1); 2 |
| 2 | max(tuple)は、タプル内の要素の最大値を返します。 | tuple2 =( '5'、 '4'、 '3'); max(tuple2); 5 |
| 3 | min(tuple)は、タプル内の要素の最小値を返します | tuple3 =( '5'、 '4'、 '8'); min(tuple3); 4 |
| 4 | tuple(seq) | list1=[1,2,3]; tuple4=tuple(list1);tuple4 |
不変のタプルについて****いわゆる不変のタプルは、タプルが指すメモリ内のさまざまなアドレス値を指します。
>>> tup =('r','u','n','o','o','b')>>> tup[0]='g' #要素の変更をサポートしていません
Traceback(most recent call last):
File "<stdin>", line 1,in<module>
TypeError:'tuple' object does not support item assignment
>>> id(tup) #メモリアドレスを表示する
4440687904>>> tup =(1,2,3)>>>id(tup)4441088800 #メモリアドレスが異なります
不変性は悪いことではありません。たとえば、理解できないAPIにデータを渡す場合、データが変更されないようにすることができます。同様に、関数から返されたタプルを操作する場合、組み込みのList()関数を使用してそれをリストに変換できます。
8、Python辞書##
辞書は別の可変コンテナモデルであり、任意のタイプのオブジェクトを格納できます
辞書の各キー値(key => value)のペアは、コロン(:)で区切られ、各ペアはコンマ(、)で区切られます。辞書全体は中括弧({})で囲まれ、形式は次のとおりです。
辞書(辞書)は、リスト以外にPythonで最も柔軟な組み込みデータ構造タイプです。リストはオブジェクトの順序付けられたコレクションであり、辞書はオブジェクトの順序付けられていないコレクションです。2つの違いは、辞書の要素がオフセットではなくキーを介してアクセスされることです。
8.1 辞書###の値にアクセスします
辞書は「{}」で識別されます。ディクショナリは、インデックス(キー)とそれに対応する値で構成されます。
# Example1
youmen ={'name':'tom','code':6379,'youmen':'flying'}print(youmen['name'])print(youmen['code'])
tom
6379
# Example2
dict ={'Alice':'1234','youmen':'22','Cecil':'3258'}print("dict[Alice]",dict['Alice'])print('dict[youmen]',dict['youmen'])
dict[Alice]1234
dict[youmen]22
8.2 辞書を変更する###
辞書に新しいコンテンツを追加する方法は、次のように、新しいキーと値のペアを追加し、既存のキーと値のペアを変更または削除することです。
dict ={'Alice':'1234','youmen':'22','Cecil':'3258'}
dict['Alice']=1
dict['youmen']=22print(dict['Alice'])print(dict['youmen'])
# 以下は、例の出力結果です。
122
8.3 辞書要素を削除する###
**次の例のように、1つの要素を削除して、辞書をクリアすることもできます。辞書をクリアするために必要な操作は1つだけです。**表示delコマンドを使用して辞書を削除します。
dict ={'Alice':'1234','youmen':'22','Cecil':'3258'}
del dict['Alice']
dict.clear()
del dict
print(dict['Alice'])
# このとき、del操作を実行すると辞書が存在しなくなるため、上記のインスタンスを実行するとエラーが報告され、例外が発生します。:
8.4 辞書キーの特徴###
ディクショナリ値は、標準オブジェクトまたはユーザー定義オブジェクトのいずれかの任意のpythonオブジェクトにすることができますが、キーは機能しません。 **** 2つの重要な点を覚えておく必要があります:** 1)同じキーを2回表示することはできません。作成中に同じキーが2回割り当てられた場合、次の例のように、後者の値が記憶されます。**
dict ={'Alice':'1234','youmen':'22','Cecil':'3258','Alice':'リトルルーキー'}print("dict['Alice']:",dict['Alice'])
# 上記の例の出力は次のとおりです。
リトルルーキー
2 )キーは不変である必要があるため、次の例のように、数値、文字列、またはタプルとして使用できますが、リストとしては使用できません。
dict ={[Alice]:'1234','youmen':'22','Cecil':'3258','Alice':'リトルルーキー'}
# 上記の例の出力:Traceback(most recent call last):
File "test.py", line 3,in<module>
dict ={['Name']:'Runoob','Age':7}
TypeError: unhashable type:'list'
8.5 辞書に組み込まれた関数とメソッド###
Pythonには、次の組み込み関数が含まれています。
| シリアル番号 | 機能と説明 | 例 |
|---|---|---|
| 1 | len(dict)辞書要素の数、つまりキーの総数をカウントします。 | >>> dict = {'Name': 'Runoob'、 'Age':7、 'Class': 'First'} >>> len(dict)3 |
| 2 | str(dict)出力辞書。印刷可能な文字列として表されます。 | >>> dict = {'Name': 'Runoob'、 'Age':7、 'Class': 'First'} >>> str(dict) "{'Name': 'Runoob'、 'Class': 'First'、 'Age':7} " |
| 3 | type(variable)は、入力変数タイプを返します。変数が辞書の場合は、辞書タイプを返します。 | >>> dict = {'Name': 'Runoob'、 'Age':7、 'Class': 'First'} >>> type(dict)<class 'dict'> |
Python辞書には、次の組み込みメソッドが含まれています。
| シリアル番号 | 機能と説明 |
|---|---|
| 1 | radiansdict.clear()は辞書内のすべての要素を削除します |
| 2 | radiansdict.copy()は辞書の浅いコピーを返します |
| 3 | radiansdict.fromkeys()は新しい辞書を作成し、シーケンスseqの要素を辞書のキーとして使用し、valは辞書のすべてのキーに対応する初期値です |
| 4 | radiansdict.get(key、default = None)は、指定されたキーの値を返します。値が辞書にない場合は、デフォルト値を返します |
| 5 | key indictキーが辞書dictにある場合はtrueを返し、そうでない場合はfalseを返します |
| 6 | radiansdict.items()は、トラバース可能な(キー、値)タプル配列をリストとして返します |
| 7 | radiansdict.keys()はイテレーターを返します。イテレーターはlist() |
| 8 | radiansdict.setdefault(key、default = None)はget()に似ていますが、キーが辞書に存在しない場合、キーが追加され、値がデフォルトに設定されます |
| 9 | radiansdict.update(dict2)辞書dict2のキーと値のペアをdict |
| 10 | radiansdict.values()はイテレーターを返します。イテレーターはlist() |
| 11 | pop(key [、default])辞書の指定されたキーに対応する値を削除します。戻り値は削除された値です。キー値を指定する必要があります。それ以外の場合は、デフォルト値が返されます。 |
| 12 | popitem()は、辞書内のキーと値の最後のペアをランダムに返し、削除します。 |
9、Python3コレクション##
**セットは、繰り返されない要素の順序付けられていないシーケンスです。 ****中括弧{}またはset()を使用してコレクションを作成できます。注:空のコレクションを作成するには、{}を使用して空の辞書を作成するため、{}の代わりにset()を使用する必要があります。 **フォーマットの作成:
parame ={value01,value02,...}
または
set(value)
basket ={'apple','orange','apple','pear','orange','banana'}print(basket)print('apple'in basket)
# 上記の例の出力は次のとおりです。
{' apple','banana','orange','pear'}
True
# 以下に2セット間の動作を示します。
a =set('admin')
b =set('youmen')print(a - b)print(a ^ b)print(a | b)print(a & b)
# 以下は、例の出力結果です。
{' i','d','a'} #セットaにはbに含まれていない要素が含まれています
{' u','d','i','y','a','e','o'}{'a','u','e','o','n','m','i','d','y'} #aとbの両方に含まれる要素
{' n','m'} #aとbの両方に含まれる要素.
9.1 要素を追加###
要素xをコレクションに追加
thisset =set(('admin','Google','Taobao'))
thisset.add('youmen')print(thisset)
thisset.update('flying')print(thisset)
# 上記の例の出力
{' Taobao','Google','youmen','admin'}{'admin','n','Taobao','y','f','Google','l','youmen','g','i'}
9.2 要素を削除する###
要素xをセットaから移動します。存在しない場合は、エラーが報告されます
thisset =set(('admin','Google','Taobao'))
thisset.remove("Taobao")print(thisset)
# 上記の例の出力
{' admin','Google'}
9.3 コレクション要素の数を数え、コレクションをクリアします###
# コレクション要素の数を数える
thisset =set(('admin','Google','Taobao'))print(len(thisset))3
# 空のコレクション
thisset.clear()print(thisset)set()
# 要素がコレクションに存在するかどうかを確認します
x in thisset
thisset =set(('admin','Google','Taobao'))print('admin'in thisset)
True
コレクションは理解もサポートします
>>> a ={x for x in'YouMen'if x not in'o'}>>> a
{' e','u','Y','n','M'}
9.4 組み込みメソッドの完全なリスト###
| 方法 | 説明 |
|---|---|
| add() | コレクションに要素を追加する |
| clear() | コレクション内のすべての要素を削除します |
| copy() | コレクションをコピーする |
| Difference() | 複数のセットの差を返します |
| Difference_update() | 指定されたセットにも存在するセット内の要素を削除します。 |
| destroy() | コレクション内の指定された要素を削除します |
| 交差点() | セットの交差点を返します |
| intersection_update() | セットの共通部分を返します。 |
| isdisjoint() | 2つのセットに同じ要素が含まれているかどうかを判断し、含まない場合はTrueを返し、含まない場合はFalseを返します。 |
| issubset() | 指定されたセットがメソッドパラメータセットのサブセットであるかどうかを判断します。 |
| issuperset() | このメソッドのパラメーターセットが指定されたセットのサブセットであるかどうかを判別します |
| pop() | 要素をランダムに削除 |
| remove() | 指定された要素を削除します |
| symmetric_difference() | 2つのコレクションで繰り返されない要素のコレクションを返します。 |
| symmetric_difference_update() | 現在のセットの別の指定されたセットの同じ要素を削除し、別の指定されたセットの異なる要素を現在のセットに挿入します。 |
| union() | 2つのセットの和集合を返します |
| update() | コレクションに要素を追加する |
10、トラバーサルスキル##
辞書をトラバースするとき、items()メソッドを使用してキーワードと対応する値を同時に解釈できます:
>>> dict ={'nginx':80,'tomcat':8080,'Mysql':3306}>>>for i,k in dict.items():...print(i,k)...
nginx 80
tomcat 8080
Mysql 3306
# 列挙を使用してシーケンスをトラバースできます()関数
>>> for i ,v inenumerate(['tic','tac','toe']):...print(i,v)...0 tic
1 tac
2 toe
# シーケンスを逆方向にトラバースする場合は、最初にシーケンスを指定してから、reverseを呼び出します。()関数:>>>for i inreversed(range(1,10,2)):...print(i)...97531
# シーケンスを順番にトラバースし、ソートを使用します()この関数は、元の値を変更せずにソートされたシーケンスを返します:>>> dict ={'nginx':80,'tomcat':8080,'Mysql':3306,'Redis':6379,'NTP':123}>>> dict
{' nginx':80,'tomcat':8080,'Mysql':3306,'Redis':6379,'NTP':123}>>>for i insorted(set(dict)):...print(i)...
Mysql
NTP
Redis
nginx
tomcat
11、Pythonデータタイプ変換##
場合によっては、組み込みタイプのデータを変換する必要があります。データタイプの変換では、関数名としてデータタイプを使用するだけで済みます。
次の組み込み関数は、データタイプ間の変換を実行できます。これらの関数は、変換された値を表す新しいオブジェクトを返します。
| col1 | col2 |
|---|---|
| 機能 | 説明 |
| [ int(x [、base])] | xを整数に変換 |
| [ long(x [、base])] | xを長整数に変換 |
| [ float(x)] | xを浮動小数点数に変換 |
| [ complex(real [、imag])] | 複素数を作成する |
| [ str(x)] | オブジェクトxを文字列に変換 |
| [ repr(x)] | オブジェクトxを式文字列に変換 |
| [ eval(str)] | 文字列内の有効なPython式を計算し、オブジェクトを返すために使用されます |
| [ tuple(s)] | シーケンスsをタプルに変換します |
| [ list(s) | シーケンスsをリストに変換します |
| [ set(s)] | 変数セットに変換 |
| [ dict(d) | 辞書を作成します。 dはシーケンス(キー、値)タプルである必要があります。 |
| [ 凍結セット] | 不変セットに変換 |
| [ chr(x)] | 整数を文字に変換する |
| [ unichr(x)] | 整数をUnicode文字に変換する |
| [ ord(x)] | 文字を整数値に変換する |
| [ hex(x) | 整数を16進文字列に変換 |
| [ oct(x)] | 整数を8進文字列に変換 |
12、メモリ管理##
* 変数を事前に宣言する必要はなく、タイプを指定する必要もありません。
*動的言語の特徴
* 一般に、プログラミングにおける変数の存続やメモリの管理について気にする必要はありません。
* Pythonは参照カウントを使用して、すべての変数への参照数を記録します.(参照カウンター、ガベージコレクションメカニズム)*可変参照数が0になると、ごみ収集されたGCになります。
*カウントの増加:xなど、他の変数に割り当てて参照数を増やします=3,y=x
*カウントの減少:*関数が実行されると、ローカル変数は自動的に破棄され、オブジェクト参照数が減少します
*変数は、xなどの他のオブジェクトに割り当てられます=3;y=x;x=4*パフォーマンスの問題については、変数参照の問題を考慮する必要がありますが、メモリを解放するには、需要に応じてメモリを解放しないようにしてください.
Recommended Posts